Page History
| Navitabs | ||||
|---|---|---|---|---|
|
1. Introduktion
Indholdsfortegnelse:
| Table of Contents |
|---|
Introduktion
Dette er en foreløbig beskrivelse, med rettelser på vej.
...
Formålet med dette dokument er at beskrive systemarkitekturen for eCPR2 servicenNationalt eCPR.
1.2. Læsevejledning
Dokumentet er tiltænkt personer der skal drifte eCPR og indeholder dermed udviklere og IT-arkitekter med interesse i Nationalt eCPR og dens opbygning. Siden indeholder primært information om Nationalt eCPR-servicen i forhold til dens relationer til andre systemer, og i første omgang dermed ikke om servicens interne opbygning.
1.3. Definitioner og referencer
...
2. Introduktion til eCPR
2.1. Løsningens opbygning
eCPR består af én javabaseret web-service, nemlig eCPR-service. Den har ekstern afhængighed til NAS, CPR-enkeltopslag, en intern database samt et view til krs-stamdata. I nedenstående diagram ses et arkitektur overblik over servicen og dens eksterne afhængigheder:
| Gliffy Diagram | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Sekvensdiagrammer
Nedenfor ses 2 sekvensdisagrammer. De blå komponenenter hører alle til eCPR-servicen, og illustrerer hvordan flowet overordnet set forløber internt.
Sekvensdiagrammet for CreatePersonRequest ses nedenfor.
| Gliffy Diagram | ||||||
|---|---|---|---|---|---|---|
|
I forløbet "CreatePerson" bruges Cpr-enkeltopslag samt NAS ikke. I sekvensdiagrammet for UpdatePersonRequest ses hvordan Cpr-enkeltopslag og NAS bruges i et UpdatePerson kald. Cpr-enkeltopslag bruges kun, hvis UpdatePerson indeholder et CPR-nummer, hvorved der bliver tjekket op mod stamdata, om CPR-nummeret eksisterer. I nedenstående sekvensdiagram antages det, at UpdatePersonRequest laves med et medsendt CPR-nummer:
| Gliffy Diagram | ||||||||
|---|---|---|---|---|---|---|---|---|
|

...
Introduktion til eCPR
Løsningens Afhængigheder
Nationalt eCPR anvender følgende NSP komponenter:
Komponent | Beskrivelse | ||||||
|---|---|---|---|---|---|---|---|
DCC (DeCoupling Component), også kendt som SOSI afkoblingskomponenten, fungerer som en webservice gateway og foretager routing af forespøgsler mod services der udstilles på eller via NSP'en. | |||||||
National Adviseringsservice på NSP'en funger som en afkoblet system-til-system advisering gennem et "publish-subscribe"-mønster | |||||||
Sundhedsvæsenets Elektroniske Brugerstyring er en fælles platform for brugeradministration af forskellige sundhedsfaglige systemer. SEB vil blive brugt i Nationalt eCPR til udstilling af nationale roller som understøtter anvendersystemernes brugerrettighedsstyring mod Nationalt eCPR. Denne tilgåes via Acces Handler
| |||||||
Stamdatamodul på NSP består af 6 registreservices, hvor eCPR gør brug af SCES servicen (se nedenfor) og Stamdata Kopi register Service (SKRS) databasen, hvor den tilgår Bemyndigelsesregisteret, CPR registeret og authorisationsregisteret gennem 3 views (Se eCPR - Installationsvejledning) | |||||||
CPR-enkeltopslag er en realisering af MedCom-standarden 'Det Gode CPR Opslag' | |||||||
eCPR2 importer bruges til at lægge eCPR stamdata i KRS-databasen. Dette foregår ved, at brugere indsender data til eCPR2-servicen, hvorefter eCPR2 servicen eksporterer dette data via et job, og lægger det i et filsystem på NSP'en. eCPR2 Importeren læser data fra dette export og lægger det i databasen hvorefter SKRS servicen udstiller dette data. |
Løsningens opbygning
Nationalt eCPR består af én javabaseret web-service, nemlig eCPR-service. Den udstilles på NSP via DCC, og udstiller ligeledes adviseringer gennem NAS på NSP. For at servicen fungerer har den ligeledes en ekstern afhængighed til NSP stamdata gennem views, herunder SCES (CPR-enkeltopslag). I nedenstående diagram ses et arkitektur overblik over servicen og dens eksterne afhængigheder:
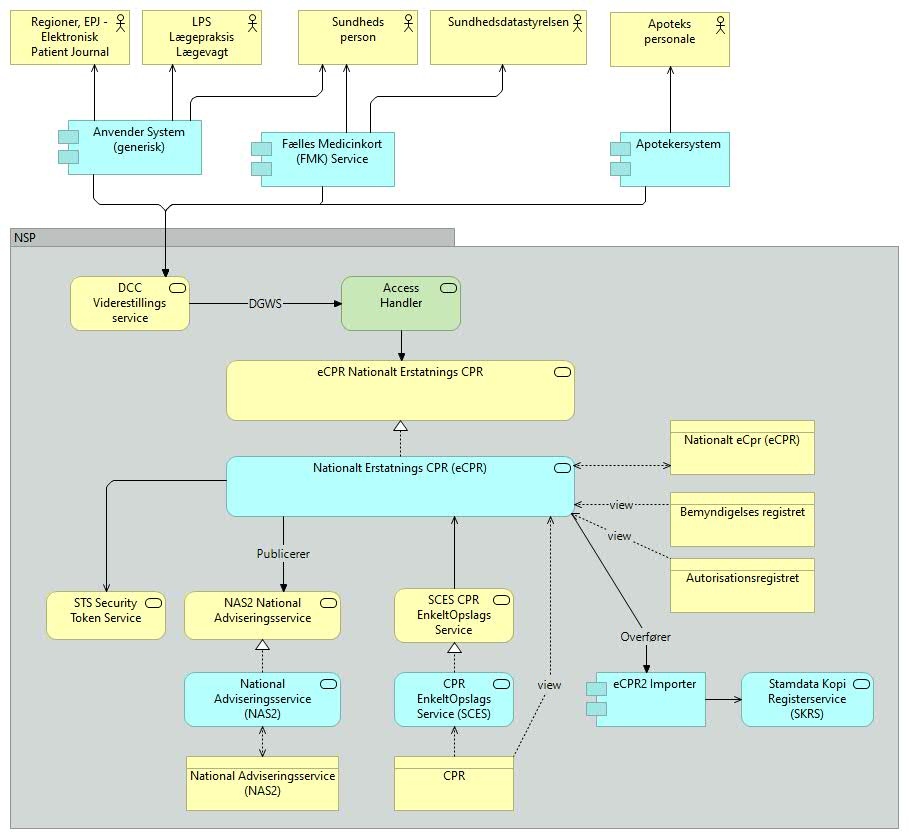
Både service og dataformater for Nationalt eCPR er udviklet til at være generelle og fleksible, så de kan understøtte forskellige scenarier for brug, og implementeringsstrategier på tværs af sundhedsvæsenets aktører.
Nationalt eCPR-service er beskrevet i eCPR - Snitfladebeskrivelse
Dataformater er beskrevet under NSP stamdataregistre her.
Sekvensdiagrammer
Nedenfor ses 2 sekvensdisagrammer. De blå komponenenter hører alle til eCPR-servicen, og illustrerer hvordan flowet overordnet set forløber internt, uden at gå i detaljer med implementationen.
Sekvensdiagrammet for CreatePersonRequest ses nedenfor.
| Gliffy Diagram | ||||||
|---|---|---|---|---|---|---|
|
I forløbet "CreatePerson" bruges Cpr-enkeltopslag samt NAS ikke. I sekvensdiagrammet for UpdatePersonRequest ses hvordan Cpr-enkeltopslag og NAS bruges i et UpdatePerson kald. Cpr-enkeltopslag bruges kun, hvis UpdatePerson indeholder et CPR-nummer, hvorved der bliver tjekket op mod stamdata, om CPR-nummeret eksisterer. I nedenstående sekvensdiagram antages det, at UpdatePersonRequest laves med et medsendt CPR-nummer:
| Gliffy Diagram | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Sikkerhed
Sikkerhedsmodellen for National eCPR er baseret på MedComs “Den Gode Webservice” og brug af SOSI-Gateway. Sundhedsfaglige brugere anvender SOSI sikkerhedsmodellen, hvor adgang gives via lokale fagsystemer og udveksles med NSP infrastrukturen, herunder Nationalt eCPR, således sundhedsfaglige brugere er identificeret med navn, rolle og organisation. Sundhedsfaglige brugere får udstedt erhvervsidentiteter via de organisationer de er tilknyttet. Disse erhvervsidentiteter vedhæftes i SOSI sikkerhedsmodellen.
Forretningsrelateret data
Data, der anvendes forretningsmæssigt, f.eks. sygehusafdelingsnummer, ydernummer og autorisationsnummer, bør medsendes i den forretningsmæssige del af dokumentet, og ikke hentes fra dokumentheaderen. Det kan ikke udelukkes at f.eks.:
En sekretær på en sygehusafdeling logger ind med SKS-sygehusafdelingsnummer med 6 cifre og foretager en opdatering af data på et afsnit angivet med 7 cifre
En lægepraksis har to ydernumre, der logges ind med det ene men sendes data for begge.
Skal der senere opstilles regler for hvorvidt dette skal være muligt bør valideringen af disse regler holdes adskilt fra den forretningsmæssige implementering. Dette bør ske for at minimere risikoen for at ændringer i sikkerhedsmodellen påvirker denne.
Adgangsstyring
| Excerpt Include | ||||
|---|---|---|---|---|
|
Formater
| Excerpt Include | ||||||
|---|---|---|---|---|---|---|
|
Typebestemmelse med OID'er
| Excerpt Include | ||||||
|---|---|---|---|---|---|---|
|
Beslutninger ift. arkitektur og jura
I følgende tabel er listet beslutninger, som har indvirkning på arkitekturen bag Nationalt eCPR.
| Dato | Emne | Problem, beskrivelse og beslutning | Afklaret med |
|---|---|---|---|
| Opbevaring af data | Problem Beskrivelse Beslutning | SDS's juridiske afdeling |
| Genbrug af eCPR-numre | Problem Beskrivelse Dog kan der stadig være lokale journaler hos andre aktører som endnu ikke har fået omlagt patientjournalen. Hvis eCPR-nummeret 'genbruges' til en ny patient risikerer man derfor at flere patienters journaler samkøres; at 'gammelt data kobles på ny patient'. Beslutning | SDS's juridiske afdeling |
| Autorisation | Problem Beskrivelse Beslutning | SDS's juridiske afdeling |
| Brug af eCPR udenfor sundhedsvæsenet | Problem Beskrivelse Beslutning | SDS's juridiske afdeling |
| Log i MinLog Borgerlog | Problem Beskrivelse Tilgang til og ændringer i CPR-registreret logges heller ikke i MinLog Borgerlog. Beslutning | SDS's juridiske afdeling |
| Log i MinLog Medhjælpslog | Problem Beskrivelse Beslutning | SDS's juridiske afdeling |
| Anvendelse af SKRS | Problem Beskrivelse SKRS bruges bl.a. til at have en lokale kope af CPR registret i dag. Beslutning | SDS's juridiske afdeling |
| Begrænsning i brug af datamodellen | Problem Beskrivelse Da der ikke sker en automatisk opdatering af data, og da patienten ikke selv har adgang til at vedligeholde data i Nationalt eCPR, er adresse og kontaktinformation forældet med det samme efter endt kontakt; dvs. at man ikke kan forvente at kunne benytte de angivne information til at kontakte patienten efterfølgende. Slutbrugergruppen blev derfor bedt om at vurdere datamodellen, og de data det er muligt at angive. Beslutning
| Slutbrugergruppe Nationalt eCPR 2020 |
| Valg af X-eCPR format | Problem Beskrivelse 1. Brug af formatet ”X-eCPR” i de lokale systemer 2. Brug af formatet ”D-eCPR+kildeangivelse” i de lokale systemer Beslutning | Styregruppen for eCPR-projektet |
...
Ændringslog
| 0.8 | 2023-10-31 | Udkast publiceret | SDS |
| 1.0 | 2023-12-05 | Side færdiggjort | SDS |

Løsningen giver alle med adgang til NSP mulighed for at aflevere adviseringer til øvrige parter i sundhedssektoren gennem NSP.
Løsningen er en realisering af et ”publish-subscribe” kommunikationsmønster.
* Hver kasse i ovenstående diagram har en kort forklaring, som kommer frem i et nyt browservindue, når der klikkes på kassen.
2.2. Software blueprint og logisk model
Nedenstående blueprint viser lagdelingen i NAS:
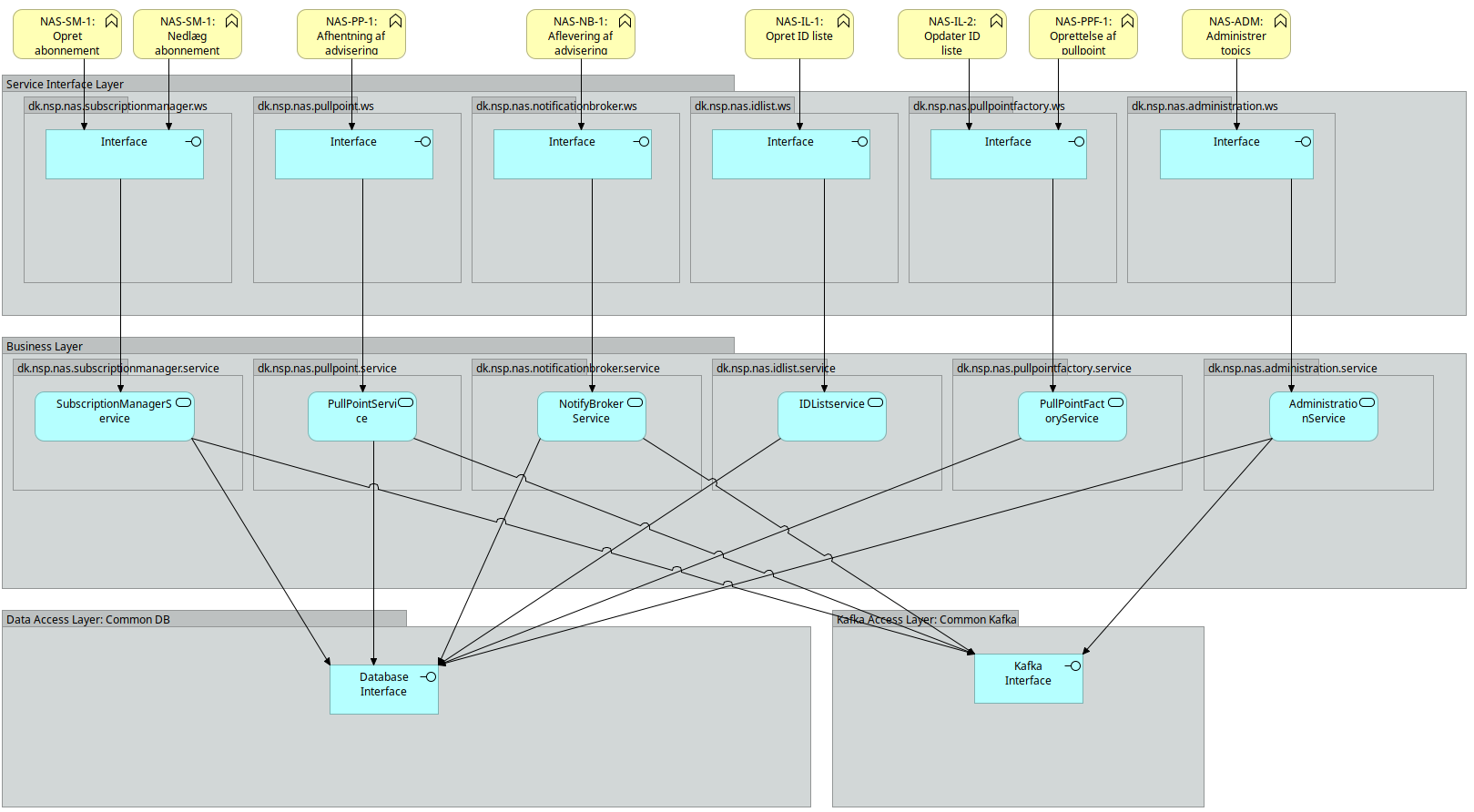
Logisk set kan løsningen tegnes som nedenstående:
2.3. Notification Broker
NotificationBrokers ansvarsområder er at modtage adviseringer via det udbudte interface Notify og delegere disse videre til det rette topic på Kafka infrastrukturen.

NotificationBroker er inddelt i lag. Selve oprettelse og orkestrering af NotificationBrokers komponenter varetages af en konfigurationskomponent. Denne konfigurationskomponent er også ansvarlig for at inkludere de relevante konfigurationer fra de delte komponenter, som NotificationBroker anvender: Det drejer sig om Topic-delen af databasekomponenten samt Publisher-delen af kafkakomponenten.
På ydersiden af NotificationBroker findes Service Interface: Dette lag er ansvarlig for at udbyde Notify SOAP servicen samt at foretage mapning ned i mod den model, der anvendes i forretningslaget i NotificationBroker.
Forretningslaget indeholder forretningslogikken: Dvs tjek på, om det indkommende topic er et lovligt NAS topic og publisering til den underliggende infrastruktur.
2.3.1. User stories
I forhold til NotificationBroker er følgende user stories relevante:
...
NotificationBrokers opførsel under "Aflevering af advisering" er beskrevet i nedenstående sekvensdiagram.
2.4. PullPoint Service
PullPoint Service har som ansvarsområde at udstille et endpoint, som anvendere kan bruge til at hente adviseringer fra NAS2 for et givent pullpoint.

Som en del af dette, er det op til PullPoint Service at opretholde en status for hvert abonnement under et givent pull point, der fortæller, hvor langt anvenderen er kommet i afhentningen.
PullPoint Service er inddelt i lag. Selve oprettelse og orkestrering af PullPoint Service komponenter varetages af en konfigurationskomponent. Denne konfigurationskomponent er også ansvarlig for at inkludere de relevante konfigurationer fra de delte komponenter, som PullPoint anvender: Det drejer sig om PullPoint-delen af databasekomponenten samt Streamer-delen af kafkakomponenten.
På ydersiden af PullPoint findes Service Interface: Dette lag er ansvarlig for at udbyde GetMessages SOAP servicen samt at foretage mapning ned i mod den model, der anvendes i forretningslaget i PullPointService.
Forretningslaget indeholder forretningslogikken: PullPoint Service henter notifikationer fra Kafka via Streamer interfacet, som stilles til rådighed via det fælles Kafka modul. Til at holde styr på tilstanden for hvert abonnement anvender PullPoint Service det fælles database modul, der holder styr på tilstand (offset) hvor hvert abonnement.
2.4.1. User stories
I forhold til PullPoint Service er følgende user stories relevante:
...
2.4.2. Sekvensdiagram
Følgende diagram viser hvordan en klient henter notifikationer på et pullpoint.
Her er web service laget igen adskilt fra forretningslogikken, som det også var gjort i Notification Broker.
Efter afhentning af subscriptions, tjekkes det at klienten har adgang til de tilhørende Topics.
Databasen rammes her flere gange, da det er nødvendigt først af finde ud af hvordan beskeder filtreres og hvorfra og så skal det persisteres hvor langt klienten/pullpoint er kommet i Kafka.
Følgende diagram viser den anden user story:
2.4.3. Kald af GetMessages logik
Nedenstående er logikken for kald til GetMessages. Logikken er dokumenteret her da det er et af de steder hvor der er mest kompleksitet i løsningen.
Der er skitseret 4 forskellige scenarier for kald af GetMessages. Ved hvert scenarie er der en kort beskrivelse af hvad scenariet dækker over. Udover det anvendes der en række termer i scenarierne der er vigtige for forståelsen af logikken. Disse er beskrevet nedenunder.
- Kafka partitioner: Et Kafka topic er delt op i en række partitioner. Opdeling af et topic i flere partitioner er en måde at skalere og parallelisere adgangen til et Kafka topic. Til et givent Kafka topic er der altid minimum en partition og den vil have partition nummer 1. Det er kun muligt at tilføje partitioner til et topic. En besked i et Kafka topic er identificeret af et partitionsnummer og et offset.
- Offset: Alle beskeder i en Kafka partition er identificeret ved et offset. Et offset er et fortløbende nummer der starter ved 0.
- Nas_consumer: Database tabel der indeholder information omkring hvilke offsets en given NAS subscription er nået til i Kafka. Når der skal læses nye adviser fra Kafka læses der fra de offsets der står i denne tabel. I tabellen er offsets en kommasepareret liste af tal. Er der f.eks. 3 partitioner og sidste gang der blev hentet adviser var det til offset 10, 9 og 13 vil der stå "10,9,13" i tabellen.
Normalt kald hvor der er nye adviser
Scenarie hvor der er sendt adviser til et topic og GetMessages kaldes for at afhente adviser.
- Kald til GetMessages operationen. Body består af maksimalt antal ønskede beskeder i svar. Pull point ID, som blev returneret da pull point blev oprettet, er den sidste del af URL'en. F.eks. http://nas/pullpoint/0d7d7a08-b742-499f-b481-82b2f6d5dc83. Her er 0d7d7a08-b742-499f-b481-82b2f6d5dc83 pull point id.
- Udfør DGWS validering. Det vil sige id kort er valid, korrekt niveau af id kort osv.
- Med Pull Point ID som nøgle læses information om Pull Point alle subscriptions for det givne pull point og for hver subscription læses nyeste og næst nyeste nas_consumer. Rækkefølgen af nas_consumer bestemmes af subscription_serialnumber.
- For hver subscription der er læst fra databasen udføres nedenstående.
- Hent antal partitioner i Kafka for det Kafka topic den nuværende subscription handler om. Dette gøres via kald til partitionsFor metoden på den Kafka Consumer der anvendes. Argument til metoden er topic.
- Da antal partioner læst fra Kafka er det samme som det antal offsets der er læst fra databasen udvides listen ikke.
- For hver partition søges der frem til det offset der er angivet for den givne partition i listen med offsets.
- Kafka polles for beskeder. Det sikres at den samlede poll tid ikke overstiger den konfigurationsparameteren kafka.poll.max.time
- Filtrering udfra den evt. ID liste der er tilknyttet på hash værdi niveau. Hash værdi for ID type og ID er gemt på hvert Kafka besked samt på ID listen i databasen.
- Filtrering på ID og ID type af hensyn til mulig hash kollision.
- Indsæt nye nas_consumer rækker i databasen. Der indsættes en række pr. subscription. Det næste serialnumber i sekvensen gives til den nye nas_consumer.
- Send svar til klient.
Kald hvor subscription er kommet bagud
Scenarie hvor subscription er kommet meget bagud. Meget defineres via property kafka.poll.delta.max.
- Kald til GetMessages operationen. Body består af maksimalt antal ønskede beskeder i svar. Pull point ID, som blev returneret da pull point blev oprettet, er den sidste del af URL'en. F.eks. http://nas/pullpoint/0d7d7a08-b742-499f-b481-82b2f6d5dc83. Her er 0d7d7a08-b742-499f-b481-82b2f6d5dc83 pull point id.
- Udfør DGWS validering. Det vil sige id kort er valid, korrekt niveau af id kort osv.
- Med Pull Point ID som nøgle læses information om Pull Point alle subscriptions for det givne pull point og for hver subscription læses nyeste og næst nyeste nas_consumer. RRækkefølgen af nas_consumer bestemmes af subscription_serialnumber.
- For hver subscription der er læst fra databasen udføres nedenstående.
- Hent antal partitioner i Kafka for det Kafka topic den nuværende subscription handler om. Dette gøres via kald til partitionsFor metoden på den Kafka Consumer der anvendes. Argument til metoden er topic.
- Da antal partioner læst fra Kafka er det samme som det antal offsets der er læst fra databasen udvides listen ikke.
- For hver partition søges der frem til det offset der er angivet for den givne partition i listen med offsets.
- Kafka polles for beskeder. Det sikres at den samlede poll tid ikke overstiger den konfigurationsparameteren kafka.poll.max.time. Hvis delta mellem max. offsets på partitionerne i det topic der skal læses fra og der hvor subscription er nået til er større end kafka.poll.delta.max anvendes der kafka.poll.catchup.timeout som timeout til Kafka.poll. Dette sikrer at data hentes fra Kafka.
- Filtrering udfra den evt. ID liste der er tilknyttet på hash værdi niveau. Hash værdi for ID type og ID er gemt på hvert Kafka besked samt på ID listen i databasen.
- Filtrering på ID og ID type af hensyn til mulig hash kollision.
- Indsæt nye nas_consumer rækker i databasen. Der indsættes en række pr. subscription. Det næste serialnumber i sekvensen gives til den nye nas_consumer.
- Send svar til klient.
Kald hvor der ikke er nye adviser i Kafka
Scenarie hvor der siden sidste kald til GetMessages ikke er sendt nogle nye adviser til det topic der ønskes hentet adviser for.
- Kald til GetMessages operationen. Body består af maksimalt antal ønskede beskeder i svar. Pull point ID, som blev returneret da pull point blev oprettet, er den sidste del af URL'en. F.eks. http://nas/pullpoint/0d7d7a08-b742-499f-b481-82b2f6d5dc83. Her er 0d7d7a08-b742-499f-b481-82b2f6d5dc83 pull point id.
- Udfør DGWS validering. Det vil sige id kort er valid, korrekt niveau af id kort osv.
- Med Pull Point ID som nøgle læses information om Pull Point alle subscriptions for det givne pull point og for hver subscription læses nyeste og næst nyeste nas_consumer. Rækkefølgen af nas_consumer bestemmes af subscription_serialnumber.
- For hver subscription der er læst fra databasen udføres nedenstående.
- Hent antal partitioner i Kafka for det Kafka topic den nuværende subscription handler om. Dette gøres via kald til partitionsFor metoden på den Kafka Consumer der anvendes. Argument til metoden er topic.
- Da antal partioner læst fra Kafka er det samme som det antal offsets der er læst fra databasen udvides listen ikke.
- For hver partition søges der frem til det offset der er angivet for den givne partition i listen med offsets.
- Kafka polles for beskeder.
- Da der ikke returneres adviser fra Kafka er der heller ikke noget at foretage filtrering på.
- Indsæt nye nas_consumer rækker i databasen. Der indsættes en række pr. subscription. Det næste serialnumber i sekvensen gives til den nye nas_consumer. Selvom der ikke er returneret nye adviser fra Kafka og offsets dermed er det samme, så indsættes der stadig nye rækker. Dette gøres af hensyn til DGWS' krav om replayability samt at holde løsningen så simpel som muligt.
- Send svar til klient.
Kald hvor antallet af Kafka partioner er blevet udvidet siden sidste kald.
Scenarie hvor antallet af partitioner for det topic der hentes data fra er blevet udvidet. Det kan f.eks. være sket af hensyn til performance.
- Kald til GetMessages operationen. Body består af maksimalt antal ønskede beskeder i svar. Pull point ID, som blev returneret da pull point blev oprettet, er den sidste del af URL'en. F.eks. http://nas/pullpoint/0d7d7a08-b742-499f-b481-82b2f6d5dc83. Her er 0d7d7a08-b742-499f-b481-82b2f6d5dc83 pull point id.
- Udfør DGWS validering. Det vil sige id kort er valid, korrekt niveau af id kort osv.
- Med Pull Point ID som nøgle læses information om Pull Point alle subscriptions for det givne pull point og for hver subscription læses nyeste og næst nyeste nas_consumer. Rækkefølgen af nas_consumer bestemmes af subscription_serialnumber.
- For hver subscription der er læst fra databasen udføres nedenstående.
- Hent antal partitioner i Kafka for det Kafka topic den nuværende subscription handler om. Dette gøres via kald til partitionsFor metoden på den Kafka Consumer der anvendes. Argument til metoden er topic.
- Da antal partioner læst fra Kafka er større end det antal offsets der er angivet i nyeste nas_consumer tabellen udvides listen med offsets. Et offset er blot en numerisk værdi og en ny parition i Kafka starter altid ved 0.
- For hver partition søges der frem til det offset der er angivet for den givne partition i listen med offsets.
- Kafka polles for beskeder.
- Filtrering udfra den evt. ID liste der er tilknyttet på hash værdi niveau. Hash værdi for ID type og ID er gemt på hvert Kafka besked samt på ID listen i databasen.
- Filtrering på ID og ID type af hensyn til mulig hash kollision.
- Indsæt nye nas_consumer rækker i databasen. Der indsættes en række pr. subscription. Det næste serialnumber i sekvensen gives til den nye nas_consumer.
- Send svar til klient.
Kald hvor adviser er blevet slettet i Kafka
Nedenstående scenarie hvor beskederne i det Kafka topic der skal hentes adviser fra er blevet slettet på grund af alder. Det er en indbygget mekaniske i Kafka at beskeder slettes fra et topic efter et konfigurerbart interval.
- Kald til GetMessages operationen. Body består af maksimalt antal ønskede beskeder i svar. Pull point ID, som blev returneret da pull point blev oprettet, er den sidste del af URL'en. F.eks. http://nas/pullpoint/0d7d7a08-b742-499f-b481-82b2f6d5dc83. Her er 0d7d7a08-b742-499f-b481-82b2f6d5dc83 pull point id.
- Udfør DGWS validering. Det vil sige id kort er valid, korrekt niveau af id kort osv.
- Med Pull Point ID som nøgle læses information om Pull Point alle subscriptions for det givne pull point og for hver subscription læses nyeste og næst nyeste nas_consumer. Rækkefølgen af nas_consumer bestemmes af subscription_serialnumber.
- For hver subscription der er læst fra databasen udføres nedenstående.
- Hent antal partitioner i Kafka for det Kafka topic den nuværende subscription handler om. Dette gøres via kald til partitionsFor metoden på den Kafka Consumer der anvendes. Argument til metoden er topic.
- Da antal partioner læst fra Kafka er det samme som det antal offsets der er læst fra databasen udvides listen ikke.
- For hver partition søges der frem til det offset der er angivet for den givne partition i listen med offsets.
- Kafka polles for beskeder.
- Kafka Consumer klient kaster en OffsetOutOfRangeException. Dette betyder at det offset der forsøges polles fra ikke længere eksisterer i det angivne topic.
- Der søges frem til ældste offset i det pågældne topics og Kafka polles igen.
- Filtrering udfra den evt. ID liste der er tilknyttet på hash værdi niveau. Hash værdi for ID type og ID er gemt på hvert Kafka besked samt på ID listen i databasen.
- Filtrering på ID og ID type af hensyn til mulig hash kollision.
- Som konsekvens af at der tidligere er blevet kastet en OffsetOutOfRangeException laves der en system besked som en del af svaret. En system besked er kendetegnet ved at IsSytemNotification er true på NotifyContent.
- Indsæt nye nas_consumer rækker i databasen. Der indsættes en række pr. subscription. Det næste serialnumber i sekvensen gives til den nye nas_consumer.
- Send svar til klient.
2.5. IDList service
IDList Servicen har som ansvarsområde at udstille et endpoint, som anvendere kan bruge til at administrere ID lister.
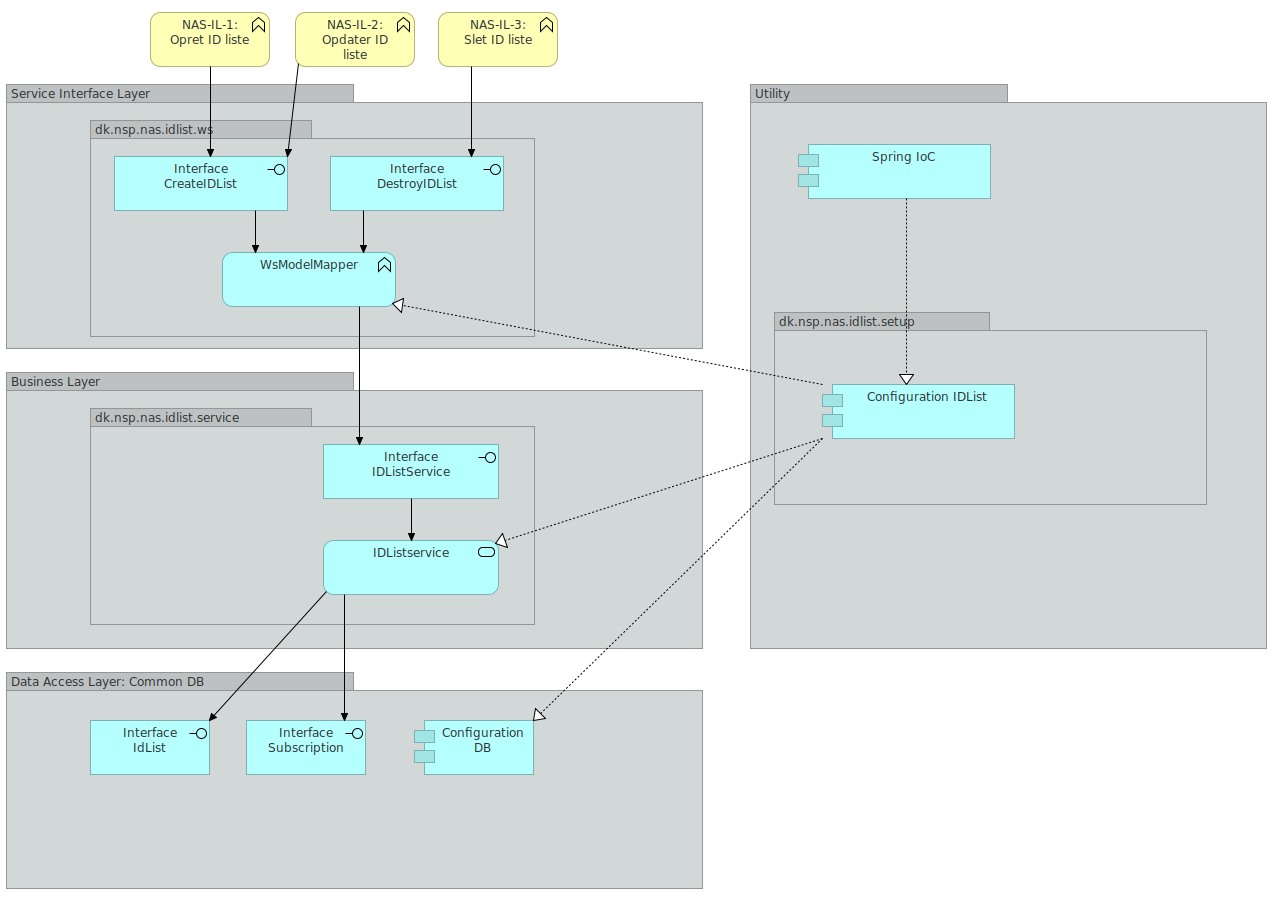
En ID liste er en liste over positive ID'er der skal hentes adviseringer for. IDList servicen udstiller to SOAP actions. En operation der hedder CreateIDList og en der hedder DestroyIDList. CreateIDList anvendes til både at oprette og opdatere en ID liste. Dette gøres ved at tjekke om en ID liste med det givne navn allerede findes.
IDList Servicen er inddelt i lag. Selve oprettelse og orkestrering af IDList Service komponenter varetages af en konfigurationskomponent. Denne konfigurationskomponent er også ansvarlig for at inkludere de relevante konfigurationer fra de delte komponenter, som IDList anvender: Det drejer sig om IDList, IDListContent og Subscription delene af databasekomponenten.
På ydersiden af IDList findes Service Interface: Dette lag er ansvarlig for at udbyde CreateIDList samt DestroyIDList SOAP servicene samt at foretage mapning ned i mod den model, der anvendes i forretningslaget i IDListService.
Forretningslaget indeholder forretningslogikken: IDList Service enten opretter, opdaterer eller nedlægger en id liste. En ID liste persisteres i databasen ved hjælp af kald til metoder i databaselaget.
2.5.1. User stories
I forhold til IDList Service er følgende user stories relevante:
...
2.5.2. Sekvensdiagram
Nedenstående 3 sekvensdiagrammer viser hvordan man henholdsvis opretter, opdaterer og sletter id lister. Hvert af de 3 sekvensdiagrammer er knyttet til en user story ved samme navn.
2.6. Subscription manager
Subscription Manager Servicen har som ansvarsområde at udstille et endpoint, som anvendere kan bruge til at oprette og nedlægge subscriptions.
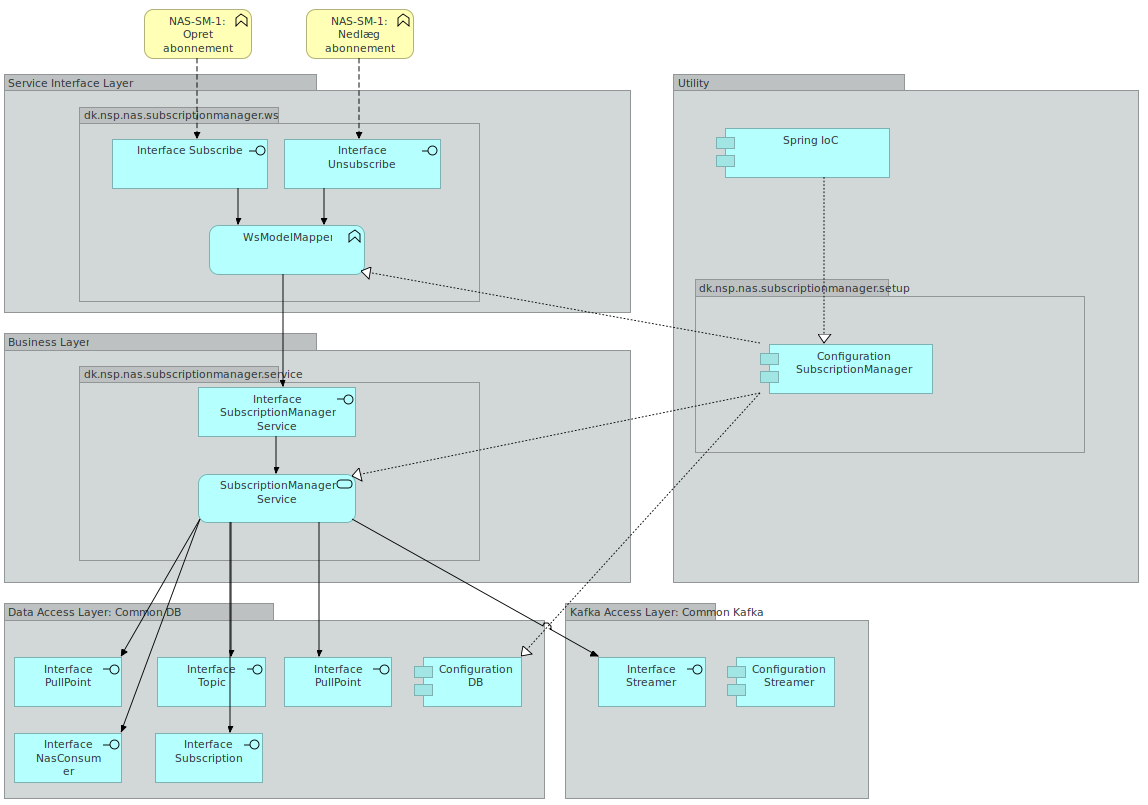
En subscription er et abbonnement på et topic hvor der kan være tilknyttet en id liste. Abonnementet er det der knytter et pull point og et topic sammen. Subscription manager servicen udstiller to SOAP actions. En operation der hedder Subscribe og en der hedder Unsubscribe. Subscribe anvendes til at oprette subscriptions. Unsubscribe anvendes til at nedlægge subscriptions.
Subscription Manager Servicen er inddelt i lag. Selve oprettelse og orkestrering af Subscription Manager Service komponenter varetages af en konfigurationskomponent. Denne konfigurationskomponent er også ansvarlig for at inkludere de relevante konfigurationer fra de delte komponenter, som Subscription Manager anvender: Det drejer sig om alle dele af database komponenten samt streamer delen af Kafka komponenten.
På ydersiden af Subscription Manager findes Service Interface: Dette lag er ansvarlig for at udbyde Subscribe samt Unsubscribe SOAP servicene samt at foretage mapning ned i mod den model, der anvendes i forretningslaget i SubscriptionManagerService.
Forretningslaget indeholder forretningslogikken: Subscription Manager Service enten opretter eller nedlægger en subscription. En subscription persisteres i databasen ved hjælp af kald til metoder i databaselaget.
2.6.1. User stories
I forhold til Subscription Manager Service er følgende user stories relevante:
...
2.6.2. Sekvensdiagram
Nedenstående 2 sekvensdiagrammer viser hvordan man henholdsvis opretter ned nedlægger subscriptions. Hvert af de 2 sekvensdiagrammer er knyttet til en user story ved samme navn.
2.7. Pullpoint Factory Service
PullPointFactory har som ansvarsområde at udstille et endpoint, som anvendere kan bruge til at oprette pullpoints.

Servicen er ligesom alle øvrige services inddelt i lag og opbygningen er identisk med PullPoint – se afsnit herom. Den eneste forskel er at PullPointFactory ikke anvender Kafka og dermed ikke har noget med Streamer interfacet at gøre.
2.7.1. User stories
I forhold til Pullpoint Factory Service er følgende user stories relevante:
...
2.7.2. Sekvensdiagram
Nedenstående sekvensdiagram viser hvordan man opretter pullpoints. Sekvensdiagrammet er knyttet til user story af samme navn.
2.8. Administration Service
Administration service har som ansvarsområde at udstille et REST endpoint til anvendelse af driften.

Dette endpoint kan anvendes til oprette topics, nedlægge topics osv. i NAS. Servicen er som de andre services i NAS2 lagdelt. Den adskiller sig dog fra de andre services ved at den ikke udstiller et SOAP WebService med DGWS. Derimod udstiller den et REST endpoint. Dette endpoint har ikke noget sikkerhedslag da det kun er udstillet til driften.
2.8.1. User stories
I forhold til Administration Service er følgende user stories relevante:
...
2.8.2. Sekvensdiagram
Nedenstående sekvensdiagram viser hvordan man opretter pullpoints. Sekvensdiagrammet er knyttet til user story af samme navn.
2.9. Cleanup Service
Cleanup Service kaldes for at starte et oprydningsjob, som sletter gamle rækker i databasen.
Følgende udføres ved cleanup:
- Gamle subscriptions slettes
- Gamle nasconsumers slettes
- De nyeste to for hver subscription beholdes, resten slettes i batches af 20.
2.10. Snitflader
NAS2 implementerer WS-Notification snitfladen. De operationer der er implementeret er beskrevet i NAS2 - Anvenderguide#Anvenderguide-Generelt dokumentet. De steder hvor der er implementeret yderlige validering eller restriktioner er disse også dokumenteret. Komplette WSDL'er vil blive tilgængelige på https://wsdl.nspop.dk/ når servicen er deployet til TEST2. I skrivende stund (2019-06-18) er det NAS1 WSDL'er og skemaer der er tilgængelige. Det skal dog nævnes at NAS1 og NAS2 implementerer samme snitflade.
2.11. Kafkamodul
* Hver kasse i ovenstående diagram har en kort forklaring, som kommer frem i et nyt browservindue, når der klikkes på kassen.
Kafkamodulet leverer en snitflad til kommunikation med Kafka. Under hjelmen anvends NSP Kafka Client library (se “Den gode brug af Kafka” (https://www.nspop.dk/display/public/web/Den+Gode+Brug+af+Kafka#DenGode-BrugafKafka-NSPKafkaClients).
Kafkamodulet er realiseret som et modul, som de konkrete NAS 2 services kan inkludere og anvende efter behov. Inkluderingen af kafkamodulet sker ved at aktivere een eller begge af kafkamodulets konfigurationskomponenter. Kafkamodulet tilbyder to konfigurationer til dens anvendere: Een til publishers og een til streamers.
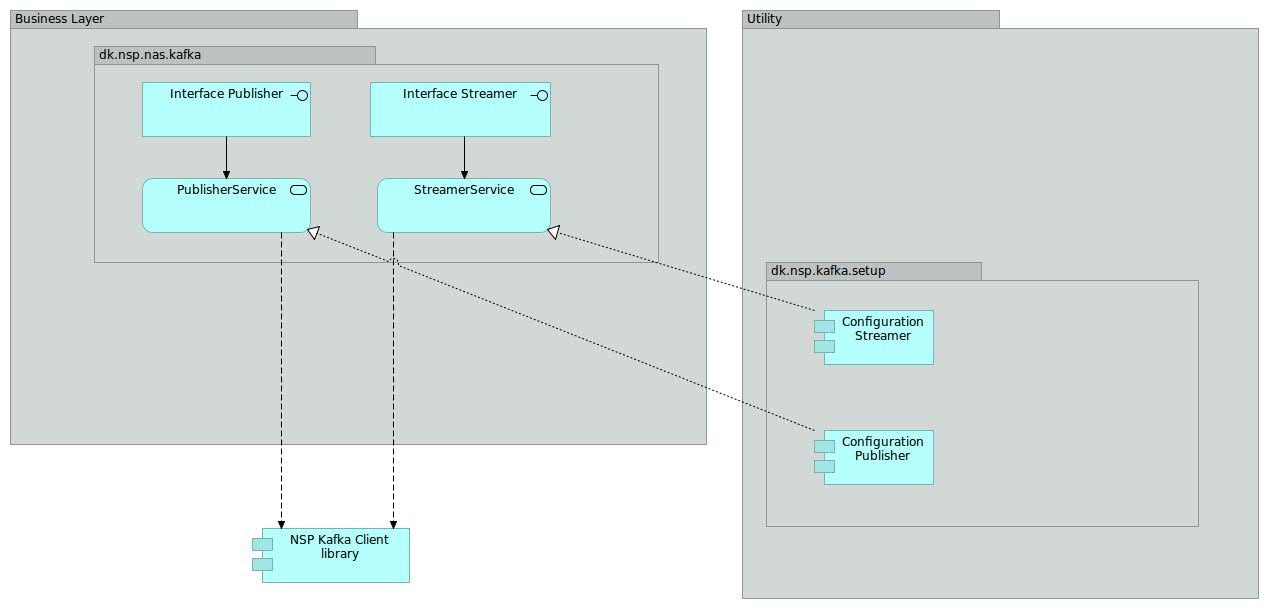
NAS 2 services tilgår kafka gennem kafkamodulets forretningslag interfaces. F.eks anvender NotificationBroker Publisher til at foretage publiseringen ned på et givent kafka topic.
2.12. Databasemodul
Alle NAS komponenter har brug for at tilgå og/eller administrere (dele af) den samlede datamodel for NAS 2. Som en del af NAS 2 komponenterne arbejdes der med et fællesmodul med services til læsning og skrivning af datamodellen.

Databasemodulet er realiseret som et modul, som de konkrete NAS 2 services kan inkludere og anvende efter behov. Inkluderingen af databasemodulet sker ved at aktivere databasemodulets konfigurationskomponent.
NAS 2 services tilgår datamodellen gennem forretningslagets interfaces. F.eks anvender NotificationBroker TopicMapping til at validere af det indkommende NAS topic og mapning ned til internt (kafka) topic. Andre services tilgår andre dele af databasemodellen via de udbudte interfaces (se blueprint ovenfor).
Det følgende diagram viser hvilke NAS2 komponenter, der tilgår hvilke services i database modulet. Det skal bemærkes at idlist dækker over både idlist og idlistcontent.
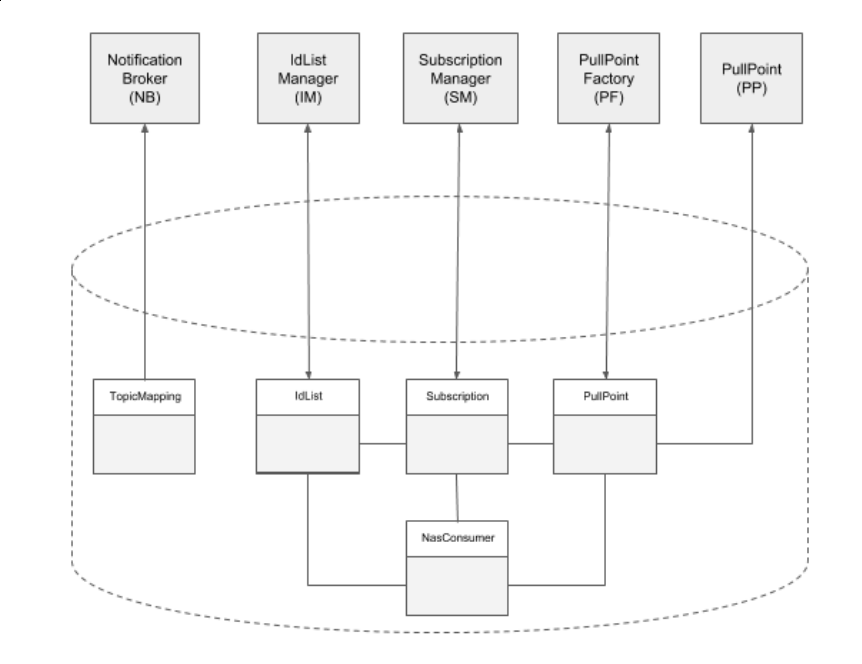
2.12.1. Database model
* Hver kasse i ovenstående diagram har en kort forklaring, som kommer frem i et nyt browservindue, når der klikkes på kassen.
Til den følgende model, er der taget udgangspunkt i databasemodellen fra NAS 1.x. Umiddelbart er der dog ingen grund til at have flere database schema, så som der tidligere har eksisteret.
2.12.2. Topic mapning
Der skal være muligt at mappe topics indeholdt i notifikationer til Kafka topics. Denne 1-til-1 mapning er givet ved følgende tabel:
Eventuelle metadata-informationer såsom f.eks. hvem der har oprettet topic kan tilføjes metadata kolonnen. Metadata kolonnen vil blive gemt som JSON og dermed kan den udvides med ekstra værdier efter behov. Disse felter vil som udgangspunkt ikke blive læse i servicen og dermed er servicen heller ikke afhængig af hvad der står i metadata kolonnen.
2.12.3. Topic Access
For at oprette et abonnement på et Topic eller hente beskeder/notifikationer for et Topic, skal klienten have adgang til det specifikke Topic. Adgangen til Topics gives i følgende tabel:
Hvordan identifier udfyldes, kan ses i driftsvejledningen.
2.12.4. Pullpoint
Et pullpoint modelleres til persistering af bla. ejerskab af et pullpoint.
2.12.5. Nas Consumer Rollback
For alle topics gemmes offsets med mellemrum. Dette gøres for at understøtte muligheden for at spole en given subscription tilbage til et givent tidspunkt. Offsets gemmes i tabellen nas_consumer_rollback.
2.12.6. Offset håndtering
Når en klient henter beskeder/notifikationer på et pullpoint, skal der fortsættes fra der hvor klienten sidst slap. Denne information gemmes i nasConsumer i offset, som allerede beskrevet. Det kræver dog en mindre forklaring. Det er nemlig ikke blot eet offset, men en samling af flere offsets, der gemmes. Dette skyldes den måde Kafka clusteret bedst muligt udnyttes på. Når en besked afleveres til Notification Broker, vil den blive givet videre til Kafka clusteret og blive gemt i en af de partitioner, der er konfigureret. Der er skal som minimum være opsat det antal partitioner for et topic, som der er noder i clusteret.
Beskeder vil blive uniform fordelt til partitioner tilhørende et topic. Når beskeder skal hentes ud igen, skal en Kafka consumer, altså Pullpoint servicen, sættes op sådan, at den henter fra samtlige partitioner for et givet topic. Der skal hentes ud fra det offset, der er gemt for den pågældende subscription og partition. Når tilstrækkelige beskeder er hentet og der skal returneres til klient, gemmes nye offsets til den efterspurgte subscription i databasen igen.
Måden offsets gemmes på er i en "liste" i offset i nasConsumer. Da dette dog kun er en streng, skal der vælges passende formattering. Dette simplificeres af at partitioner altid angives med tallene fra 0 og opefter. En komma-separeret liste vil derfor være tilstrækkelig.
2.12.7. Abonnementer
For at data kan leveres til et pull point skal der være et eller flere abonnementer (Subscription). En subscription relaterer sig til et PullPoint og en række offsets (NasConsumer) og en evt. id list (IdList). NasConsumer er en representation af hvor langt en consumer er nået samt identifikation af seneste kald. Identifikation af seneste kald er nødvendig for at overholde DGWS krav omkring at gensende seneste svar. Hvor langt en consumer er nået er blot en tekststreng og så er det op til Kafka at fortolke denne tekststreng. Dette er med til at sikre en afkopling mellem det underliggende system til at gemme beskeder og forretningslogikken. NasConsumer er modelleret så der udelukkende læses og indsættes rækker i tabellen. Når seneste offset skal hentes, så er det blot nødvendigt at læse nyeste række for den subscription, der er tale om. Der er ikke brug for at opdatere eksisterende rækker. Dette betyder også, at det løbende skal ryddes op, så gamle rækker fjernes. Dette håndeteres i Cleanup Service.
IdList og tilhørende IdListContent er en representation af det eventuelle filter der er på en subscription. Det vil sige at det er en filtrering af beskeder til en given subscription.
3. Designmålsætninger og -beslutninger
kvalitetsattributter:
modificerbarhed
skalerbart, flaskehalse, ingen single point of failure
vi laver en liste over hvad vi har fokus på - en checkliste vi anvender til at følge op
3.1. Designbeslutninger
3.1.1. Autentificeringsmetode for NotificationBroker
Spørgsmål: I sin nuværende (NAS1) udgave anvender NotificationBroker ikke DGWS til autentificering af indkommende requests. I stedet anvendes IP whitelisting. Skal dette også være således i NAS2, eller skal NotificationBroker anvende DGWS ligesom de andre NAS komponenter.
Overvejelser: Man kunne lave NotificationBroker i to udgaver (een med og een uden DGWS). Problemet er, at FMK i dag anvender snitfladen uden DGWS, og vil skulle gøre noget andet, hvis NotificationBroker pludselig bruger DGWS. Yderligere er der en forventning om, at IDWS kommer (også for NAS), så en ændring måske vil være spildt.
Beslutning: NotificationBroken anvender IP whitelisting som i dag - også i NAS2.
3.1.2. Topic mapping fra topic til internt topic (Kafka topic)
Leverandør synspunkter i forhold til om konvertering fra topic til internt topic skal være database baseret eller en konfigurerbar regel.
3.1.2.1. Database baseret
Fordele
- Man er ikke begrænset af at et givent Kafka topic får et bestemt navn i forhold til det topic man mapper fra.
- Når man skal validere om NotifyBroker Subscription Manager kaldes med et valid topic er det nemt at validere ved blot at lave et enkelt opslag i databasen.
- Det vil være muligt at nedlægge et topic i to skridt. Det skal forstås på den måde at man først kan slette topic fra databasen. Så vil det ikke længere være muligt at kalde NotifyBroker på det givne topic. Derefter vil subscribere have X antal dage til at få hentet alle data og så kan topic nedlæggges i Kafka.
Ulemper
- Man skal sikre sig at både internt topic er oprettet i både Kafka og mappings tabellen.
3.1.2.2. Konfigurerbar regel
Fordele
- Når man skal oprette et nyt topic skal dette kun gøres i Kafka.
Ulemper
- Når det skal valideres om NotifyBroker og Subscription Manager kaldes med et validt topic er der ikke nogen nem måde at gøre dette på. Umiddelbart kan man kun spørge efter alle topics i Kafka clustered og det må antages at dette er dyrere end at lave et enkelt opslag i en database.
- Man binder sig på én bestemt mapping fra topic til Kafka topic. Dette kan give problemer hvis man ønsker at oprette et bestemt topic og Kafka ikke understøtter dette navn.
- Driften har særlig navnekonvention i forhold til opretteles af topics. Denne er ikke som udgangspunkt compliant med NAS Topics opbygning, hvorfor der skal defineres og vedligeholdes en mapningsalgoritme
3.1.2.3. Alternativ model skitseret på Kommentarer til NAS 2.0 Design og Arkitekturbeskrivelse
Beslutning: Der anvendes mapping tabel. Roadmap opgave er registreret til at automatisere oprettelse af data i mapping tabel, topic i kafka osv.
3.1.3. Kafka modul (Arosii)
Herunder findes beskrivelse af design omkring håndtering af nogle af brugsscenarier ifht. brugen af Kafka.
3.1.3.1. Offset håndtering og normal hentning
Når en klient henter beskeder/notifikationer på et pullpoint, skal der fortsættes fra der hvor klienten sidst slap. Denne information gemmes i nasConsumer i offset, som allerede beskrevet. Det kræver dog en mindre forklaring. Det er nemlig ikke blot eet offset, men en samling af flere offsets, der gemmes. Dette skyldes den måde Kafka clusteret bedst muligt udnyttes på. Når en besked afleveres til Notification Broker, vil den blive givet videre til Kafka clusteret og blive gemt i et af de partitioner, der er konfigureret. Der er skal som minimum være opsat det antal partitioner for et topic, som der er noder i clusteret.
Beskeder vil blive uniform fordelt til partitioner tilhørende et topic. Når beskeder så skal hentes ud igen, skal en Kafka consumer, altså Pullpoint servicen, sættes op sådan, at den henter fra samtlige partitioner for et givet topic. Der skal hentes ud fra det offset, der er gemt for det pågældende pullpoint og partition. Når tilstrækkelige beskeder er hentet og der skal returneres til klient, gemmes nye offsets til det efterspurgte pullpoint i databasen igen.
Måden offsets gemmes på er i en "liste" i offset i nasConsumer. Da dette dog kun er en streng, skal der vælges passende formattering. Dette simplificeres af at partitioner altid angives med tallene fra 0 og opefter. En komma-separeret liste vil derfor være tilstrækkelig.
3.1.3.2. For sent hentning af beskeder
Når beskeder har ligget på Kafka i tilpas lang tid vil de blive slettet. Dette skal konfigureres sammen med topic. For klienter betyder dette at hvis de ikke beskeder hentes ud i tide, vil de blive slettet. I pullpoint servicen vil dette blive håndteret på den måde at offsets rundes op til starten af tilhørende partitioner.
3.1.3.3. Fjerne partitioner
Kafka understøtter ikke at fjerne partitioner. Derfor er det heller ikke noget NAS skal forholde sig til.
3.1.3.4. Udvidelse af antal partitioner
Hvis et topic oplever meget trafik, så er det mulig tilføje yderligere partitioner. Denne udvidelse vil betyde at beskeder også skal hentes ud fra disse nye partitioner, når en klient igen forespørger på et pullpoint. Dette vil ske transparent i Kafka modulet, da der her altid checkes for antallet af partitioner for det givne topic. Offset for disse nye partitioner vil starte på 0.
3.1.3.5. Oprettelse af subscribers (initiering af offset)
Når en subscription oprettes bliver der også oprettet en speciel række i nasConsumer, som ikke indeholder noget messageId. Denne række skal indeholde de aktuelle offsets for det tilhørende topic. Disse findes vha. Kafka modulet.
Beslutning: Ovenstående er blot en beskrivelse af brugen af Kafka og dermed ikke nogen reel beslutning.
3.1.4. Databasemodel i forhold til PP (KIT)
I forhold til modelering af NasConsumer anbefales der at lave en databasemodel hvor der kun indsættes nye rækker. Det vil sige den bliver lidt mere event orienteret i og med at det er nye events der indsættes i databasen. Det giver nogle umiddelbare fordele og ulemper.
Fordele
- DGWS krav om at kunne gensende tidligere svar opfyldes nemt da historik over tidligere offset og antal beskeder i svar bibeholdes i databasen.
- Antallet af låsninger i databasen minimeres da man ikke skal låse eksisterende rækker i forbindel.
- I og med der ikke skal opdateres rækker giver det en lidt simplere kode.
Ulemper
- Hvis der ikke ryddes op i databasen, så vil data mængden blive ved med at vokse. Derfor skal der laves oprydning af tabellen.
3.1.4.1. Offset håndtering i databasen
Offsets i Kafka er reelt set blot en kommasepareret liste med offsets. Første værdi er offset for partition 0, anden værdi er offset for partition 1 osv. I databasen gemmes blot blot en "blob" og denne blob gives som parameter til Kafka modulet og det er Kafka modulet der så splitter den kommaseparerede liste. Når beskeder skal hentes via GetMessages tjekkes der først hvor mange partitioner der er for det Kafka topic der skal hentes data fra. Hvis der er det samme antal partitioner i Kafka som det der er gemt i databasen så læses hver partition blot og de nye offsets gemmes i databasen. Hvis der er flere partitioner end den offset blob der er gemt i database, så er det fordi der er tilføjet yderlige partitioner og disse skal også læses. Offset starter altid ved 0 og derfor læses de partitioner der ikke er offset for i databasen fra offset 0. Alle de nye offsets gemmes i databasen. Næste gang GetMessages kaldes vil antallet af offsets i databasen så igen passe med det antal partitioner der findes i Kafka. Da det ikke er muligt at fjerne partitioner for et Kafka topic så er det ikke et scenarie der håndteres. Hvis der alligevel er færre partitioner i Kafka end der er offsets i databasen returneres en alvorlig fejl.
3.1.4.2. Alternative løsninger
Løsning 1
Nedenstående er umiddelbare fordele og ulemper i forhold til den model der er foreslået under punkt 2.6.5.
Fordele
- Databasen er delt mere logisk op i forhold til funktionalitet
Ulemper
- Da vi kun indsætter data i tabellerne SubscriptionState og KafkaState så er det svært at afgøre hvilken række i de to tabeller der relaterer sig til hinanden.
- En lidt dyrere løsning performance mæssigt da der skal læses en tabel ekstra hver gang et pull point kaldes.
Løsning 2
...
Nedenstående er umiddelbare fordele og ulemper i forhold til den model der er foreslået under punkt 2.6.5.
Fordele
- Databasen er delt mere logisk op i forhold til funktionalitet
- Der er en direkte relation mellem tabellerne SubscriptionState og KafkaState og dermed kan man nemt se hvilken subscription state og kafka state der relaterer sig til hinanden.
Ulemper
- En lidt dyrere løsning performance mæssigt da der skal læses en tabel ekstra hver gang et pull point kaldes.
Beslutning: Model beskrevet under punkt 2.6.5 anvendes.
3.1.4.3. Aflevering af notifikationer til Kafka
Requests mod notification broker kan indeholde et eller flere notifikationer. Disse notifikationer skal enten alle leveres videre Kafka eller ingen i tilfælde af fejl. Aflevering af kun nogle af de modtage notifikationer til Kafka er problematisk. De problematiske situationer kan yderligere begrænses til fejl ved kommunikation til Kafka. Validering af notifikationerne samt hentning af metadata fra databasen vil ske før Kafka kontaktes og er derfor ikke umiddelbart problematiske; disse er derudover også blot læse operationer.
Umiddelbart er der 2 måder at håndtere dette på:
- lade klienten vide at kun nogle beskeder er blevet gemt i Kafka og lade det være op til klienten at bestemme hvad der så skal gøres.
- anvende transaktioner ifht. levering af beskeder til Kafka. Hvis afleveringen på et tidspunkt fejler, vil ingen beskeder dermed blive gemt i Kafka og klienten kan roligt forsøge requestet igen.
I NAS 1.x anvendes transaktioner, hvorfor tilsvarende opførsel som beskrevet i 2 forefindes.
Løsning 1 har nogle problemer:
- ændring af semantikken af snitflade ifht. NAS 1.x
- ændring af snitflade ifht. WS-notification (ikke direkte undersøgt, men der findes ikke umiddelbart måder at fortælle klienten at kun nogle beskeder er blevet gemt)
Løsning 2 har ikke disse problemer, men vil afkræve yderligere ressourcer af Kafka. Det tyder umiddelbart på at performance ikke (betydeligt) er påvirket af introduktionen af transaktioner – dette er dog ikke testet.
Beslutning: Jvf. diskussion på Slack er det besluttet at der skal returneres en exception til kalder med information om hvilke beskeder der ikke kunne afleveres.
3.1.5. Forskelle mellem WS-Notification og NAS2
WS-Notification er en familie af standarder bestående af:
- WS-BaseNotification 1.3 OASIS Standard
- WS-BrokeredNotification 1.3 OASIS Standard
- WS-Topics 1.3 OASIS Standard
NAS2 har til opgave (prioriteret rækkefølge):
- At udstille de samme snitflader som NAS1.
- At implementere WS-Notification
Prioriteringen ovenfor medfører, at NAS2 på visse punkter afviger fra WS-Notification standarden. Det følgende afsnit beskriver de væsentligste af disse afvigelser. Generelt henvides der til for anvenderguiden for detaljeret snitflade dokumentation af de områder hvor NAS2 implementerer yderlige begrænsninger af WS-Notification snitfalden.
3.1.5.1. WS-BrokeredNotification og WS-Topicsde beskrivelsede beskrivelse
NAS1 implementerer ikke noget fra WS-BrokeredNotification og WS-Topics. Derfor er der heller ikke implementeret noget fra disse to standarder i NAS2.
3.1.5.2. Format af notifikationspayload
Data i en Notification er domæne-specifik og ikke defineret som en del af WS-BaseNotification. NAS2 foreskriver (ligesom NAS1) at indholdet af en Notification skal være af typen NotifyContent. Dette er således en indskrænkning af WS-BaseNotification. Denne indskrænkning er ikke begrænsende, da NotifyContent igen kan indeholde hvad som helst (Any).
3.1.5.3. Push-style notificeringer
I følge WS-BaseNotification er det muligt for aftagere af notifikationer at oprette deres abonnement med en push-style semantik. Abonnenter giver en URL (endpoint), hvorpå NotificationBroker kan sende notificeringer (push). Specifikationen nævner en række tilfælde, hvor denne push mekanisme ikke er passende: "For example, certain NotificationConsumers are behind a firewall such that the NotificationProducer cannot initiate a message exchange to send the Notification. A similar circumstance exists for NotificationConsumers that are unable or unwilling to provide an endpoint to which the NotificationProducer can send Notification Messages. In other situations, the NotificationConsumer prefers to control the timing of receipt of Notification Messages, instead of receiving Notification Messages at unpredictable intervals, it may prefer to “pull” retrieve the Notification Messages at a time of its own choosing."
Hverken NAS1 eller NAS2 tilbyder denne type push notificeringer.
3.1.5.4. Ikke implementerede operationer
Nedenstående er en liste over de operationer der er defineret i WS-BASeNotification der IKKE er implementeret. Dette skyldes at disse heller ikke er implementeret i NAS1.
- ResumeSubscription fra PausableSubscriptionMabager
- PauseSubscription fra PausableSubscriptionMabager
- Unsubscribe fra PausableSubscriptionMabager
- Renew fra PausableSubscriptionManager
- GetCurrentMessage fra NotificationProducer
3.1.6. Poll timeout mod Kafka
Når der skal læses data fra Kafka sker det via et klient bibliotek. Når data skal læses sker det ved kald til KafkaConsumer.poll(timeout). Poll metoden returnerer så snart der er læst data fra Kafka eller timeout perioden er gået. Når poll kaldes, og der er data tilgængelig i Kafka, er der ingen garanti for at alle beskeder på et givent topic returneres. Der returneres blot et antal af beskeder. Man skal så kalde gentagende gange for at læse alle beskeder fra et givent topic. Hvis timeout sættes til 0 eller en meget lav værdi, så kan Kafka klient biblioteket ikke nå at hente data fra Kafka inden timeout perioden er gået og så er der ikke nogen garanti for at data på noget tidspunkt bliver hentet fra Kafka.
Nuværende NAS2 logik
Nedenstående er groft sagt den logik der er omkring selve kaldet til poll(timeout) i NAS2. Timeout har været konfigureret til enten 0 eller et lavt antal milisekunder.
- Poll(timeout) kaldes.
- returneres der 0 beskeder så returneres der til kalderen.
- Er det totale antal af beskeder hentet fra Kafka større end det maksimum brugeren ønsker, så returneres der til brugeren.
- Gå til step 1
Med ovenstående logik så bliver poll(timeout) kaldt indtil der er læst nok beskeder fra Kafka eller poll(timeout) returnerer 0 beskeder. Det vil i langt de fleste tilfælde være timeout situationen der indtræffer først. Det betyder også at alle kald til GetMessages operationen har en svartid på minimum timeout værdien. Derfor har det også været ønsket at timeout skal være så lav som muligt. Det betyder at der er oplevet situationer hvor alle beskeder ikke er returneret til kalderen da timeout har været så lav at beskeder ikke er blevet læst fra Kafka.
Løsningsforslag
Nedenstående er to løsningsforslag til at løse problematikken hvor alle beskeder ikke når at blive læst ud fra Kafka på grund af for lav timeout.
Forhøje timeout
Forhøje timeout mod Kafka til 1 sekund. Efter en del test virker det stabilt at sætte timeout til 1 sekund når poll(timeout) kaldes.
Fordele
- Der skal ikke ændres i logik da det blot er en konfigurationsparameter der skal ændres.
- Der tilføjes ikke yderlige kompleksitet i koden.
Ulemper
- Alle kald til GetMessages får en svartid på minimum et sekund.
- Hvis en timeout på et sekund ikke er nok får vi ikke nogen form for alarm. Dog anses det ikke sandsynligt at der er i normal situationer er svartider på mere end et sekund fra Kafka. Tænkte situationer hvor det kunne ske er voldsom belastning af Kafka cluster, netværksproblemer eller meget lange svartider fra disk system. I alle disse tilfælde bør det dog være noget der skal håndteres på anden måde.
Ændre logik
Logikken omkring afhentning af beskeder fra Kafka ændres som beskrevet nedenfor.
- KafkaConsumer.endOffsets(partitions) kaldes for at finde seneste offsets for det topic der skal læses data fra.
- Seneste offsets sammenlignes med de offsets vi skal læses data fra.
- Hvis seneste offsets er lig eller mindre end der hvor vi skal læse data fra, så returneres der til kalder.
- Poll(timeout) kaldes med en passende timeout. Det kan f.eks. være et sekund.
- Hvis offsets for de returnerede beskeder er større eller lig de offsets fremfundet i step 1 returneres hentede data til kalder.
- hvis poll(timeout) ikke returnerede data betyder det at vi har ramt timeout, men vi ved at der er data i Kafka. Returner fejl til kalder.
- Gå til Step 3.
Fordele
- Vi kan logge og fortælle kalder hvis vi rammer timeout på poll metoden selvom der er data i Kafka.
- Svartider kan holdes på et minimum da vi kun rammer timeout i tilfælde af fejl.
Ulemper
- Der tilføjes øget kompleksitet til koden.
3.1.7. Udvidet poll timeout ved kald til Kafka når subscription er bagud
Ifm at anvenderne er skiftet fra NAS1 til NAS2 er det blevet tydeligt at den algoritme som NAS bruger til at kalde Kafka med ikke altid er optimal. Hvis en subscription er kommet bagud har anvenderne meget svært ved at indhente afsenderne. Det ser du til at den lave default timeout til poll kaldet gør at Kafka ofte returnerer 0 beskeder, hvilket får algoritmen til at tro den har nået enden af streamen og derfor stopper med at spørge.
Vi ønsker derfor 2 ændringer indført i Streamer implementationen:
Vælge poll strategi baseret på offsets
Vi ønsker at de endOffsets der læses i initConsumer metoden returneres herfra og gives med som input til KafkaIterator klassen. Denne kan derved bruge disse til at afgøre om subscriptionen er bagud i forhold til en ny property (kafka.poll.delta.max) og hvis dette er tilfældet vælge at anvende en ny poll metode der er mere aggressiv.
Den nye metode skal anvende en anden konfigurerbar poll timeout (kafka.poll.catchup.timeout) når den kalder Kafka. På den måde vil kun de subscriptions der er bagud belaste svartiderne.
Afslut iterator baseret på samlet svartid
Metoden hasNext() i klassen KafkaIterator skal anvende en ny konfiguration (kafka.polls.max.time) til at afgøre hvor længe de samlede kald til poll() metoden i Kafka må tage. Hvis tiden er overskredet skal metoden returnerer false så vi ikke får timeouts i loadbalancher mv.
Fordele
- Anvender kan indhente det den er bagud
Ulemper
...