Page History
| Table of Contents |
|---|
*Dokumentationen af NSP services og komponenter på NSPOP omfatter udelukkende NSP produktionsmiljøet og ikke NSP’s øvrige miljøer. Det er muligt at få information og indblik i tilstanden på et af de øvrige miljøer via de gængse kommunikationsveje.
TODO: titel?
links til gavn under skrivning:
Teknisk implementeringsvejledning Aftaleoversigt
https://github.com/KvalitetsIT/kih-anvendelse
https://github.com/KvalitetsIT/aftaledeling
NXRG - Design- og arkitekturbeskrivelse
Indledning
Formål
Dokumentdeling gør det muligt for aktører sundhedsvæsnet i sundhedsvæsenet at dele relevante data om borgere , og dermed skabe et overblik over den enkelte borgers situation for de aktører, som har brug for dette. Det kan være dem, som planlægger og gennemfører behandlingsforløb eller for borgerens borgeren selv og deres omsorgspersoner. Samtidig skal det være muligt for borgeren at bestemme, hvem han/hun vil dele disse data med gennem samtykke spærring samt se, hvem der har læst data via MinLog. Infrastrukturen på NSP, der muliggør deling af dokumenter på tværs af sundhedsaktører, er baseret på IHE XDS standarden
Dette dokuments fokus er selve dokumentdelingen; dens dele, dens infrastruktur og, hvordan man kommer igang kommer i gang med at anvende den, som eksempelvis udvikler, der skal udvikle systemer, der skal anvende den.
Der forventes et hvis vist kendskab til CDA dokumenter - da fokus ikke er disse, ligesom kendskab til anvendelse af DGWS, NSP og SDN forventes for implementeringen. Hjælpe moduler Hjælpemoduler som MinSpæringSamtykkeService, MinLog MinLog2 og andre komponenter, der er i spil i forbindelse med dokumentdeling berøres heller ikke andet overfladisk.
Hvad er dokumenter
Data i en XDS infrastruktur gemmes som dokumenter. Et dokument har et unikt id (documentId) og en række metadata, der beskriver, hvad dokumentet handler om. Dokumenter kan indholdsmæssigt være af flere forskellige typer: slags mht indhold og format. Eksempler er PDF, Word-dokument , men kan også være af typen og XML. Et eksempel på et XML dokument er CDA (Clinical Document Architecture). Et CDA dokument er egentlig bare et struktureret XML dokument, der følger en bestemt standard for kliniske dokumenter til udveksling (deling). Se f.eks. What is HL7 CDA? for en kort beskrivelse. Her kan man bl.a. se, at CDA findes på forskellige niveauer 1-3, hvor 3 har den højeste grad af struktur.
En vigtig egenskab ved CDA dokumenter er den fælles CDA header. Denne header indeholder information, der går igen henover alle typer af kliniske dokumenter, f.eks. hvilken patient drejer dokumentet sig om, hvilken organisation er ansvarlig (ejer) af dokumentet mm. CDA headeren er således en international standard (HL7), men der findes en dansk specialisering af denne (standardiseret i regi af Medcomden danske profilering af metadata). Denne er beskrevet her HL7 Implementation Guide for CDA Release 2.0 CDA Header (DK CDA Header). Medcom vedligeholder en XDS Metadata for Document Sharing. Danish profile. Der er en tilhørende liste over tilladte værdi sæt for metadata, som findes her DK-IHE_Metadata-Common_Code_systems-Value_sets.
Der findes andre flere profiler, der er specialiseringer af CDA. Dvs. kliniske dokumenter, der har en struktur til bestemte formål. Medcom har leveret Hver af disse har deres egen kode værdi i metadata feltet typecode. Der findes danske profileringer af følgende typer (se evt. Medcoms oversigt over HL7 standarder):
- Appointment Document (APD) til aftaler
- Careplan (CPD)
- Personal Data Card/Stamkort (PDC)
- Personal Health Monitoring Report (PHMR) til hjemmemonitorering
- Questionnaire Form Definition Document (QFDD) og Questionnaire Response Document (QRD) til patientrapporterede oplysninger (PRO)
Oprindelig var det aftaledokumenter (APD) som blev delt på NSP platformen. Men det har ændret sig, så også de andre dokumenttyper er kommet i spil. Alle dokumenterne på NSP er CDA dokumenter for nuværende. Og de De skal alle overholde Medcoms de danske profiler nævnt ovenfor.
Der er to typer af CDA dokumenter (angives også i metadata feltet type) .
- "Stable document" som bliver skabt og gemt en gang for alle
- "On-demand" som først skabes på det tidspunkt det faktisk efterspørges
TODO: andre dokumenttyper af ondemand som skal nævnes med navn?
Hvad er dokumentdeling
Hvad er dokumentdeling
XDS står for Cross-Enterprise Document Sharing og er en international standard udarbejdet af Integrating the Healthcare Enterprise (IHE) for udveksling af kliniske dokumenter. En XDS infrastruktur består XDS står for Cross-Enterprise Document Sharing og er en international standard udarbejdet af Integrating the Healthcare Enterprise (IHE) for udveksling af kliniske dokumenter. En XDS infrastruktur består (mindst) af følgende to komponenter:
- XDS Document Repository: Står for til persistering af dokumenter tilknyttet et unikt ID.
- XDS Document Registry: Står for til opbevaring og indexering indeksering af metadata vedr. dokumenterne i et eller flere XDS repositories. Dette Metadata kunne f.eks. være start- og sluttidspunkt dokumentet dækker over, eller dets forfatter (author) (oplysningerne stammer typisk fra CDA headeren)
Integrationen med XDS infrastrukturen sker vha en række standardiserede SOAP webservices - ITI kald. Et overblik over XDS infrastrukturen og de forskellige services ses nedenfor:
Der er to varianter af CDA dokumenter, som deles i infraskturen (angives også i metadata feltet type). De har hver deres servicehåndtag, som det fremgår nedenfor.
- "Stable document" som bliver skabt og gemt en gang for alle
- "On-demand" som skabes på det tidspunkt, det faktisk efterspørges, (gemmes ikke, men skabes hver gang)
Integrationen med XDS infrastrukturen sker vha. en række standardiserede SOAP webservices - ITI kald. Et overblik over en standard XDS infrastruktur og de forskellige services ses nedenfor:
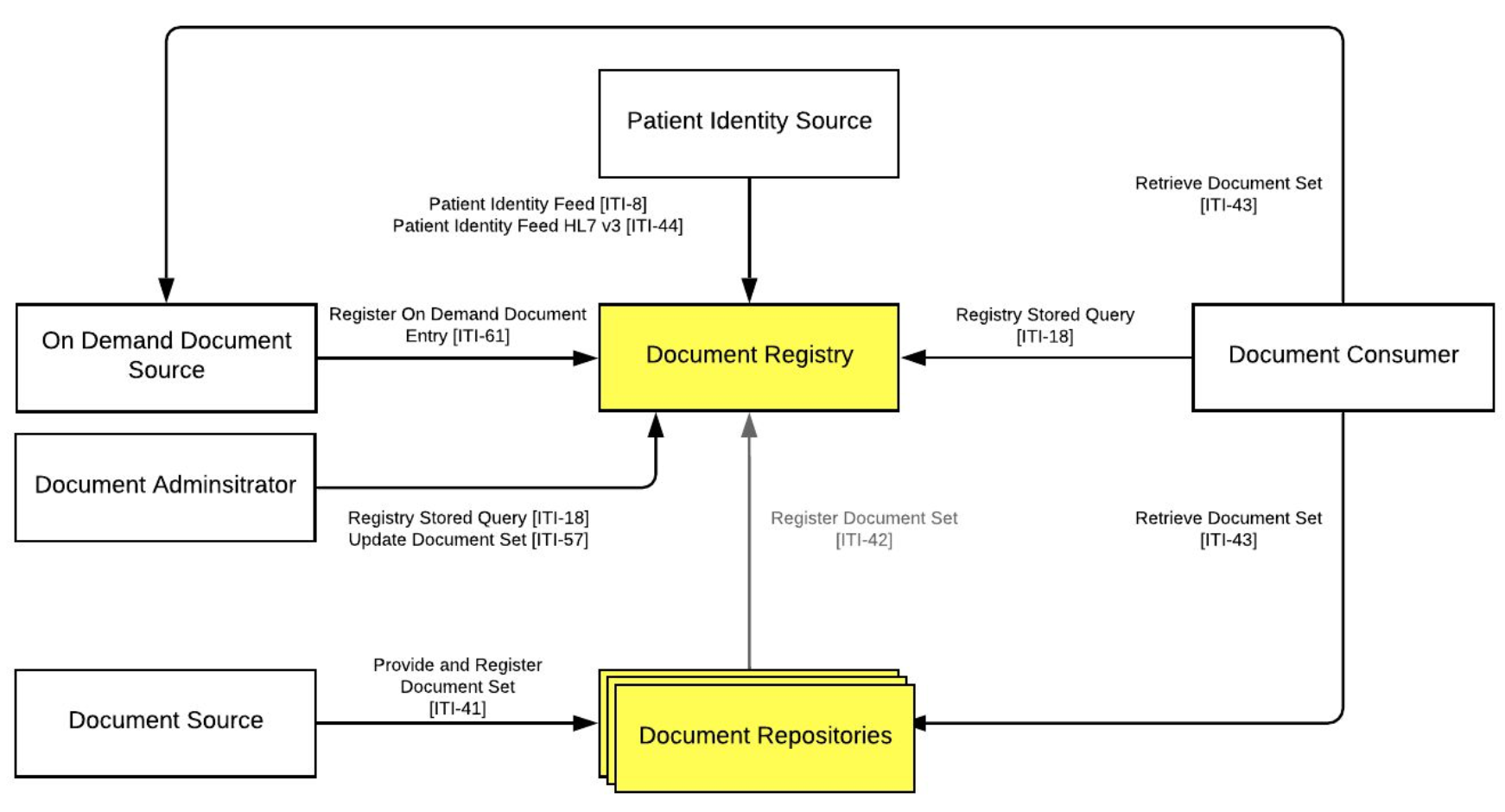
Når data skal deles vha XDS sker følgendeer der følgende overordnede flows:
- Oprettelse af dokumenter:
- Dokumenter afleveres af dokumentkilden (Document Source) til XDS repository via servicehåndtaget ITI-41 Provide and Register Document Set. Herefter sørger XDS repository for at registrere dokumentet i XDS registry via servicehåndtaget ITI-42 Register Document Set.
- Hvis der er tale om et on-demand dokument registreres det af dokumentkilden (On Demand Document Source) direkte i XDS registry via servicehåndtaget ITI-61 Register On Demand Document Entry, da der ikke er et
- faktisk CDA dokument at gemme.
- Fremsøgning og hentning af dokumenter
- Dokumentaftager (Document Consumer) fremsøger dokumenter i XDS registry via servicehåndtaget ITI-18 Registry Stored Query. Svaret på denne query
- kan være en liste af
- metadata for de dokumenter, som matcher søgningen. Et af felterne er repositoryId, der fortæller,
- hvor dokumentet kan findes.
- Dokumentaftager (Document Consumer) henter dokument i XDS repository via servicehåndtaget ITI-43 Retrieve Document Set
- Dokumentadministrator (Document Administrator) kan opdatere metadata (heriblandt slet (deprecate)ugyldiggøre) i XDS registry via servicehåndtaget ITI-57 Update Document Set.
- (Patient Identify Source som fremgår af figuren anvendes ikke på NSP, men er med i figuren da den indgår i standarden)
IHE XDS standarden er specificeret i en række dokumenter:. Disse er listet i nedenstående tabel med links og en beskrivelse af, hvordan man med fordel kan navigere i dem.
| Id | Beskrivelse | Link * |
|---|---|---|
| ITI TF-1 | Alle IHE profilerne beskrives. For NSP dokumentdeling er relevant afsnit
Man vil også kunne finde brugbar information i flere af appendixerne. | IHE IT Infrastructure Technical Framework Volume 1 (ITI TF-1) Integration Profiles (Revision 17.0 – Final Text) |
| ITI TF-2 | Hvert ITI håndtag beskrives med definition, information, som overføres, og begrænsninger Hvilket afsnit, som er relevant afhænger af hvilke ITI håndtag man skal implementere. Skal man lave fremsøgning (ITI-18) vælges afsnit "3.18 Registry Stored Query [ITI-18]" | IHE IT Infrastructure (ITI) Technical Framework, Volume 2 Revision 18.0, July 30, 2021 – Final Text |
| ITI TF-3 | Her I dette dokument beskrives metadata ved dokumentdeling. For NSP dokumentdeling er relevant afsnit
| IHE IT Infrastructure (ITI) Technical Framework, Volume 3 Revision 18.0, July 30, 2021 – Final Text |
| ITI TF-Metadata | Her beskrives Opdatering Dette dokument indeholder information omkring opdatering af metadata, som endnu ikke er med blevet indsat i den udgivne specifikation. Dokumentet indeholde indeholder de dele, som med tiden skal flettes ind i 1-3 ovenfor. Hvis man skal implementere opdatering af metadata (ITI-57) kan følgende afsnit være relevante:
| IHE IT Infrastructure Technical Framework Supplement 10 XDS Metadata Update 15 Rev. 1.12 – Trial Implementation July 2, 2021 |
| (*revision og dato matcher versionen da link indsat) |
Hvis man skal igang i gang med dokumentdeling, og ingen kendskab har til ovenstående specifikationerspecifikation, kan en tilgang være:
- Start med at skabe et overblik over documententry, associations og submissionsest - f.eks. i "ITI TF-3 afsnit 4.1 Abstract Metadata Model". Det er de objekttyper, man primært taler om i standarden og datamodellen man bør forstå.
- Læs derefter omkring de forskellige kald nævnt ovenfor:
- ITI-41 til oprettelse/ret af dokumenter - ITI TF-2 afsnit "3.41 Provide and Register Document Set-b [ITI-41]"
- ITI-18 fremsøgning af dokumenter : ITI TF-2 afsnit "3.18 Registry Stored Query [ITI-18]"
- ITI-43 hent af dokumenter: ITI TF-2 afsnit "3.43 Retrieve Document Set [ITI-43]"
NSP Arkitekturoversigt af komponenter
På NSP består dokumentdelings infrastrukturen dokumentdelingsinfrastrukturen af følgende komponenter.
TODO
<< oversigtstegninger over komponenter og iti interaktioner - tag kopi fra aftaledeling: Aftaler - justser med (+SFSK og -backends)?? >> I den tegning for dokumentdeling er det DDS Repo+Registry+DRS+DROS+SFSK, der er relevante (diverse backends skal ikke dokumenteres her). Skrive "udløbsdato" for DRS.
<< liste og forklaring af tegning inkl links til anvender guide for de forskellige >>
husk at placere hjælpe moduler og nævne at det får man med
nævne flere miljøer med denne konfig, og ref'e til test link nedenfor
Minlog, behandlingsrelationer, minSamtykke (filter) og værdispring
Hvordan kommer man igang
Komponenterne i dokumentdelings infrastrukuren kommunikerer med ITI kald, som er standardiserede SOAP services, der skal overholde IHE XDS specifikationen. De er i det såkaldte XML basererede "RIM format"
Det er op til anvenderen/udvikleren selv at vælge platform og frameworks, der passer til resten af dennes løsning. Fra et udvikler perspektiv kan man enten vælge selv at generere stubkode udfra de standardiserede WSDL filer eller at anvende et tredjepartsprodukt. Nedenfor gives et forslag til, hvordan det kan gribes an med tredjepartsproduktet IPF Open eHealth Integration Platform, som forudsætter man arbejder på en java platform. Andre platforme kan have tilsvarende værktøjer og muligheder.
Da dokumentdelingen kører på NSP og sundhedsdatanettet (SDN) skal man anvende Den gode Web Service og have adgang til SDN for den del af miljøerne. Dette beskrives ikke yderligere her.
OpeneHealth biblioteket til Java
Man behøver ikke at basere alting på Camel, men kan med fordel nøjes med at inkludere biblioteket IPF Commons IHE XDS i sin kodebase. Her findes både stubbe og en masse anvendelige utilities. Disse kan blandt andet mappe fra RIM formatet (specificeret af IHE XDS standarden), til en en "OpeneHealth core model", som er java klasser. Og gør det at udvikle ITI kald lettere at arbejde med.
Helt overordnet kan det at lave et ITI kald deles op i følgende trin
- Opret kald i OpeneHealth coree model
- For ITI41 kald indebærer det blandt andet opret/indlæs af dokument samt opret af metadata til documententry
- For ITI42, 57 og 61 indebærer det oprettelse af metadata
- For ITI18 skal søge kriterierne sættes op
- For ITI43 skal dokumentiderne sættes op
- Udfør kald - det transformeres til RIM format på vej ud, og tilbage til core model ved returnering vha. openeHealth frameworket
- Aflæs kaldets svar og håndter eventuelle fejl returneret. For ITI-18 og ITI-43 er der ligeledes dokument id'er henholdsvis dokumenter, der skal håndteres.
Dette kan illustreres ved følgende transformeringsdiagram, hvor man ser core modellen blive transformateret til RIM formatet og efterfølgende et ITI kald udført. Resultatet af ITI kaldet kommer tilbage i RIM format, og transformeres til core modellen:
| Gliffy Diagram | ||||||
|---|---|---|---|---|---|---|
|
Et eksempel på, hvordan forskellen mellem core model og RIM format kommer til udtryk, ses her for håndtering af confidentiality code og CPR nummer i forbindelse med oprettelse af et dokument.
Først OpeneHealth core model, den kode man skriver i sit program:
| Code Block | ||||
|---|---|---|---|---|
| ||||
documentEntry.getConfidentialityCodes().add(new Code("N", new LocalizedString("N"), "2.16.840.1.113883.5.25"));
AssigningAuthority patientIdAssigningAuthority = new AssigningAuthority("1.2.208.176.1.2");
Code patientCode = new Code("2512489996", new LocalizedString("CPR"), "1.2.208.176.1.2");
documentEntry.setPatientId(new Identifiable(patientCode, patientIdAssigningAuthority)); |
Og her tilsvarende RIM format, som openeHealth oversætter det til og som anvendes ved ITI kaldet:
:
| Gliffy Diagram | ||||||||
|---|---|---|---|---|---|---|---|---|
|
- DROS (anvenderguide) anvendes til skrive aktiviteterne:
- Oprettelse af nye dokumenter (ITI-41 Provide and Register Document Set) sker fra anvendersystemerne. DROS lagrer det oprettede dokument i det bagvedliggende nationale XDS Repository. I forbindelse med oprettelsen sørger det nationale XDS Repository for at få indexeret dokumentet og dets metadata i det nationale XDS Registry (ITI-42 Register Document Set). Tidligere har også DRS været anvendt til dette formål, men den udgår.
- Oprettelse af et dokument, som en opdatering til et eksisterende dokument (ITI-41 Provide and Register Document Set). Her ugyldiggøres det eksisterende/gamle dokument.
- Ugyldiggøre (deprecate) et dokument eller opdatering af et dokument (ITI-57: Update Document Set)
- Registrering af On-Demand dokumenter (ITI-61 Register On-Demand Document Entry)
- Registrering af Stable dokumenter (ITI-42 Register Document Set). Dette anvendes, hvis man selv ejer et repository, men anvender det nationale registry til indeksering. Et eksempel på dette er KIH databasen, som indeholder hjemmemålinger (PHMR) og spørgeskemaer (QRD) .
- DokumentDelingsServicen (DDS registry) (anvenderguide) anvendes til fremsøgning af dokumenter (ITI-18 Registry Stored Query) hvor der kigges i
- det Nationale XDS Registry
- aftale adaptorer til region Nord og Region Midt. Disse delegere søgninger videre til de to Bookplan instanser i Region Nord hhv. Region Midt
- FSK registry (vha bruger idkort)
- DokumentDelingsServicen (DDS repository) (anvenderguide) anvendes til at hente dokumenter (ITI-43 Retrieve Document Set) fra
- det Nationale XDS Repository
- aftale adaptorer til Region Nord og Midt, som henter Bookplan dokumenter i Region Nord hhv. Region Midt
- KIH databasen
- Graviditetsmappe On-Demand repository
- FSK (vha bruger idkort)
- Søgning af Fælles StamKort (SFSK) (anvenderguide) er til at fremsøge (ITI-18 Registry Stored Query) og hente (ITI-43 Retrieve Document Set) Fælles Stamkort vha system idkort . Dette er on-demand dokumenter, som skabes ud fra en række bagvedliggende stamdata services.
- Læse servicene i DDS registry/ DDS repository og SFSK gør brug at hjælpe komponenterne BehandlerRelationsService, SamtykkeService og MinLog2 for at sikre borgerens rettigheder. Se evt. DDS anvenderguide for mere beskrivelse.
Ovenstående infrastruktur findes i flere versioner/miljøer. Eksempelvis findes miljøerne test1, test2, prodtest og produktion. Og f.eks. DROS findes i versionerne "Aftaler", "Graviditetsmappe" og "Planer og aftaler".
Hvordan kommer man i gang
Komponenterne i dokumentdelings infrastrukturen kommunikerer med ITI kald, som er standardiserede SOAP services, der skal overholde IHE XDS specifikationen - i det såkaldte XML basererede "RIM format"
Det er op til anvenderen/udvikleren selv at vælge platform og frameworks, der passer til resten af dennes løsning. Fra et udvikler perspektiv kan man enten vælge selv at generere stubkode ud fra de standardiserede WSDL filer eller at anvende et tredjepartsprodukt. Nedenfor gives et forslag til, hvordan det kan gribes an med tredjepartsproduktet IPF Open eHealth Integration Platform, som forudsætter man arbejder på en java platform. Andre platforme kan have tilsvarende værktøjer og muligheder.
De metadata, man registrerer om dokumentet, skal ligesom CDA headeren, overholde de danske standarder XDS Metadata for Document Sharing. Danish profile og DK-IHE_Metadata-Common_Code_systems-Value_sets.
Da dokumentdelingen kører på NSP og sundhedsdatanettet (SDN) skal man anvende Den gode Web Service og have adgang til SDN for den del af miljøerne. Dette beskrives ikke yderligere her.
OpeneHealth biblioteket til Java
Man kan med fordel inkludere biblioteket IPF Commons IHE XDS i sin kodebase. Her findes både stubbe og en masse anvendelige utilities. Disse kan blandt andet mappe fra den IHE XDS standard specificerede RIM format, til en en "OpeneHealth core model", som er java klasser. Og gør det at udvikle ITI kald lettere at arbejde med.
Helt overordnet kan det at lave et ITI kald deles op i følgende trin
- Opret kald i OpeneHealth core model
- For ITI41 kald indebærer det blandt andet opret/indlæs af dokument samt opret af metadata til senere fremsøgning
- For ITI42, 57 og 61 indebærer det registrering og indeksering af metadata
- For ITI18 skal søgekriterierne angives
- For ITI43 skal dokumentid'erne angives
- Udfør kald - det transformeres til RIM format på vej ud, og tilbage til core model ved returnering vha. openeHealth frameworket
- Aflæs kaldets svar og håndter eventuelle fejl returneret. For ITI-18 og ITI-43 er der ligeledes metadata/dokument id'er henholdsvis dokumenter, der skal håndteres.
Dette kan illustreres ved følgende transformeringsdiagram, hvor man ser core modellen blive transformateret til RIM formatet og efterfølgende et ITI kald udført. Resultatet af ITI kaldet kommer tilbage i RIM format, og transformeres til core modellen:
| Gliffy Diagram | ||||||
|---|---|---|---|---|---|---|
|
Et eksempel på, hvordan forskellen mellem core model og RIM format kommer til udtryk, ses her for håndtering af confidentiality code og CPR nummer i forbindelse med oprettelse af et dokument.
Først OpeneHealth core model, den kode man skriver i sit program:
| Code Block | ||||
|---|---|---|---|---|
| ||||
documentEntry.getConfidentialityCodes().add(new Code("N", new LocalizedString("N"), "2. | ||||
| Code Block | ||||
| ||||
<ns2:Classification classificationScheme="urn:uuid:f4f85eac-e6cb-4883-b524-f2705394840f" classifiedObject="urn:uuid:69d3b9f3-7919-40e0-8731-32fb339216c2" nodeRepresentation="N" id="urn:uuid:9068bc2b-1717-4337-abfb-027f303b20c6"> <ns2:Slot name="codingScheme"> <ns2:ValueList> <ns2:Value>2.16.840.1.113883.5.25")); AssigningAuthority patientIdAssigningAuthority = new AssigningAuthority("1.2.208.176.1.2"); Code patientCode = new Code("2512489996", new LocalizedString("CPR"), "1.2.208.176.1.2"); documentEntry.setPatientId(new Identifiable(patientCode, patientIdAssigningAuthority)); |
Og her tilsvarende RIM format, som openeHealth oversætter det til, og som anvendes ved ITI kaldet:
| Code Block | ||||
|---|---|---|---|---|
| ||||
<ns2:Classification classificationScheme25</ns2:Value> </ns2:ValueList> </ns2:Slot> <ns2:Name> <ns2:LocalizedString xml:lang="en-US" charset="UTF-8" value="N"/> </ns2:Name> </ns2:Classification> <ns2:ExternalIdentifier registryObject="urn:uuid:69d3b9f3f4f85eac-7919e6cb-40e04883-8731b524-32fb339216c2f2705394840f" identificationSchemeclassifiedObject="urn:uuid:58a6f84169d3b9f3-87b37919-4a3e40e0-92fd8731-a8ffeff9842732fb339216c2" valuenodeRepresentation="2512489996^^^&1.2.208.176.1.2&ISON" id="urn:uuid:6dc240d89068bc2b-d8711717-4df14337-b8c6abfb-3414f1415022027f303b20c6"> <ns2:Name>Slot name="codingScheme"> <ns2:LocalizedString value="XDSDocumentEntry.patientId"/> </ns2:Name> </ns2:ExternalIdentifier> |
Vigtige Objekter og id'er
Når man arbejder med OpeneHealth core model er der nogle centrale klasser/objekter man arbejder med. 3 af dem er SubmissionSet, DocumentEntry og Relation:
| Gliffy Diagram | ||||||||
|---|---|---|---|---|---|---|---|---|
|
(Simplificert figur efter figur 4.1-1 i ITI TF-3. Da man på NSP ikke arbejder med folders er disse elementer udeladt)
ValueList>
<ns2:Value>2.16.840.1.113883.5.25</ns2:Value>
</ns2:ValueList>
</ns2:Slot>
<ns2:Name>
<ns2:LocalizedString xml:lang="en-US" charset="UTF-8" value="N"/>
</ns2:Name>
</ns2:Classification>
<ns2:ExternalIdentifier registryObject="urn:uuid:69d3b9f3-7919-40e0-8731-32fb339216c2" identificationScheme="urn:uuid:58a6f841-87b3-4a3e-92fd-a8ffeff98427" value="2512489996^^^&1.2.208.176.1.2&ISO" id="urn:uuid:6dc240d8-d871-4df1-b8c6-3414f1415022">
<ns2:Name>
<ns2:LocalizedString value="XDSDocumentEntry.patientId"/>
</ns2:Name>
</ns2:ExternalIdentifier> |
Vigtige Objekter og id'er
Når man arbejder med OpeneHealth core model, er der nogle centrale klasser/objekter at beskæftige sig med. 3 af dem er SubmissionSet, DocumentEntry og Association:
| Gliffy Diagram | ||||||||
|---|---|---|---|---|---|---|---|---|
|
(Simplificeret figur efter figur 4.1-1 i ITI TF-3. Da man på NSP ikke arbejder med folders er disse elementer udeladt)
Man anvender submissionSet, når man skriver data Man anvender submissionSet når man sender data ind (dvs ikke til søgninger). Et submissionSet pakker et kald ind. Indholdet af et submissionSet er documententries og associations. Opretter man Oprettes nye dokumenter, vil der i et submissionset være en eller flere documentEntries (et for hvert dokument) og tilsvarende antal "SE-DE HasMember" associationer. Tilsvarende gælder for ret dokument. Men her vil der yderligere være en "Relationship" association af typen "replace". Sletter (deprecate) man Ugyldiggøres et dokument, har man ikke en documentEntry, men en "Relationship" association af typen "update availability status".
Når man opretter et documentEntry, skal der sættes et entryUuid på. Dette id er vigtigt, da det anvendes i forbindelse med senere ret og slet (deprecate) af ugyldiggørelse af dokumentet. Det skal have prefix "urn:uuid:" for at være et entryUuid, ellers vil det blive opfattet som et symbolsk id, og den kaldte komponent vil selv tildele et gyldigt entryUuid.
Når man udfylder documentEntry udfyldes med metadata, skal man huske de førnævnte CDA standarder. Er der tale om et stable dokument, kan man overveje, om ikke man ikke med fordel kan hente meget af metadata informationen fra dokumentet selv (fra headeren), ved at deserialisere det.
I forbindelse med, at man opretter oprettelse af associationer, skal der angives en source og target entryuuid, udover associationens egen entryUuid. Her gælder
- For opret af dokumenter: source er submissionSet entryUuid og target er documentEntry 's entryUuid
- For ret, ; som for opret. Men den Den ekstra "replace" association: source er source nye dokuments dokumentEntry entryUuid og target det gamle dokumentdokumentEntry entryUuid
- For slet (deprecate)ugyldiggørelse: source er submissionSet entryUuid, og target er documentEntry entryUuid for det dokument, som skal slettes
TODO: hvilke id'er er vigtige ud over de nævne?
- ugyldiggøres
På NSP er der På NSP er der 3 forskellige måder at lave en fremsøgning på:
- FindDocuments: Den traditionelle måde, hvor man opsætter en række søgekriterier som dato interval, dokument status, dokument type typekode mm.
- FindDocuemensByReference: her søge efter dokumentreferencer, man måtte have sat på da dokumentet blev oprettet kombineret med andre almindelige søgekriterier
- GetDocuments: her fremsøges dokumenterne efter entryuuid eller uniqueid
Når man laver en fremsøgning med ITI-18, kan man få to forskellige typer af objekter tilbage, baseret på den retur type man sætter i kaldet. NSP understøtter een:
- LeafClass: her returnes en liste af matchende documentEntry med fuld metadata
- ObjectRef: her returnes en liste af objekt referencer, som entryuuid
...
- indhold
Eksempler på kald
Det følgende er eksempelkode til at illustrere et ITI-41 kald til oprettelse af et dokument
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
// Nyt kald/request
ProvideAndRegisterDocumentSet provideAndRegisterDocumentSet = new ProvideAndRegisterDocumentSet();
// Opret documentEntry
DocumentEntry documentEntry = new DocumentEntry();
AssigningAuthority patientIdAssigningAuthority = new AssigningAuthority("1.2.208.176.1.2"); // OID for CPR registret
Identifiable patientIdentifiable = patientIdentifiable = new Identifiable("2512489996", patientIdAssigningAuthority);
documentEntry.setPatientId(patientIdentifiable);
... mere metadata, se CDA profilen
// Tilføj dokumentet til request
provideAndRegisterDocumentSet.getDocuments().add(new Document(documentEntry, new DataHandler(new ByteArrayDataSource(documentPayload.getBytes(), documentEntry.getMimeType()))));
// Opret SubmissionSet
provideAndRegisterDocumentSet.setSubmissionSet(createSubmissionSet(documentEntry.getPatientId(), contentTypeCode, submissionTime));
// Opret association mellem SubmissionSet og DocumentEntry
provideAndRegisterDocumentSet.getAssociations().add(createAssociation(submissionSet, documentEntry));
// Transformer request - dette laver core model om til RIM format
ProvideAndRegisterDocumentSetTransformer registerDocumentSetTransformer = new ProvideAndRegisterDocumentSetTransformer(ebXMLFactory);
EbXMLProvideAndRegisterDocumentSetRequest30 ebxmlRequest = (EbXMLProvideAndRegisterDocumentSetRequest30) registerDocumentSetTransformer.toEbXML(provideAndRegisterDocumentSet);
ProvideAndRegisterDocumentSetRequestType provideAndRegisterDocumentSetRequestType = ebxmlRequest.getInternal();
// Udfør kald
RegistryResponseType registryResponse = iti41PortType.documentRepositoryProvideAndRegisterDocumentSetB(provideAndRegisterDocumentSetRequestType);
// Transformer response - dette laver RIM format til core model
ResponseTransformer responseTransformer = new ResponseTransformer(ebXMLFactory);
Response response = responseTransformer.fromEbXML(new EbXMLRegistryResponse30(registryResponse));
// Aflæs kaldets svar
if (response.getStatus().equals(Status.SUCCESS)) {
// Kaldet gik godt
} else
if (response.getStatus().equals(Status.PARTIAL_SUCCESS) || response.getStatus().equals(Status.FAILURE)) {
// Der er warning eller fejl i kaldet, håndter dem
for (ErrorInfo error : response.getErrors()) {
}
} |
...
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
// Nyt kald/request
FindDocumentsQuery findDocumentsQuery = new FindDocumentsQuery();
// Opret søge kriterier
AssigningAuthority patientIdAssigningAuthority = new AssigningAuthority("1.2.208.176.1.2"); // OID for CPR registret
Identifiable patientIdentifiable = patientIdentifiable = new Identifiable("2512489996", patientIdAssigningAuthority);
findDocumentsQuery.setPatientId(patientIdentifiable); // angiv patienten dokumenterne vedrører
List<AvailabilityStatus> searchStatusList = new LinkedList<AvailabilityStatus>();
searchStatusList.add(AvailabilityStatus.APPROVED);
findDocumentsQuery.setStatus(searchStatusList); // søg efter dokumenter, som har status approved
findDocumentsQuery.getServiceStartTime().setFrom(serviceStartTimeFrom); // søg efter specifik dato interval som start tidspunkt
findDocumentsQuery.getServiceStartTime().setTo(serviceStartTimeTo); // ved at angive fra og til serviceStartTime
QueryRegistry queryRegistry = new QueryRegistry(findDocumentsQuery);
queryRegistry.setReturnType(QueryReturnType.LEAF_CLASS); //returner fuld metadata for de fremsøgte dokumenter
// Transformer request - dette laver core model om til RIM format
QueryRegistryTransformer requestTransformer = new QueryRegistryTransformer();
EbXMLAdhocQueryRequest30 ebxmlRequest = (EbXMLAdhocQueryRequest30) requestTransformer.toEbXML(queryRegistry);
AdhocQueryRequest adhocQueryRequest = ebxmlRequest.getInternal();
// Udfør kald
AdhocQueryResponse adhocQueryResponse = iti18PortType.documentRegistryRegistryStoredQuery(adhocQueryRequest);
// Transformer response - dette laver RIM format til core model
QueryResponseTransformer responseTransformer = new QueryResponseTransformer(ebXMLFactory);
EbXMLQueryResponse ebXML = new EbXMLQueryResponse30(adhocQueryResponse);
QueryResponse queryResponse = responseTransformer.fromEbXML(ebXML);
// Aflæs kaldets svar
if (queryResponse.getStatus().equals(Status.SUCCESS)) {
// Kaldet gik godt, håndter de fremsøgte dokumenter metadata
for (DocumentEntry documentEntry : queryResponse.getDocumentEntries()) {
}
} else
if (queryResponse.getStatus().equals(Status.PARTIAL_SUCCESS) || queryResponse.getStatus().equals(Status.FAILURE)) {
// Der er warning eller fejl i kaldet, håndter dem
for (ErrorInfo error : queryResponse.getErrors()) {
}
}
|
Sammenholder man ovenståede kodeekspempler Nærlæser man ovenstående kodeeksempler, kan man genkende ovenstående transformeringsfigurs kasser i kodelinierne. Eksempelvis for ITI-41 kaldet, hvor hvor line 1-18 svarer til boks 2 (core model), linie 20-23 til boks 2 og 3 (core model og RIM format), linie 26 til kaldet mellem boks 3 (RIM format) og NSP komponenten, linie 28-30 til boks 3 og 2 (RIM format og core model) samt linie 32-40 til boks 2 (core model)
Savner man Savnes inspiration til kodeeksempler, er også integrationstestene til f.eks. DROS og NXRG et godt sted at kigge.
...
| Code Block | ||||
|---|---|---|---|---|
| ||||
ID: 2
Response-Code: 200
Encoding: UTF-8
Content-Type: application/soap+xml;charset=UTF-8
Headers: {connection=[keep-alive], content-type=[application/soap+xml;charset=UTF-8], Date=[Thu, 24 Feb 2022 14:12:50 GMT], transfer-encoding=[chunked]}
Payload:
<?xml version="1.0" encoding="UTF-8"?>
<soap:Envelope xmlns:soap="http://www.w3.org/2003/05/soap-envelope">
<soap:Header>
.. soap headers fjernet for overskueligehed...
</soap:Header>
<soap:Body>
<ns6:AdhocQueryResponse xmlns:ns6="urn:oasis:names:tc:ebxml-regrep:xsd:query:3.0" xmlns:ns5="urn:oasis:names:tc:ebxml-regrep:xsd:lcm:3.0" xmlns:ns4="urn:ihe:iti:xds-b:2007" xmlns:ns3="urn:oasis:names:tc:ebxml-regrep:xsd:rs:3.0" xmlns:ns2="urn:oasis:names:tc:ebxml-regrep:xsd:rim:3.0" totalResultCount="2" status="urn:oasis:names:tc:ebxml-regrep:ResponseStatusType:Success">
<ns2:RegistryObjectList>
<ns2:ObjectRef id="urn:uuid:a573c596-6cc4-40e4-85c2-529d2fbf6914"/>
<ns2:ObjectRef id="urn:uuid:4a68ec73-f9c1-4a32-8b50-1c8d585f6590"/>
</ns2:RegistryObjectList>
</ns6:AdhocQueryResponse>
</soap:Body>
</soap:Envelope> |
Biblioteker til .Net
TODO: find noget
https://www.iheusa.org/sites/iheusa/files/IHE%20Profiles%20for%20Health%20Information%20Exchange.pdf
https://groups.google.com/g/ihe-north-america-connectathon-2007/c/dLNk8mWoMVY
Hjælpeværktøjer og links
De følgende links kan alle bidrage til at lette arbejdet med at implementere dokumentdeling.
:ebxml-regrep:xsd:rs:3.0" xmlns:ns2="urn:oasis:names:tc:ebxml-regrep:xsd:rim:3.0" totalResultCount="2" status="urn:oasis:names:tc:ebxml-regrep:ResponseStatusType:Success">
<ns2:RegistryObjectList>
<ns2:ObjectRef id="urn:uuid:a573c596-6cc4-40e4-85c2-529d2fbf6914"/>
<ns2:ObjectRef id="urn:uuid:4a68ec73-f9c1-4a32-8b50-1c8d585f6590"/>
</ns2:RegistryObjectList>
</ns6:AdhocQueryResponse>
</soap:Body>
</soap:Envelope> |
Dokumenttype-adskillelse i XDS-infrastrukturen
For at smidiggøre infrastrukturen ift. performance, vedligehold og sikkerhed er det besluttet, at vi fremadrettet etablerer separate registries (indexes) og repositories for hver dokumenttype (typecode). Dette er endvidere i fin overensstemmelse med den domænebaserede målarkitektur, der baserer sig på IHE-XCA-profilen.
Da data i registry (SDS patientindex) og repository registreres via Dokument Registrerings- og Opdateringsservicen (DROS), skal der tilsvarende etableres en separat DROS tilknyttet hvert par af registry (SDS patientindex) og repository, så vi ender op med en separat trio DROS/registry/repository per dokumenttype.
Dette betyder, at der vil være et separat endpoint pr dokumenttype, som anvenderne skal anvende, når dokumenter registreres (og opdateres). Der vil til gengæld fortsat kun være behov for ét endpoint til dokumentdelingsservicen, når man skal fremsøge dokumenter.
Hjælpeværktøjer og links
De følgende links kan alle bidrage til at lette arbejdet med at implementere dokumentdeling.
| Værktøj | Beskrivelse | Link |
|---|---|---|
| DDS | Guide til anvendere, når man skal læse data:
| https://www.nspop.dk/display/public/web/DDS+-+Guide+til+anvendere |
| DROS | Guide til anvendere, når man skal skrive data:
| https://www.nspop.dk/display/public/web/DROS+-+Guide+til+anvendere |
| Aftaleoversigt | Siden beskriver de tekniske forretningsregler i forhold til at implementere Aftaleoversigten i et lokal fagsystem eller en borgerportal. | Aftaleoversigt |
| Aftaler | Beskriver servicearkitekturen, der ligger bag deling af aftaler via NSP | https://www.nspop.dk/display/public/web/Aftaler |
| NSP test endpoints | For test1 kan man anvende endpoints til højre. Ønskes i stedet adgang til test2, skiftet "test1" ud med "test2". sts endpointet anvendes i forbindelse med at man trækker et idkort til DGWS. | Alle test miljøer: Endpoints for eksterne testmiljøer iti18: http://test1-cnsp.ekstern-test.nspop.dk:8080/ddsregistry |
| Værktøj | Beskrivelse | Link |
| DDS | Guide til anvendere
| https://www.nspop.dk/display/public/web/DDS+-+Guide+til+anvendere |
| DROS | Guide til anvendere Når man skal skrive noget:
| https://www.nspop.dk/display/public/web/DROS+-+Guide+til+anvendere |
| Aftaleoversigt | Siden beskriver de tekniske forretningsregler i forhold til at implementere Aftaleoversigten i et lokal fagsystem eller en borgerportal. | Aftaleoversigt |
| Aftaler | Beskriver servicearkitekturen, der ligger bag deling af aftaler via NSP | https://www.nspop.dk/display/public/web/Aftaler |
| Medcom CDA Viewer | Her kan man fremsøge, hente, oprette, rette og slette ugyldiggøre (deprecate) dokumenter dokumenter på test1 og test2 Hvis man f.eks har lavet et ITI-41 kald til en service, og vil se, at dokumentet blev registreret og gemt, kan man fremsøge og hente det her. Skal man lave en ITI-18 fremsøgning kan man oprette dokumenter oprettes her først. Det er også muligt at downloade request og response (RIM format) ved de forskellige udførsler. Det kan anvendes til sammenligning med et ITI kald, man sidder og udvikler på og som f.eks. driller. Adgang kræver login, kontakt Medcom | https://cdaviewer.medcom.dk/cdaviewer/ |
| Medcom CDA Validator | Her findes en CDA validator, der kan checke om et CDA dokument opfylder den danske profil. | https://cda.medcom.dk/ |
| Medcom CDA builder/parser | Bibliotek der kan benyttes til at serialisere og deserialisere CDA dokumenter standardiseret af MedCom. Herunder udtræk af metadata. | https://bitbucket.org/4s/4s-cda-builder/src/master/4s-cda-builders/ |
| MedCom igang guide | Medcoms "kom godt igang med dokumentdeling" Beskrivelsen er mere bred end, den i dette her dokument og går også mere i detaljer på udvalgte punkter. Den er dog ikke helt opdateret på alle punkter. | https://www.medcom.dk/media/10982/kom-godt-igang-med-dokumentdeling-14-interactive.pdf |
...