1. Indledning
Indeværende side tjener som guide til udvikling af fremtidige stamdataindlæsere, som skal udvikles i henhold til referencearkitekturen. Som udgangspunkt er denne guide den samme for enhver stamdataindlæser, hvorfor den ligger under referencearkitektur. Under den tilsvarende Guide til udviklere for en konkret stamdataindlæser, vil der derfor altid refereres til nærværende side, og kun i de tilfælde, hvor noget supplerende specifikt for den pågældende stamdataindlæser er nødvendigt, vil dette skrives under den konkrete stamdataindlæsers Guide til udviklere.
Referencearkitekturen har til formål at skabe et fælles grundlag for en modernisering af eksisterende og kommende stamdataindlæsere. Den gør dette ved at fastlægge de strukturer, metoder og paradigmer som anvendes ved udvikling af en stamdataindlæser, og som sammen sikrer en fælles forståelse for strukturen og opførslen af en stamdataindlæser. Betydningen er dels at der sker en modernisering af de eksisterende stamdataindlæsere, men også at fremtidig vedligehold vil være mere effektiv da stamdataindlæsere vil være bygget på et fælles fundament.
1.1. Formål
For at validere den definerede referencearkitektur, er der udviklet en enkelt stamdataindlæser som proof of concept: Stamdataindlæser for Yder data.
Implementeringen af Yder stamdataindlæseren anvender alle elementer i referencearkitekturen, og derved kan den bruges som referencepunkt for implementering af andre stamdataindlæsere.
I denne guide vil kommende udviklere af stamdataindlæsere kunne se, hvordan de griber opgaven an, når en ny eller eksisterede stamdataindlæser skal udvikles efter referencearkitekturens principper.
1.2. Sammenhæng med øvrige dokumenter
Denne guide beskriver udvikling af en stamdataindlæser med udgangspunkt i den definerede referencearkitektur. Det forventes at læseren er bekendt med denne referencearkitektur, herunder begreber og principper der anvendes i stamdataindlæsere.
1.3. Læsevejledning
Læseren forventes at have kendskab til Java softwareudvikling med anvendelse af Maven, WildFly, Flyway, Docker, og Apache Camel (i det efterfølgende benævnt som Camel).
1.4. Introduktion til Stamdataindlæsere
Stamdataindlæsere er en central del af SDS's udstilling af stamdata til aftagere der anvender disse data.
SDS vedligeholder flere stamdatakopiregistre, hvor der for hvert af disse findes en specialiseret stamdataindlæser dedikeret det pågældende register, som sørger for, at de dataudtræk, der modtages fra forskellige kilder, indlæses og skrives til en database, hvorfra aftagere på en veldefineret måde kan hente de ønskede data.
Som beskrevet i referencearkitekturen, er det ønsket, at den enkelte stamdataindlæser skal sikre et højt kvalitetsniveau af data, så eventuelle fejl i de modtagne udtræk er sorteret fra, inden de når aftageren.
2. Opsætning af udviklingsmiljø
Koden til stamdataindlæsere kan findes i SVN i denne placering
Bemærk at stamdataindlæserene benytter sig af et fælles-modul, der findes her:
2.1. Krav til software
Krav til applikationsserveren og operativsystemet er de samme som til produktionsmiljøet. De specifikke krav kan ses i https://www.nspop.dk/display/public/web/Husregler+for+udvikling+til+NSP
Derudover er der en række krav til de anvendte udviklingsværktøjer:
Maven 3.0.3 eller højere anvendes.
Ud over dette er det et krav, at man har docker installeret lokalt, og kan køre docker for linux (hvis man er på windows).
Bemærk at stamdataindlæserne typisk benytter docker også til test (se test-afsnit senere i dette dokument).
2.2. Bygge Docker images
Stamdataindlæserene køres og testes ved brug af docker containere, som bygges i jenkins-pipelines.
For detaljer refereres til NSP Continuous Integration & Delivery som beskriver dette nøjere.
3. Afvikling
Stamdataindlæserene er Camel baserede java applikationer, som kan køres lokalt enten direkte eller via samme JBoss Wildfly docker containere, som der køres i test og produktion.
3.1. Udviklers arbejdsstation
Lokalt vil der typisk arbejdes ud fra kørsel af unittests (se nedenstående afsnit om unittest), og ellers ved at køre development docker-compose filen <projekt>/compose/development/docker-compose.yml.
Herved vil det meste udvikling blive udført ved kontinuert kørsel af unittests, og når helheder skal testes, kan man starte develoment docker-compose filen, eller køre integrationstestene (se nedenstående afsnit om integrationstests).
En typisk terminal kommando, her eksemplificeret for yderindlæseren, for at bygge en indlæser, og starte development docker-compose er som følger:
|
Denne bygger projektet, stopper og fjerner eventuelle gamle docker-containere, bygger nye og starter det igen.
3.2. Continous Integration & Delivery
CI/CD foregår ud fra NSP's vejledninger herom NSP Continuous Integration & Delivery.
Der eksisterer for stamdataindlæsere følgende byg
3.2.1.1. Build
Til hver indlæser oprettes et jenkins-byg, ved navn <indlæser>_Build som bygger koden, kører unittests og bygger det docker-image som danner indlæseren.
Dette byg bestemmes ud fra den Jenkinsfile der ligger i projektet (se fx. https://svn.nspop.dk/svn/importers/yderindlaeser/trunk/Jenkinsfile for yderindlæseren).
Koden bygges i et NSPBUILDER docker image, og unittests køres (mvn test).
Herefter bygges der et dockerimage ud fra den byggede war-fil. Dette gøres ud fra Dockerfile filen i projektet (se fx. https://svn.nspop.dk/svn/importers/yderindlaeser/trunk/Dockerfile for yderindlæseren)
Idet der benyttes testcontainers for at køre tests med en rigtig mariadb docker container, er det nødvendigt at det benyttede NSPBUILDER image understøtter docker. (for yderindlæseren er det pr. februar 2020 imaget registry.nspop.dk/platform/nspbuilder:jdk8-slim som benyttes til dette på jenkins-dev.nspop.dk jenkinsserveren).
3.2.1.2. integrationstest
Som et sidste trin i jenkins-bygget, vil det byggede docker-image med indlæseren blive startet op via docker-compose, og indlæserens integrationstests vil afprøve indlæseren udefra. Dvs. integrationstests vil lægge en fil klar til indlæseren, vente på den bliver færdig og se at de indlæste elementer findes i databasen samt kan hentes korrekt fra de nødvendige aftagerkomponenter som SKRS (stamdatakopiregisterservice).
Denne test giver en automatisk validering af de tilhørende komponenter til en indlæser som ellers hurtigt kan blive glemt.
4. Beskrivelse af systemdesign
De paradigmer der ligger til grund for designet er jf. referencearkitekturen:
- Vi ønsker, at en stamdataindlæser skal sikre en så høj datakvalitet som muligt, så aftagerne af stamdata kan forvente at de data de modtager lever op til forudsætninger om konsistens, typer og længder.
- Vi ønsker, at en stamdataindlæser skal indlæse så meget data som muligt, så vi tillader at dele af de modtagne data indlæses mens andre, fejlbehæftede, dele ikke indlæses.
I tilfælde af at dele af filen ikke lever op til forudsætningerne, skal stamdataindlæseren tydligt gøre opmærksom på hvilke data, der er berørt samt deres placering i de modtagne data, så en efterfølgende fejlfinding kan foretages så nemt som muligt. - Hvor en stamdataindlæser behandler forskellige typer af sammenknyttede entiteter, vil vi internt gruppere disse entiteter i en event. Denne interne repræsentation i events giver dels det fundament der understøtter ønsket om at skrive så meget data som muligt under bevarelsen af data-konsistensen og dels en mulighed for at distribuerer data i konsistente klumper.
- Da den overordnede funktionalitet på tværs af stamdataindlæsere er den samme, ønsker vi en komponent baseret implementering, så det er tydeligt hvor og hvornår en given funktionalitet udføres under behandlingen af modtagne data
- For at undgå dublering af kode skal fælles funktionalitet, der anvendes på tværs stamdataindlæsere, lægges i fælles bibliotek
4.1. Overordnet design
For at imødekomme den komponentbaserede tilgang, er stamdataindlæserne designet omkring en pipeline, som orkestrerer de komponenter, der tilsammen udgør implementeringen af en stamdataindlæser for et givent register.
Pipelinen er baseret på Apache Camel, der er en open source implementering af Enterprise Integration Patterns (EIP), herunder Pipe and Filter som er velegnet til at styre denne type af funktionalitet.
De logiske komponenter som pipelinen orkestrerer for en given stamdataindlæser, forventes at være ensartede på tværs af stamdataindlæserene, og de består af:
- Modtag datasæt
- Indlæs datasæt
- Validering af datasæt
- Parsning af datasæt til events
- Validering af events
- Berigelse af events med metadata
- Duplet filter
- Levering af events - persistering af de rå events og de indeholdte entiteter i databasen
- Logning
- Backup af fil
Rækkefølgen af komponenterne i pipelinen er vist her:
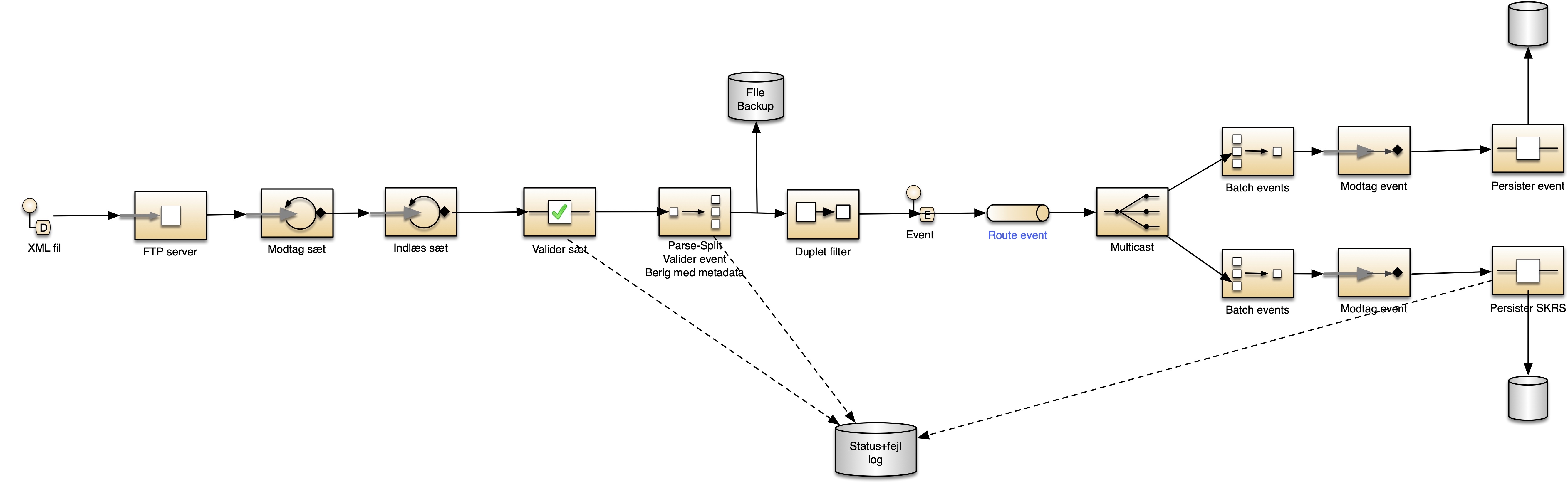
Ud over de komponenter der udføres i pipelinen indeholder hver stamdataindlæser også en status-servlet hvorigennem stamdataindlæserens status kan ses.
De logiske komponenter er beskrevet herunder.
4.2. Modtag datasæt
Et datasæt, i form af en fil, hentes fra en fjern placering, f.eks. en SFTP sever og placeres i en lokal folder til videre behandling i stamdataindlæseren.
Modtagelsen af en fil med stamdata anvender standard funktionalitet i Camel. Camel understøtter forskellige måder hvorpå det kan afgøres om en fil er klar til at blive hentet af en stamdataindlæser, og herunder gennemgås de forventede scenarier samt hvorledes Camel konfigureres til at fungere i hvert scenarie.
Generelt startes modtagelsen, når der ankommer en fil i en folder på en FTP server. Med de viste muligheder for at afgøre om skrivning af filen er overstået (f.eks. ved brug af readLock optionen), er der ikke nogen grund til kun at kigge efter nye filer på bestemte tidspunkter som evt. er afstemt med data-kildens normale frekvens.
Det betyder at vi kan sætte kommende indlæsere op til at kigge efter nye filer kontinuert - men for ikke at "overbelaste" FTP serveren, er der nedenfor indsat et delay som angiver en forsinkelse mellem hvert tjek (og dermed login på FTP serveren). Som udgangspunkt er der lagt et delay ind på 2h som er 2 timer (som er konfigurerbart) - det betyder at der foretages et tjek efter nye data når indlæseren startes op, og derefter hver 2. time.
I de efterfølgende Camel udtryk er det med fed markeret om en konfigurations-værdi leveres (og styres) eksternt.
4.2.1. Modtagelse af en fil der skrives til temporær fil
Hvis leverandøren af filen anvender det sikre foretrukne mønster, hvor filen skrives til en temporær fil, hvorefter den omdøbes i en atomar fil-operation til det filnavn der kigges efter, kan hentning af filen implementeres med dette Camel udtryk som vil kigge efter *.XML filer, hente filen til en lokal folder når den er synlig og slette filen fra kilden:
from("ftp:user@ftpserver?password=xxx&readLock=rename&antInclude=*.XML&delete=true&delay=2h")
.to("file:" + INPUT_FOLDER );
4.2.2. Modtagelse af fil som ikke skrives til temporær fil
Hvis leverandøren af en fil ikke anvender det sikre foretrukne mønster, hvor filen skrives til en temporær fil hvorefter den omdøbes i en atomar fil-operation til det tilnavn der kigges efter, kan Camel's indbyggede "change" option anvendes som tjekker om filen stadig ændrer sig, og når den ikke gør det længere anses den for færdigskrevet og filen hentes.
Hentning af filen implementeres i dette tilfælde med et Camel udtryk som vil kigge efter *.XML filer, hente filen til en lokal folder når den ikke er ændret i et 10 sekunders interval og slette filen fra kilden:
from("ftp:user@ftpserver?password=xxx&readLock=changed&readLockCheckInterval=10000&antInclude=*.xml&delete=true&delay=2h")
.to("file:" + INPUT_FOLDER );
4.2.3. Modtagelse af filsæt i folder uden at filer må slettes
Hvis leverandøren skriver nye filer til, f.eks., en NYESTE_TEMP folder, og først når skrivningen er helt færdigt omdøber folderen til, f.eks., NYESTE for at signalere at nye data er tilgængelige, samtidig med at filerne i NYESTE folderen ikke må ikke slettes, da de altid skal være tilgængelige for andre klienter, som gerne vil hente data, skal Camels idempotent funktionalitet anvendes ved fil hentningen.
Hentning af en sådan fil implementeres med dette Camel udtryk som vil kigge efter fil.txt i NYESTE folderen, hente filen til en lokal folder når idempotentKey, der er defineret som "fil-navn+fil-ændrettid" ikke er set før og lade filen blive på kilden:
from("ftp:user@ftpserver/NYESTE?password=xxx&readLock=rename&antInclude=fil.txt&delete=false&noop=true&idempotent=true&idempotentKey=${file:name}-${file:modified}&delay=2h")
.to("file:" + INPUT_FOLDER );
4.3. Indlæs datasæt
Filen med data indlæses af Camel fra den lokale folder hvori modtagelsen har placeret den.
4.4. Validering af datasæt
På en modtaget fil gennemføres der et antal valideringer, før data parses og splittes til events. Valideringen på dette trin sikrer, at når filen efterfølgende håndteres, så er den som udgangspunkt korrekt i henhold til det aftalte.
I tilfælde af fejl vil resultatet af valideringen blive vist på indlæserens status-servlet.
De valideringer der skal gennemføres afhænger af den specifikke stamdataindlæser, men følgende valideringer vil som regel være aktuelle:
4.4.1. Validering af filnavn
Filnavnet vil ofte indeholde et løbenummer eller et datostempel. Valideringen af filnavnet vil derfor fejle hvis løbenummeret eller datostemplet enten mangler eller ikke er større eller senere end den senest modtagne fil
Hvis valideringen fejler stoppes filen og den givne fejl logges til databasen og applikationsloggen.
4.4.2. Validering af encoding
Indholdet af filen for en given stamdataindlæser, skal være kodet i henhold til en aftalt encoding, f.eks. UTF-8 eller ISO-8859-1.
Der foretages en validering af at den modtagne fil opfylder den aftalte encoding.
Hvis valideringen fejler stoppes filen og den givne fejl logges til databasen og applikationsloggen med en relativ position i filen af det tegn som ikke er i den forventede encoding.
4.4.3. Validering af struktur
Indholdet af filen for en given stamdataindlæser forventes at være i en given struktur, f.eks. XML eller CSV.
Der foretages en validering af strukturen, f.eks. via en XML skema validering. Denne validering tjekker ikke for data indholdet, men sikrer udelukkende at strukturen af filen er som forventet.
Valideringen af strukturen fejler hvis
- Strukturen ikke er korrekt
- Der er data elementer som ikke passer med strukturen
Hvis valideringen fejler stoppes filen og den givne fejl logges til databasen og applikationsloggen.
4.4.4. Yderligere validering
Indholdet af filen valideres for stamdataindlæser-specifikke krav, f.eks.
- Hvis filen indeholder en checksum for f.eks. antal indeholdte rækker, tjekkes det at værdien matcher antal rækker i filen
- Hvis filen indeholder et fuldt dump af data kan det tjekkes at antallet af data i filen ikke afviger for meget i forhold til tidligere modtagne data.
Hvis valideringen fejler stoppes filen og den givne fejl logges til databasen og applikationsloggen.
4.5. Parsning af datasæt til events
Resultatet af pasningen er en strøm af events, hvor hver event indeholder en eller flere data-entiteter som sammen udgør en konsistent enhed i forhold til aftagere af data.
F.eks. for Yderindlæseren, vil en event indeholder en Yder samt dennes relaterede YderPersoner.
Denne tilgang sikrer, at aftagere af data kan forvente, at når de modtager en mængde af data, så er den konsistent, så de ikke selv skal tage højde for dette.
Til beskrivelsen af events anvender vi Apache Avro som også er forberedt på evt. senere levering af data via data-strømme, f.eks. via Apache Kafka.
Se eventuelt referencearkitekturen for stamdataindlæsere, der beskriver fordelene ved at anvende events i større detaljer.
4.6. Validering af events
Når de enkelte events er genereret, påtrykkes de en validering der sikrer at de indeholdte data overholder hvad der er aftalt med leverandøren af data.
Denne validering omfatter
- Obligatoriske/optionelle felter
- Data typer (tidsangivelser, numeriske felter, værdiintervaller, mønstre f.eks. CPR)
- Feltlængder jf. evt. datamodel
Hvis valideringen af en event fejler, så logges det til databasen og applikationsloggen, men håndteringen af de øvrige events fortsætter. Dermed sikrer vi, at vi indlæser så mange events som muligt, for at tilgodese aftageren, samtidig med at vi tilbageholder fejlbehæftede data.
Dele af denne validering foretages/sikres via det anvendte Avro skema.
4.7. Berigelse af events med metadata
Hvert event beriges med metadata, som ikke er en del af de forretningsmæssige data, der er indeholdt i filen.
Disse data er f.eks. identifikation af kildefilen og en entitets placering i kildefilen, og de har til formål at højne kvaliteten i efterfølgende logninger ved fejl, så driftssupporten nemt kan finde frem til årsagen af sådanne fejl.
4.8. Dublet filter
Selvom stamdataindlæseren modtager et fuldt dump af data, ønsker aftagerne kun at få reelle ændringer.
Derfor indeholder pipelinen et dublet filter, som bortfiltrerer de events som kun indeholder data, der er identiske med, hvad der tidligere er modtaget, samt annoterer de resterende events med hvilke af dets entiteter der er nye, ændrede eller eksisterer. For yderligere detaljer se referencearkitekturen.
4.9. Levering af events
Til slut i pipelinen leveres events til aftagere.
Som udgangspunkt foregår dette ad to kanaler, der dog begge anvender SKRS som grænseflade:
- som entiteter via SKRS
- som events via SKRS
Begge kanaler leverer de samme data, men der kan være historiske og/eller tekniske omstændigheder der gør den ene kanal mere velegnet end den anden.
Begge kanaler leverer data via en MariaDB database og SKRS'en, der begge er en integreret del af NSP'en.
Stamdataindlæseren opretter forbindelse til databasen via en datasource, som alt afhængig af miljøet peger på den rigtige instans (CI/CD, test, staging, produktion) af databasen.
Beslutningen om at lade data være repræsenteret internt som events åbner op for at data kan leveres som en datastrøm, f.eks. via Apache Kafka, men det er en mulighed som endnu ikke er til rådighed.
De to kanaler er beskrevet nærmere herunder
4.9.1. Entiteter via SKRS
Nuværende aftagere af stamdataregisterdata vil allerede anvende SKRS'en som grænseflade. Dvs. at de har udviklet en klient som kan kalde SKRS'en og som kan håndtere de data der hentes derfra til brug i deres systemer.
For at sikre at eksisterende aftagere ikke skal ændre deres klienter, skriver nye Stamdataindlæsere entiteter til en tabel struktur så data kan udstilles via SKRS på samme måde som den Stamdataindlæser de afløser.
Det betyder, at Stamdataindlæseren vil bryde de interne events op i de enkelte entiteter og skrive disse entiteter til databasen i separate tabeller på samme måde som tidligere.
De nye Stamdataindlæsere behandler data internt som en datastrøm, så for at undgå mange små skrivninger til databasen, er der introduceret en gruppering (batchning) af events inden de skrives til databasen. Hvor store disse grupperinger er, er konfigurerbart og kan derfor tilpasses den konkrete Stamdataindlæser.
4.9.2. Events via SKRS
For at tilbyde nye aftagere af stamdataregisterdata et alternativ, skriver nye Stamdataindlæsere også de interne events direkte til en tabel i databasen, og disse events udstilles via SKRS grænsefladen.
Det betyder, at nye aftagere kan vælge at modtage events der består af flere sammenhængende entiteter, og derved undgå selv at skulle knytte disse entiteter sammen, hvilket betyder udvikling af en simplere klient.
4.10. Logning
Logning af hvad der foregår under filens behandling i pipelinen sker på forskellige niveauer og formater.
På øverste niveau logges via SLALog i NSPUtil og dertil logges der i stamdataindlæserens applikations- og audit-log samt til databasen.
4.10.1. SLALog
Via SLALog logges modtagelse og afslutning af en datafil.
For Yderindlæseren giver det følgende logs i filen nsputil-sla.log:
nsputil-sla.log
|
4.10.2. Applikations- og audit-log
Via Log4J logges stamdataindlæser aktivitet til applikations- og audit-log.
For Yderindlæseren giver det følgende logs i yderAudit.log og yderApplication.log:
yderAudit.log
|
yderApplication.log
|
4.10.3. Databaselog
Som et supplement til indholdet i logfilerne samt til at levere datagrundlaget for ovennævnte status-servlet, logges der til følgende tabeller i databasen:
- PREFIX_DataSet - indeholder en række for hver modtagen fil. Den UUID som identificerer datasættet, knyttes også til forretningsdata, så det er entydigt hvilken fil, der sidst har påvirket en given række af forretningsdata.
- PREFIX_DataSetLog - indeholder evt. fejl der er registreret under behandling af den pågældende fil
- PREFIX_RegisterStatus - indeholder den akkumulerede status for det pågældende register
- PREFIX_RegisterFejl - indeholder et registers fejlede entiteter og er linket til den senest relaterede række i PREFIX_DataSetLog.
Hvor PREFIX er det stamdataindlæser specifikke prefix som anvendes i navngivningen af tabeller for en given stamdataindlæser, f.eks. "YDS" for Yderindlæseren.
4.11. Backup af fil
Der foretages en backup af det modtagne filsæt når parsningen og dermed event-genereringen er tilendebragt.
Backup lokationen anvender Camels standard funktionalitet mhp. placering og navngivning.
Da stamdataindlæsere afvikles som et Docker image, er placeringen af backup filerne mountet til en ekstern placering så filerne kan tilgås af driften udenfor Docker imaget.
For Yderindlæseren er backup placeringen mountet på /Stamdata_backup og backupfilerne er navngivet på formen ${file:name.noext.single}-${exchangeId}.${file:name.ext.single} hvor der anvendes elementer af Camel's Simple Language.
Formatet betyder, at når der ankommer en fil med navnet SSR1040025.00043.xml så bliver backup filen navngivet som SSR1040025.00043-<uuid>.xml, f.eks. SSR1040025.03591ea0-af6e-4fe2-bb2e-63fbb3859e6a.xml
Den UUID der indsættes i backupfilens navn, er den samme UUID som anvendes i registreringen af den modtagne fil i tabellen YDS_DataSet og YDS_DataSetLog - så hvis den ovenstående fil ikke var blevet indlæst pga. fejl i filen, ville den tilsvarende logning se ud som følger:
DataSet:

DataSetLog

4.12. Status servlet
Denne servlet anvendes af driften til kontinuert at tjekke om håndteringen af modtagne filer er gået godt eller om det pågældende register er fejlbehæftet. Alt afhængigt af hvad servletten tjekker kan noget af informationen caches mellem kald så monitoreringen ikke påvirker ydelsen af stamdataindlæseren.
Status kaldes med URL'en: http://<host>:8080/<xxxx>indlaeser/status - f.eks. http://<host>:8080/yderindlaeser/status for Yderindlæseren.
Hvis Stamdataindlæseren er ok, svares der med HTTP 200 og (som information) den gældende version af Stamdataindlæseren, f.eks.:
|
Hvis der er et problem som betyder at Stamdataindlæseren ikke kan sikre konsistensen af stamdata registret, skal der altid svares tilbage med HTTP 500 og en beskrivelse af problemet så driftsorganisationen umiddelbart kan påbegynde afhjælpning af fejlen, f.eks.:
|
5. Beskrivelse af kildekodens struktur og design
Kildekoden er struktureret i henhold til systemdesignet, der er bygget op omkring udførelsen af en pipeline.
Der er defineret et stamdataindlæser-bibliotek som indeholder fælleskomponenter der anvendes på tværs af stamdataindlæsere.
Koden for både fælleskomponenter og stamdataindlæsere er struktureret som et standard Maven projekt med en tilhørende pom.xml fil der definerer afhængigheder til 3. parts biblioteker.
5.1. Kodestruktur for fælleskomponenter
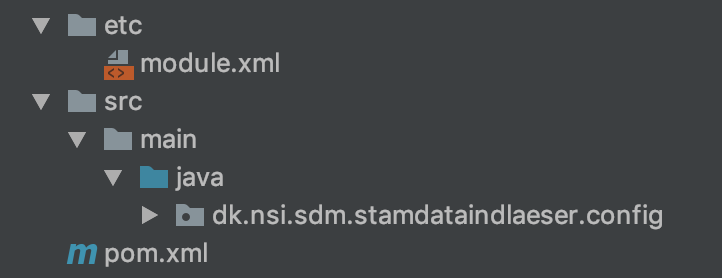
Strukturen for fælleskomponenterne består af
etc- indeholder modul definition af biblioteketjava- indeholder koden for fælleskomponenterpom.xml- indeholder definition af afhængigheder til 3. parts komponenter
5.2. Kodestruktur for stamdataindlæser
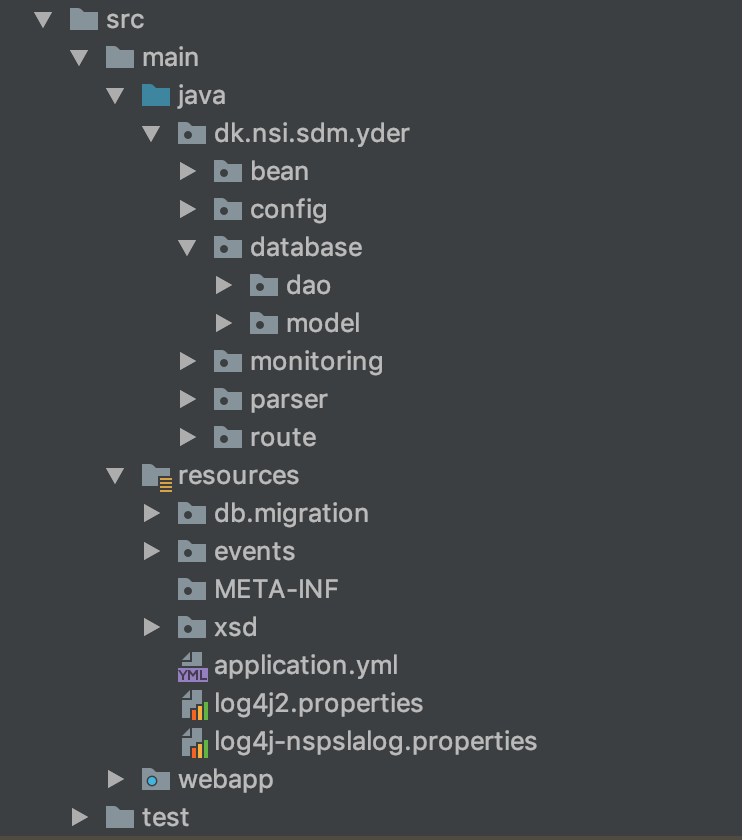
Her er strukturen eksemplificeret fra Yderindlæseren hvor
beanindeholder koden for de komponenter der orkestreres af pipelinenconfigindeholder indlæsning og udstilling af eksterne konfigurations-variabledatabaseindeholder model og database adgang for entiteterdaoindeholder database adgang til at læse, skrive og opdatere entitetermodelindeholder java klasser til at repræsenterer de entiteter som DAO klasserne håndterer
monitoring- indeholder koden der anvendes af status servlet til monitorering af stamdataindlæserens tilstand.parser- indeholder hjælpeklasser for parsning af stamdata filer, for Yderindlæseren er det SAX parser event handlere.route- indeholder den grundliggende opsætning af Camel router som orkestrerer udførelsen af pipelinenresources- indeholder bl.a. konfiguration af applikations- og NSP-logfilerdb-migration- indeholder sql scripts, der udføres af flyway til at vedligeholde og migrere databasenevents- indeholder specifikation af AVRO skema på JSON format - specifikationen beskriver struktur og indhold af de events, der flyder gennem pipelinenxsd- indeholder skema for Yderindlæserens stamdatafil og bruges under validering af en modtagen fil
webapp- indeholder visningsdelen for status-servlettest- indeholder unit- og integrations-tests
5.3. Versionskontrol
Kildekoden for hhv. fælles komponenter og stamdataindlæsere ligger i NSP'ens Subversion (SVN) installation. For en given stamdataindlæser opretter NSP driften en placering som udvikleren af den givne stamdataindlæser kan anvende.
For fælles komponenter ligger koden i https://svn.nspop.dk/svn/libraries/stamdataindlaeser/trunk/
For Yderindlæseren ligger koden i https://svn.nspop.dk/svn/importers/yderindlaeser/trunk/ og andre stamdataindlæsere vil blive placeret i foldere på tilsvarende vis under https://svn.nspop.dk/svn/importers/
Ved frigivelse af koden tagges den med et SVN tag på formen
- for en release kandidat:
release-x.y.zrc - for en produktions release:
release-x.y.z
NSP driften kan efterfølgende bygge den ønskede release via Jenkins og igangsætte installation i test- og produktions-miljøer.
5.4. Databasenavnekonvention
Stamdataindlæsere vil afvikle på en og samme database. For at undgå, at de kolliderer omkring oprettelse af tabeller etc. skal alle tabeller som en stamdataindlæser anvender, prefixes med et unikt prefix. For en given stamdataindlæser vil NSP drift udstikke et unikt prefix som kan anvendes til de tilhørende tabeller. F.eks. for Yderindlæseren er prefixet "YDS" anvendt og alle tabelnavne er derfor på formen YDS_xxxx.
Til vedligehold af databasen anvendes Flyway, som sikrer en kontrolleret afvikling af database migreringsscripts - dvs. Flyway holder styr på, hvilke migreringsscripts der er afviklet, og hvilke der mangler at blive afviklet, når stamdataindlæseren startes.
Flyway indeholder selv en tabel, som holder styr på hvilke scripts, der er afviklet. For at undgå sammenblanding mellem stamdataindlæsere, anvendes det angivne prefix også ved initialisering og afvikling af Flyway. Hvordan prefixet anvendes kan ses i denne kodestump fra Yderindlæseren:
|
6. Beskrivelse af test opsætning
Stamdataindlæsere benytter i vid udstrækning docker til test, for at kunne teste så vidt muligt med de rigtige afhængigheder.
Det overordnede setup er beskrevet i NSP Continuous Integration & Delivery, og det er herved muligt at starte en specifik stamdataindlæser med lokalt kørende database samt stamdatakopiregisterservice (SKRS); således at hele flowet kan afprøves lokalt.
6.1. Unittest
Der anvendes unittests i alle stamdataindlæsere ved brug af JUnit.
Stamdataindlæseres unittest-setup er specielt på to punkter, i det der benyttes mocks for at kunne teste Camel, samt at der benyttes TestContainers, således at unittests kan ramme en rigtig lokalt kørende mariadb database kørende i docker (https://www.testcontainers.org).
Unittests kan køres ved at eksekvere
|
6.1.1. Mocking i Camel
I det Camel kører asynkront, er det nødvendigt for unittests at vide, hvornår Camel er færdig med at indlæse en fil, hvis testen skal vide, hvornår den kan kontrollere, om det gik som forventet. Dette gøres i stamdataindlæsere som Yderindlæseren, i klassen BaseMockTest, hvor Camel-routen mockes ved at tilføje et sidste MockEndpoint, som en test kan vente på.
Hvis ikke der benyttes mocks til Camel kan man være nødsaget til at indsætte waits, hvilket gør testeksekveringen langsommere, samt kan være forskellige afhængig af eksekveringsmaskinens computerkraft.
6.1.2. Unittests med en kørende MariaDb
I det stamdataindlæsere selv migrerer databaseskemaet (via Flyway), samt i overensstemmelse med NSP husregler ikke benytter ORM som Hibernate, er det blevet godkendt at unittests selv starter en mariadb database via docker, og tester ved brug af den.
TestContainers er et java bibliotek som tillader programmatisk instruering af docker starter op, og herved starter en ny tom mariadb container op, som applikationen kan køre databasemigreringer mod, og herefter benytte i alle unittests.
For eksempel se https://svn.nspop.dk/svn/importers/yderindlaeser/trunk/src/test/java/dk/nsi/sdm/yder/BaseTest.java klassen i yderindlæser-projektet.
6.2. Integrationstest
Til hver indlæser foreslås det, at der laves specielle automatiserede tests, som kan køres som integrationstests.
Disse integrationstests giver mulighed for at teste hele indlæseren med de afhængigheder den vil benytte sig af, når den kører i produktion, som fx. SKRS (registerkopiservice) eller SYES (enkeltopslagsservicen).
Unittests til integrationstests markeres i koden med en custom testkategori og projektet sættes op så disse kan køres ved at køre (mvn test -Pintegrationtest).
Disse tests vil så kræve at indlæseren samt de korrekte afhængigheder allerede kører, hvilket typisk laves via docker-compose. For yderindlæseren er compose/test/docker-compose.yml lavet således, at denne starter yderindlæser, database samt SKRS i en opsætning som kan testes via integrationstestene. Så man kan starte denne docker-compose fil lokalt (docker-compose up) og så ved siden af køre integrationstestene, som vil lægge en fil op, vente på at den bliver indlæst, og herefter se efter i både database samt SKRS om indlæsningerne er gået godt.
6.3. Performancetest
Stamdataindlæserene indeholder typisk ikke en automatiseret testsuite beregnet til performancetest. Det anbefales dog at der udføres en manuel performancetest i forbindelse med udvikling, med indlæsningsfiler af omtrent samme størrelse og kompleksitet som de rigtige indlæsningsfiler.
En sådan rudimentær performancetest er ment til at afdække eventuelle flaskehalse som kan blive optimeret før release, samt også give en idé til hvor lang tid indlæseren vil skulle bruge for at indlæse de typiske filer der modtages.
7. Skabelon for udviklingsprojekt
Ved igangsættelse af et nyt stamdataindlæserprojekt, tages der udgangspunkt i yderindlæseren (eller anden nyere udvalgt indlæserkode) og navngivning, indhold, modeller og lignende kan tilpasses derfra, med udgangspunkt i den samme opbygning og struktur som den kopierede indlæser.
Der er med vilje ikke lavet et decideret skabelon-projekt eller et indlæser-framework med en tilhørende hård binding, da det forventes at være bedre at tage udgangspunkt i en kørende indlæser, og rette til.
Dette skulle gerne give mere frihed, mod at det der ligger noget arbejde i den initielle kopiering og tilpasning.
Foreslåede tilpasningstrin, ved kopiering af indlæser til ny (se evt. ovenstående afsnit 5 på denne side for placering af den specifikke kodeelementer) er:
- Kopier hele projektet (trunk) til ny mappe, og gå igennem og omdøb navne (fx. yder til cpr osv.)
- Ret skema til for både databasemigreringer, samt avro-skema (som genkompileres) og ret modeller til.
- Tilpas parser implementeringen som ligger i
bean's så den passer til de data der modtages - Gå igennem, udkommenter og fjern indtil en rudimentær version kan kompilere og teste.
Herfra burde grund-strukturen være den samme som den indlæser der blev kopieret fra, og det meste opsætning for docker, tests og logning genbruges.