Fejl håndteres på samme måde for alle indlæsere, hvorfor denne beskrivelse ligger under referencearkitektur i stedet for at blive gentaget for alle de enkelte indlæsere.
Fejlsituationer kan ske mange steder i pipelinen fra referencearkitekturen og afhængig af konteksten skal de håndteres på forskellig vis.
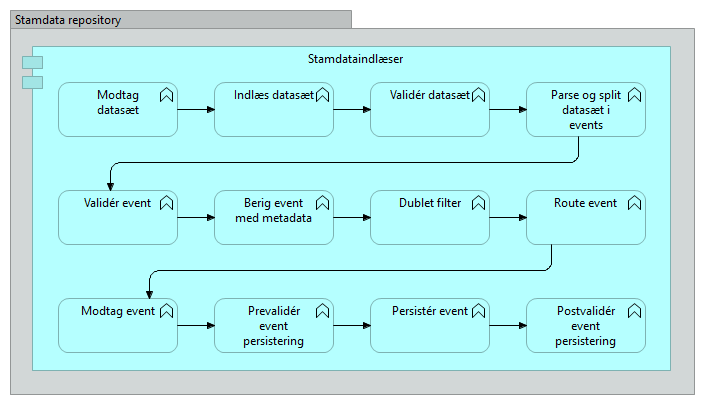
Pipelinen har ovenstående forløb og herunder beskrives der hvad der kan gå galt, hvordan situationen håndteres og hvilke meta-data der skal være til rådighed for at kunne foretage den fornødne håndtering.
Hvor der herunder er nævnt at noget rapporteres, forventes det at der forefindes en standard metode/API hvorigennem rapportering i form af logning og/eller alarmering kan foretages.
Modtag datasæt
Ved Modtag datasæt hentes filen fra den givne lokation som scannes og placeres i en lokal folder.
Scanningen efter filer foretages via en Camel route som poller en given lokation (lokal folder, SFTP eller andet) for forekomsten af en fil der matcher et aftalt mønster (*.xml)
Det som kan gå galt her er:
- Ingen forbindelse til fil-lokation
- Camel vil her melde en fejl hvis lokationen ikke kan tilgås og denne fejl rapporteres
- Fil matcher ikke filter (*.xml)
- Camel vil her ikke melde nogen fejl da det er en helt normal situation af der ligger filer som ikke matcher og dermed ikke skal hentes.
Hvis en fil skrives under et andet navn (*.tmp) og er lang tid om at blive skrevet, kan det være vanskeligt at afgøre om det er en fejlsituation eller ej.
Evt. kan der i den enkelte stamdata indlæser indbygges et job der trigges på et aftalt tidspunkt og som tjekker om den forventede fil-frekvens er opfyldt og hvis ikke foretage en rapportering
- Camel vil her ikke melde nogen fejl da det er en helt normal situation af der ligger filer som ikke matcher og dermed ikke skal hentes.
- Fil er låst
- Hvis filen matcher men er låst, vil Camel melde en fejl og denne fejl rapporteres
Indlæs datasæt
Indlæs datasæt henter filen fra den lokale folder og påbegynder processering af filen.
Der er ikke identificeret fejlsituationer i dette trin.
Valider datasæt
Valider datasæt har til formål at sikre at filen er komplet og kan parses som en helhed.
Det som kan gå galt her er:
- Filen fejler parsning
- Parseren vil her generere en fejl som beskriver årsagen til fejlen og denne fejl rapporteres
- Rapporteringen vil indeholde et unikt id for filmodtagelsen, filens navn og tidspunktet for modtagelsen
- Indlæsning af filen stoppes
- Filen er ikke komplet jf. leveret checksum/antal poster
- Valideringen vil her generere en fejl som beskriver årsagen til fejlen og denne fejl rapporteres
- Rapporteringen vil indeholde et unikt id for filmodtagelsen, filens navn og tidspunktet for modtagelsen
- Indlæsning af filen stoppes
- Filen afviger "for meget" fra tidligere (kun fuldt load)
- Valideringen vil her generere en fejl som beskriver årsagen til fejlen og denne fejl rapporteres
- Rapporteringen vil indeholde et unikt id for filmodtagelsen, filens navn og tidspunktet for modtagelsen
- Indlæsning af filen stoppes
- Ukendt element i fil (f.eks. at en XML fil indeholder et ukendt element)
- Parseren vil rapportere at et ukendt element er fundet i filen
- Rapporteringen vil indeholde unikt id for filen, id for eventen, typen af elementet og en eksakt eller relativ position i filen
- Det ukendte element ignoreres og indlæsning fortsætter
Parse og split datasæt/Valider event
Parse og split datasæt/Valider event har til formål at parse filen og undervejs opdele filen i de enkelte events (=hændelser)
Det som kan gå galt her er:
- Data indhold er forkert format
- Parseren vil rapportere at data er i forkert format
- Rapporteringen vil indeholde unikt id for filen, id for eventen, typen af elementet, det forventede og faktiske format og en eksakt eller relativ position i filen
- Det event som indeholder forkerte data indlæses ikke
- Data indhold er forkert længde
- Parseren vil rapportere at data er i forkert længde
- Rapporteringen vil indeholde unikt id for filen, id for eventen, typen af elementet, den forventede og faktiske længde og en eksakt eller relativ position i filen
- Det event som indeholder forkerte data indlæses ikke
- Obligatoriske felter mangler
- Parseren vil rapportere at data mangler
- Rapporteringen vil indeholde unikt id for filen, id for eventen, typen af elementet, de manglende felter og en eksakt eller relativ position i filen
- Det event som mangler data indlæses ikke
Berig event
Berig event tilføjer meta data til eventen så den indeholder data omkring det datasæt der producerede eventen.
Der er ikke identificeret fejlsituationer i dette trin.
Dublet filter
Dublet filter kontrollerer om eventen allerede eksisterer i helt identisk form i databasen, og i givet fald sorteres eventen fra som en ikke-opdatering.
Det som kan gå galt her er:
- Ingen forbindelse til database
- Camel vil melde en fejl som vil blive rapporteret.
- Rapporteringen vil indeholde unikt id for filen og id for den aktuelle event.
- Camel vil forsøge at læse den eksisterende event i databasen i den forventning at databasen kommer op igen
- Processeringen af denne og resterende events fortsætter når databasen er tilbage.
Route event
Route event har til formål at pakke eventen og sende den til consumeren/aftageren
Det som kan gå galt her er:
- Hvis Kafka - ingen kontakt til Kafka
- Camel vil melde en fejl som vil blive rapporteret.
- Rapporteringen vil indeholde unikt id for filen og id for den aktuelle event.
- Camel vil rulle leveringen tilbage og gentage levering i den forventning at Kafka kommer op igen
- Indlæsning af denne og resterende events fortsætter når Kafka er tilbage.
Modtag event
Modtag event udpakker eventen og stiller den til rådighed for consumeren/aftageren
Det som kan gå galt her er:
- Hvis Kafka - ingen kontakt til Kafka
- Camel rapporterer en generel fejl
- Indlæsning fortsætter når kontakt til Kafka er genoprettet
- Hvis Kafka - unmarshal fejler
- Camel rapporterer en fejl
- Rapporteringen vil indeholde unikt id for filen, id for den aktuelle event, den rapporterede unmarshal-fejl samt en eksakt eller relativ position i filen
- Indlæsning af denne event stopper
- Hvis Kafka - ukendt type af event
- Camel rapporterer en fejl
- Rapporteringen vil indeholde unikt id for filen, id for den aktuelle event, den ukendte type samt en eksakt eller relativ position i filen (metadata er her lidt usikre for hvis typen er ukendt må eventen være blevet lagt på Kafka af en 3. part(?))
- Indlæsning af denne event stopper
Prevalider event
Prevalider event er ikke en del af den kørende pipeline.
Validering af event indholdet foregår i Valider event og da der indtil videre ikke er andre kanaler der genererer events, vil de ikke kunne være in-valide når de ankommer hertil.
Persister event
Persister event har til formål at foretage skrivningen (slet/opdater/indsæt) til databasen.
Det som kan gå galt her er:
- Ingen forbindelse til database
- Camel vil melde en fejl som vil blive rapporteret.
- Rapporteringen vil indeholde unikt id for filen og id for den aktuelle event.
- Camel vil rulle skrivningen tilbage og gentage skrivning i den forventning at databasen kommer op igen
- Indlæsning af denne og resterende events fortsætter når databasen er tilbage.
- Mismatch mellem model og database (felter, feltlængder, not-null felter) bør ikke kunne forekomme da det skal være fanget i Valider event
- Camel vil melde en fejl som vil blive rapporteret.
- Rapporteringen vil indeholde unikt id for filen, id for den aktuelle event, den rapporterede db-fejl samt en eksakt eller relativ position i filen
- Indlæsning af denne event stopper (men de øvrige events i batchet fortsætter.
Postvalider event
Postvalider event er ikke en del af den kørende pipeline.
Vi har indtil videre ikke set et behov for at foretage en postvalidering af data.
Rapportering af og opfølgning på fejl
Hvis en stamdataindlæser melder, at der er fejl i et eller flere event, og de derfor ikke kan indlæses, så vil overvågningsservicen for den pågældende stamdataindlæser fortælle dette i sit svar, når den bliver kaldt. På denne måde bliver der rejst en alarm, som driftsovervågningen bliver opmærksom på. Informationen i fejlbeskeden vil være så detaljeret som mulig i forhold til hvilke events (unikt identificeret), der fejler, og hvad der er gået galt med dem.
Denne detaljerede information kan så anvendes af driftssupporten, når de tager kontakt til ejeren af kildesystemet, hvorfra stamdataudtrækket med fejlene stammer fra. De fejlagtige data rettes efterfølgende op i kildesystemet, og et nyt/opdateret udtræk bliver eksporteret fra kildesystemet, der indlæses af stamdataindlæseren. Såfremt alt går godt, og der således er blevet rettet op på fejlen, ændres svaret for den pågældende stamdataindlæsers overvågningsservice til alt ok.