Indhold
Indledning
Dette dokument indeholder analyse af log data fra den første performance test, som er kørt for Minlog2. Testene er kørt forår 2020. Analysen dækker
- MinLog2 - Performancetest rapport borger lookup
- MinLog2 - Performancetest rapport medhjælper lookup
- MinLog2 - Performancetest rapport minlog1 lookup
- MinLog 2 - Performancetest rapport registration
Detaljer omkring performance test vejledningen findes her. Her kan læses omkring de log filer, som ligger til grund for analysen, hvilket scope testen er kørt i, hvordan test er kørt og hvilke krav, der er til komponenten under test.
Se iøvrigt krav til performance test og rapport på siden https://www.nspop.dk/display/public/web/Performancekrav
Læsevejledning
Læseren forventes at have kendskab til National Sundheds-IT's platform NSP, samt generelt kendskab til WildFly applikation server, MariaDB, Kafka og java.
Dokumenthistorik
Version | Dato | Ansvarlig | Beskrivelse |
1.0 | 14-12-2020 | KvalitetsIT | Dokument oprettet som en kopi af test rapport Tekst, som ikke har med performance test er fjernet Test vejledning er fjernet, da dette findes andetsteds |
Definitioner og forkortelser
Definition | Beskrivelse |
NSP | Den nationale service platform (inden for sundheds-IT) |
MinLog2 - Performancetest rapport borger lookup
Performance testen består af en række kald til opslag efter logninger på forskellige cpr numre. Et sådant enkelt opslag vil svare til, hvad en borger vil udføre, skulle han ville se, hvad der er registreret om ham.
Testen udført er komponent "minlog2", testplan "lookupidws" og distribution "test900".
MinLog 2 service er version 2.0.25perf og NSP standard performance test framework version 2.0.21.
De rå test resultater er vedhæftet denne side (minlog2_lookupidws_test900_run1.tar.gz)
JMeter log
JMeter hoved filen beskriver overordnet testens resultat. Her kan kan ses, at der er kørt 10 iterationer med test, deres tidsinterval , throughput og fejlprocent for hver.
Iteration | Tråde | Nodes | Starttid | Sluttid | Throughput | Fejlprocent |
|---|---|---|---|---|---|---|
| 1 | 1 | 2 | 2020-03-12_10-02-36 | 2020-03-12_10-17-40 | 3,26 kald per sekund | 0 % |
| 2 | 2 | 2 | 2020-03-12_10-17-57 | 2020-03-12_10-33-00 | 5,89 kald per sekund | 0 % |
3 | 3 | 2 | 2020-03-12_10-33-19 | 2020-03-12_10-48-23 | 8,6 kald per sekund | 0 % |
| 4 | 4 | 2 | 2020-03-12_10-48-40 | 2020-03-12_11-03-45 | 10,89 kald per sekund | 0 % |
| 5 | 5 | 2 | 2020-03-12_11-04-01 | 2020-03-12_11-19-05 | 12,91 kald per sekund | 0 % |
| 6 | 6 | 2 | 2020-03-12_11-19-22 | 2020-03-12_11-34-27 | 14,42 kald per sekund | 0 % |
| 7 | 6 | 3 | 2020-03-12_11-34-47 | 2020-03-12_11-49-50 | 20,82 kald per sekund | 0 % |
| 8 | 6 | 4 | 2020-03-12_11-50-26 | 2020-03-12_12-05-39 | 26,93 kald per sekund | 0 % |
| 9 | 6 | 5 | 2020-03-12_12-06-40 | 2020-03-12_12-21-43 | 34,04 kald per sekund | 0,008 % |
| 10 | 6 | 6 | 2020-03-12_12-22-36 | 2020-03-12_12-37-41 | 37,12 kald per sekund | 0 % |
Det fremgår også af filen, at den endelige måling af throughput er 37,12 kald per sekund.
Samt at fejlprocentet på den fulde kørsel er 0 %.
Access log
Denne log findes for hver applikations server (docker container).
Her findes data for hvert enkelt kald, der er lavet til minlog servicen, herunder hvor lang tid et kald har taget (Duration), samt hvornår kaldet er udført. Ud fra loggens data kan man også beregne hvor mange kald der udføres i en given periode.
De følgende 2 grafer viser 95 % hendholdsvis 98 % percentil for kaldende. Grupperingen er 10 minutter:
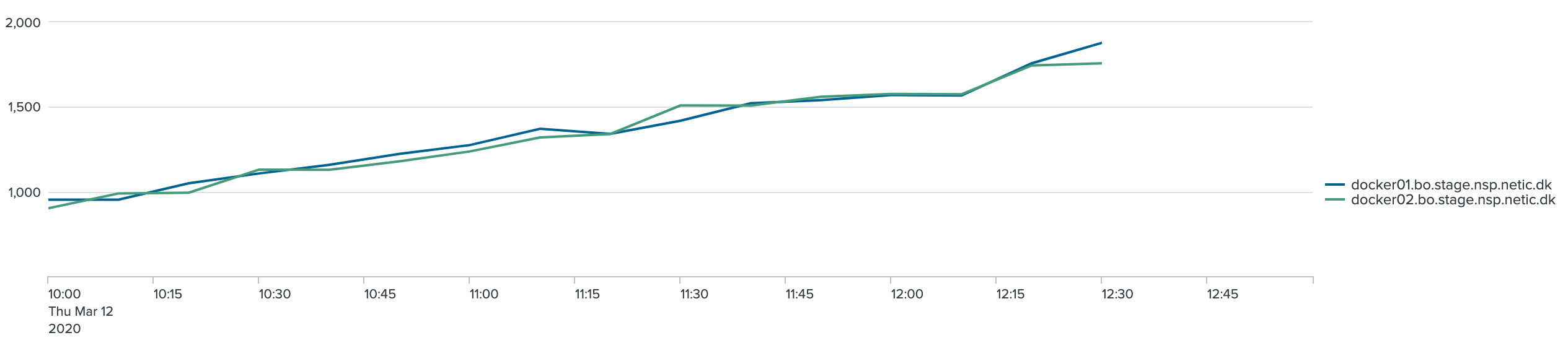
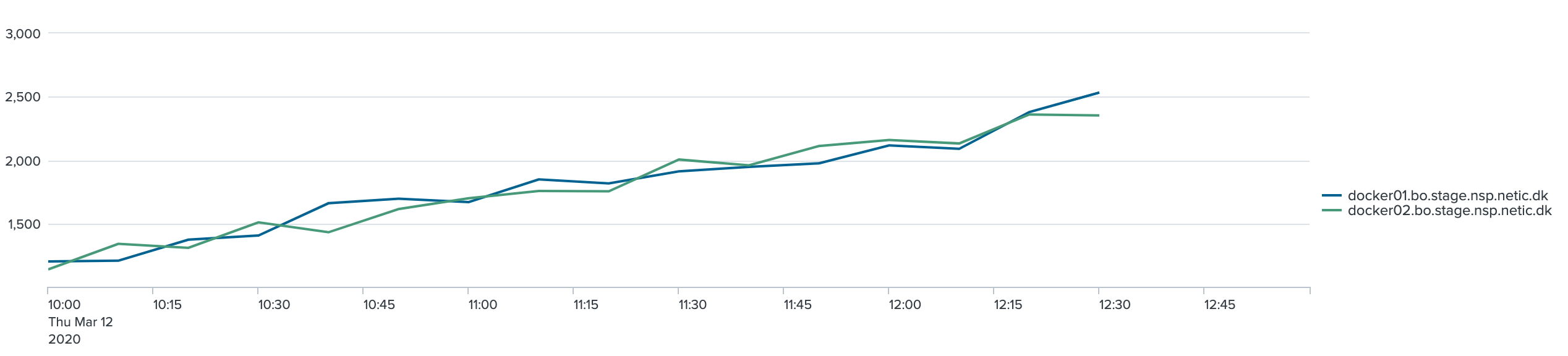
Det ses af graferne, at jo flere nodes/tråde jo højere bliver svar tiden overordnet set.
Den næste graf viser antal kald per sekund:
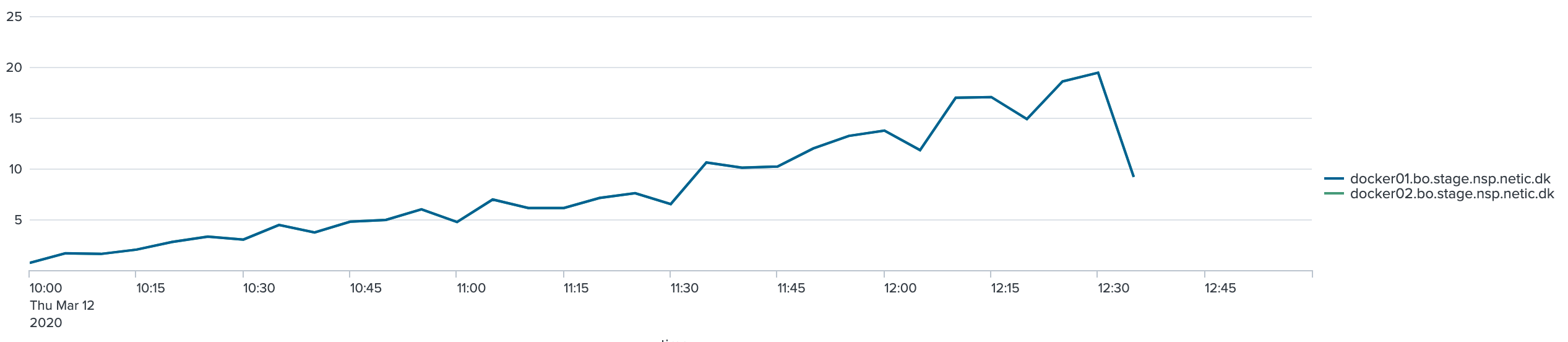
Af grafen fremgår det, at jo flere nodes og tråde (disse øges over tid, per iteration) jo flere kald kommer der igennem per sekund overordnet set.
Vurdering
Performance kravene
- under 2,50 sekund for 95 % af tilfældende; dette overstiges ifølge "95 % percentil grafen" ikke. Max svartiden er her under 2 sekund
- under 5,5 sekund for 98 % af tilfældende; dette overstiges ifølge "98 % percentil grafen" ikke. Max svartiden er her under 2,6 sekunder
Vi er inden for performance kravene i testens fulde køretid.
Vmstat log
Denne log findes for hver applikations server (docker container). Den viser resultatet af kommandoen vmstat
Udtræk omkring cpu fra denne log vises i de følgende grafer:
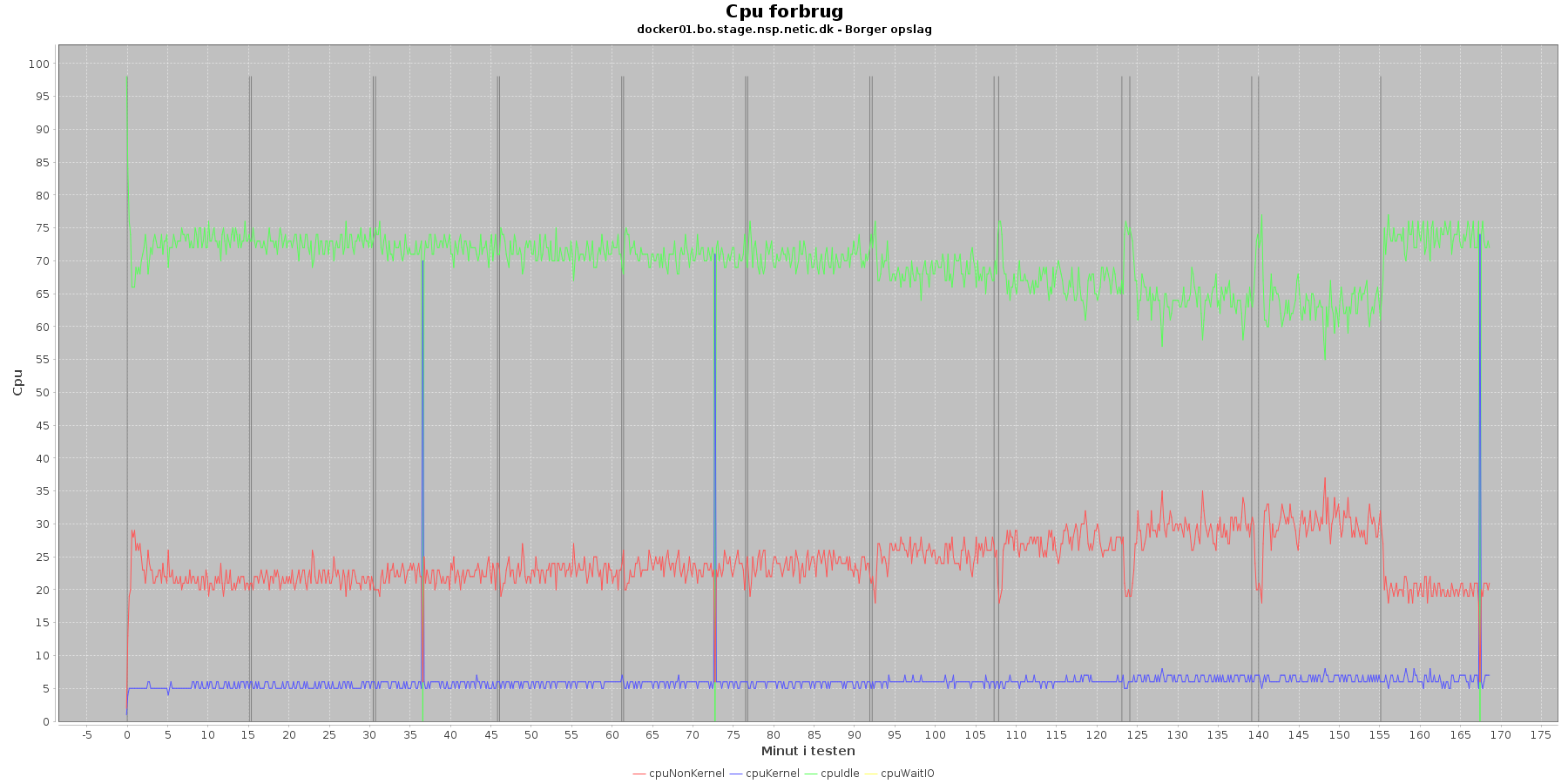
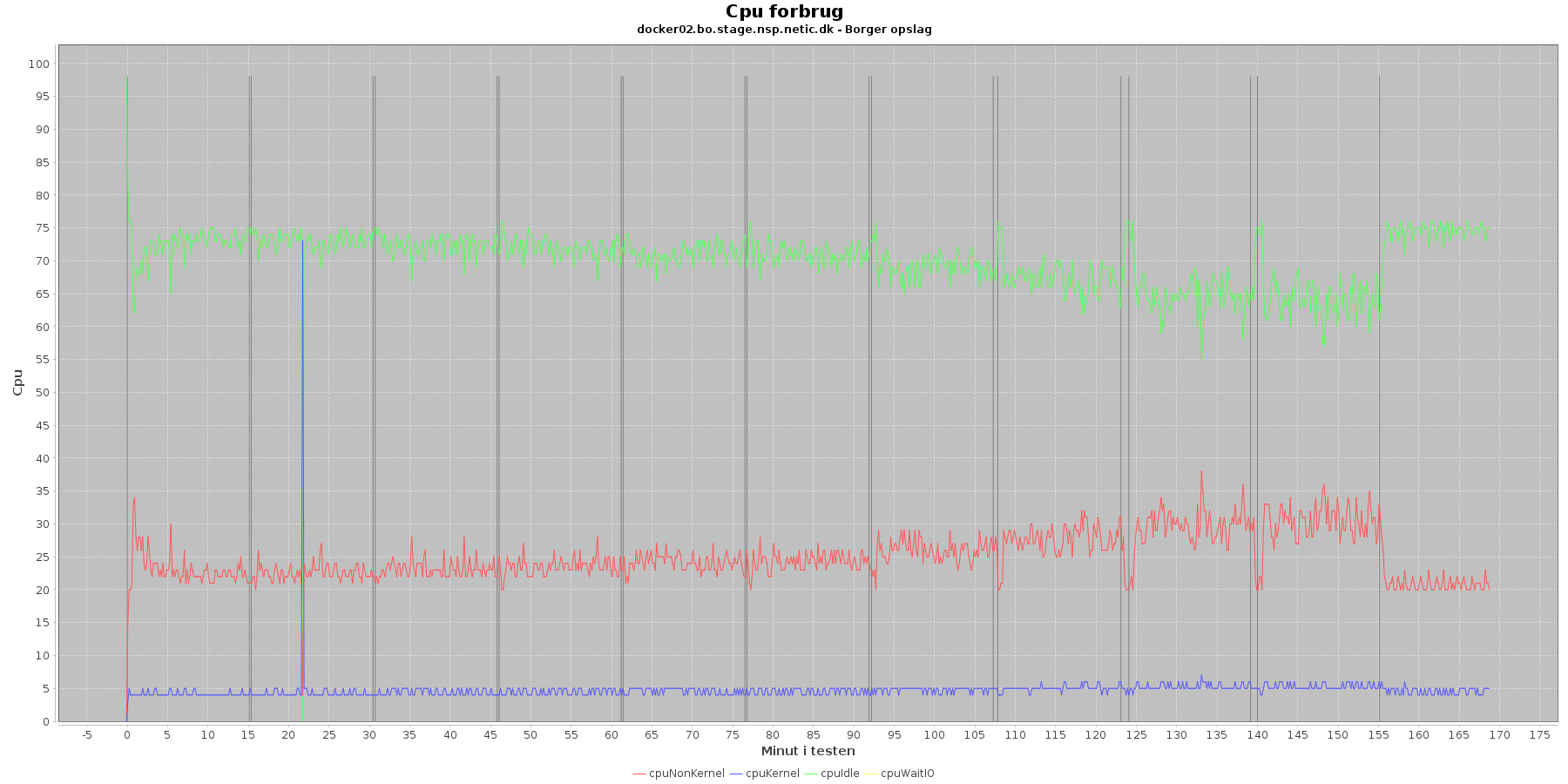
Data serier i grafen er:
- cpuNonKernel (rød): tid brugt på non-kernel opgaver
- cpuKernel (blå): tid brugt på kernel opgaver
- cpuIdle (grøn): tid brugt på ingenting
- cpuWaitIO (gul): tid brugt på at vente på i/o
- iterationerne (sort) er en cirka placering, da wmstat loggen ikke indeholder tidstempel
Man kan se at cpuIdle og cpuNonKernel påvirkes lidt som servicen presses mere. cpuIdle ligger lavere over tid, mens cpuNonKernel grafen ligger en smule højere over tid. Den generelle flyt af kurverne er dog ikke faretruende.
Man kan også se, at cpuIdle dykker til 0 nogle få gange hen over iterationerne. Når dette sker er der en stigning i cpuKernal. Udsvingende vender dog retur til udgangspunktet.
Udtræk omkring io læs og skriv fra vmstat vises i de følgende grafer:
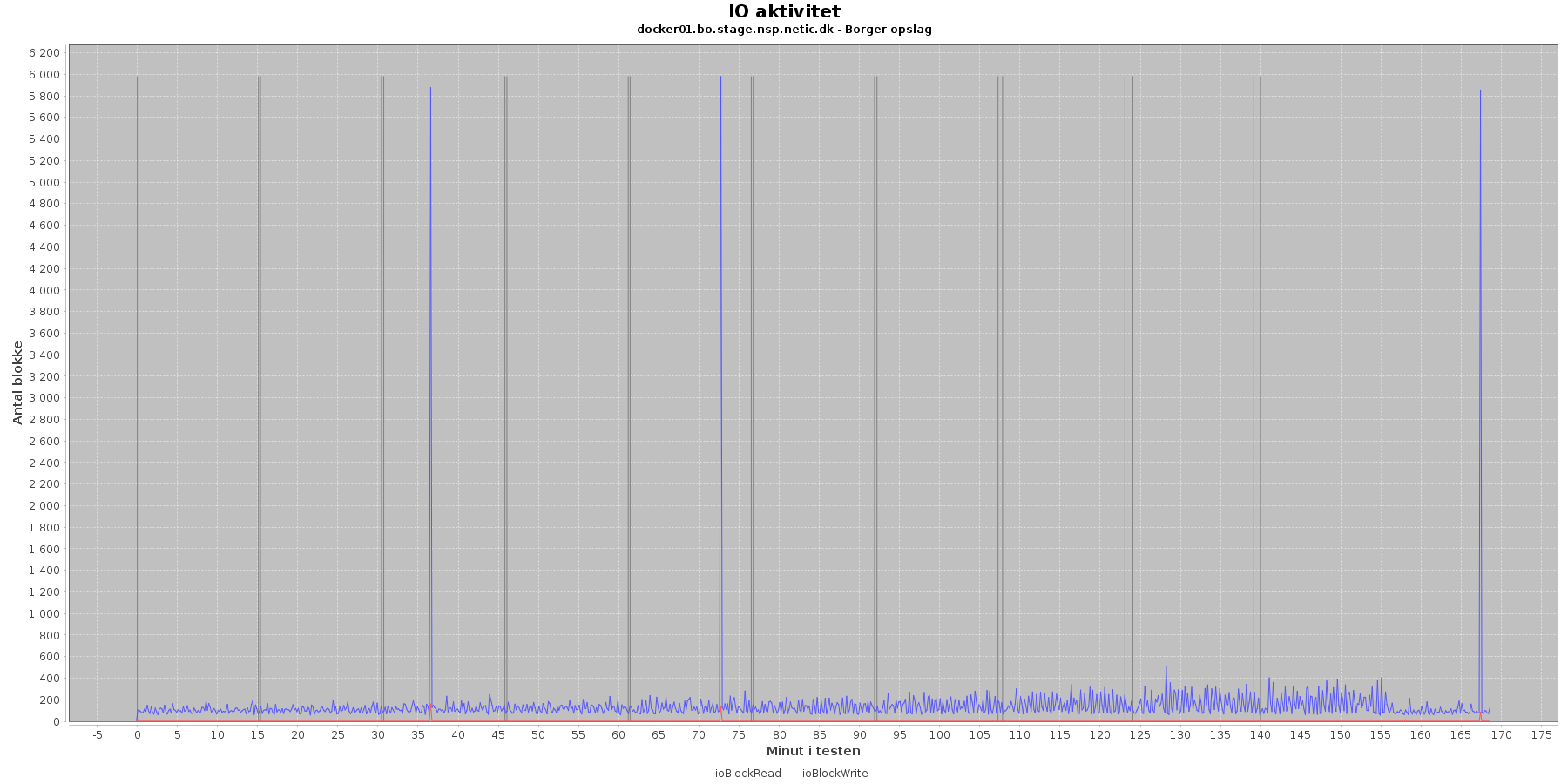
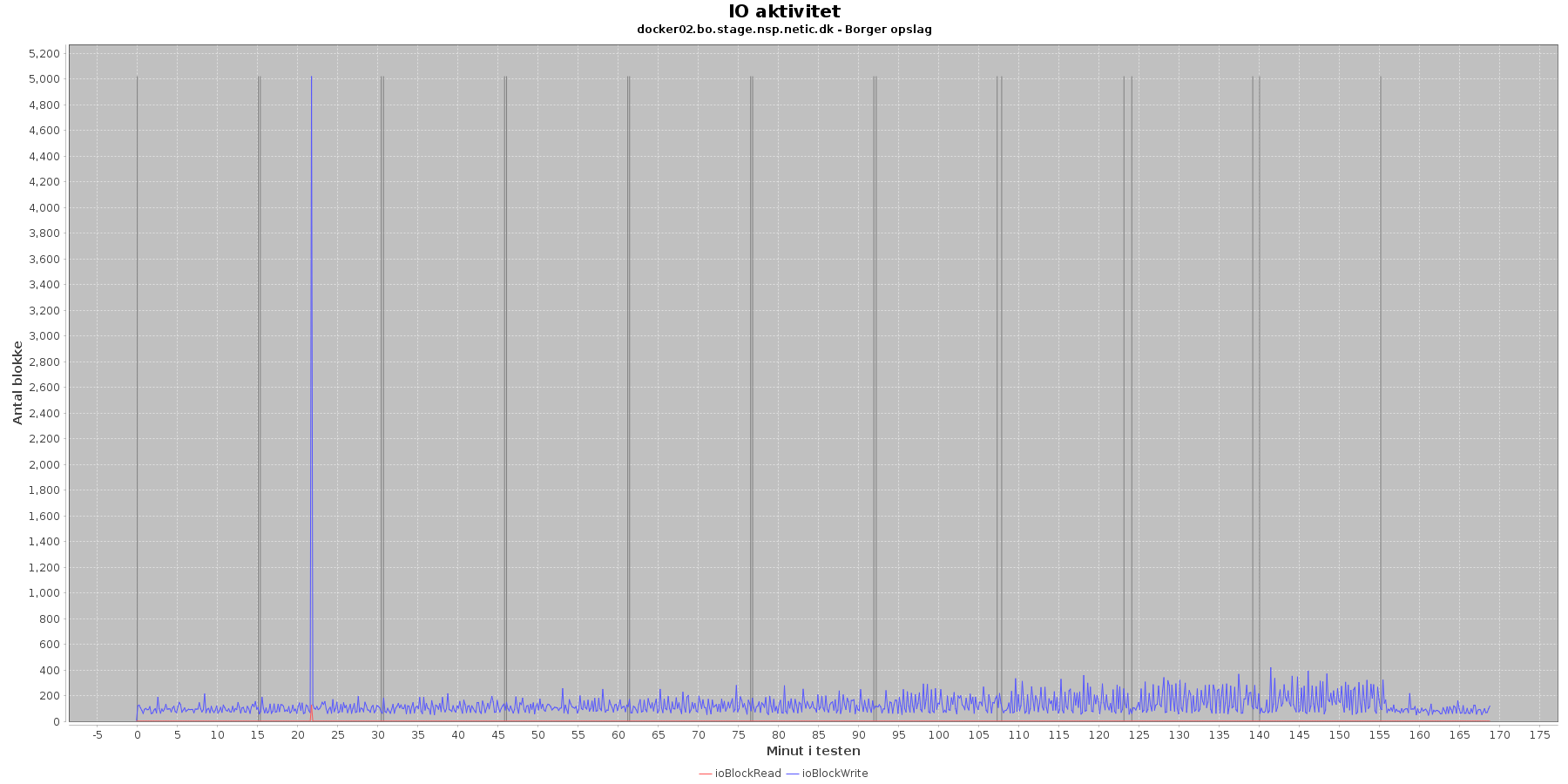
Data serier i grafen er:
- ioBlockRead (rød): læsning på disk (blokke)
- ioBlockWrite (blå): skriving på disk (blokke)
- iterationerne (sort) er en cirka placering, da wmstat loggen ikke indeholder tidstempel
Der er lidt løbende skriv til disken mens testen kører, og sammenligner man graferne fra før på cpu forbrug, ses det, at de få store udsving i skrivninger falder sammen med at cpuKernal går op og cpuIdle går ned.
Vurdering
Der er intet negativt at bemærke omkring cpu forbruget eller io.
Jstat log
Denne log findes for hver applikations server (docker container). Loggen viser resultatet af kommandoen jstat. Jstat siger noget om, hvordan JVM'en har det.
Udtræk omkring hukommelse og garbage collection fra denne log vises i de følgende grafer:
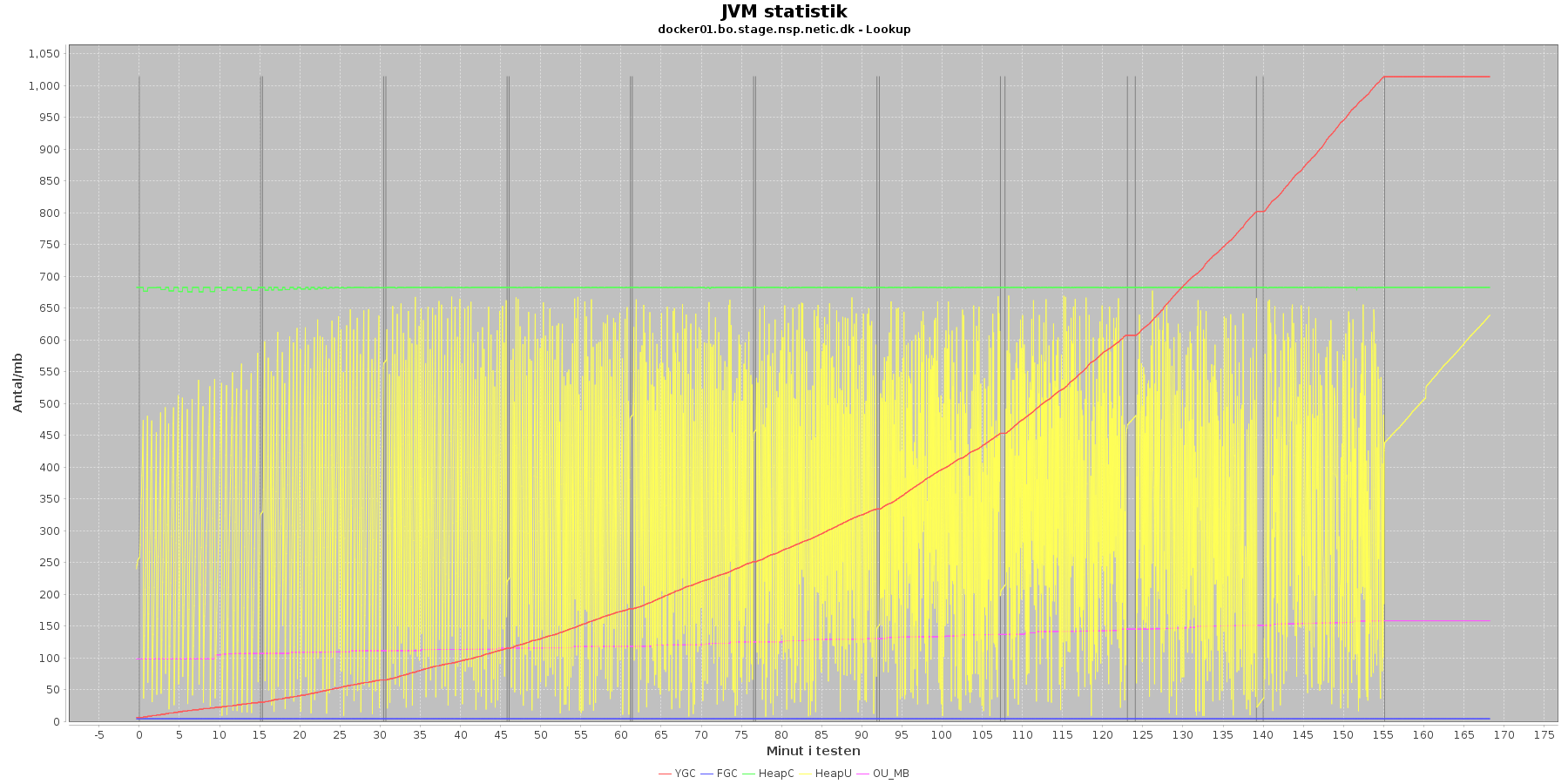
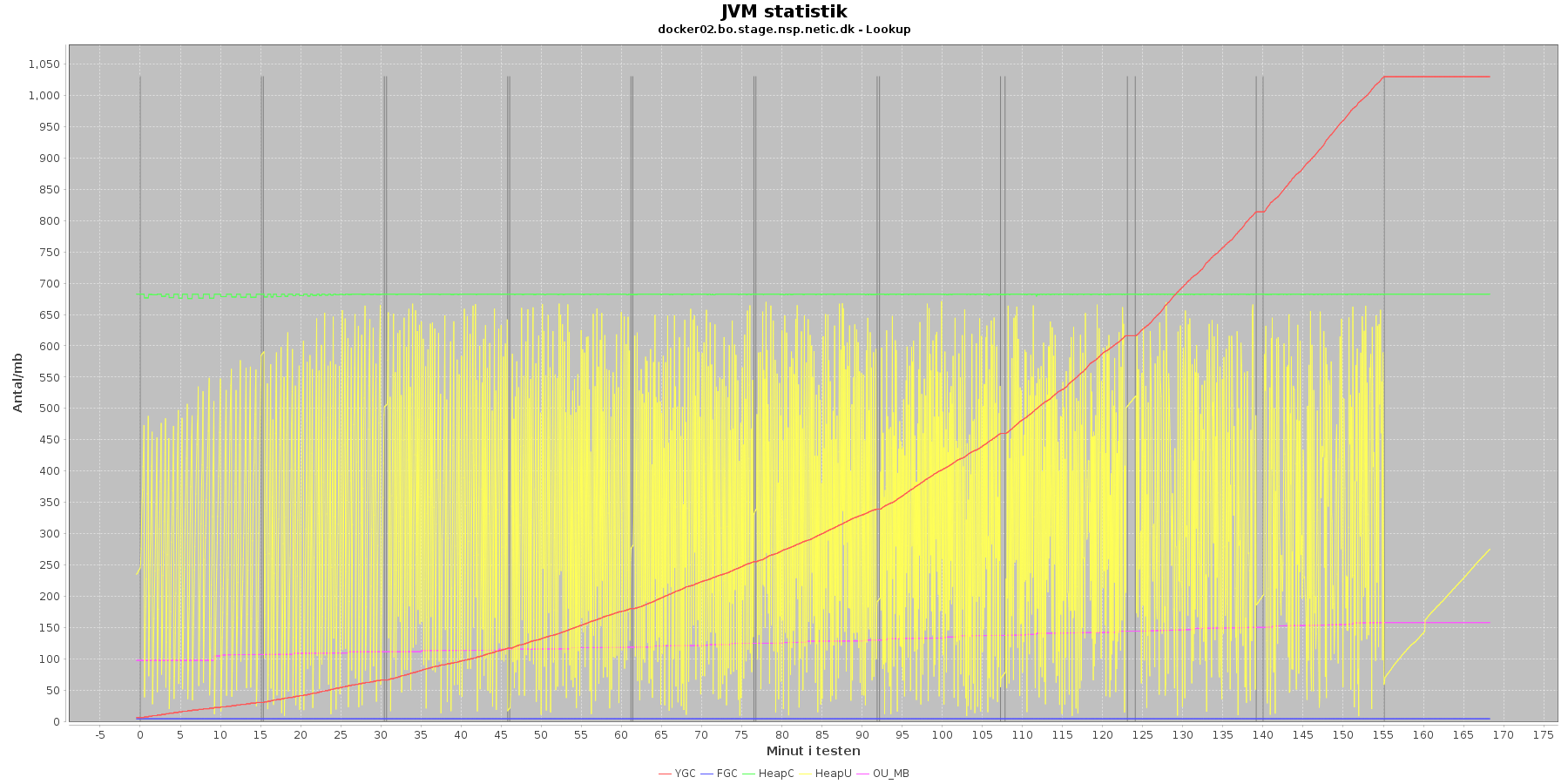
Data serier i grafen er:
- YGC (rød): young generation garbage collection events, antal af "ung" garbage collection siden start
- FGC (blå): full garbage collection events, antal af fuldstændig garbage collection siden start
- HeapU (gul): består af S0U+S1U+EU fra jstat loggen. Young generation memory utilization. "Ung" hukommelses forbrug
- HeapC (grøn): består af S0C+S1C+EC fra jstat loggen. Young generation memory capacity. "Ung" hukommelses kapacitet
- OU_MB (pink): old space utilization. "Ældre" hukommelses forbrug
- OC: old space capacity. "Ældre" hukommelses kapacitet er ikke en del af grafen men er konstant på 1.398.272 KB.
- Iterationer (sort) er baseret på det tidstempel, som findes i jstatloggen
Det kan være lidt svært at se graferne for full garbage collection (FGC). Kigger man nærmere på datagrundlaget bag graferne, ses det, at der ikke er full garbage collection for servicen under testen.
Der er en meget svag stigende tendens på den ældre hukommelse (OU_MB). Man må gå ud fra, at kommer den op på en kritisk grænse, da vil systemet køre en full garbage collection (FGC).
Der køres ofte garbage collection på den yngre hukommelse, hvilket holder HeapU - yngre hukommelses forbrug - nede så den kun svinger inden for et konstant interval.
Vurdering
Den yngre forbrugte hukommelse eskalerer ikke. Garbage collecteren gør sit arbejde.
Docker stats log
Denne log findes for hver applikations server (docker container). Loggen viser resultatet af kommandoen docker stats. Docker stats siger noget om, hvordan containeren forbruger sine ressourcer.
Udtræk omkring hukommelse, cpu og netværkstrafik vises i følgende grafer.
Hukommelse:
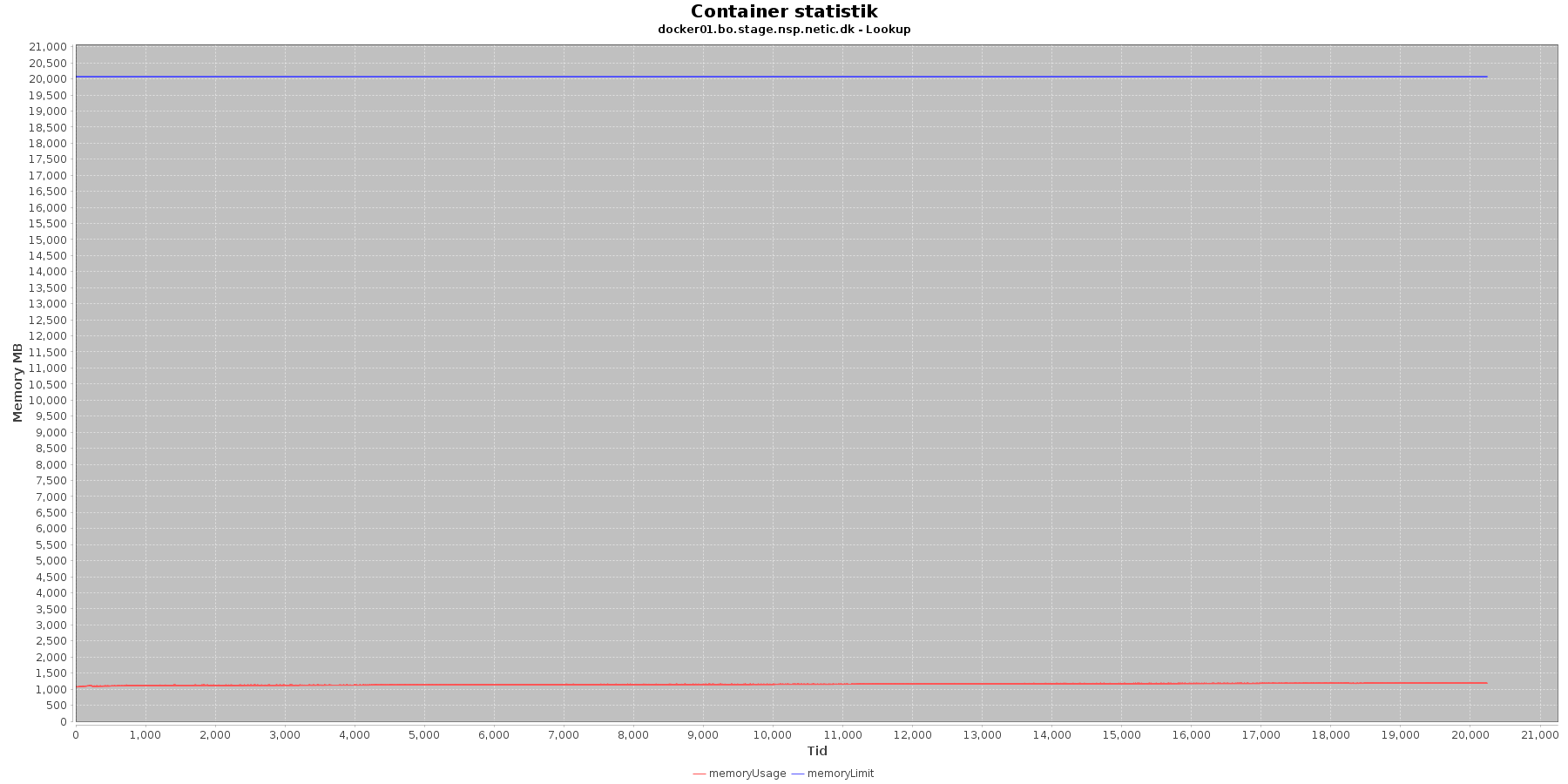
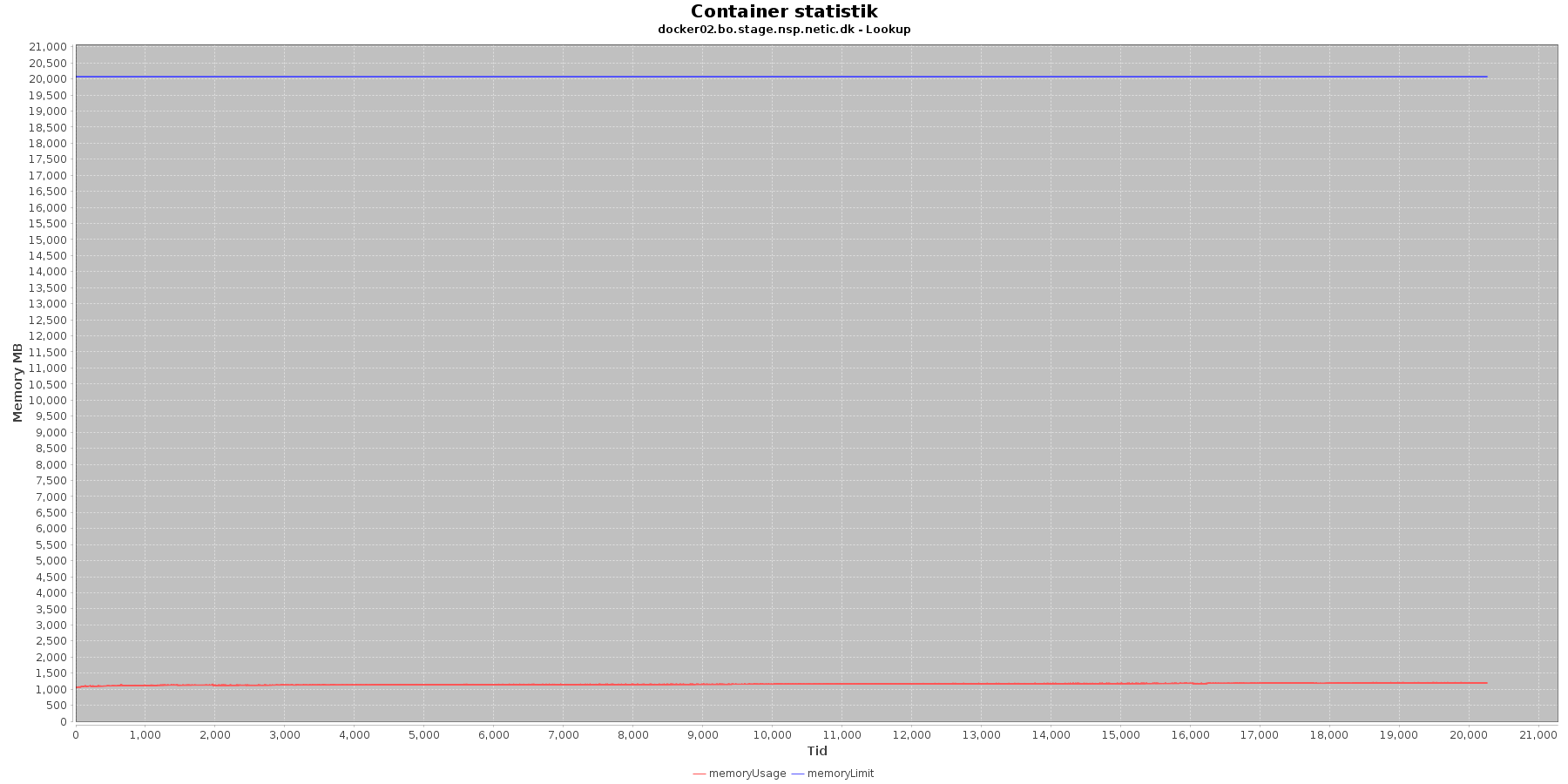
Data serier i grafen er:
- memoryUsage (rød): den totale mængde hukommelse containeren bruger
- memoryLimit (blå): den totale mængde hukommelse contaneren kan bruge
Den forbrugte hukommelse er meget stabil.
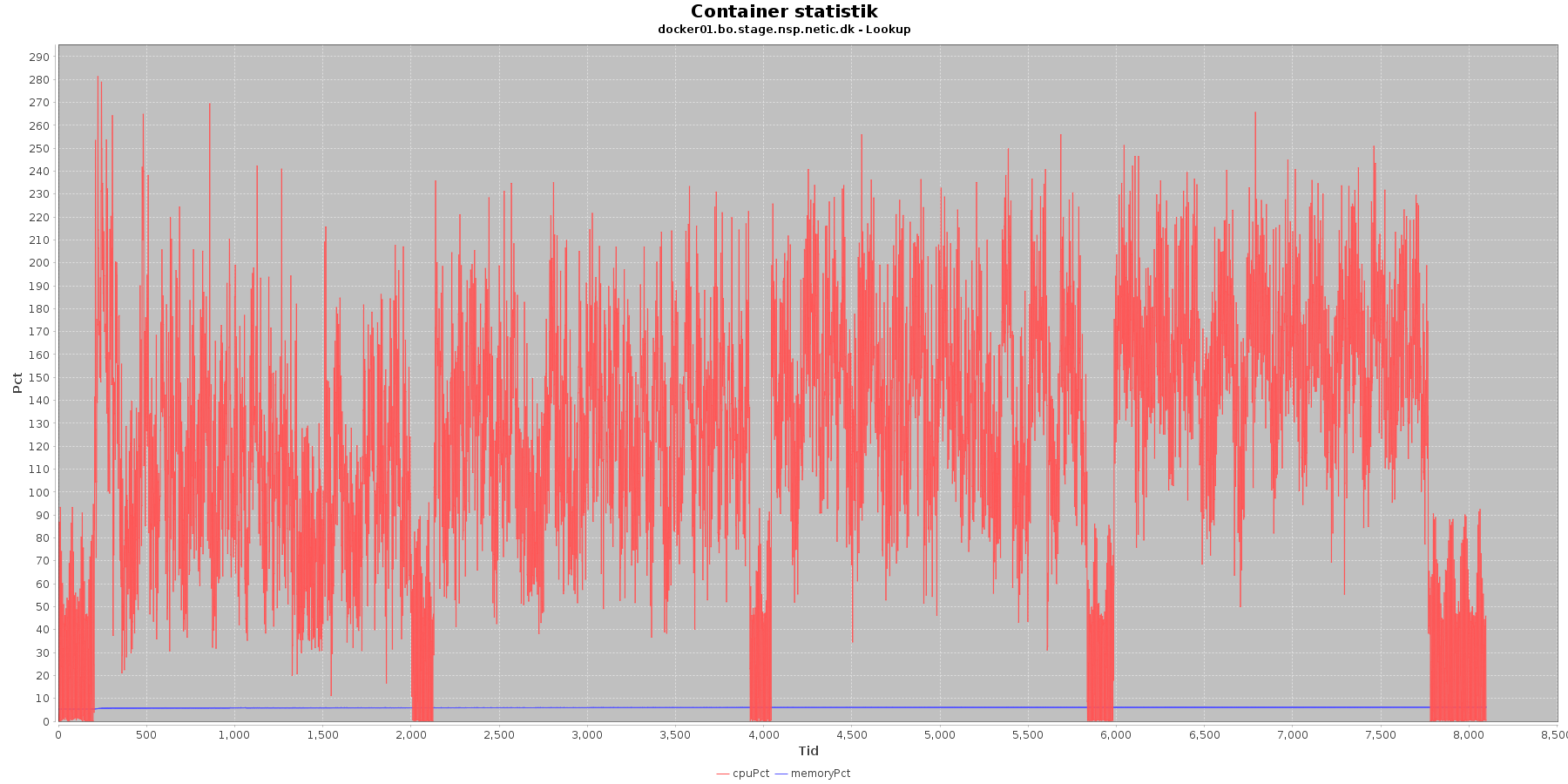
Cpu og hukommelse procent:
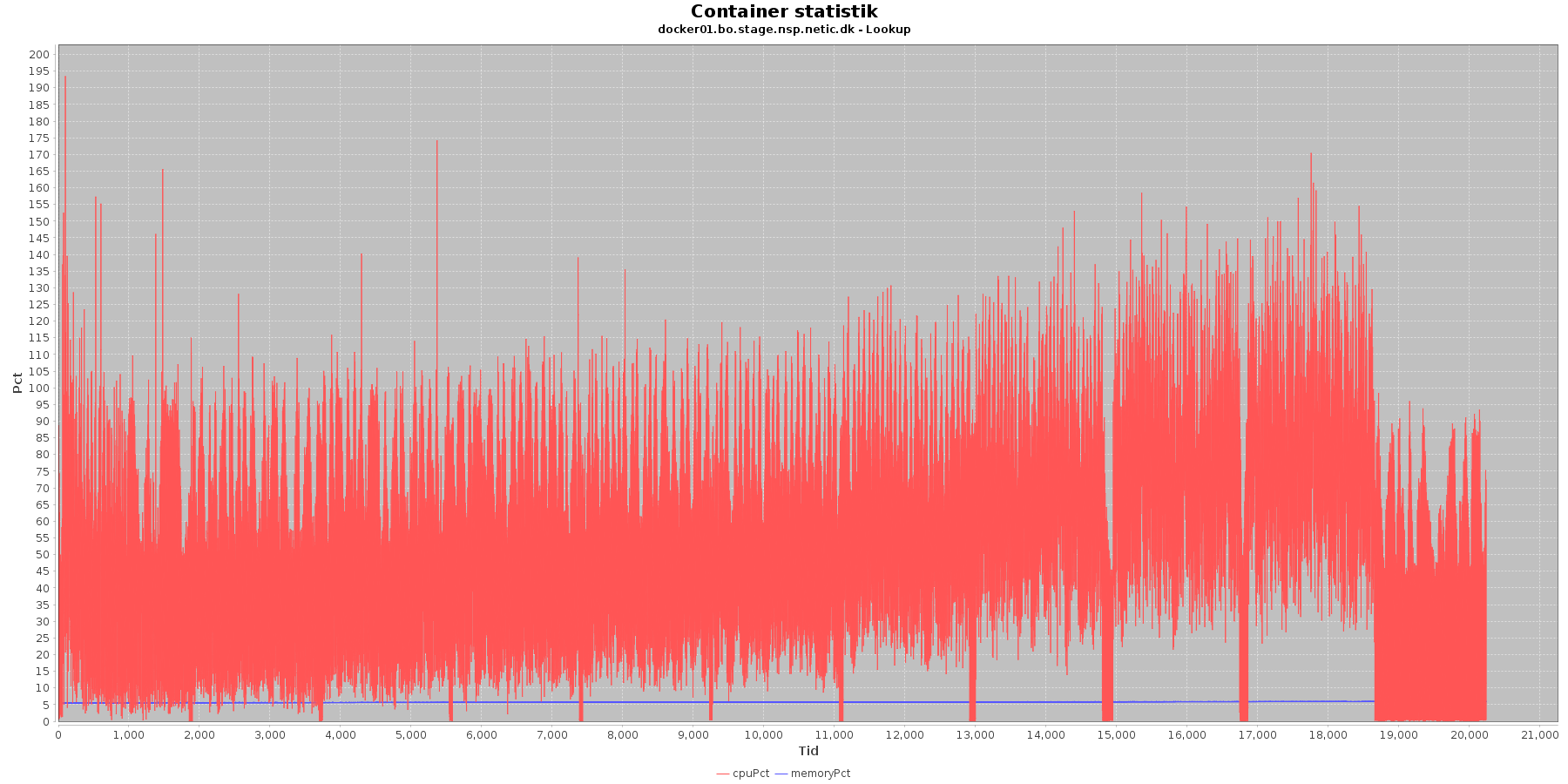
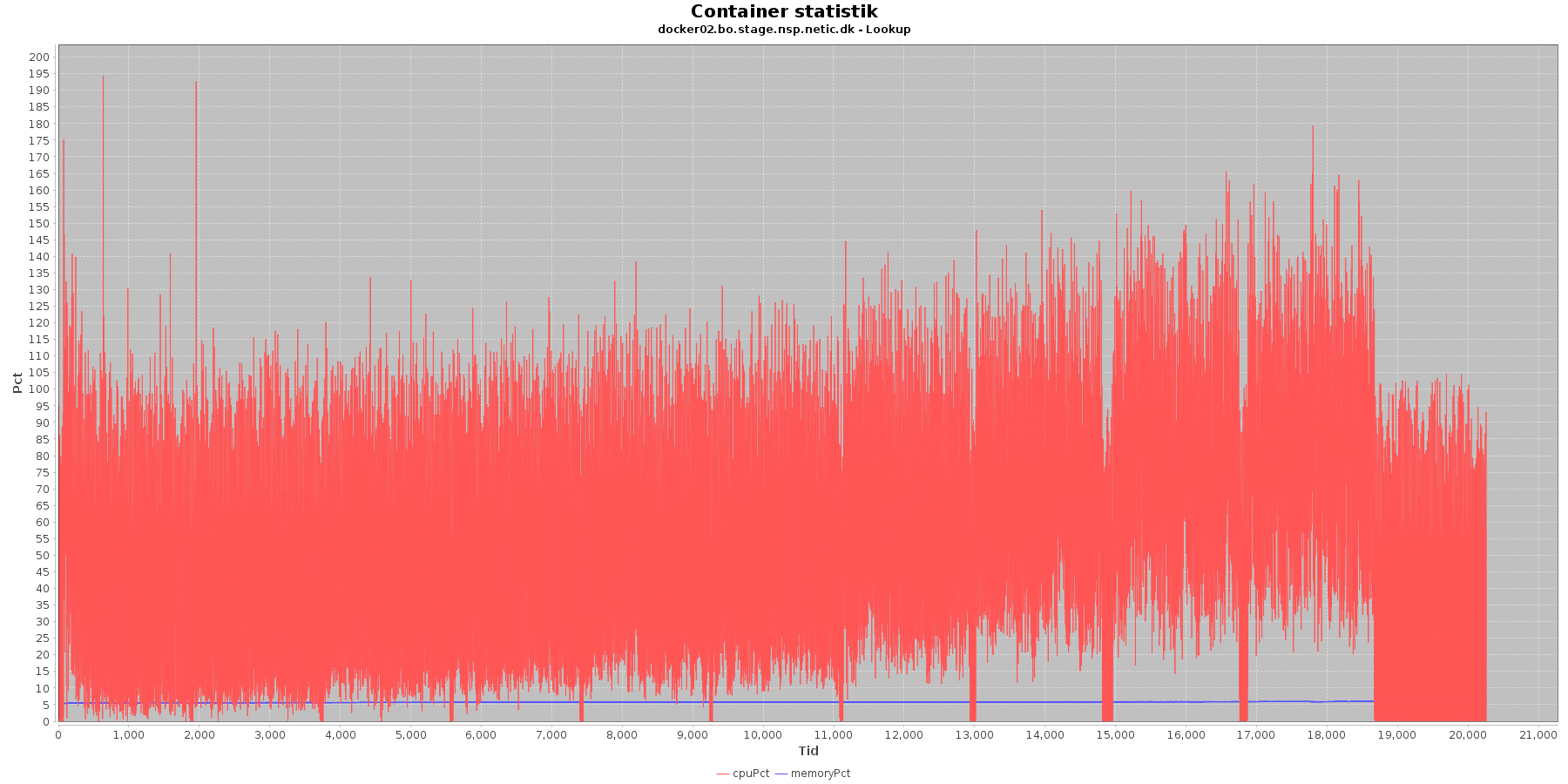
Data serier i grafen er:
- cpuPct (rød): hvor mange procent af hostens cpu containeren bruger
- memoryPct (blå): hvor mange procent af hostens hukommelse containeren bruger
Servicen viser et stabilt forbrug af hukommelse. Den envendte cpu er svagt stigende som servicen bliver presset.
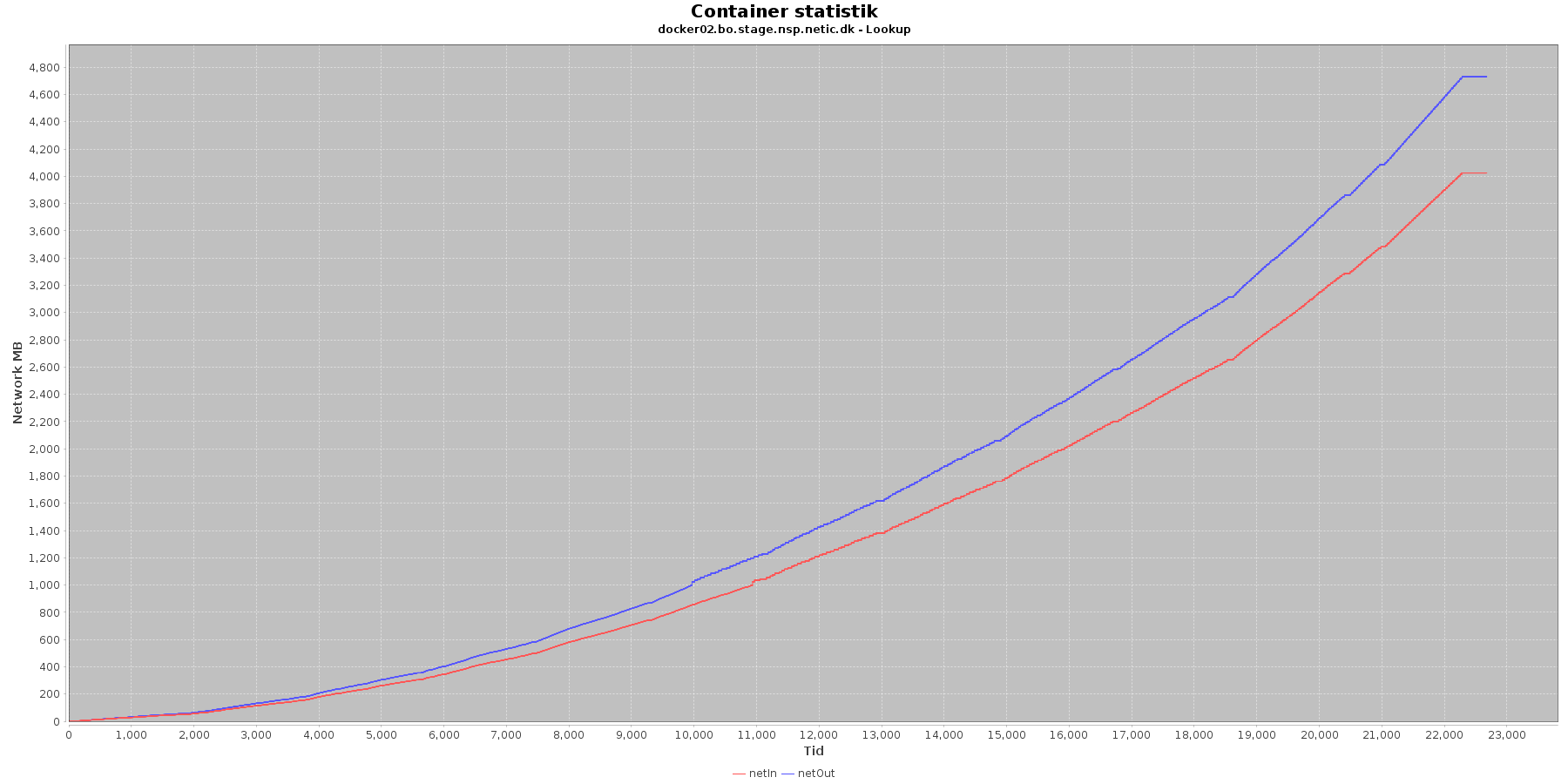
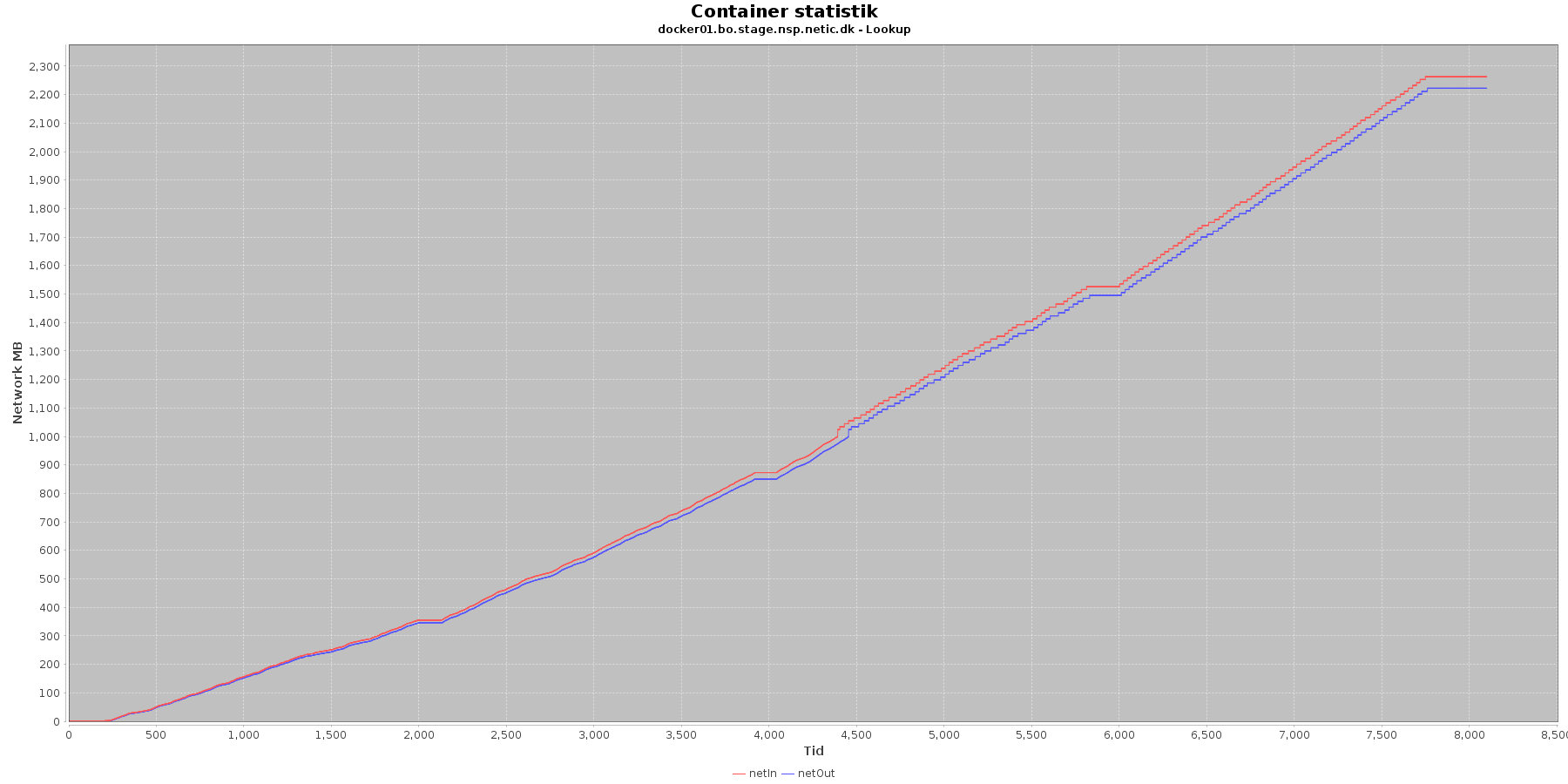
Netværk:
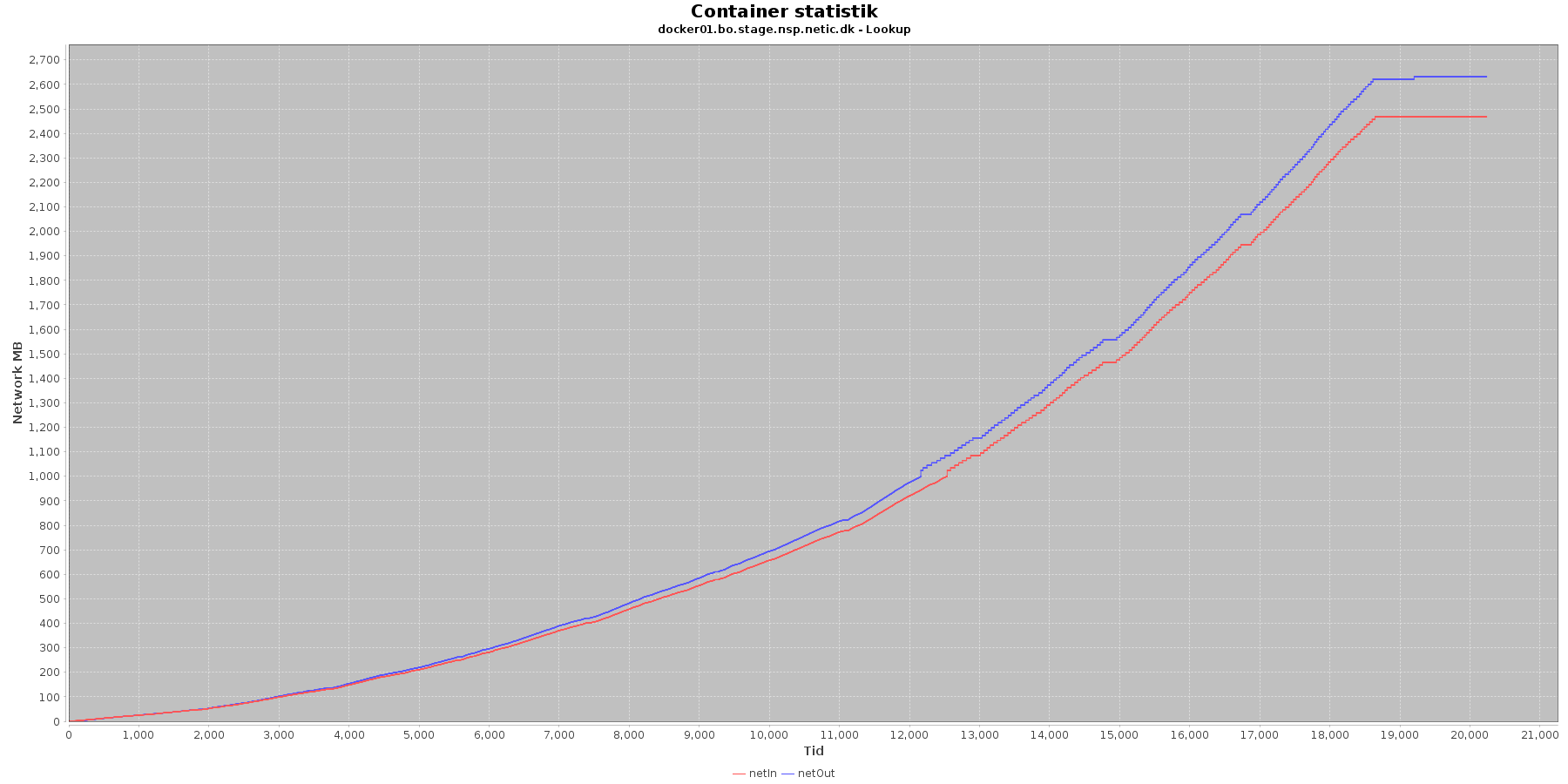
Data serier i grafen er:
- netIn (rød): den mængde data som er modtaget af containeren over netværket
- netOut (blå): den mængde data som er sendt ud af containeren over netværket
De 2 grafer for ind- og udsendt data følges ad, hvilket er forventeligt; indkomne kald skaber trafik til database og igen retur til kalder. netOut stiger mest.
Vurdering
Der er intet at bemærke som kan påvirke servicens performance i negativ retning.
Konklusion
Efter at have analyseres data fra performance testen kan følgende trækkes frem:
- Throughput på testen er 37,12 kald per sekund
- Gennemsnitlig højeste svartid per kald til servicen:
For 95 % percentil: under 2 sekunder
For 98 % percentil: under 2,6 sekunder
Kravene på under 2,5 henholdsvis 5,5 sekunder er overholdt - Cpu status: cpu forbruget stiger lidt over test perioden, som servicen presses mere. Dog kun kortvarigt.
- io på netværk: stiger over tid, hvilket er forventet
- Hukommelses forbrug: servicen håndterer brug af hukommelse fint
- Garbage collection: servicen kører jævnligt garbage collection og dermed stiger hukommelses forbruget ikke over tid. Dette er et tegn på, at vi ikke har memory leaks.
Analysen af performance test data har ikke givet anledning til bekymring eller identificering af flaskehalse.
MinLog2 - Performancetest rapport medhjælper lookup
Performance testen består af en række kald til opslag efter logninger på forskellige cpr numre i medhjælper loggen. Et sådant enkelt opslag vil svare til en læge, der vil verificere, hvilke logninger en given medhjælper har givet anledning til.
Testen udført er komponent "minlog2", testplan "lookup_onbehalfof" og distribution "test900".
MinLog 2 service er version 2.0.24perf og NSP standard performance test framework version 2.0.19
De rå test resultater er vedhæftet denne side (minlog2-lookup_onbehalfof_test900_run1.tar.gz)
Indledningsvis skal siges, at servicen kørende på docker1 gik i fejl sidst i testen pga memory problemer. Der mangler derfor access log data for ca. 10 minutter i slutningen af testen.
JMeter log
JMeter hoved filen beskriver overordnet testens resultat. Her kan kan ses, at der er kørt 12 iterationer med test, deres tidsinterval , throughput og fejlprocent for hver.
Iteration | Tråde | Nodes | Starttid | Sluttid | Throughput | Fejlprocent |
|---|---|---|---|---|---|---|
| 1 | 1 | 2 | 2020-02-20_15-48-53 | 2020-02-20_16-03-57 | 3,91 kald per sekund | 0,030 % |
| 2 | 2 | 2 | 2020-02-20_16-04-13 | 2020-02-20_16-19-18 | 8,13 kald per sekund | 0,025 % |
3 | 3 | 2 | 2020-02-20_16-19-35 | 2020-02-20_16-34-39 | 11,87 kald per sekund | 0,030 % |
| 4 | 4 | 2 | 2020-02-20_16-34-57 | 2020-02-20_16-50-02 | 15,31 kald per sekund | 0,015 % |
| 5 | 5 | 2 | 2020-02-20_16-50-20 | 2020-02-20_17-05-24 | 19,47 kald per sekund | 0,025 % |
| 6 | 6 | 2 | 2020-02-20_17-05-41 | 2020-02-20_17-20-46 | 22,47 kald per sekund | 0,030 % |
| 7 | 7 | 2 | 2020-02-20_17-21-02 | 2020-02-20_17-36-19 | 25,84 kald per sekund | 0,030 % |
| 8 | 8 | 2 | 2020-02-20_17-36-42 | 2020-02-20_17-51-47 | 29,13 kald per sekund | 0,030 % |
| 9 | 9 | 2 | 2020-02-20_17-52-19 | 2020-02-20_18-07-22 | 34,41 kald per sekund | 0,030 % |
| 10 | 10 | 2 | 2020-02-20_18-07-40 | 2020-02-20_18-22-44 | 35,24 kald per sekund | 0,050 % |
| 11 | 10 | 3 | 2020-02-20_18-23-12 | 2020-02-20_18-38-17 | 49,61 kald per sekund | 0,027 % |
| 12 | 10 | 4 | 2020-02-20_18-38-50 | 2020-02-20_18-53-54 | 39,52 kald per sekund | 0,878 % |
Det fremgår også af filen, at den endelige måling af throughput er 49.61 kald per sekund.
Samt at fejlprocentet på den fulde kørsel er 0,027 %.
Throughput falder mellem iteration 11 og 12. Og der er en forøgning af fejl i den sidste iteration.
Access log
Denne log findes for hver applikations server (docker container).
Her findes data for hvert enkelt kald, der er lavet til minlog servicen, herunder hvor lang tid et kald har taget (Duration), samt hvornår kaldet er udført. Ud fra loggens data kan man også beregne, hvor mange kald der udføres i en given periode.
De følgende 2 grafer viser 95 % hendholdsvis 98 % percentil for kaldende. Grupperingen er 10 minutter:
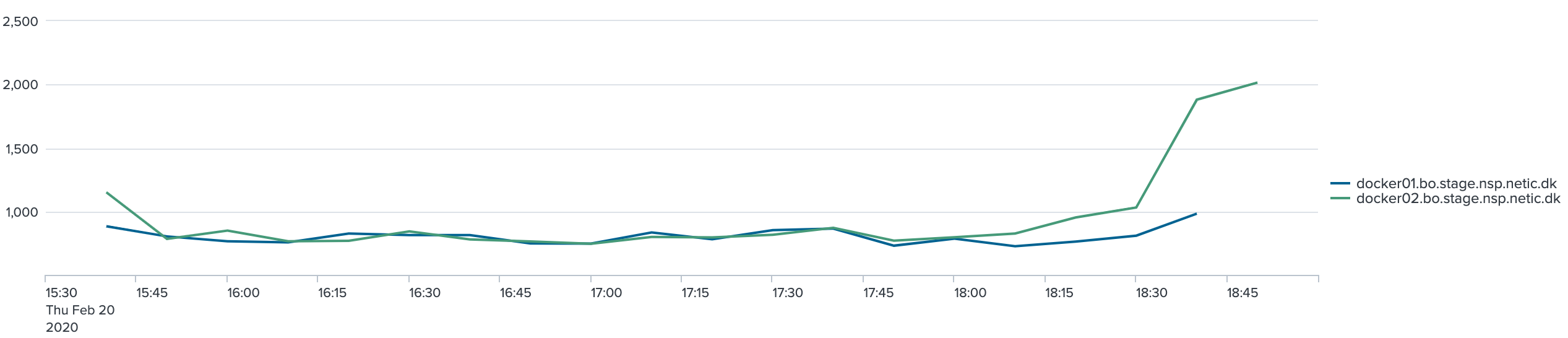
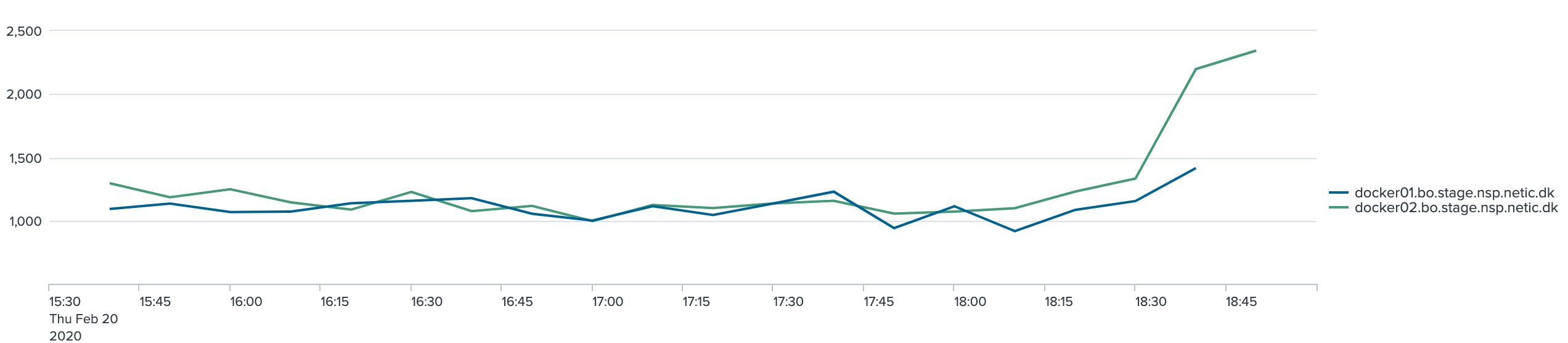
Det ses af graferne, at svartiden ikke ændrer sig med flere nodes/tråde. Først til sidst i testen går den op.
Den næste graf viser antal kald per sekund:

Af grafen fremgår det, at jo flere nodes og tråde (disse øges over tid, per iteration) jo flere kald kommer der igennem per sekund overordnet set.
Servicen kørende på Docker1, som fik problemer sidst i testen, har dog et faldende antal request i sidste iteration.
Vurdering
Performance kravene
- under 2,50 sekund for 95 % af tilfældende; dette overstiges ifølge "95 % percentil grafen" ikke. Max svartiden er her under 2,1 sekunder
- under 5,5 sekund for 98 % af tilfældende; dette overstiges ifølge "98 % percentil grafen" ikke. Max svartiden er her under 2,5 sekunder
Vi er inden for performance kravene i testen fulde køretid, selv i den test iteration, hvor den ene testede service stoppede.
Vmstat log
Denne log findes for hver applikations server (docker container). Den viser resultatet af kommandoen vmstat
Udtræk omkring cpu fra denne log vises i de følgende grafer:
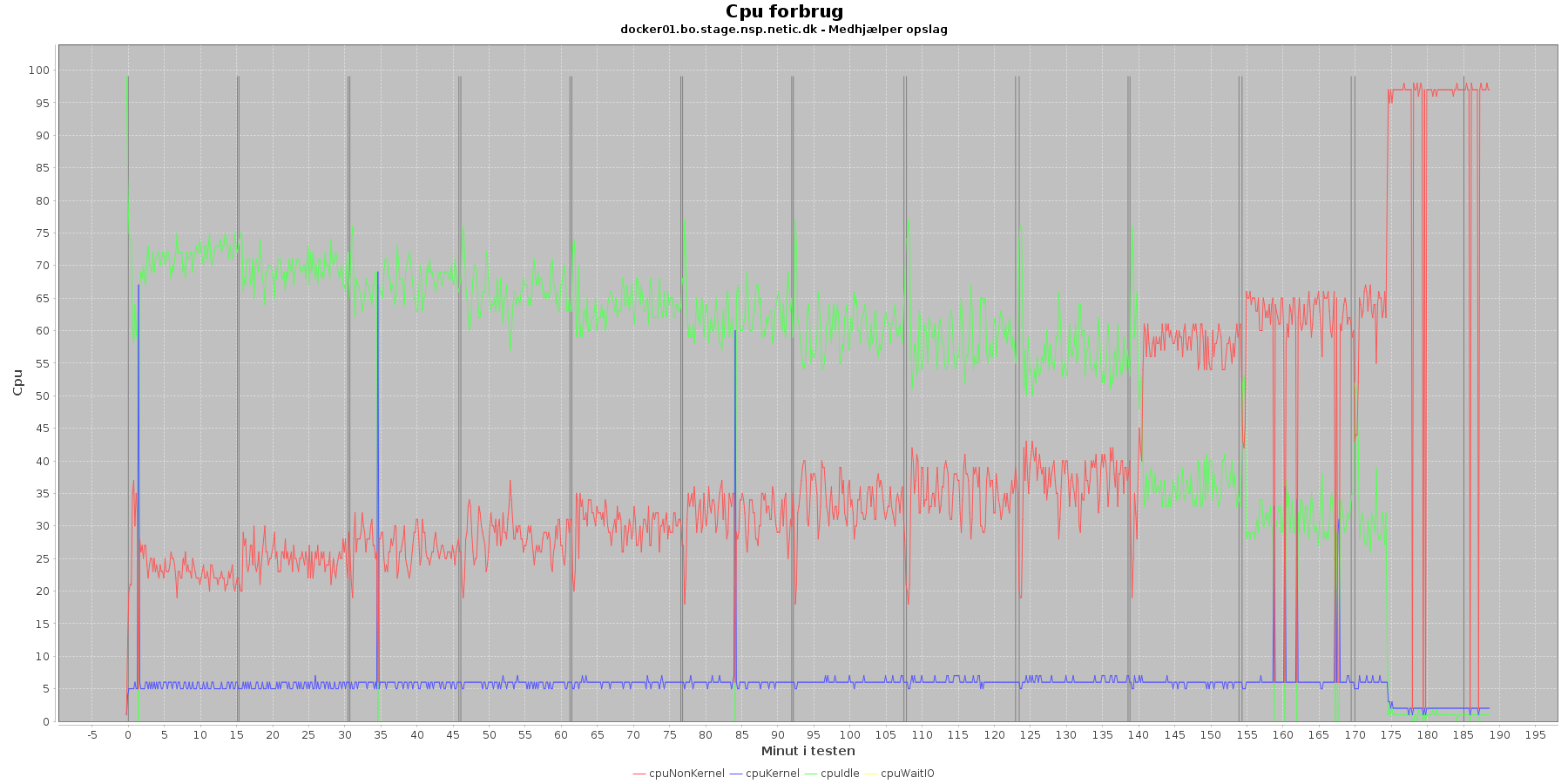
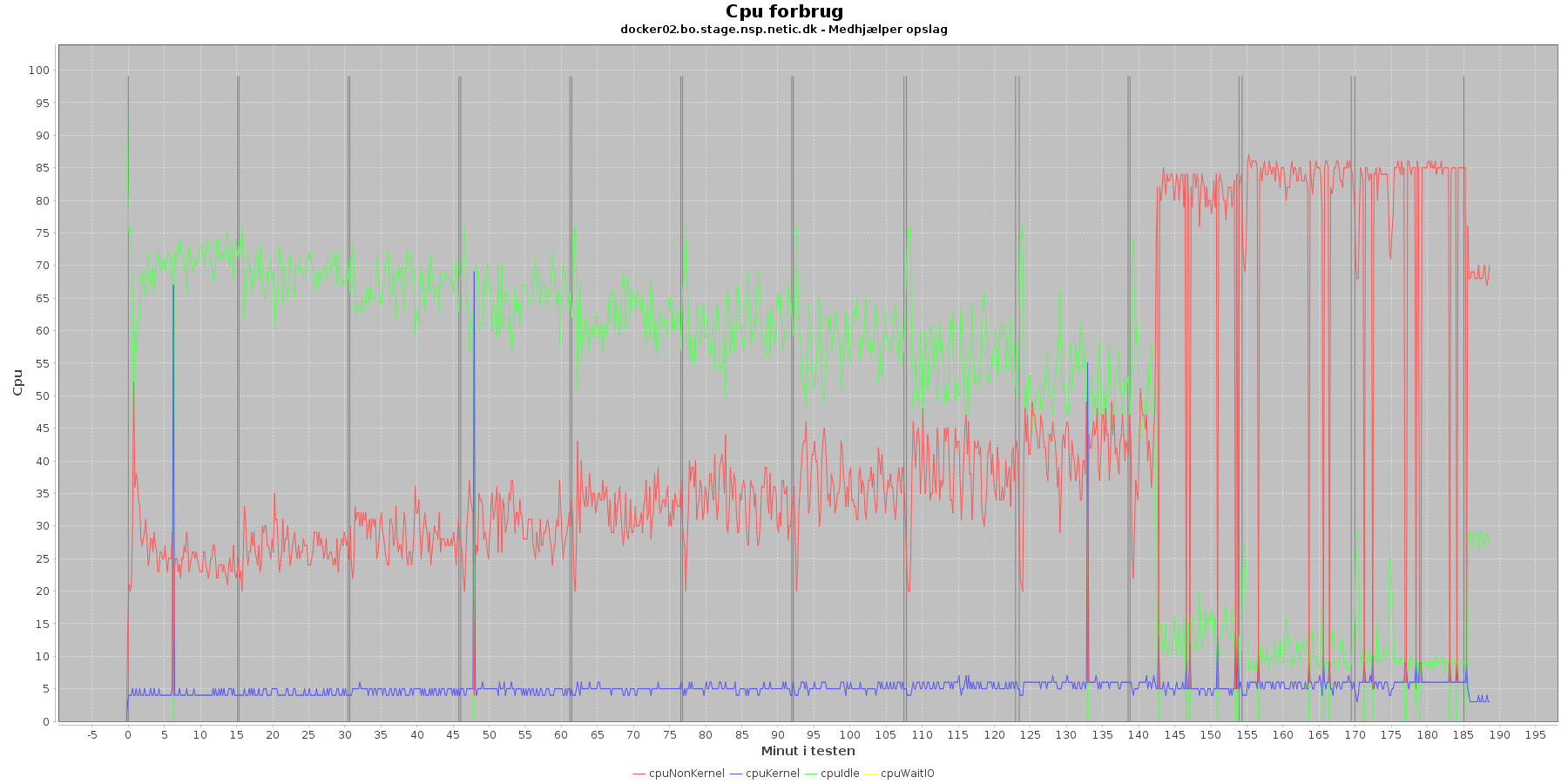
Data serier i grafen er:
- cpuNonKernel (rød): tid brugt på non-kernel opgaver
- cpuKernel (blå): tid brugt på kernel opgaver
- cpuIdle (grøn): tid brugt på ingenting
- cpuWaitIO (gul): tid brugt på at vente på i/o
- iterationerne (sort) er en cirka placering, da wmstat loggen ikke indeholder tidstempel
Man kan se at cpuIdle og cpuNonKernel påvirkes lidt som servicen presses mere. cpuIdle ligger lavere over tid, mens cpuNonKernel grafen ligger en smule højere over tid.
Man kan også se, at cpuIdle dykker til 0 nogle få gange hen over iterationerne. Når dette sker, er der en stigning i cpuKernal. Udsvingende vender dog retur til udgangspunktet.
Hen ved testens 10. iteration sker der dog en stor ændring i dette mønster. Her stiger cpuNonKernal meget fra at ligge under 50 % til at komme over. For docker1s vedkommende bliver den ved at stige, til den rammer næsten 100 %, og for docker2 lander den på 85%
Udtræk omkring io læs og skriv fra vmstat vises i de følgende grafer:
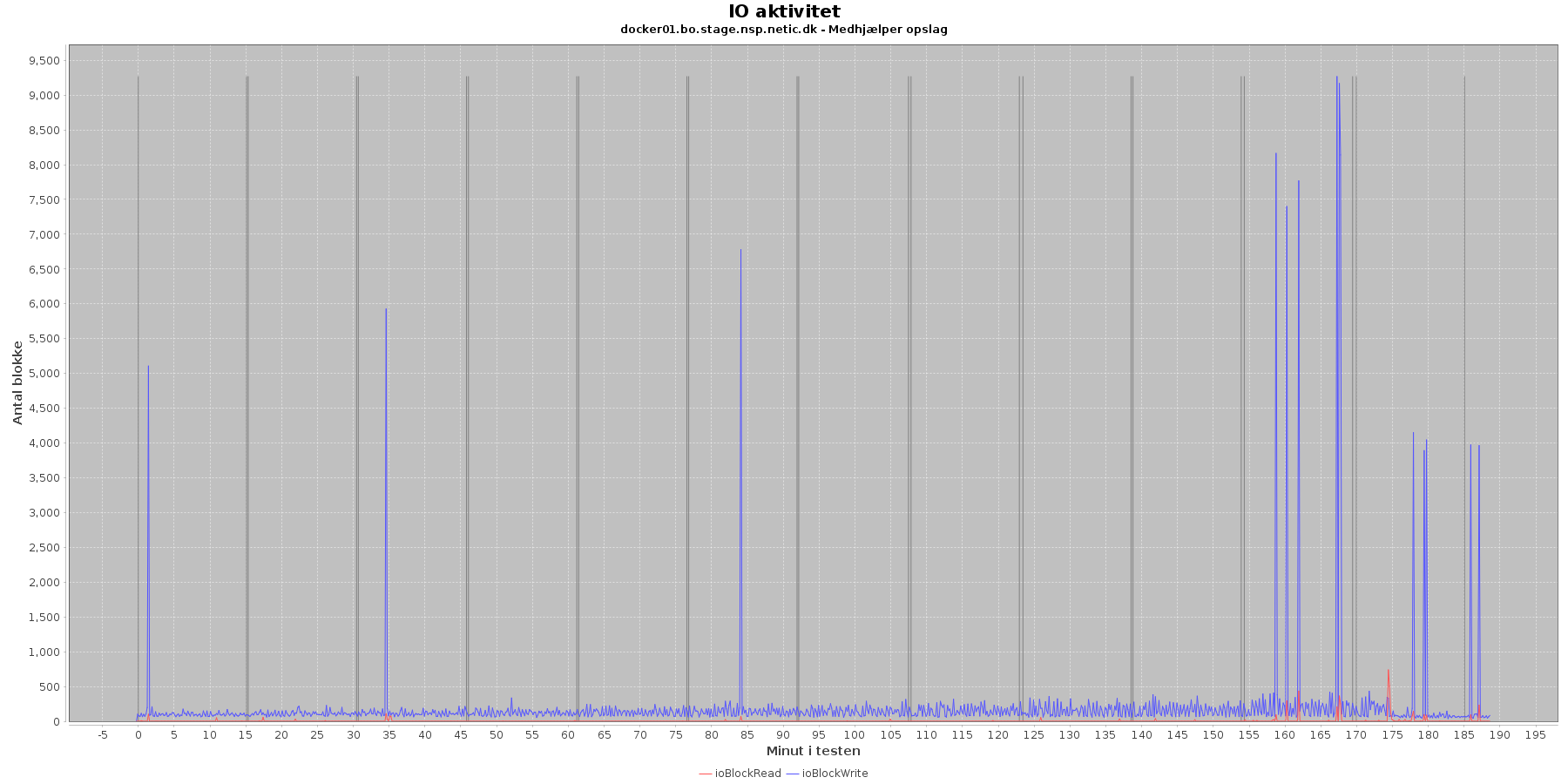
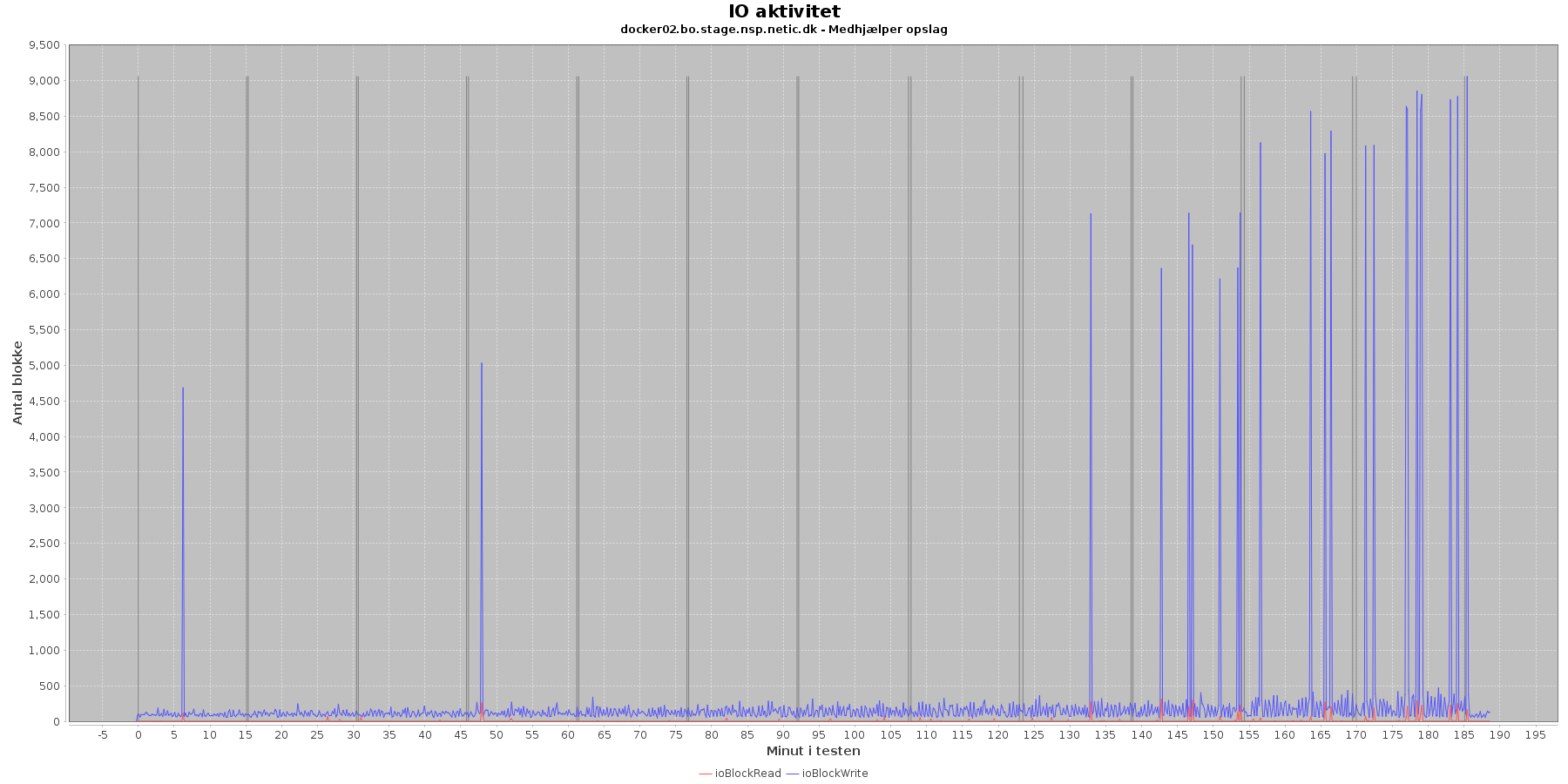
Data serier i grafen er:
- ioBlockRead (rød): læsning på disk (blokke)
- ioBlockWrite (blå): skriving på disk (blokke)
- iterationerne (sort) er en cirka placering, da wmstat loggen ikke indeholder tidstempel
Der er lidt løbende skriv til disken, mens testen kører, og sammenligner man graferne fra før på cpu forbrug, ses det, at de få store udsving i skrivninger falder sammen med at cpuKernal går op og cpuIdle går ned. Dog ses en markant stigning i antal af skriv til disk i samme periode som cpuNonKernel stiger.
Vurdering
Cpu forbruget i 10. og efterfølgende iterationer kan give grund til bekymring.
Jstat log
Denne log findes for hver applikations server (docker container). Loggen viser resultatet af kommandoen jstat. Jstat siger noget om, hvordan JVM'en har det.
Udtræk omkring hukommelse og garbage collection fra denne log vises i de følgende grafer:
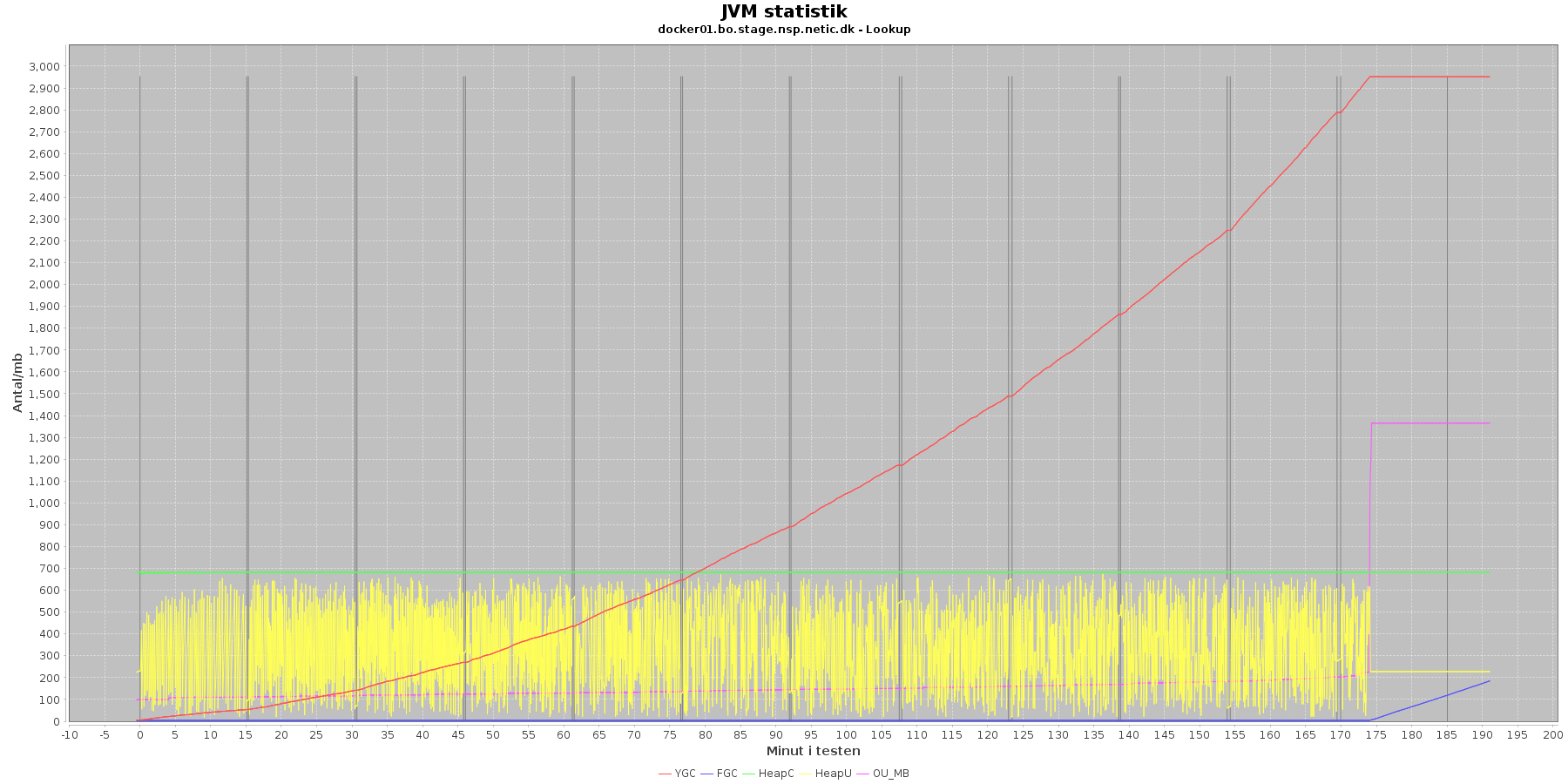
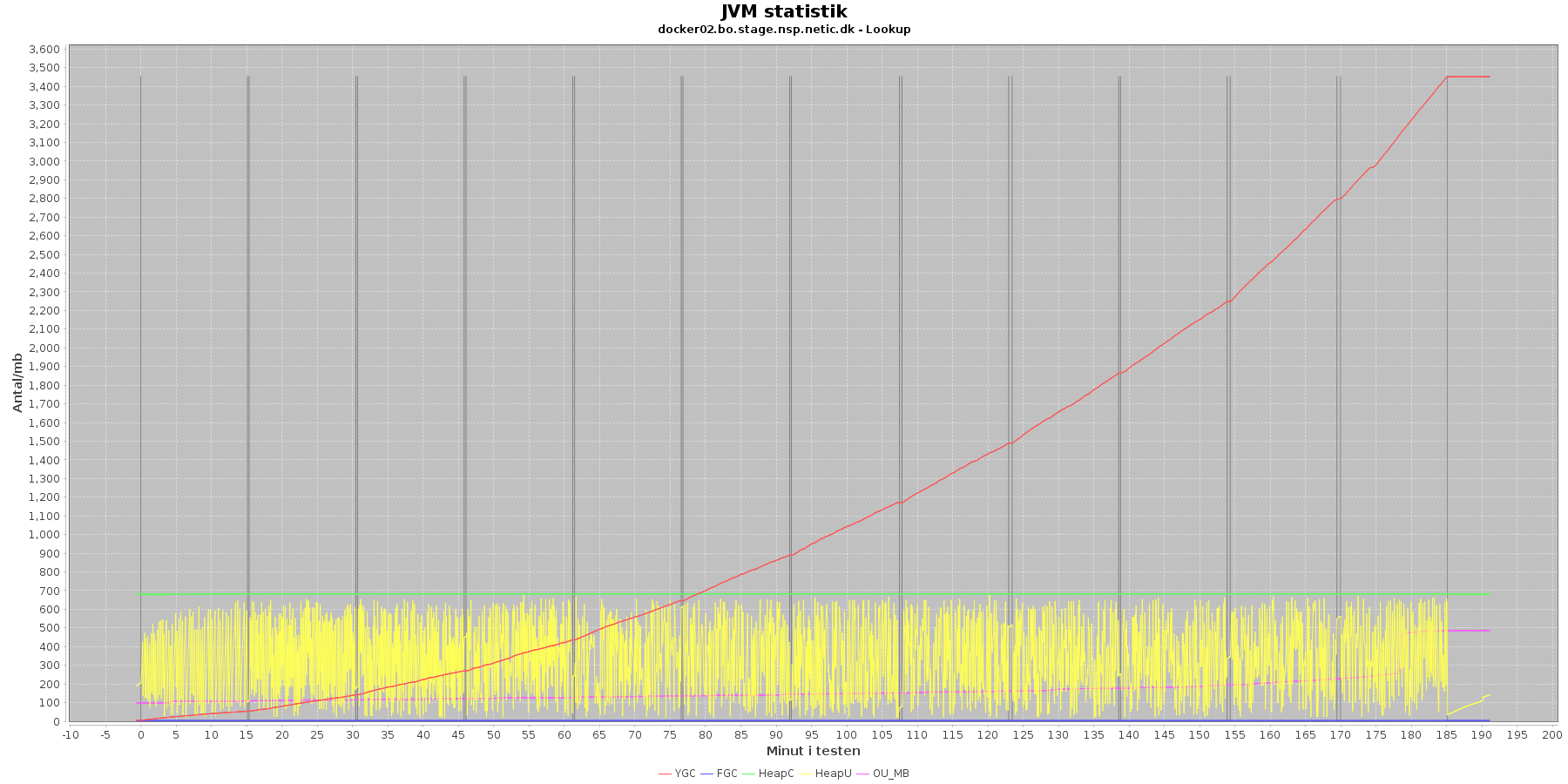
Data serier i grafen er:
- YGC (rød): young generation garbage collection events, antal af "ung" garbage collection siden start
- FGC (blå): full garbage collection events, antal af fuldstændig garbage collection siden start
- HeapU (gul): består af S0U+S1U+EU fra jstat loggen. Young generation memory utilization. "Ung" hukommelses forbrug
- HeapC (grøn): består af S0C+S1C+EC fra jstat loggen. Young generation memory capacity. "Ung" hukommelses kapacitet
- OU_MB (pink): old space utilization. "Ældre" hukommelses forbrug
- OC: old space capacity. "Ældre" hukommelses kapacitet er ikke en del af grafen men er konstant på 1.398.272 KB.
- Iterationer (sort) er baseret på det tidstempel, som findes i jstatloggen
For docker2 køres der ikke full garbage collection (FGC) under testen. docker1 får dog brug for dette i testen sidste iteration, hvor der køres ialt 181 gange full garbage collection.
Der er en svag stigende tendens på den ældre hukommelse (OU_MB). Og i sidste iteration stiger den en del, især for docker1, hvor den faktisk rammer loftet på 1.398.272 KB.
Der køres ofte garbage collection på den yngre hukommelse, hvilket holder HeapU - yngre hukommelses forbrug - nede så den kun svinger inden for et konstant interval.
Vurdering
Det giver anledning til bekymring at den ældre hukommelse rammer loftet ved øget pres og får servicen til at gå ned.
Docker stats log
Denne log findes for hver applikations server (docker container). Loggen viser resultatet af kommandoen docker stats. Docker stats siger noget om, hvordan containeren forbruger sine ressourcer.
Udtræk omkring hukommelse, cpu og netværkstrafik vises i følgende grafer.
Hukommelse:
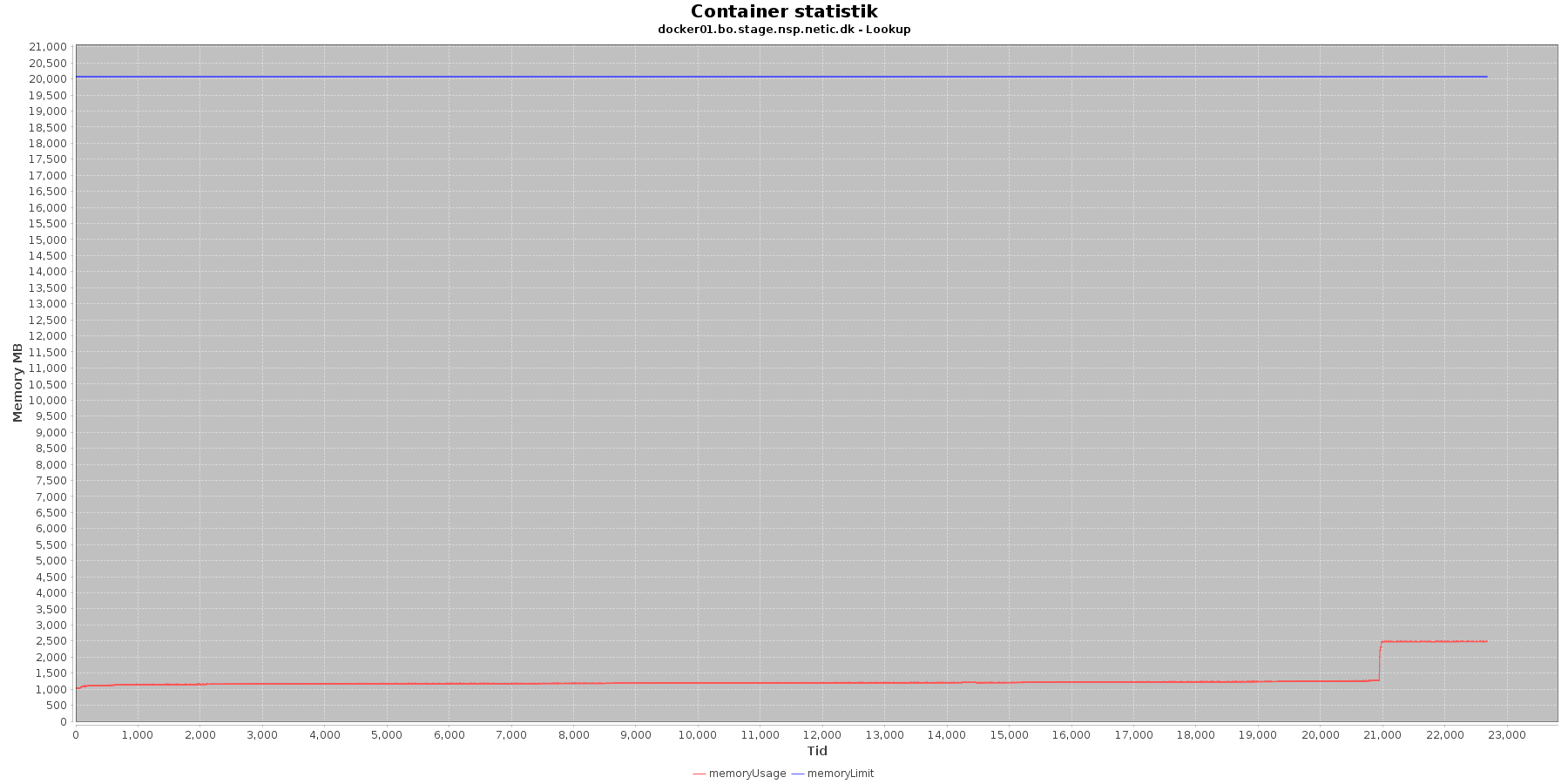
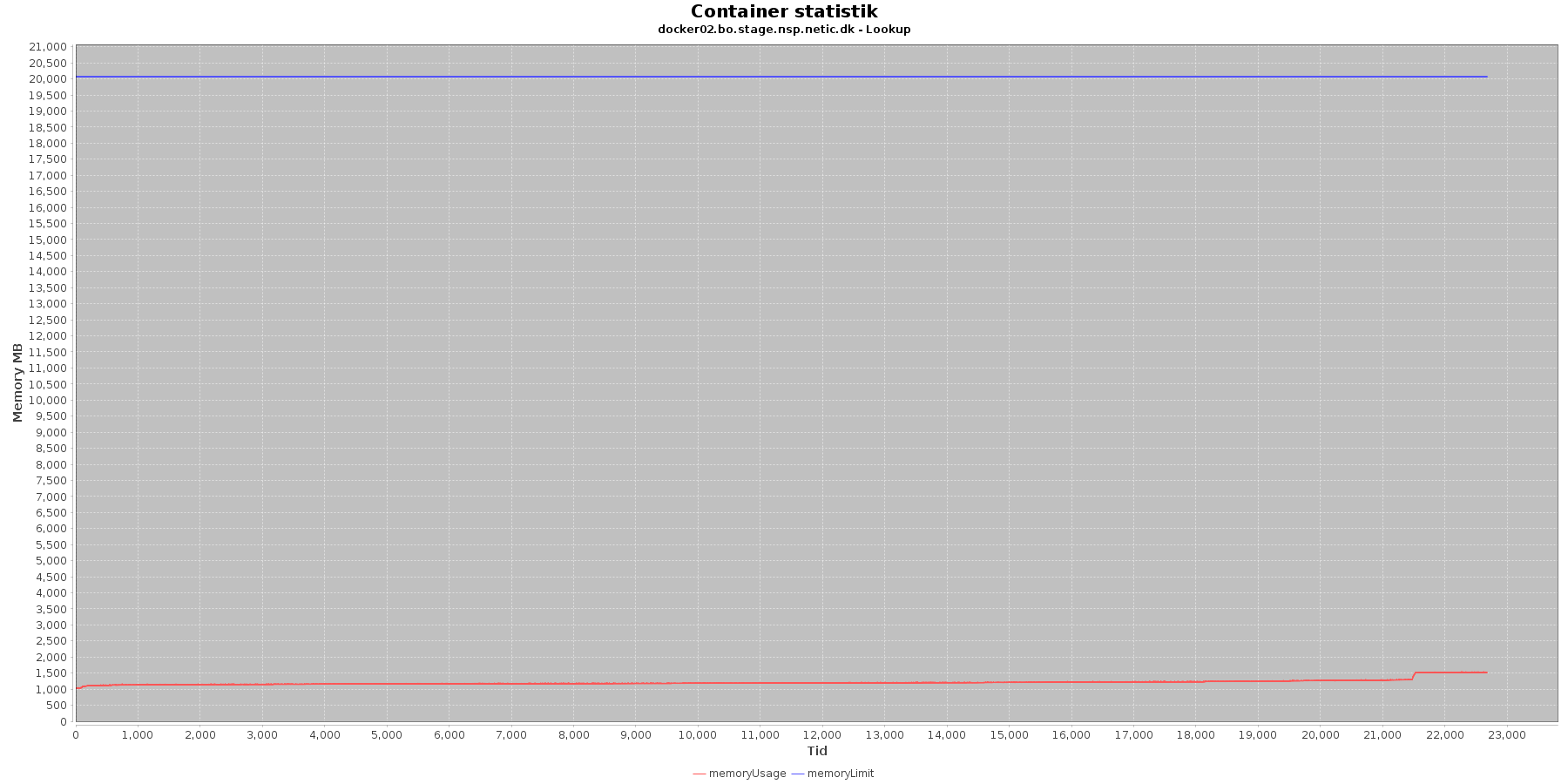
Data serier i grafen er:
- memoryUsage (rød): den totale mængde hukommelse containeren bruger
- memoryLimit (blå): den totale mængde hukommelse contaneren kan bruge
Den forbrugte hukommelse er meget stabil indtil sidst i testen, hvor den for især docker1 stiger brat.
Cpu og hukommelse procent:
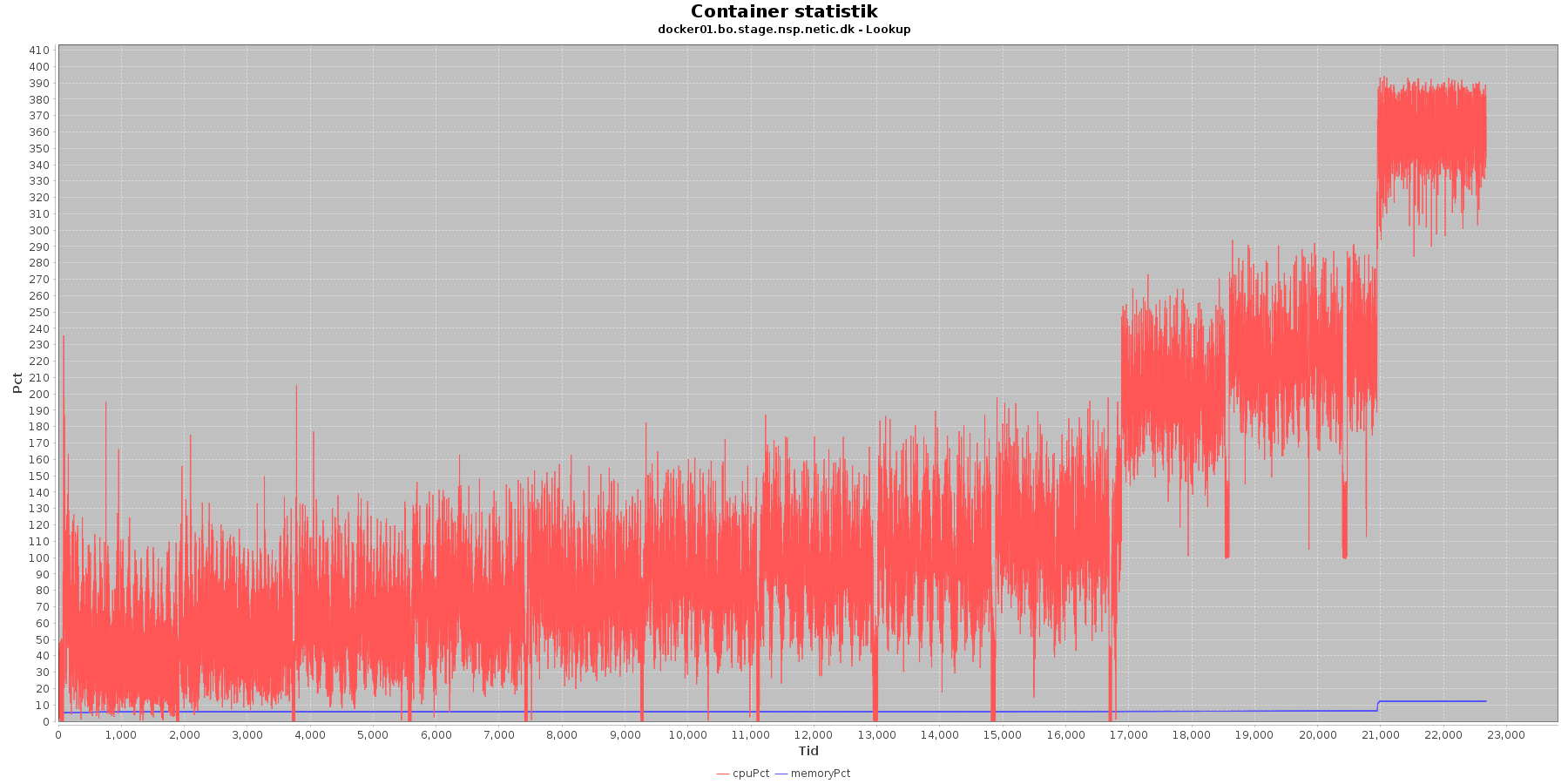
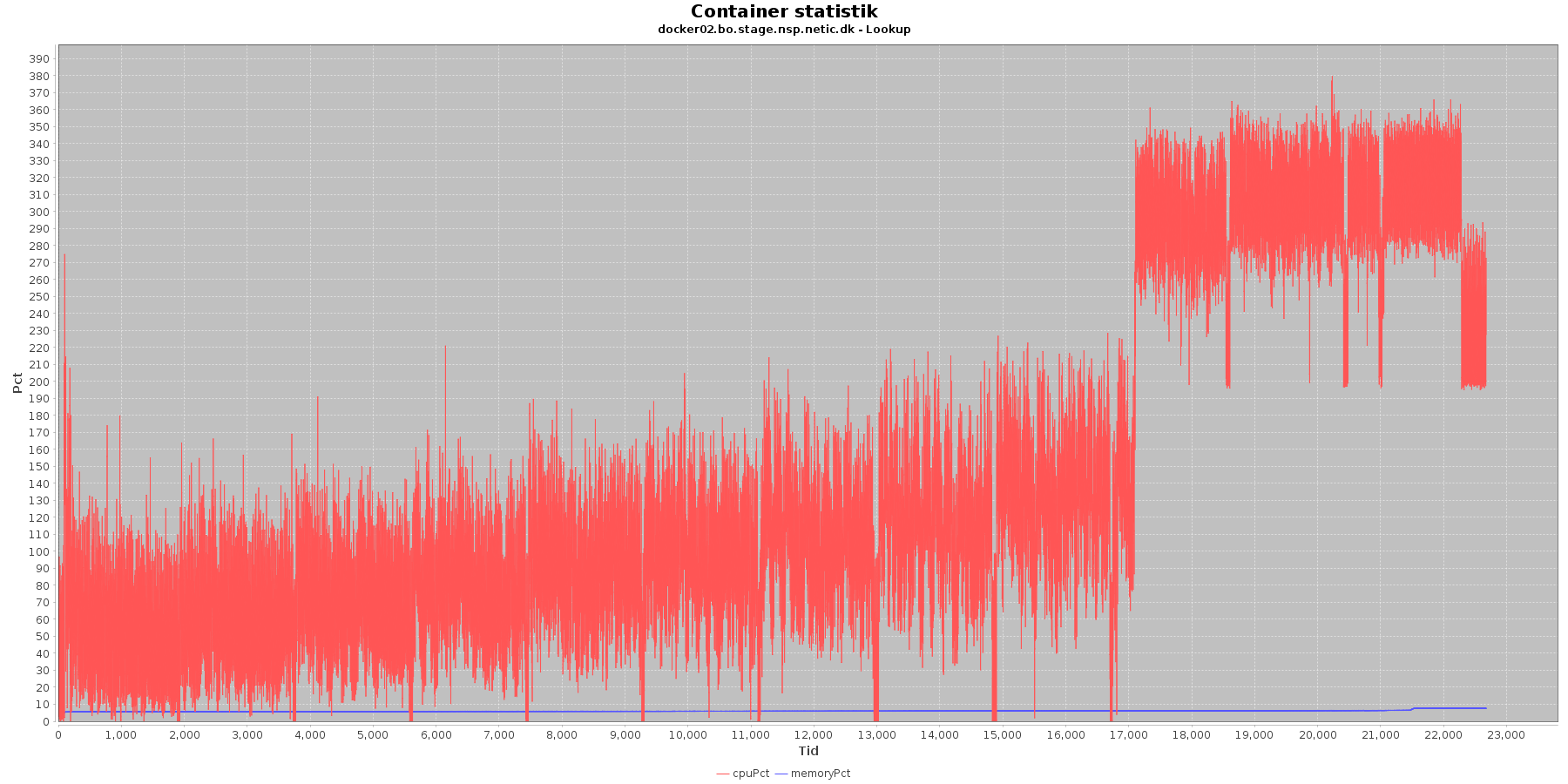
Data serier i grafen er:
- cpuPct (rød): hvor mange procent af hostens cpu containeren bruger
- memoryPct (blå): hvor mange procent af hostens hukommelse containeren bruger
Servicen viser et stabilt forbrug af hukommelse i starten af testen, men igen ses en stigning sidst i testen især på docker1.
Den envendte cpu er svagt stigende som servicen bliver presset. Og fra 10. iteration laver både docker1 og docker2 nogle høje spring i cpu forbruget.
Netværk:
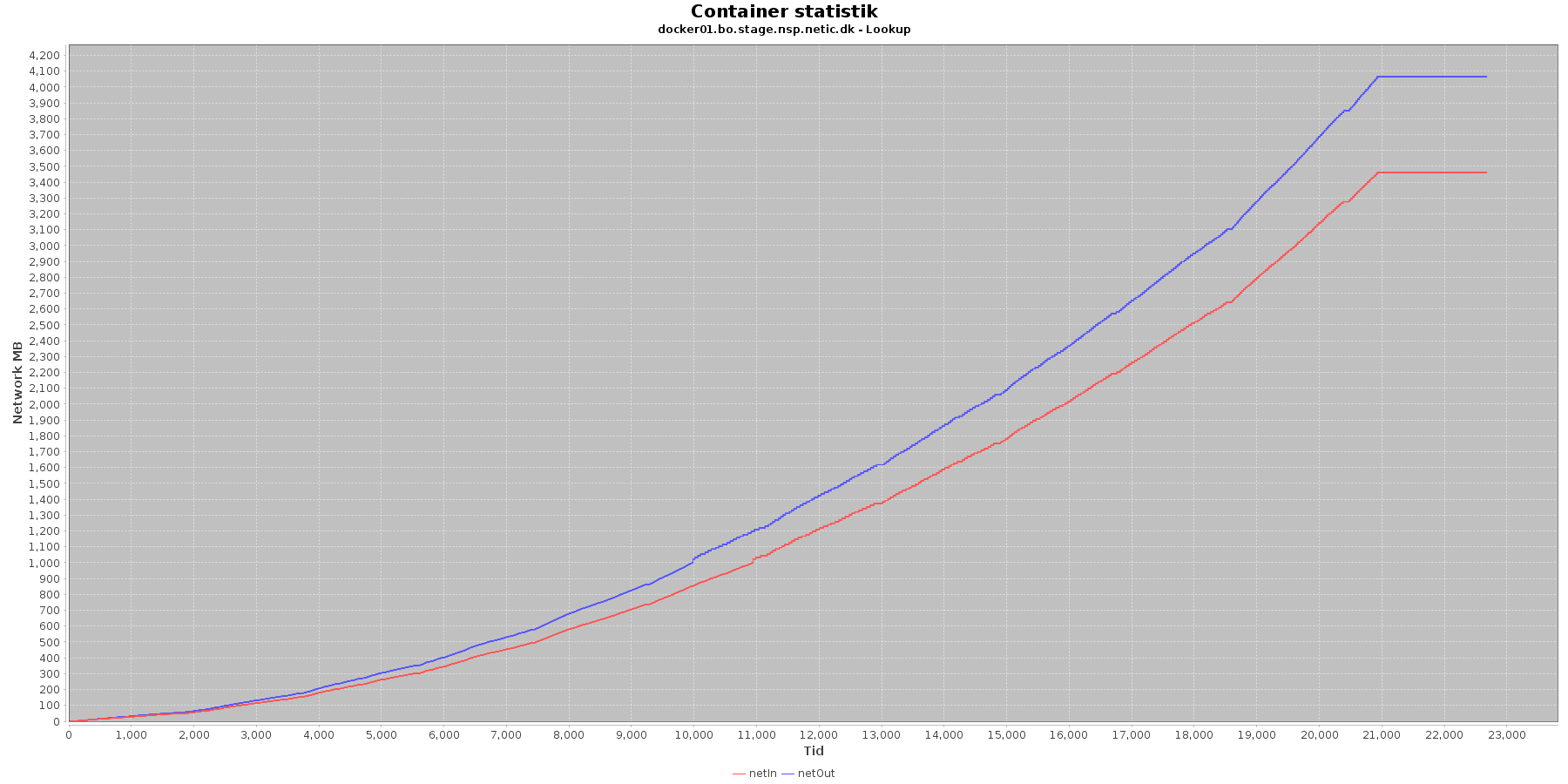
Data serier i grafen er:
- netIn (rød): den mængde data som er modtaget af containeren over netværket
- netOut (blå): den mængde data som er sendt ud af containeren over netværket
De 2 grafer for ind- og udsendt data følges ad, hvilket er forventeligt; indkomne kald skaber trafik til database og igen retur til kalder. netOut stiger mest.
Vurdering
Disse log data viser igen den øgede cpu og hukommelsesforbrug sidst i testen. Det ser dog ud til at containeren har masser af hukommelse og ikke i sig selv er ved at løbe tør.
Konklusion
Efter at have analyseres data fra performance testen kan følgende trækkes frem:
- Throughput på testen er 49,61 kald per sekund
- Gennemsnitlig højeste svartid per kald til servicen:
For 95 % percentil: under 2,1 sekunder
For 98 % percentil: under 2,5 sekunder
Kravene på under 2,5 henholdsvis 5,5 sekunder er overholdt - Cpu status: servicen ser ud til at få problemer med cpu forbruget når den presses
- io på netværk: stiger over tid, hvilket er forventet
- Hukommelses forbrug: servicen ser ud til at få problemer med hukommelsen når den presses
- Garbage collection: servicen kører jævnligt garbage collection. Noget kunne tyde på, at når servicen bliver presset, kan garbage collection ikke helt få ryddet op.
Performance testen er designet til at presse en service mere og mere. Medhjælper lookup viser en svaghed, når den presses og når til iteration 10, som er 10 tråde og 2 nodes. Det bør undersøges, hvordan denne belastning ligger i forhold til, hvad der forventes i drift, for at vurdere, om det vil blive et faktisk problem.
Den kraftige forøgelse af cpu og hukommelses forbrug bør undersøges. Kombinationen kunne måske tyde på loop. Dette bør undersøges nærmere i andre log filer eller en fokuseret test rettet mod dette.
Da testen bliver afbrudt i mangel på hukommelse, viser den ikke, om vi faktisk har nået det maksimale throughput den ellers ville have kunnet yde. Allokering af mere hukommelse til servicen kunne afhjælpe dette.
De mange fejl, der ses i jmeter loggen kan skyldes at servicen på docker1 stopper med at svare og dermed melder "Internal Server Error" tilbage.
MinLog2 - Performancetest rapport minlog1 lookup
Performance testen består af en række kald til opslag efter logninger på forskellige cpr numre. Denne test er samme type som borger lookup. Den anvender dog istedet minlog1 formatet.
Testen udført er komponent "minlog", testplan "listlogstatements" og distribution "borger".
MinLog 2 service er version 2.0.25perf og NSP standard performance test framework version 2.0.20
De rå test resultater er vedhæftet denne side (minlog2_minlog1_listlogstatements_borger_run1.tar.gz)
JMeter log
JMeter hoved filen beskriver overordnet testens resultat. Her kan kan ses, at der er kørt 4 iterationer med test, deres tidsinterval , throughput og fejlprocent for hver.
Iteration | Tråde | Nodes | Starttid | Sluttid | Throughput | Fejlprocent |
|---|---|---|---|---|---|---|
| 1 | 5 | 2 | 2020-03-09_10-16-28 | 2020-03-09_10-31-34 | 33,93 kald per sekund | 0 % |
| 2 | 8 | 2 | 2020-03-09_10-32-34 | 2020-03-09_10-47-39 | 49,51 kald per sekund | 0 % |
3 | 11 | 2 | 2020-03-09_10-48-31 | 2020-03-09_11-03-37 | 59,11 kald per sekund | 0 % |
| 4 | 11 | 3 | 2020-03-09_11-04-42 | 2020-03-09_11-19-47 | 69,49 kald per sekund | 0 % |
Det fremgår også af filen, at den endelige måling af throughput er 69,49 kald per sekund.
Samt at fejlprocentet på den fulde kørsel er 0 %.
Access log
Denne log findes for hver applikations server (docker container).
Her findes data for hvert enkelt kald, der er lavet til minlog servicen, herunder hvor lang tid et kald har taget (Duration), samt hvornår kaldet er udført. Ud fra loggens data kan man også beregne, hvor mange kald, der udføres i en given periode.
De følgende 2 grafer viser 95 % hendholdsvis 98 % percentil for kaldende. Grupperingen er 10 minutter:


Det ses af graferne, at jo flere nodes/tråde jo højere bliver svar tiden overordnet set.
Den næste graf viser antal kald per sekund:

Af grafen fremgår det, at jo flere nodes og tråde (disse øges over tid, per iteration) jo flere kald kommer der igennem per sekund overordnet set.
Vurdering
Performance kravene
- under 2,50 sekund for 95 % af tilfældende; dette overstiges ifølge "95 % percentil grafen" ikke. Max svartiden er her under 1,1 sekunder
- under 5,5 sekund for 98 % af tilfældende; dette overstiges ifølge "98 % percentil grafen" ikke. Max svartiden er her under 1,4 sekunder
Vi er inden for performance kravene i testen fulde køretid.
Vmstat log
Denne log findes for hver applikations server (docker container). Den viser resultatet af kommandoen vmstat
Udtræk omkring cpu fra denne log vises i de følgende grafer:
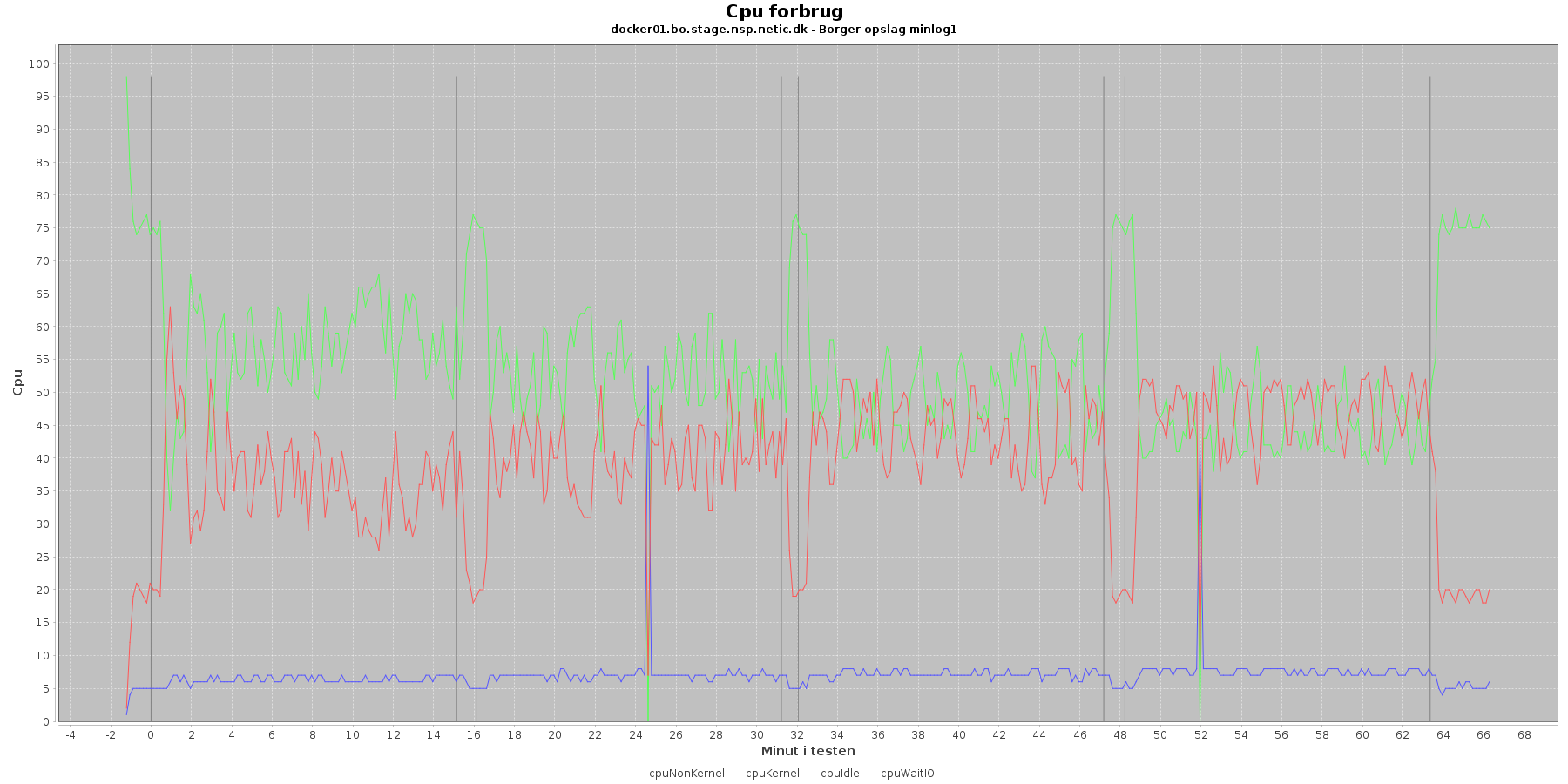
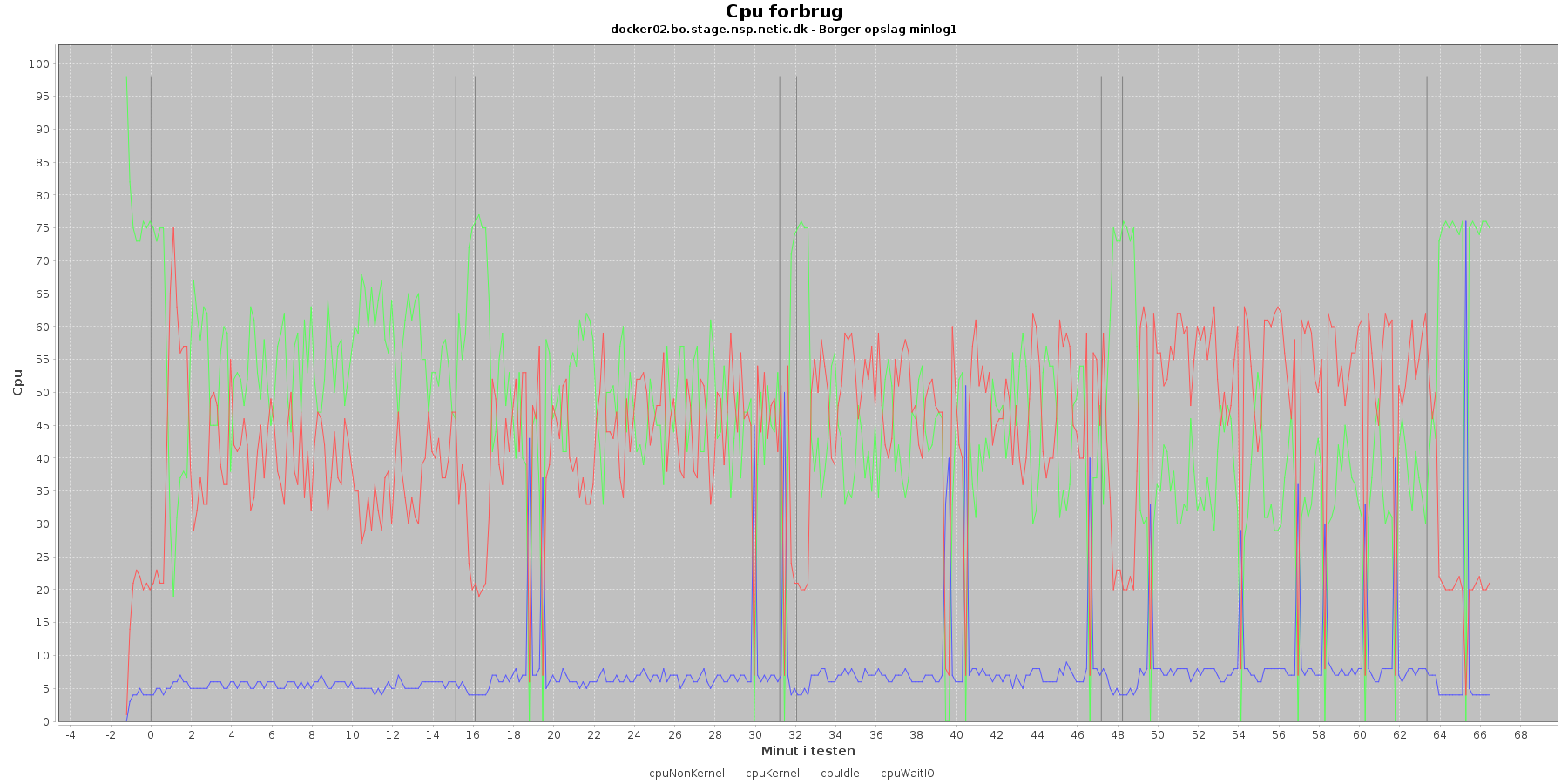
Data serier i grafen er:
- cpuNonKernel (rød): tid brugt på non-kernel opgaver
- cpuKernel (blå): tid brugt på kernel opgaver
- cpuIdle (grøn): tid brugt på ingenting
- cpuWaitIO (gul): tid brugt på at vente på i/o
- iterationerne (sort) er en cirka placering, da wmstat loggen ikke indeholder tidstempel
Man kan se at cpuIdle og cpuNonKernel påvirkes lidt som servicen presses mere. cpuIdle ligger lavere over tid, mens cpuNonKernel grafen ligger en smule højere over tid. Den generelle flyt af kurverne er dog ikke faretruende.
Man kan også se, at cpuIdle dykker til 0 nogle gange hen over iterationerne. Når dette sker er der en stigning i cpuKernal. Udsvingende vender dog retur til udgangspunktet.
Udtræk omkring io læs og skriv fra vmstat vises i de følgende grafer:
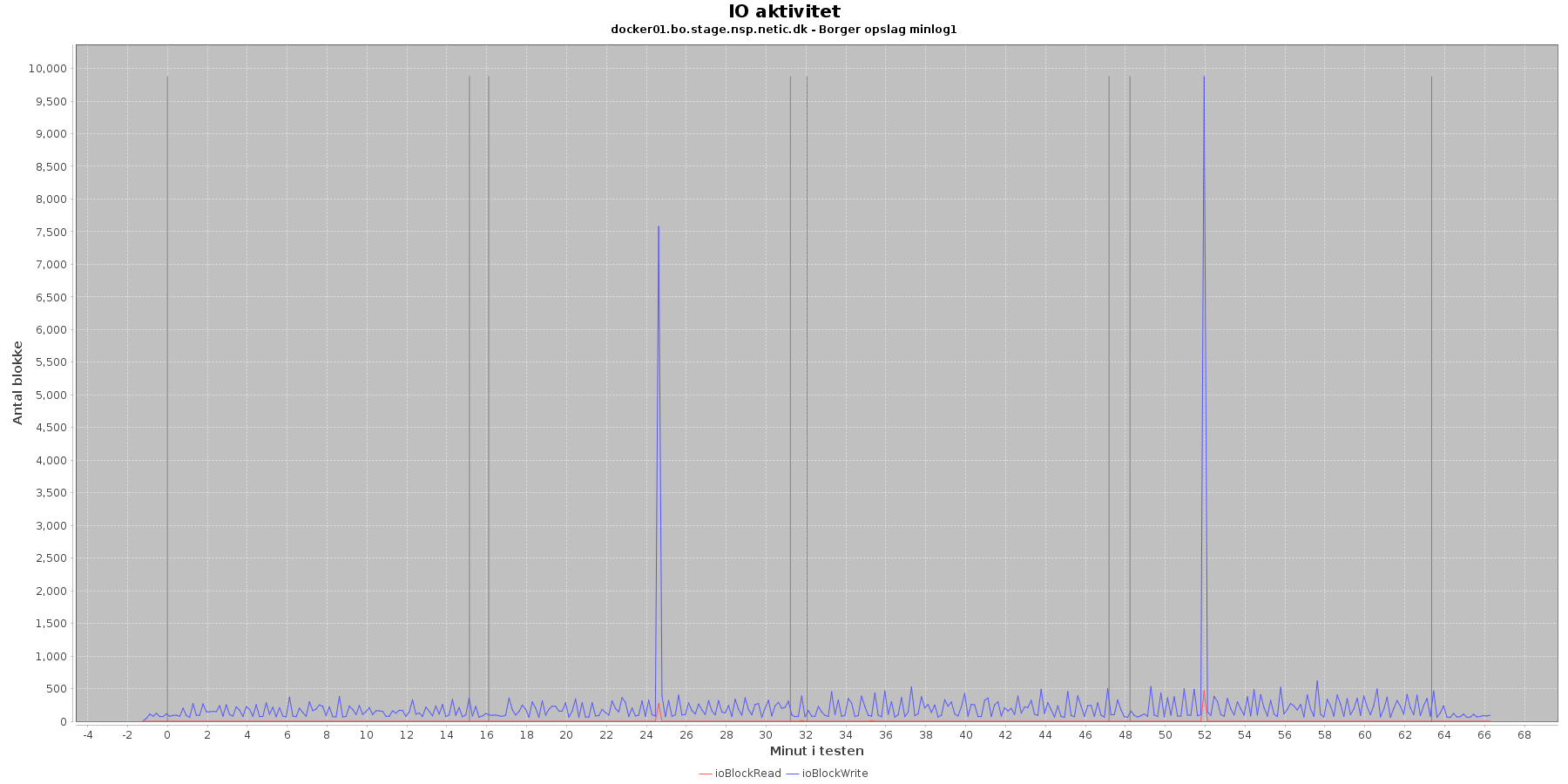
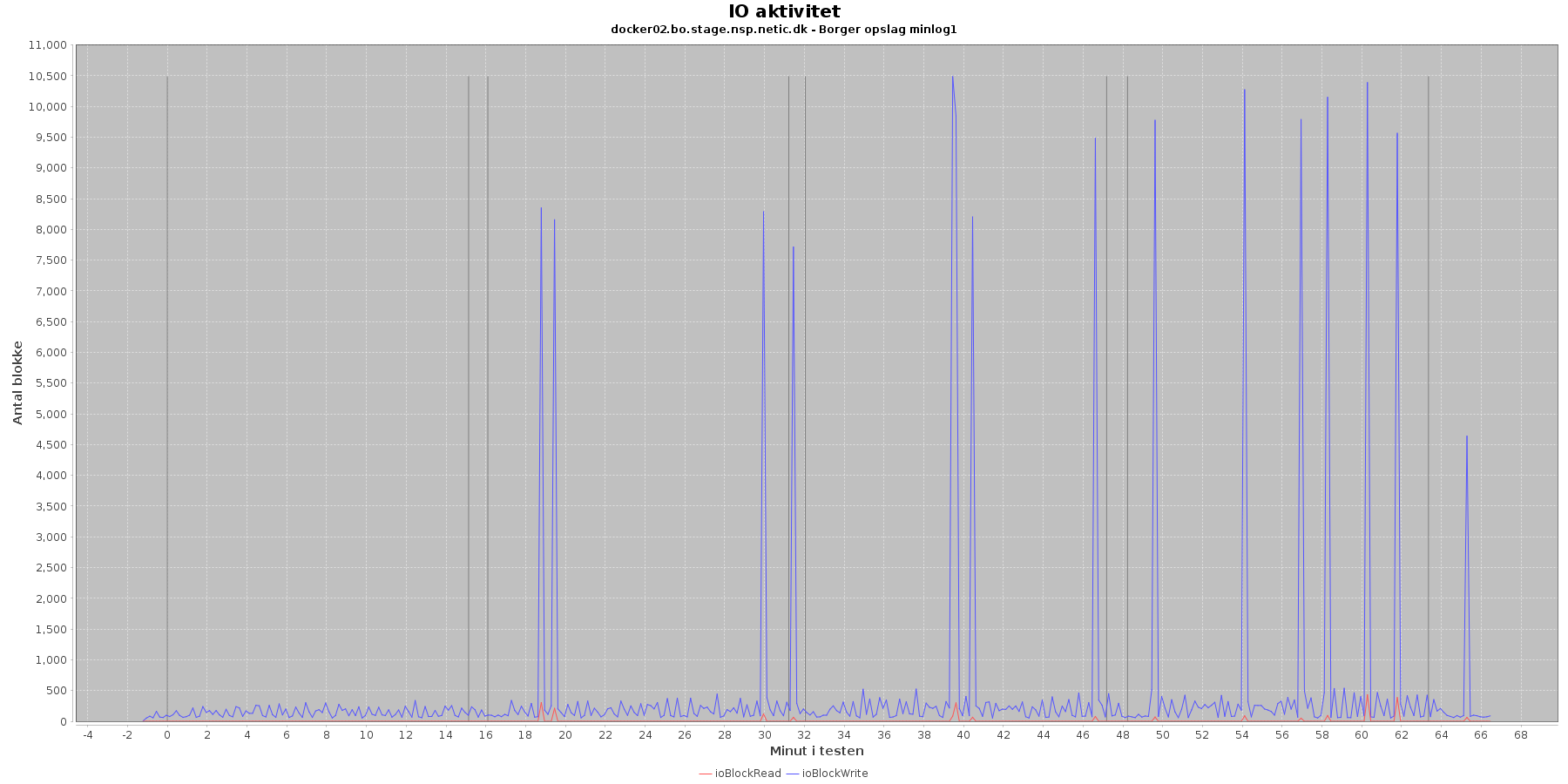
Data serier i grafen er:
- ioBlockRead (rød): læsning på disk (blokke)
- ioBlockWrite (blå): skriving på disk (blokke)
- iterationerne (sort) er en cirka placering, da wmstat loggen ikke indeholder tidstempel
Der er lidt løbende skriv til disken mens testen kører, og sammenligner man graferne fra før på cpu forbrug, ses det, at de store udsving i skrivninger falder sammen med at cpuKernal går op og cpuIdle går ned.
Vurdering
Der er intet negativt at bemærke omkring cpu forbruget eller io.
Jstat log
Denne log findes for hver applikations server (docker container). Loggen viser resultatet af kommandoen jstat. Jstat siger noget om, hvordan JVM'en har det.
Udtræk omkring hukommelse og garbage collection fra denne log vises i de følgende grafer:
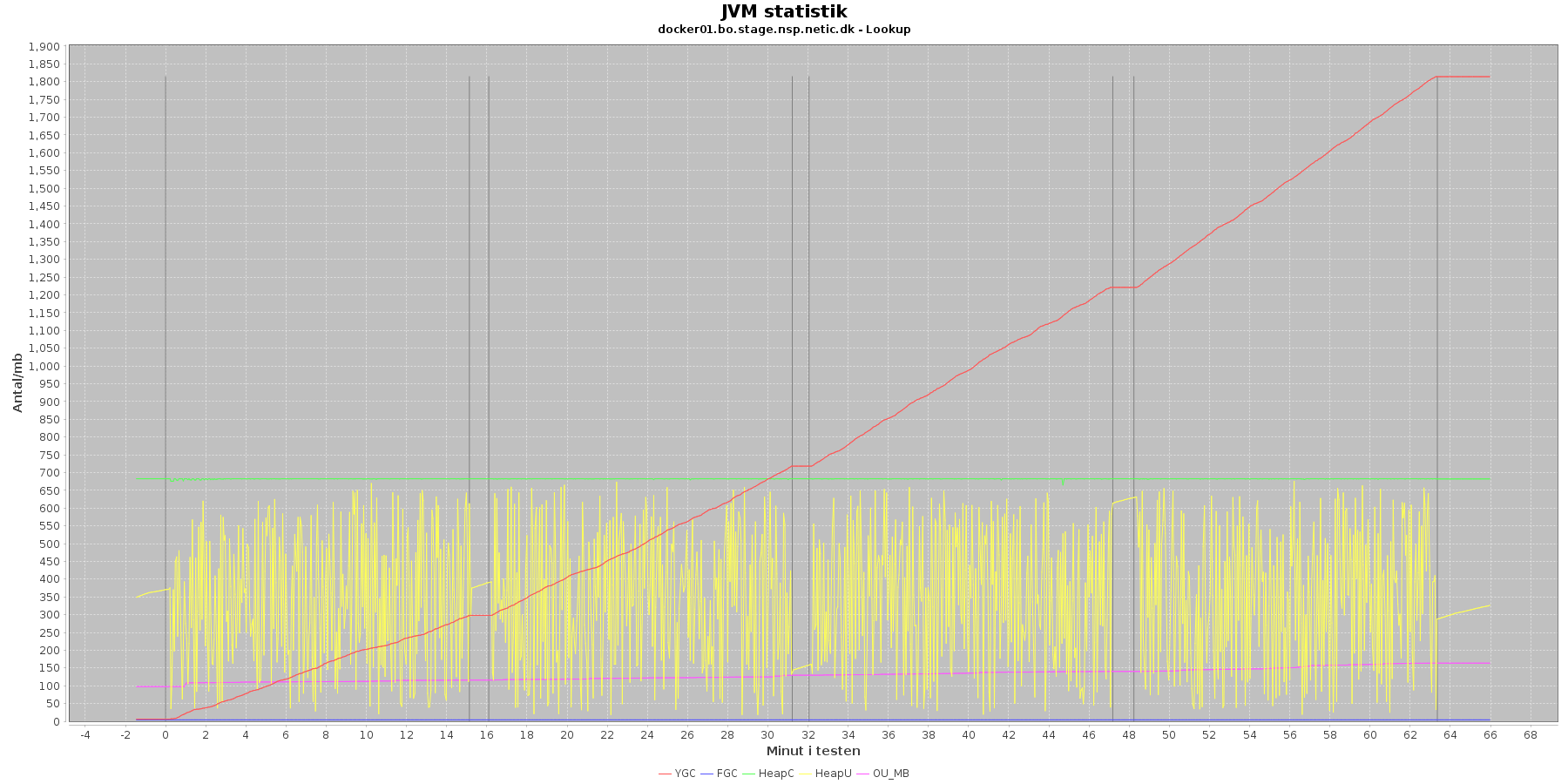
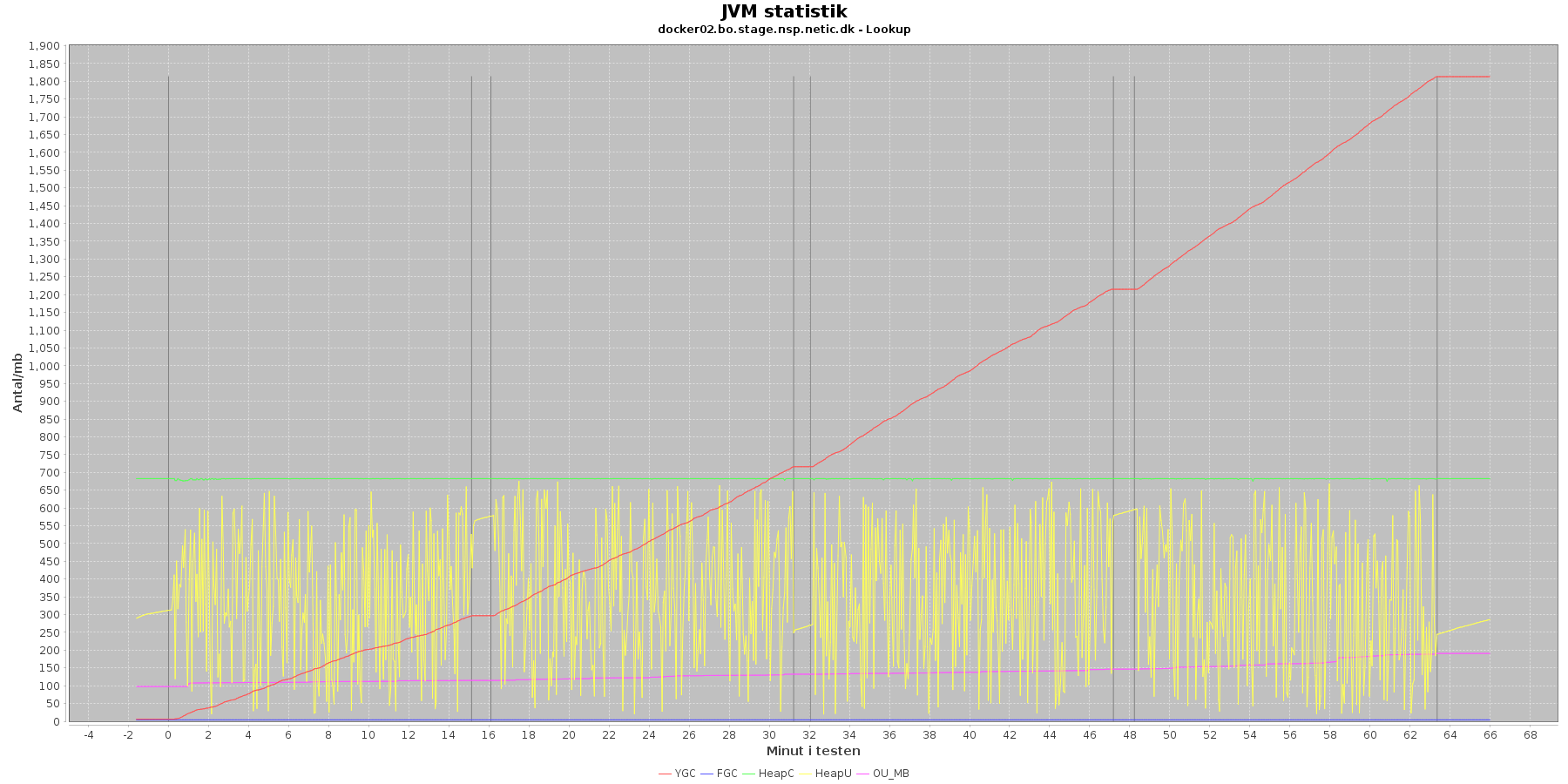
Data serier i grafen er:
- YGC (rød): young generation garbage collection events, antal af "ung" garbage collection siden start
- FGC (blå): full garbage collection events, antal af fuldstændig garbage collection siden start
- HeapU (gul): består af S0U+S1U+EU fra jstat loggen. Young generation memory utilization. "Ung" hukommelses forbrug
- HeapC (grøn): består af S0C+S1C+EC fra jstat loggen. Young generation memory capacity. "Ung" hukommelses kapacitet
- OU_MB (pink): old space utilization. "Ældre" hukommelses forbrug
- OC: old space capacity. "Ældre" hukommelses kapacitet er ikke en del af grafen men er konstant på 1.398.272 KB.
- Iterationer (sort) er baseret på det tidstempel, som findes i jstatloggen
Det kan være lidt svært at se graferne for full garbage collection (FGC). Kigger man nærmere på datagrundlaget bag graferne, ses det, at der ikke er full garbage collection for servicen under testen.
Der er en meget svag stigende tendens på den ældre hukommelse (OU_MB). Man må gå ud fra, at kommer den op på en kritisk grænse, da vil systemet køre en full garbage collection (FGC).
Der køres ofte garbage collection på den yngre hukommelse, hvilket holder HeapU - yngre hukommelses forbrug - nede så den kun svinger inden for et konstant interval.
Vurdering
Den yngre forbrugte hukommelse eskalerer ikke. Garbage collecteren gør sit arbejde.
Docker stats log
Denne log findes for hver applikations server (docker container). Loggen viser resultatet af kommandoen docker stats. Docker stats siger noget om, hvordan containeren forbruger sine ressourcer.
Udtræk omkring hukommelse, cpu og netværkstrafik vises i følgende grafer.
Hukommelse:
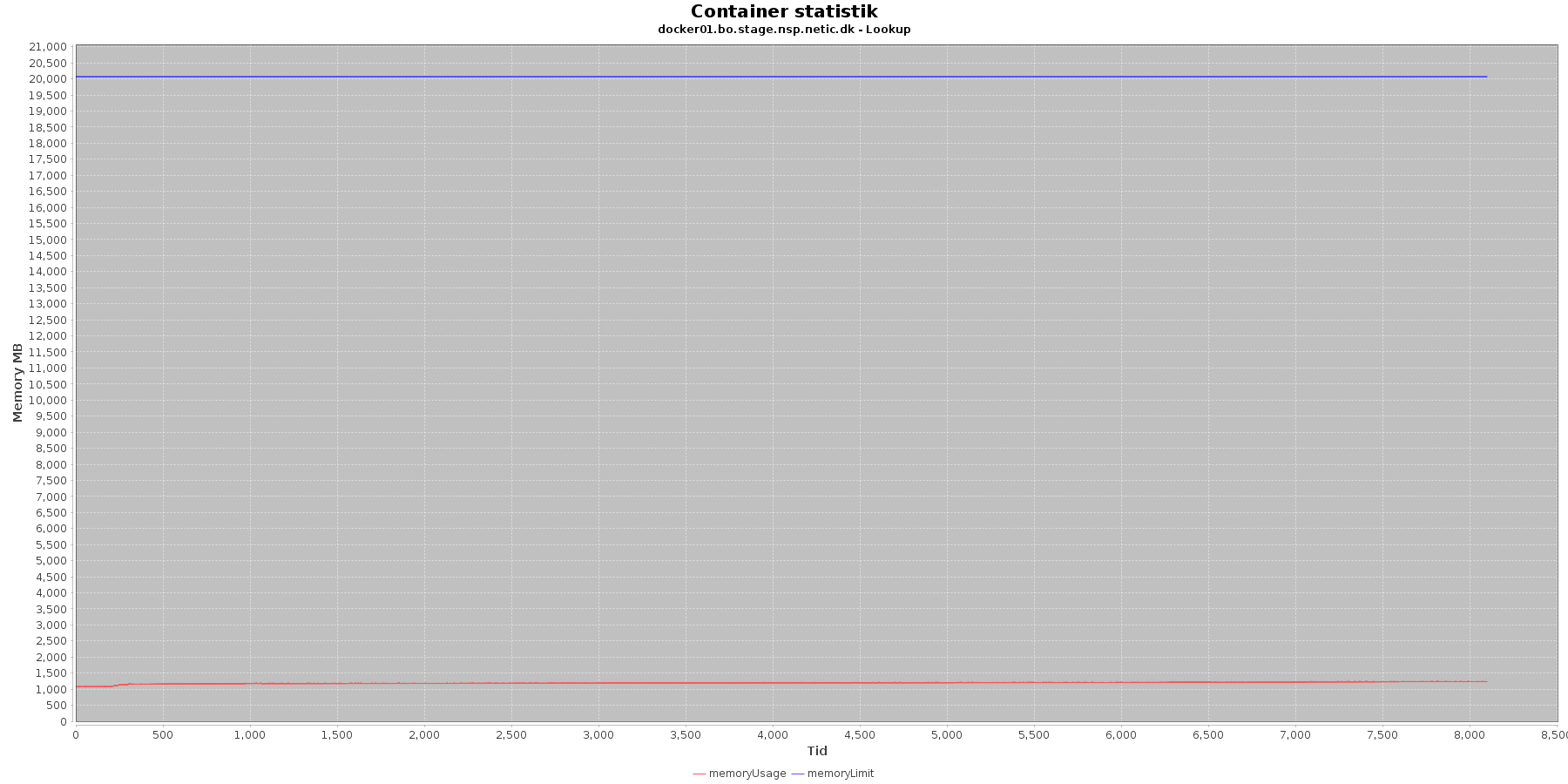
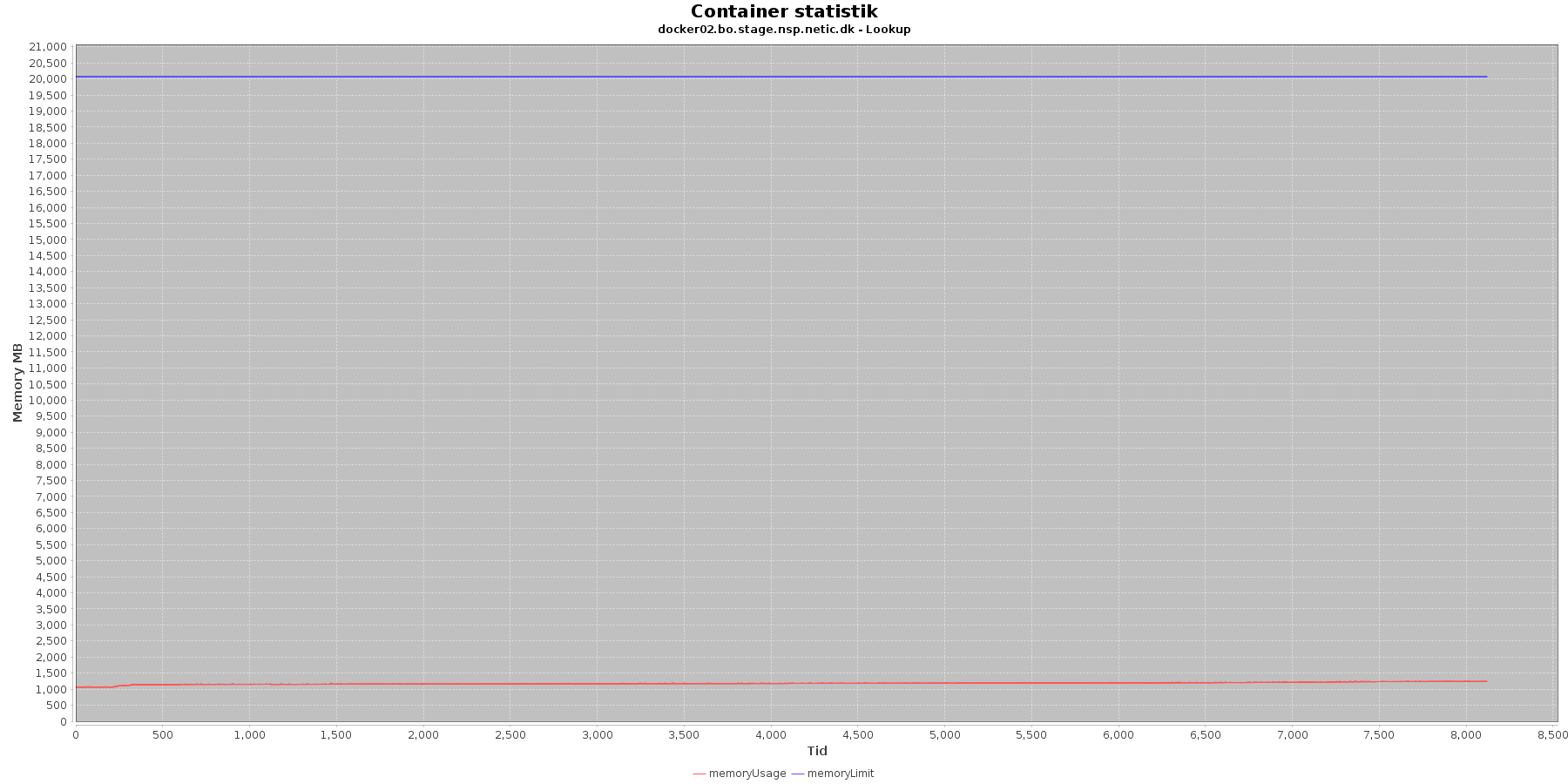
Data serier i grafen er:
- memoryUsage (rød): den totale mængde hukommelse containeren bruger
- memoryLimit (blå): den totale mængde hukommelse contaneren kan bruge
Den forbrugte hukommelse er meget stabil.
Cpu og hukommelse procent:
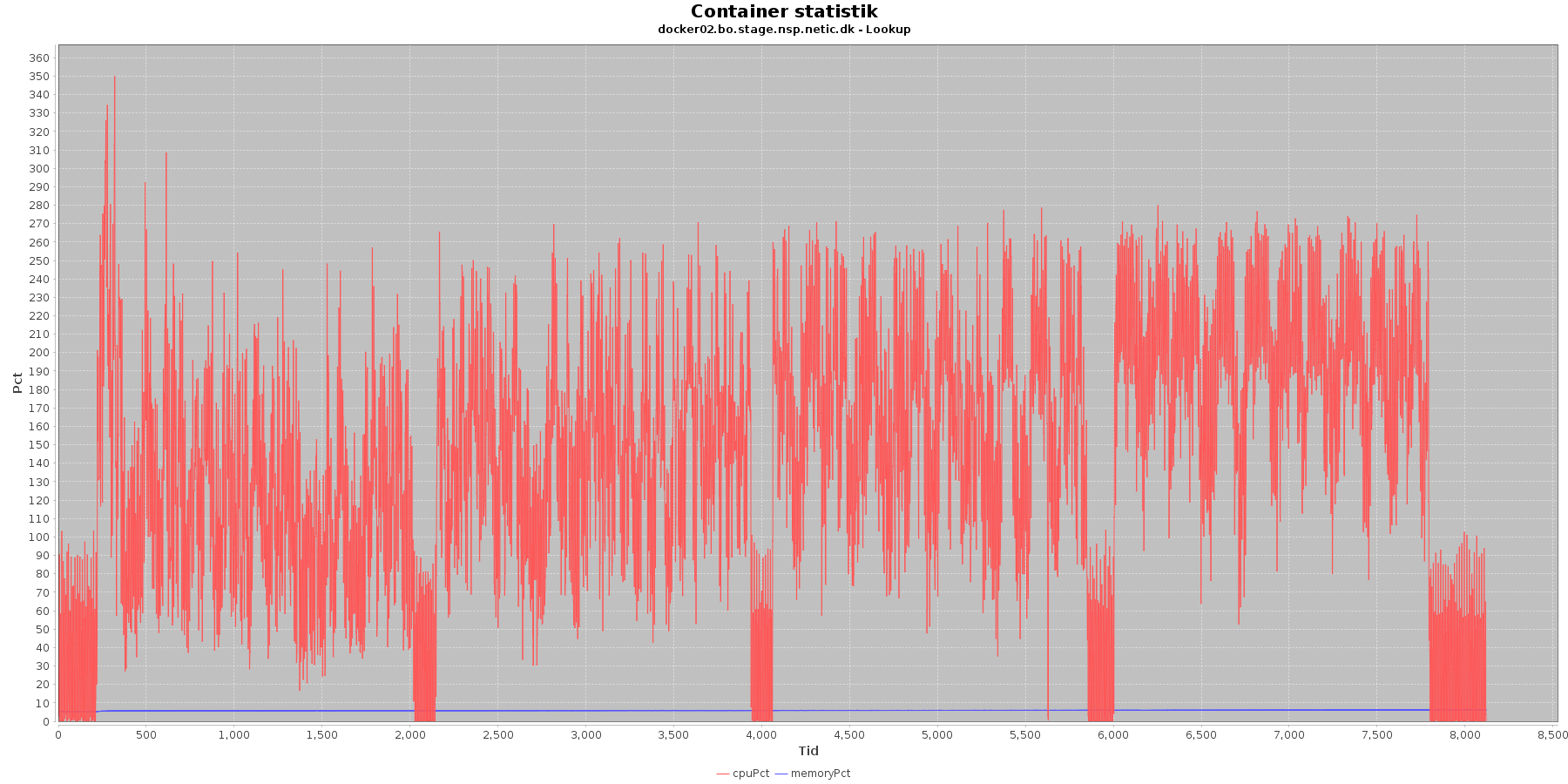
Data serier i grafen er:
- cpuPct (rød): hvor mange procent af hostens cpu containeren bruger
- memoryPct (blå): hvor mange procent af hostens hukommelse containeren bruger
Servicen viser et stabilt forbrug af hukommelse. Den envendte cpu er svagt stigende som servicen bliver presset.
Netværk:
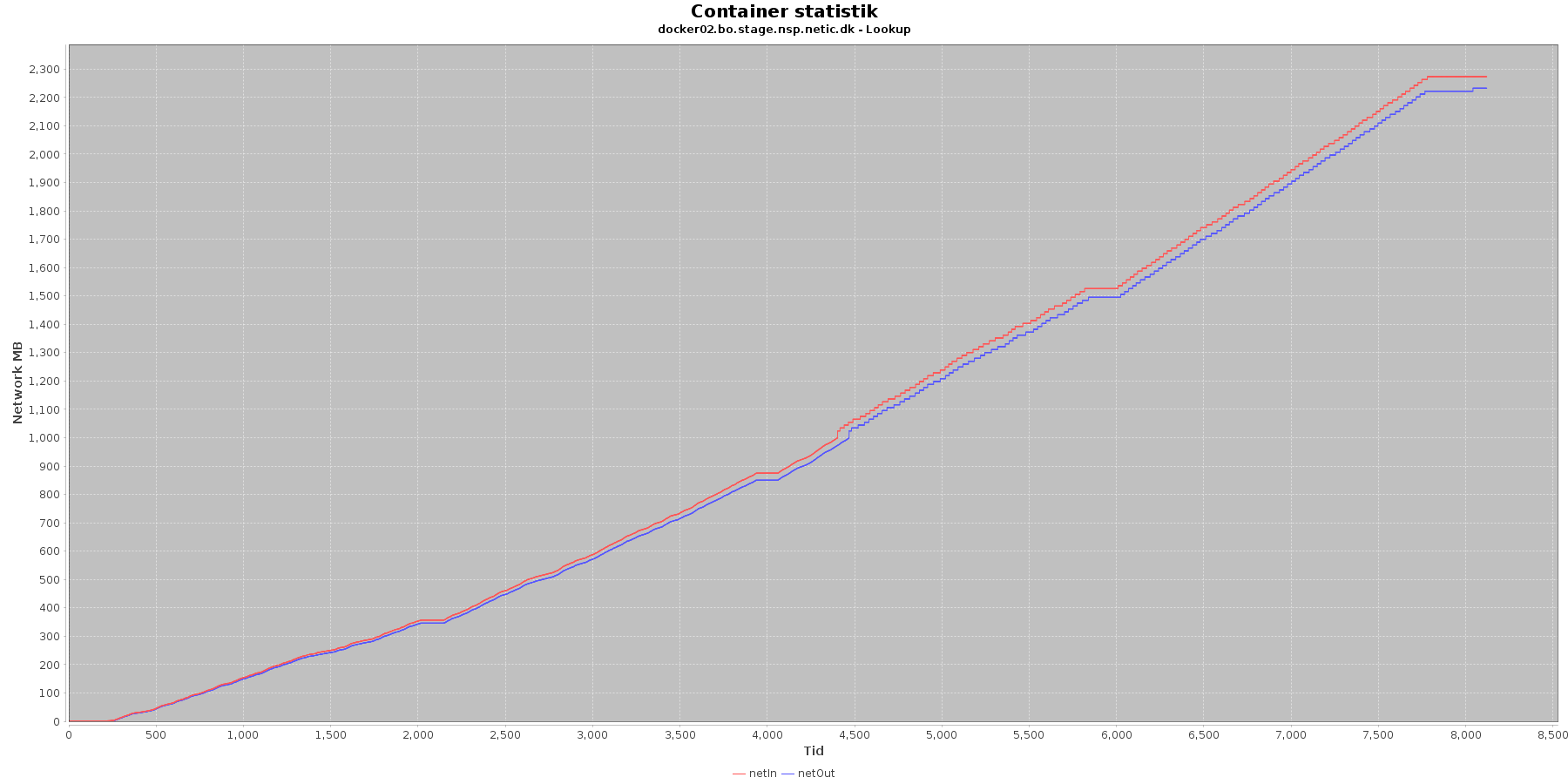
Data serier i grafen er:
- netIn (rød): den mængde data som er modtaget af containeren over netværket
- netOut (blå): den mængde data som er sendt ud af containeren over netværket
De 2 grafer for ind- og udsendt data følges ad, hvilket er forventeligt; indkomne kald skaber trafik til database og igen retur til kalder. netIn stiger mest.
Vurdering
Der er intet at bemærke som kan påvirke servicens performance i negativ retning.
Konklusion
Efter at have analyseres data fra performance testen kan følgende trækkes frem:
- Throughput på testen er 69,49 kald per sekund
- Gennemsnitlig højeste svartid per kald til servicen:
For 95 % percentil: under 1,1 sekunder
For 98 % percentil: under 1,4 sekunder
Kravene på under 2,5 henholdsvis 5,5 sekunder er overholdt - Cpu status: cpu forbruget stiger lidt over test perioden, som servicen presses mere. Dog kun kortvarigt.
- io på netværk: stiger over tid, hvilket er forventet
- Hukommelses forbrug: servicen håndterer brug af hukommelse fint
- Garbage collection: servicen kører jævnligt garbage collection og dermed stiger hukommelses forbruget ikke over tid. Dette er et tegn på, at vi ikke har memory leaks.
Analysen af performance test data har ikke givet anledning til bekymring eller identificering af flaskehalse.
MinLog2 - Performancetest rapport registration
Performance testen består af en række kald til registrering af minlog2 data med forskellige cpr numre.
Testen, som er udført er, komponent "minlog2", testplan "registration" og distribution "test900".
MinLog 2 service er version 2.0.25 og NSP standard performance test framework version 2.0.22.
Der analyseres access og stats log fra registration komponenten, samt stats log fra kafka-consumer komponenten. Derudover ses der på kafka consumer lag for begge.
Det har kun været muligt at få adgang til log filerne for 2 ud af de 4 testede applikationer (docker containere), hvorfor analysen af disse filer kun baserer sig på docker01 og docker02. Typisk er der ikke den store forskel på resultatet fra de forskellige applikationer.
De rå test resultater er vedhæftet denne side (minlog2-registration-test900-run3.tar.gz).
JMeter log data
JMeter hoved filen beskriver overordnet testens resultat. Her kan ses, at der er kørt 8 iterationer med test, belastningen i form af tråde og nodes, deres tidsinterval , throughput og fejlprocent for hver:
Iteration | Tråde | Nodes | Starttid | Sluttid | Throughput | Fejlprocent |
|---|---|---|---|---|---|---|
| 1 | 1 | 2 | 2020-05-06_11-57-39 | 2020-05-06_12-12-43 | 5,89 kald per sekund | 2,645% |
| 2 | 2 | 2 | 2020-05-06_12-13-03 | 2020-05-06_12-28-06 | 12,28 kald per sekund | 1,465% |
| 3 | 3 | 2 | 2020-05-06_12-28-24 | 2020-05-06_12-43-29 | 20,14 kald per sekund | 0,53% |
| 4 | 4 | 2 | 2020-05-06_12-43-49 | 2020-05-06_12-58-55 | 27,33 kald per sekund | 0,215% |
| 5 | 5 | 2 | 2020-05-06_12-59-26 | 2020-05-06_13-14-31 | 34,4 kald per sekund | 0,145% |
| 6 | 6 | 2 | 2020-05-06_13-14-47 | 2020-05-06_13-29-51 | 37,73 kald per sekund | 0,135% |
| 7 | 6 | 3 | 2020-05-06_13-30-12 | 2020-05-06_13-45-16 | 51,48 kald per sekund | 0,157% |
| 8 | 6 | 4 | 2020-05-06_13-45-43 | 2020-05-06_14-00-55 | 52,96 kald per sekund | 0,49% |
Det fremgår også af filen, at den endelige måling af throughput er 52,96 kald per sekund.
Samt at fejlprocentet på den fulde kørsel er 0,49 %.
Access log data
Denne log findes for hver applikations server (docker container) hvor registration komponenten har kørt.
Her findes data for hvert enkelt kald, der er lavet til minlog servicen, herunder hvor lang tid et kald har taget (Duration) samt hvornår kaldet er udført. Ud fra loggens data kan man også beregne hvor mange kald, der udføres i en given periode.
Følgende tabel viser en række beregnede data fra access loggen fordelt på applikations server (container) og test iteration. Nederst i tabellen er tallene for hver applikations server lagt sammen. Denne sum er kun ca. halvdelen af, hvad der totalt er håndteret, da log filerne kun findes for 2 applikationer servere. Test iteration er beregnet ved at sammenligne tidstempel fra access log med start og sluttidspunktet for iterationen.
De beregnede data er antal kald, kald per sekund i gennemsnit (hver iteration er 900 sekunder) samt tidsforbrug per kald i millisekunder. Derudover er antal kald der tager 6,5 sekund eller mere samt 15,5 sekund eller mere talt sammen for at kunne vurdere performance kravene.
| Application server | Iteration | Antal kald | Kald per sekund | Tidsforbrug (ms) | Kald >= 6,5 sekund | Kald >=15,5 sekund |
|---|---|---|---|---|---|---|
| docker01.cnsp.stage.nsp.netic.dk | 1 | 1325 | 1,5 | 198 | 0 = 0 % | 0 = 0 % |
| 2 | 2765 | 3,1 | 211 | 0 = 0 % | 0 = 0 % | |
| 3 | 4540 | 5,5 | 178 | 0 = 0 % | 0 = 0 % | |
| 4 | 6159 | 6,8 | 157 | 0 = 0 % | 0 = 0 % | |
| 5 | 7748 | 8,6 | 150 | 0 = 0 % | 0 = 0 % | |
| 6 | 8494 | 9,4 | 167 | 0 = 0 % | 0 = 0 % | |
| 7 | 11582 | 12,9 | 240 | 15 = 0,13 % | 15 = 0,13 % | |
| 8 | 12132 | 13,5 | 369 | 52 = 0,43 % | 51 = 0,42 % | |
| docker02.cnsp.stage.nsp.netic.dk | 1 | 1325 | 1,5 | 236 | 0 = 0 % | 0 = 0 % |
| 2 | 2765 | 3,1 | 211 | 0 = 0 % | 0 = 0 % | |
| 3 | 4540 | 5,0 | 168 | 0 = 0 % | 0 = 0 % | |
| 4 | 6159 | 6,8 | 154 | 0 = 0 % | 0 = 0 % | |
| 5 | 7748 | 8,6 | 148 | 0 = 0 % | 0 = 0 % | |
| 6 | 8494 | 9,4 | 153 | 0 = 0 % | 0 = 0 % | |
| 7 | 11582 | 12,9 | 214 | 11 = 0,09 % | 11 = 0,09 % | |
| 8 | 12105 | 13,5 | 414 | 62 = 0,51 % | 61 = 0,50 % | |
| Total | 109463 | 228 | 140 = 0,13 % | 138 = 0,13 % |
Udtræk af svartid og antal kald fordelt over testens løbetid vises i følgende grafer:
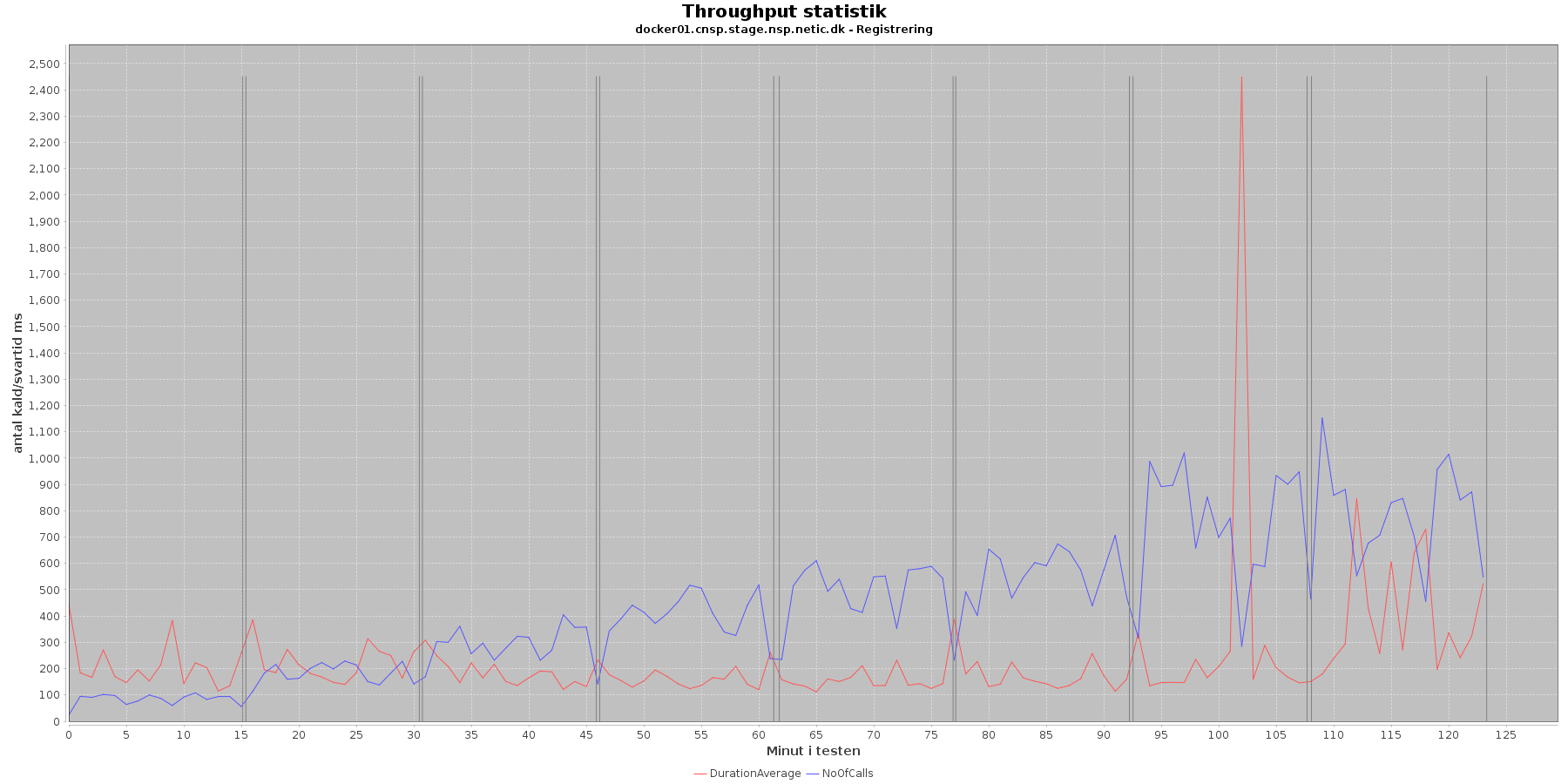
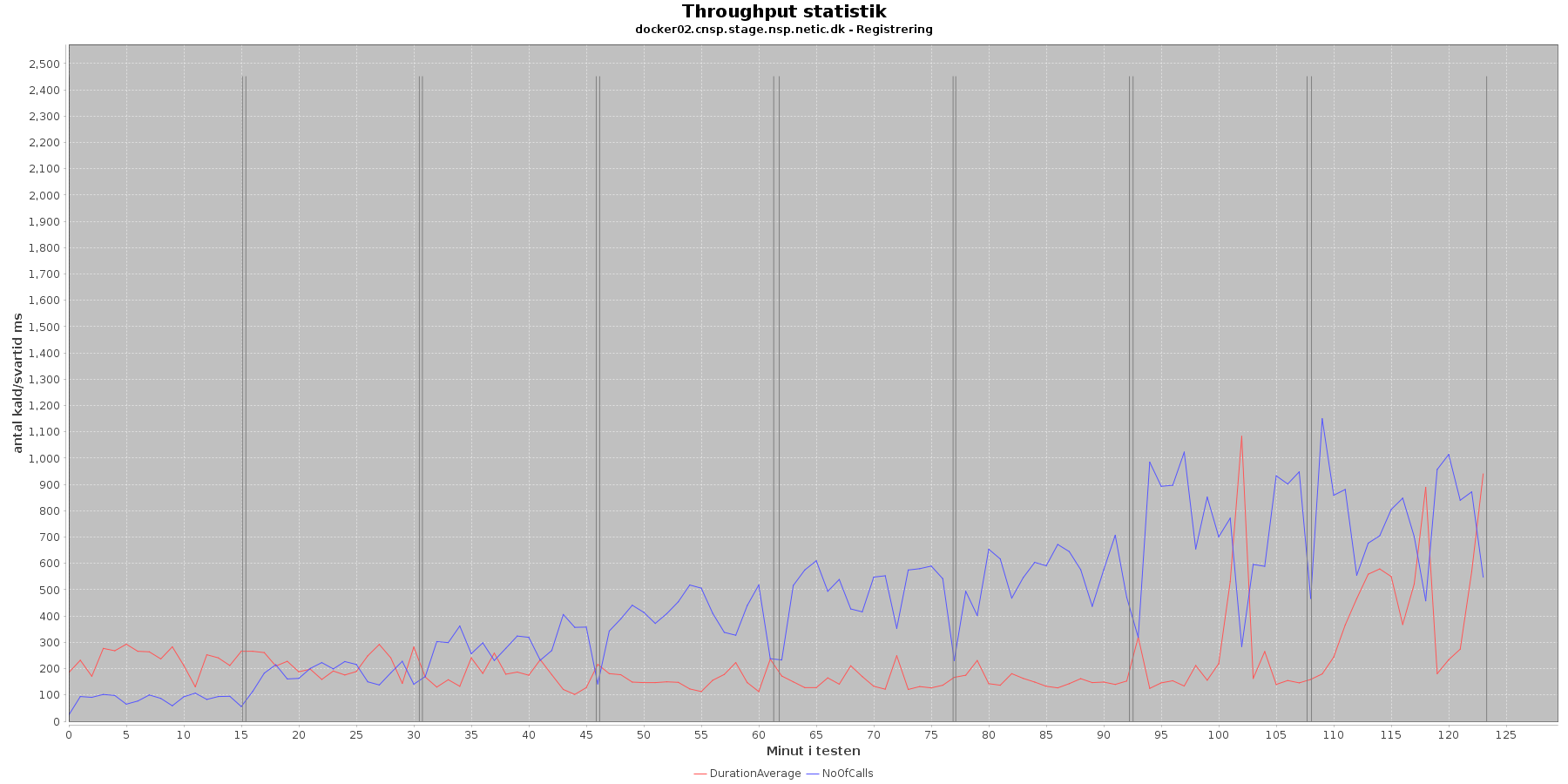
Data serier i grafen er:
- DurationAverage (rød): den gennemsnitlige svartid (ms) for hvert minut
- NoOfCalls (blå): det gennemsnitlige antal kald hvert minut
- De 8 iterationer (sort) er baseret på det tidstempel, som findes i access loggen
Vurdering
Af tabel og grafer fremgår det, at jo flere nodes og tråde (disse øges per iteration) jo flere kald kommer der igennem per tidsenhed.
Det ses, at svartiden ikke ændres i starten, fordi antallet af nodes/tråde øges. Først i iteration 7 bliver svartiden forøget.
Performance kravene er
- under 6,50 sekund for 95 % af tilfældende
- under 15,5 sekund for 98 % af tilfældende
Og disse overholdes fint qua ovenstående tabeloversigt. I iteration 8 på docker02, hvor tallene er højest, er 99,5 % under 6,5 og 15,5 sekunder.
Vmstat log
Denne log findes for hver applikations server (docker container). Både for registration og kafka-consumer. Den viser resultatet af kommandoen vmstat
Udtræk omkring cpu fra denne log vises i de følgende grafer.
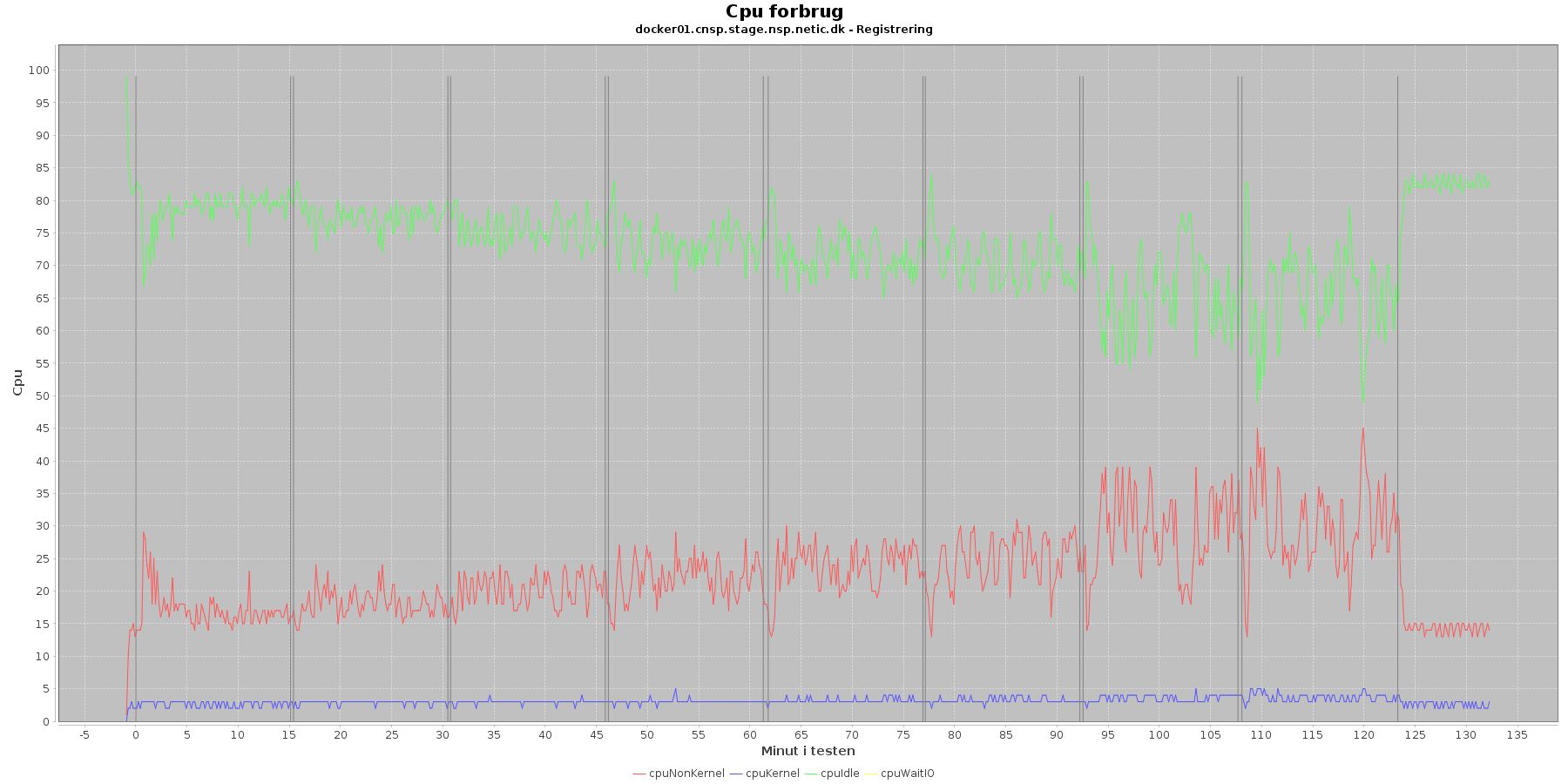
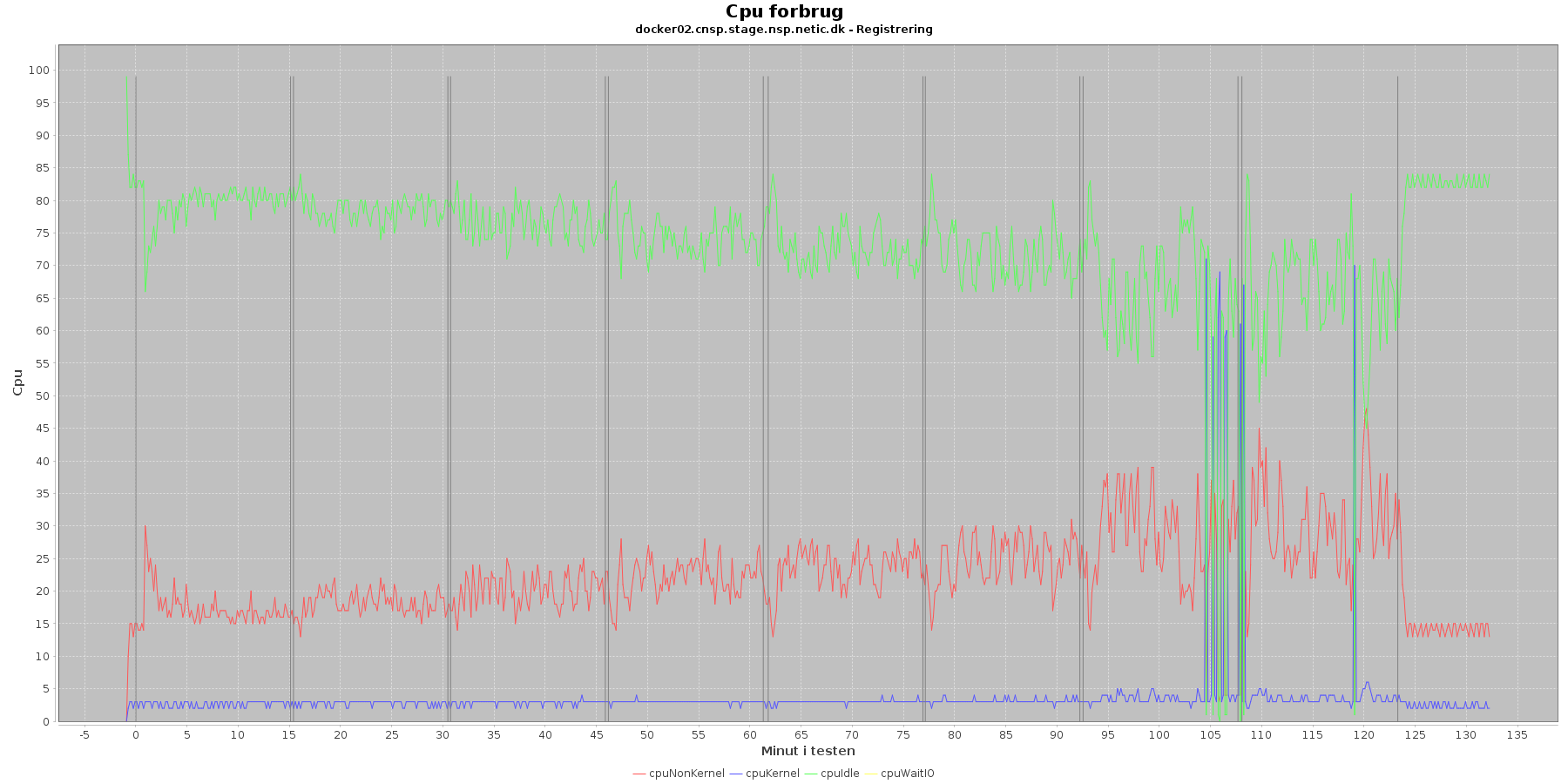
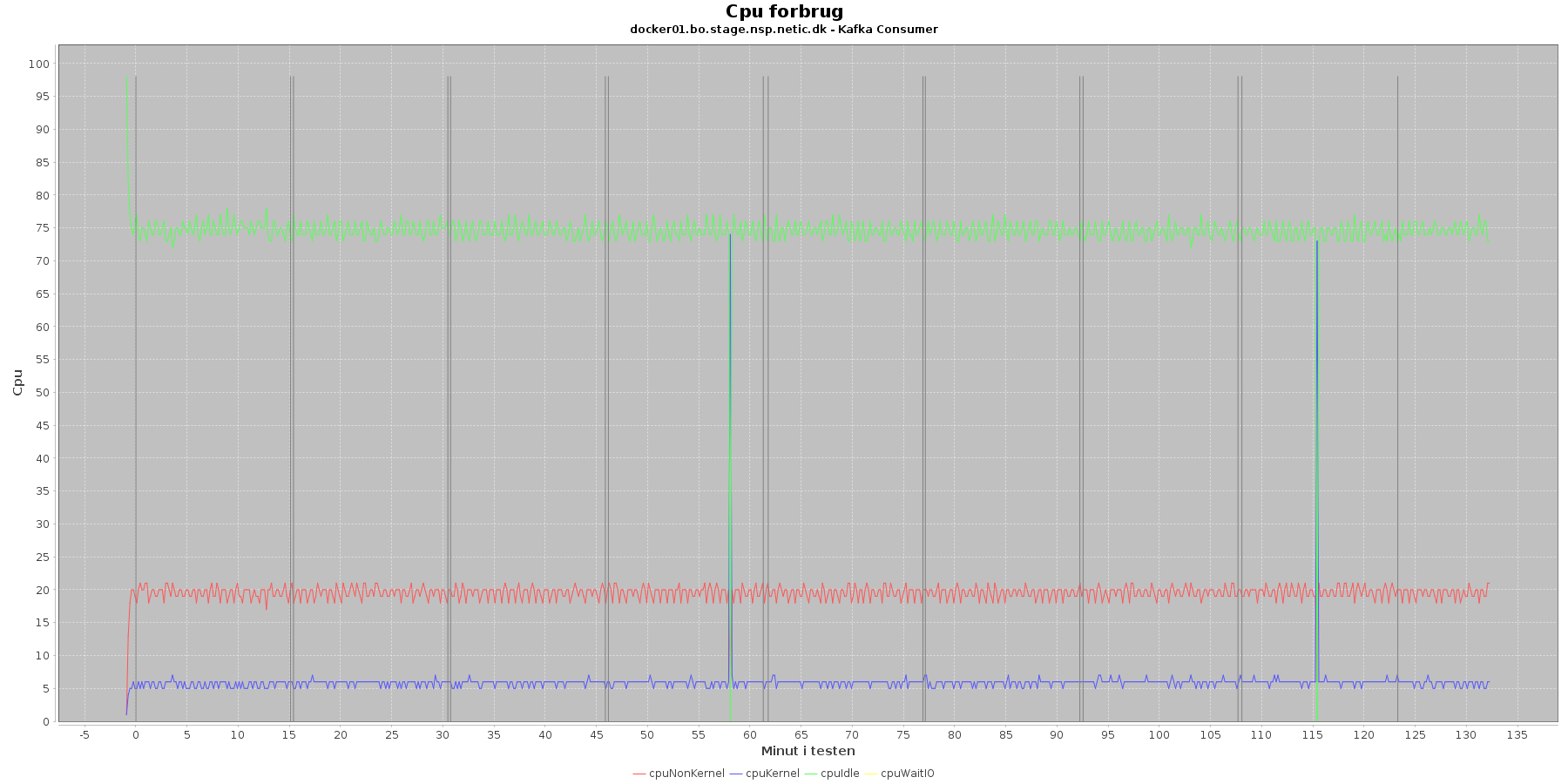
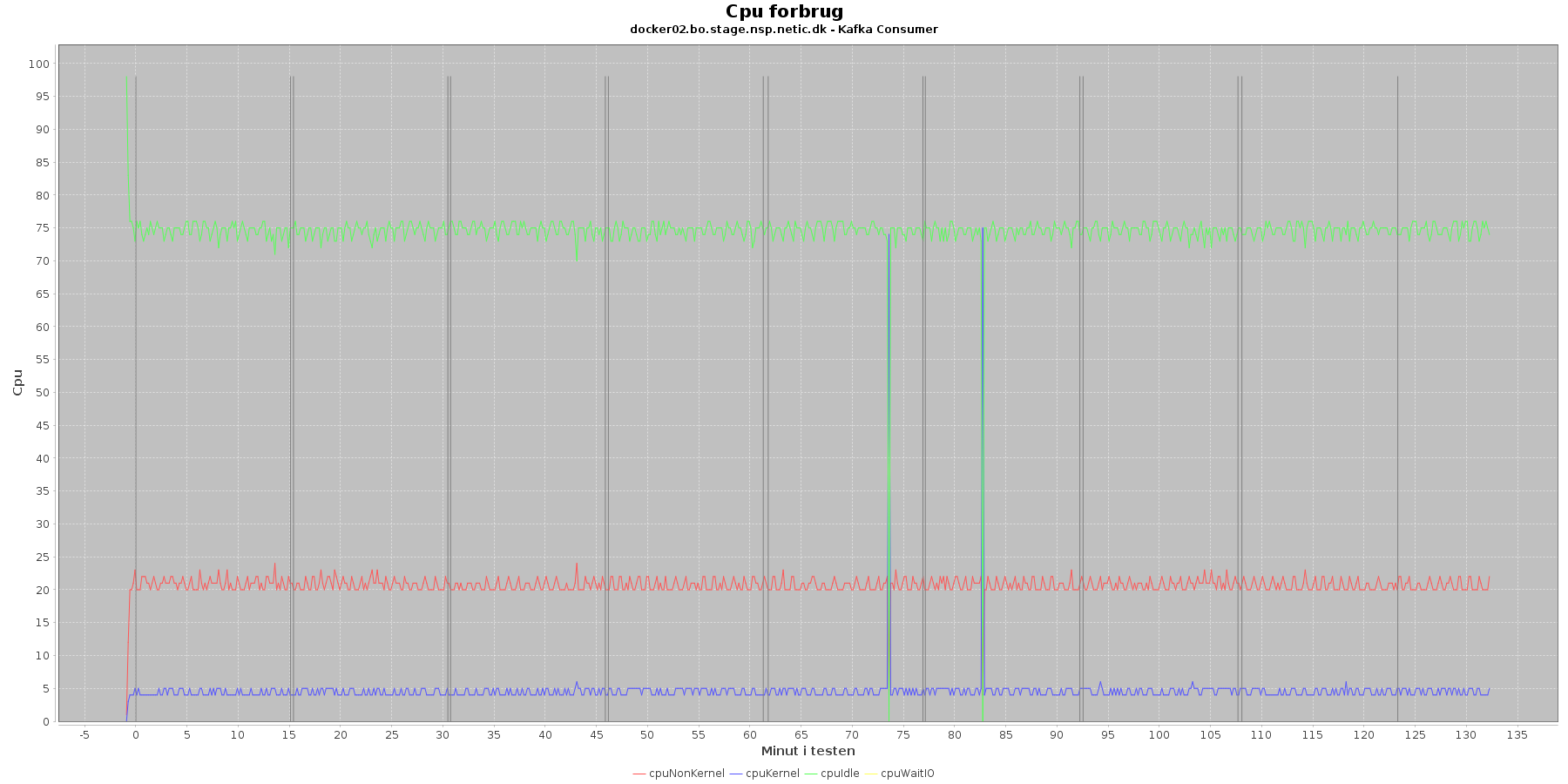
Data serier i grafen er:
- cpuNonKernel (rød): tid brugt på non-kernel opgaver
- cpuKernel (blå): tid brugt på kernel opgaver
- cpuIdle (grøn): tid brugt på ingenting
- cpuWaitIO (gul): tid brugt på at vente på i/o
- iterationerne (sort) er en cirka placering, da wmstat loggen ikke indeholder tidstempel
Registration:
- cpuIdle og cpuNonKernel påvirkes lidt som servicen presses mere. cpuIdle ligger lavere over tid, mens cpuNonKernel grafen ligger en smule højere over tid. Den generelle ændring af kurverne er dog ikke faretruende. I iteration 7 og 8 er der lidt mere udsving for docker02.
Kafka-consumer:
- cpuIdle og cpuNonKernel ligger meget konstant over iterationerne.
Udtræk omkring io læs og skriv fra vmstat vises i de følgende grafer:
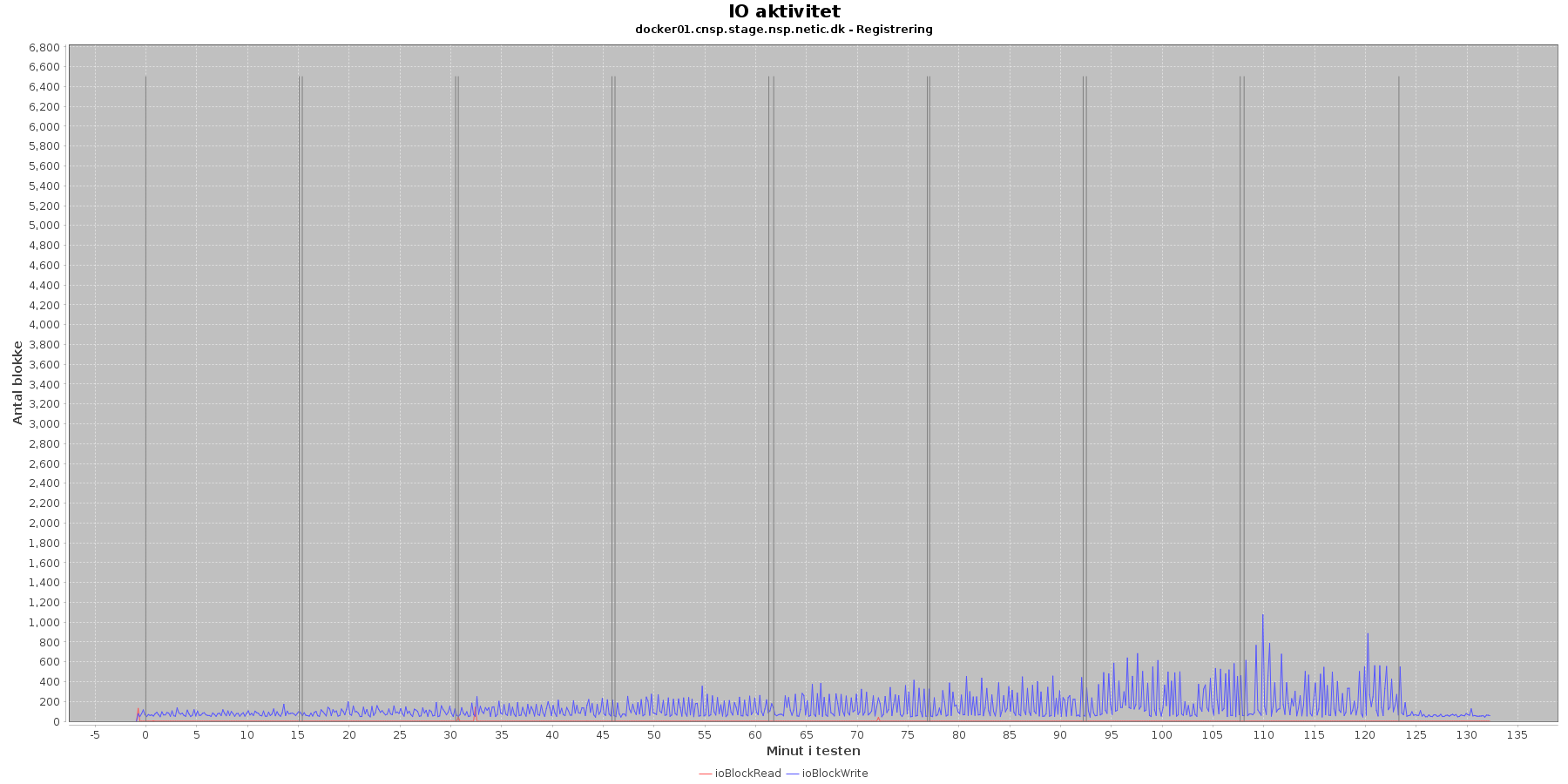
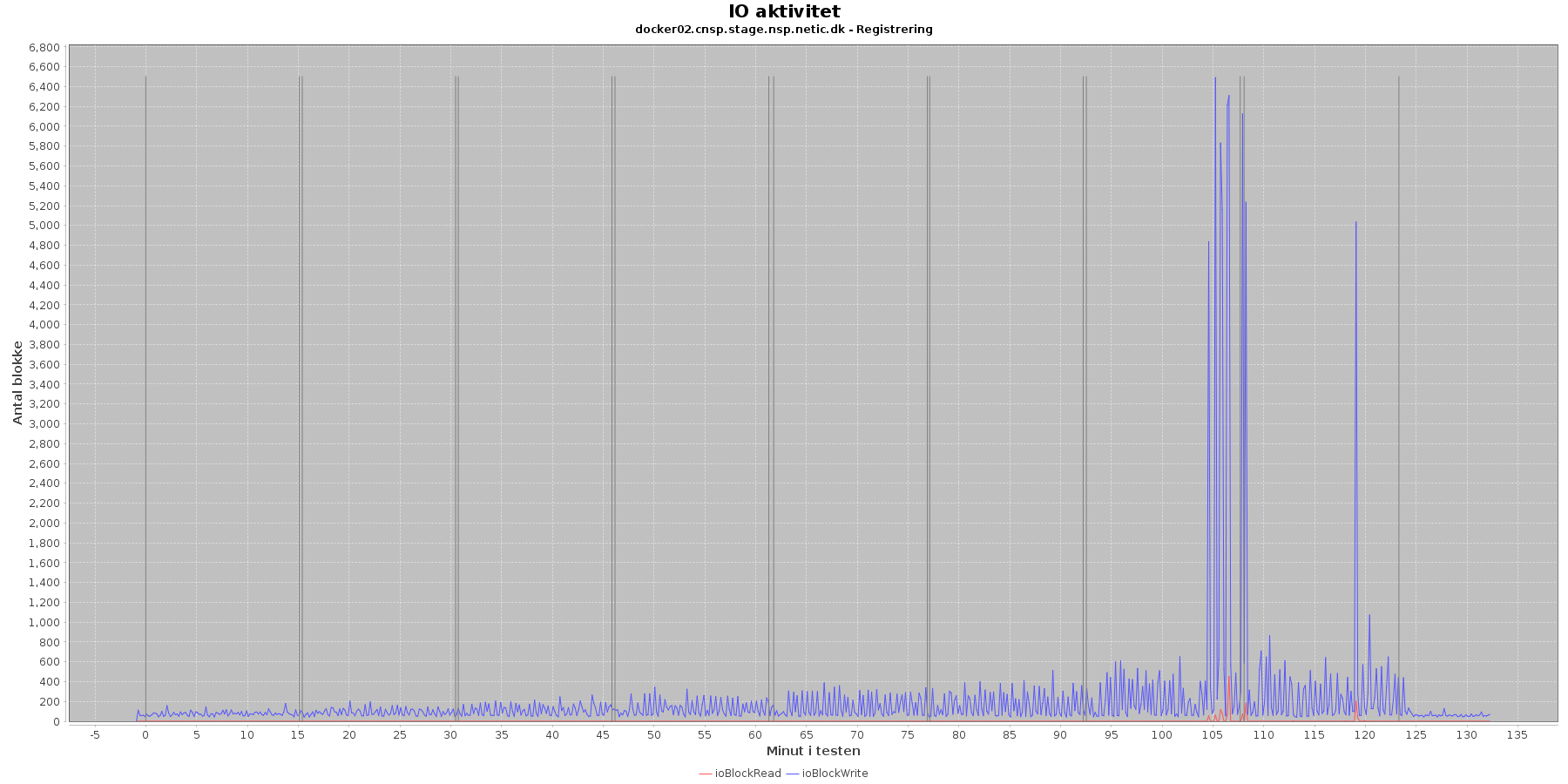
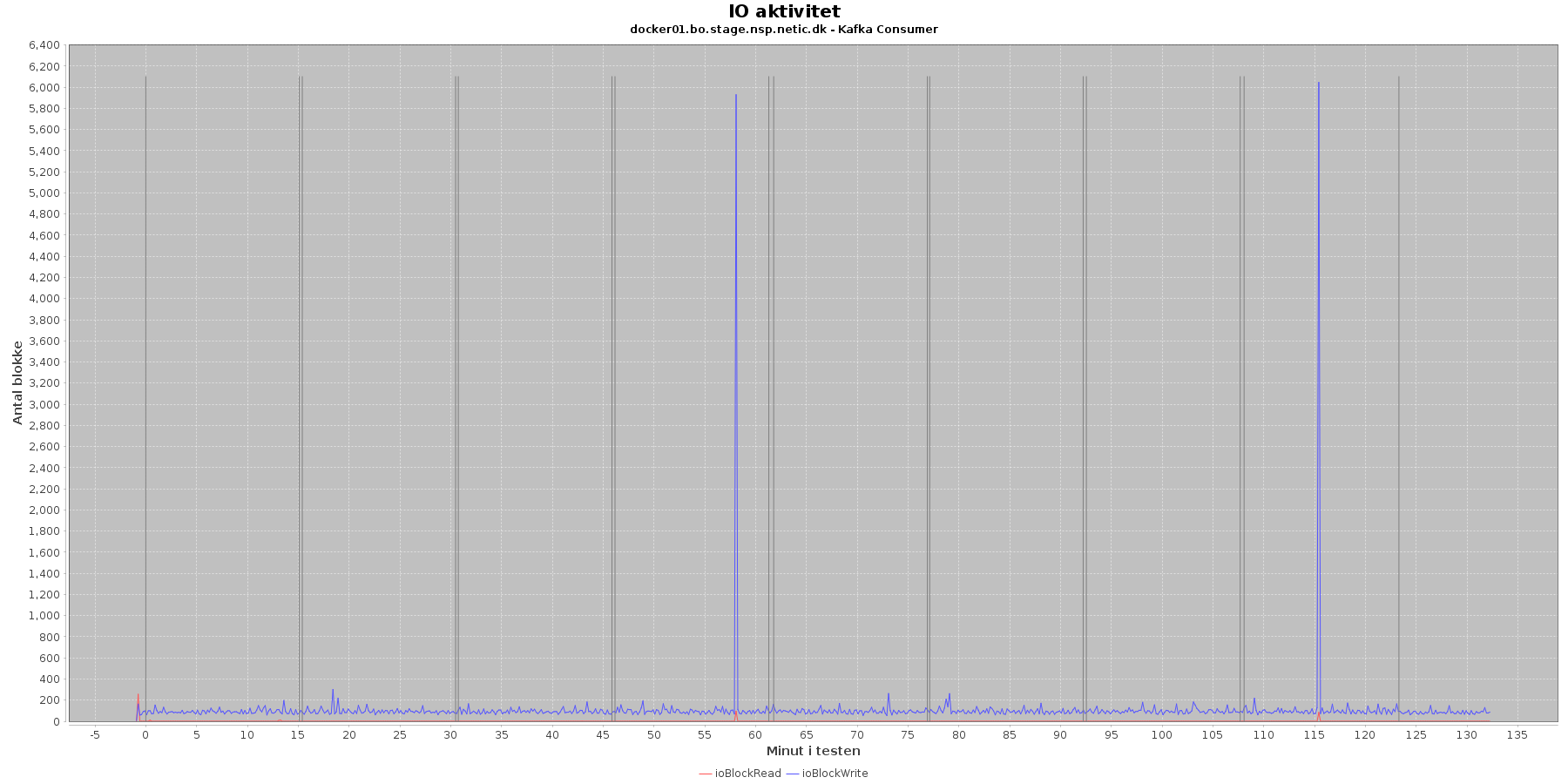
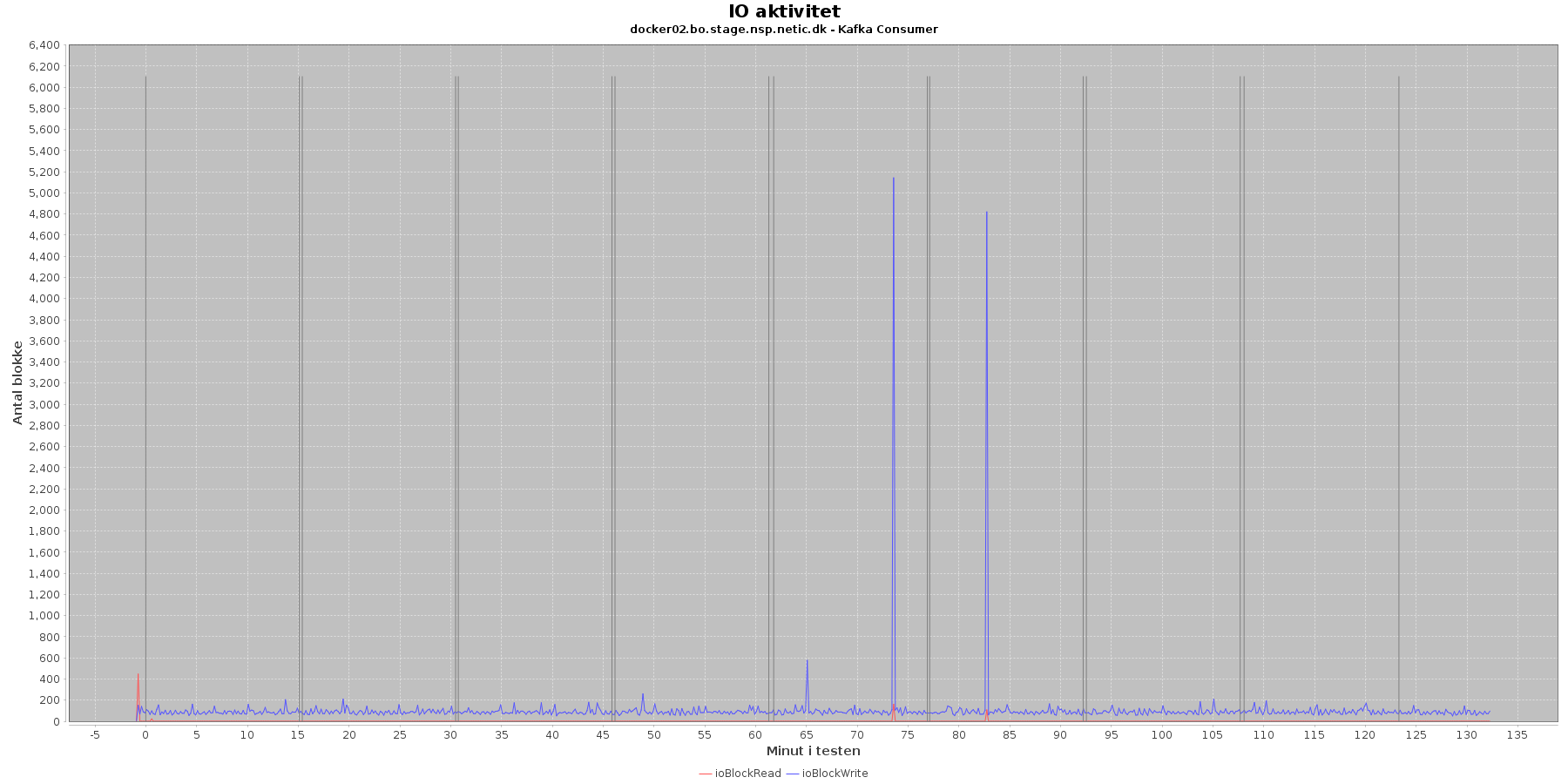
Data serier i grafen er:
- ioBlockRead (rød): læsning på disk (blokke)
- ioBlockWrite (blå): skriving på disk (blokke)
- iterationerne (sort) er en cirka placering, da wmstat loggen ikke indeholder tidstempel
Registration:
- Der er lidt løbende skriv til disken mens testen kører, og i slutningen af iteration 7 en del på docker02. Sammenligner man graferne fra før på cpu forbrug, ses det, at de store udsving i skrivninger falder sammen med at cpuKernal går op og cpuIdle går ned.
Kafka-consumer:
- Der er lidt løbende skriv til disken mens testen kører, og igen falder de få store udsving i skrivninger falder sammen med at cpuKernal går op og cpuIdle går ned.
Vurdering
Der er intet negativt at bemærke omkring cpu forbruget eller disk io.
Jstat log
Denne log findes for hver applikations server (docker container). Både for registration og kafka-consumer. Loggen viser resultatet af kommandoen jstat. Jstat siger noget om, hvordan JVM'en har det.
Udtræk omkring hukommelse og garbage collection fra denne log vises i de følgende grafer.
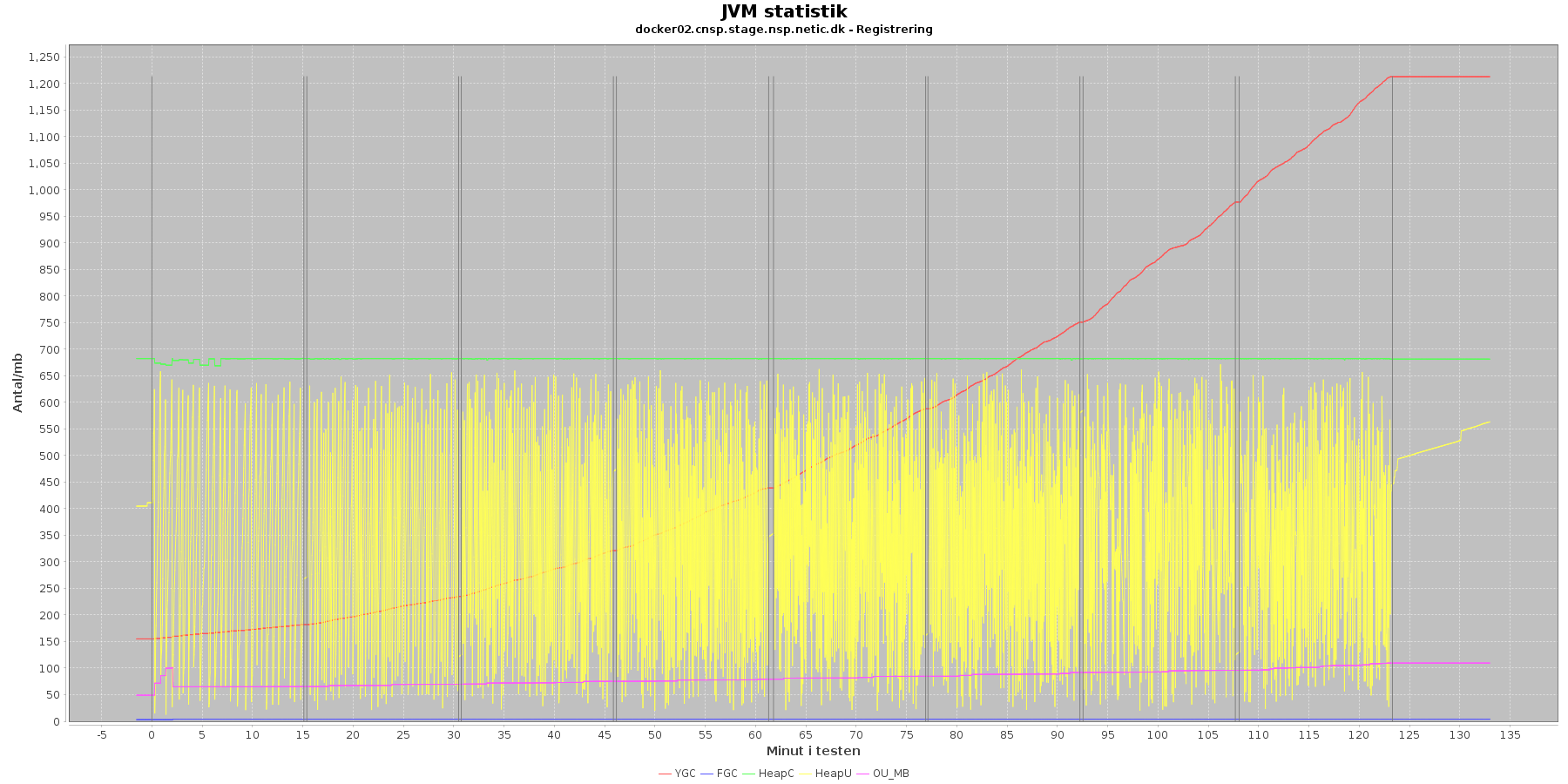
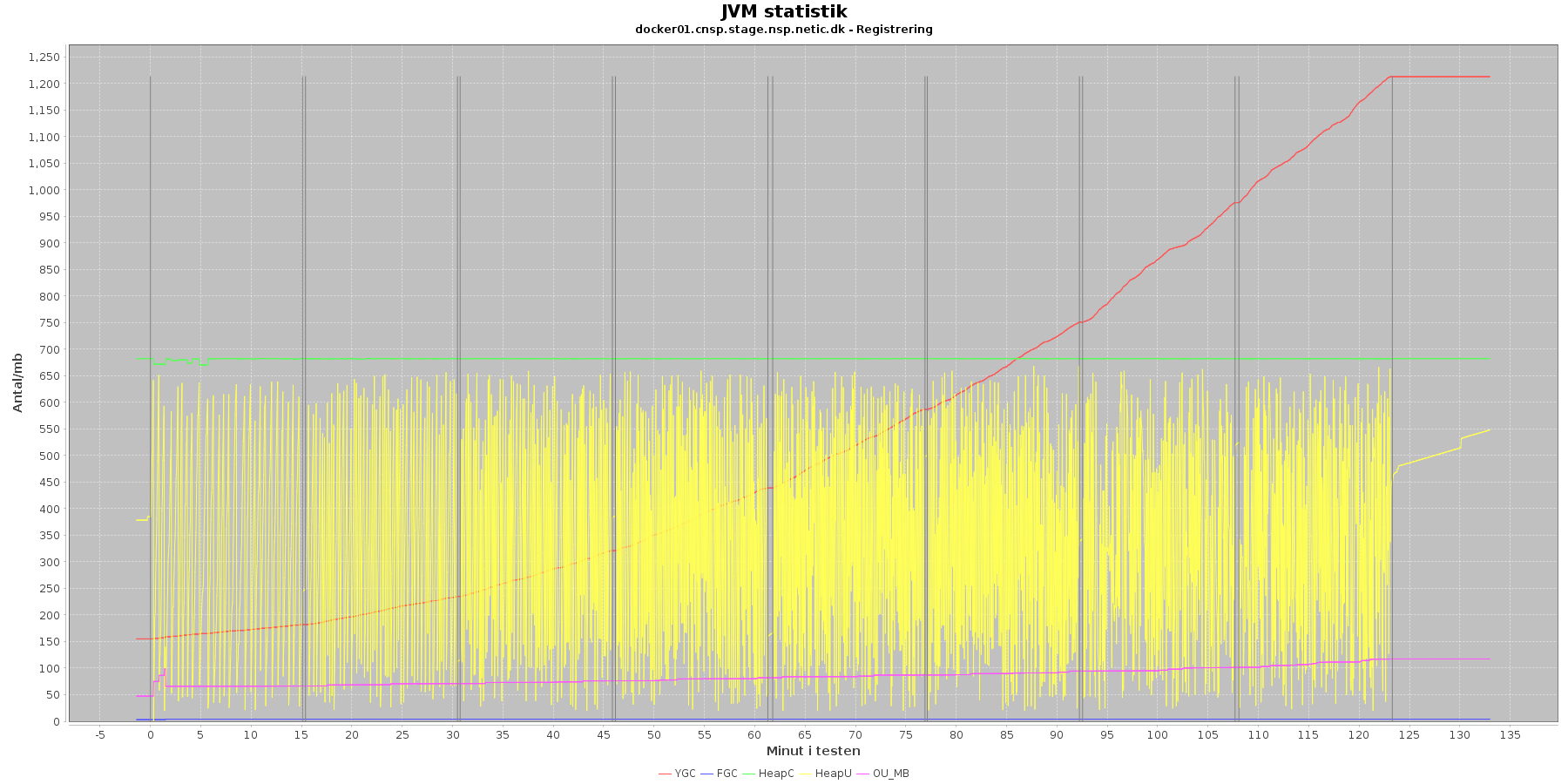
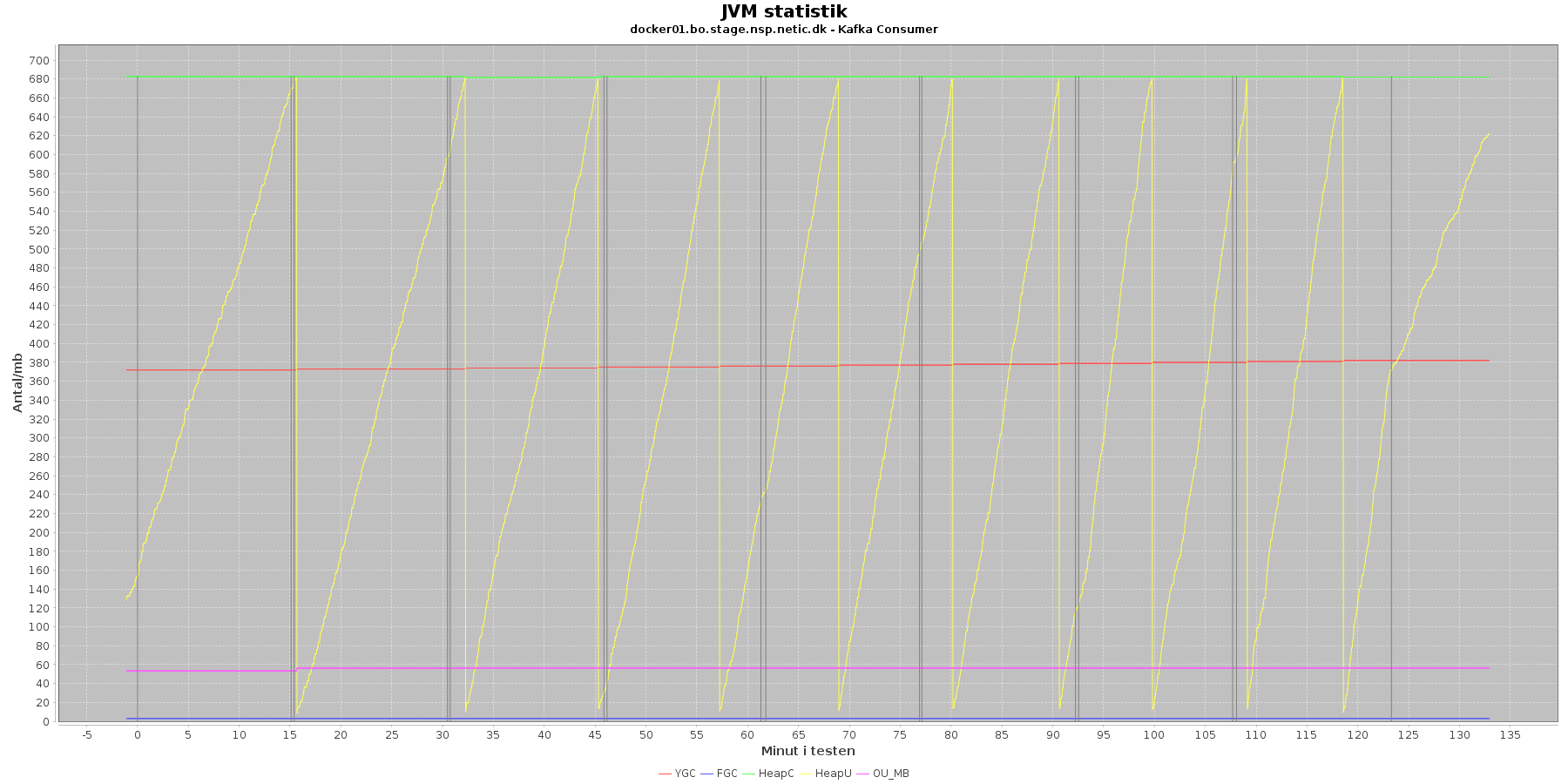
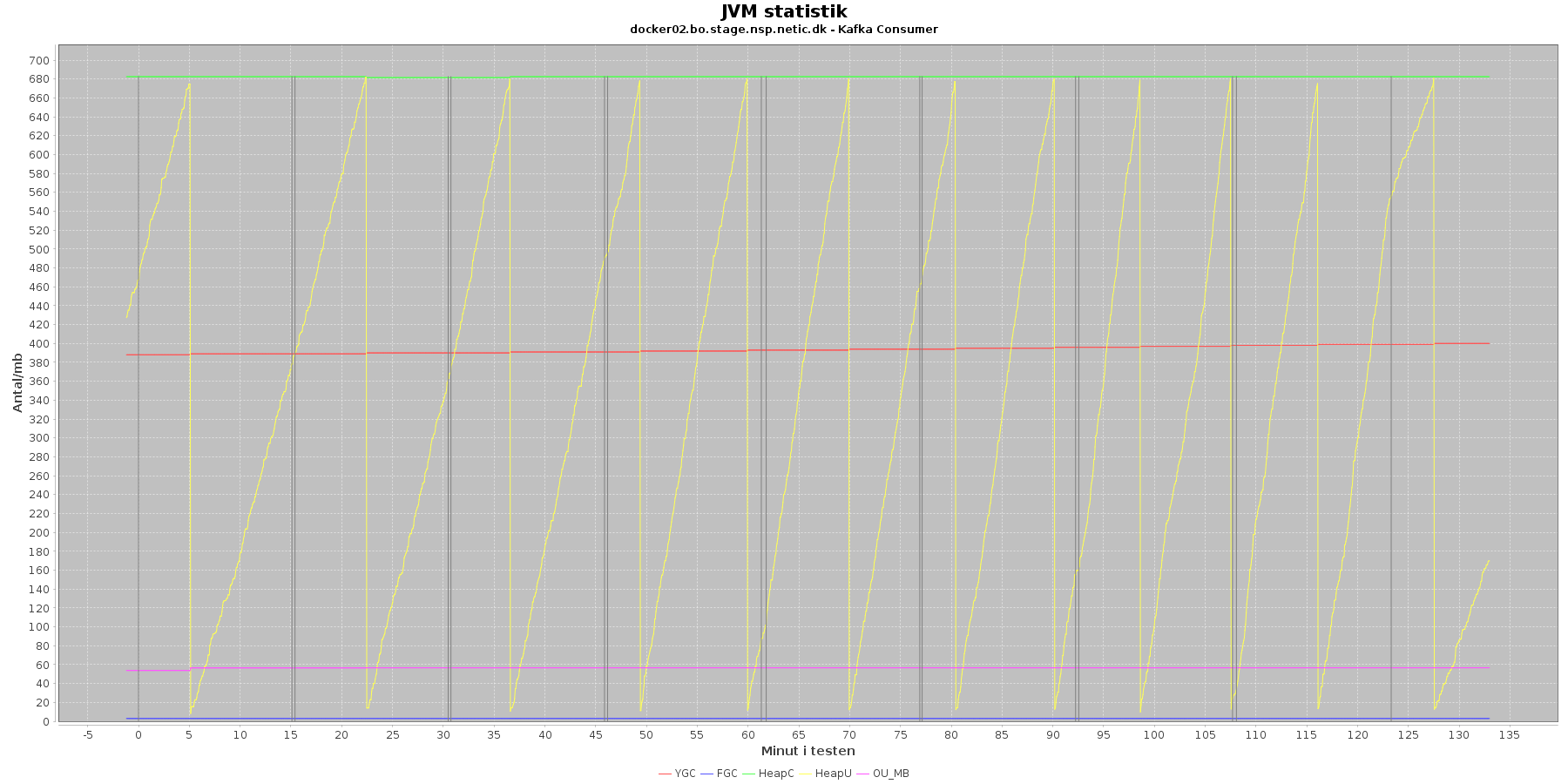
Data serier i grafen er:
- YGC (rød): young generation garbage collection events, antal af "ung" garbage collection siden start
- FGC (blå): full garbage collection events, antal af fuldstændig garbage collection siden start
- HeapU (gul): består af S0U+S1U+EU fra jstat loggen. Young generation memory utilization. "Ung" hukommelses forbrug
- HeapC (grøn): består af S0C+S1C+EC fra jstat loggen. Young generation memory capacity. "Ung" hukommelses kapacitet
- OU_MB (pink): old space utilization. "Ældre" hukommelses forbrug
- OC: oldx space capacity. "Ældre" hukommelses kapacitet er ikke en del af grafen men er konstant på 1.398.272 KB.
- Iterationer (sort) er baseret på det tidstempel, som findes i jstatloggen
Registration:
- Det kan være lidt svært at se i graferne for full garbage collection (FGC). Kigger man nærmere på datagrundlaget bag graferne, ses det, at der kørt full garbage collection for servicen under testen en enkelt gang i starten af første iteration.
- Der er en meget svag stigende tendens på den ældre hukommelse (OU_MB). Man må gå ud fra, at kommer den op på en kritisk grænse, da vil systemet køre en full garbage collection (FGC).
- Der køres ofte garbage collection på den yngre hukommelse, hvilket holder HeapU - yngre hukommelses forbrug - nede så den kun svinger inden for et konstant interval.
Kafka-consumer:
- Her er der ikke kørt fuld garbage collecion (FGC) under testen.
- Der er ikke brug for at køre meget garbage collection på den yngre hukommelse, og den yngre hukommelse (HeapU) holdes nede.
Vurdering
Den yngre forbrugte hukommelse eskalerer ikke. Garbage collecteren gør sit arbejde.
Docker stats log
Denne log findes for hver applikations server (docker container). Både for registration og kafka-consumer. Loggen viser resultatet af kommandoen docker stats. Docker stats siger noget om, hvordan containeren forbruger sine ressourcer.
Udtræk omkring hukommelse, cpu netværkstrafik vises i følgende grafer.
Hukommelse:
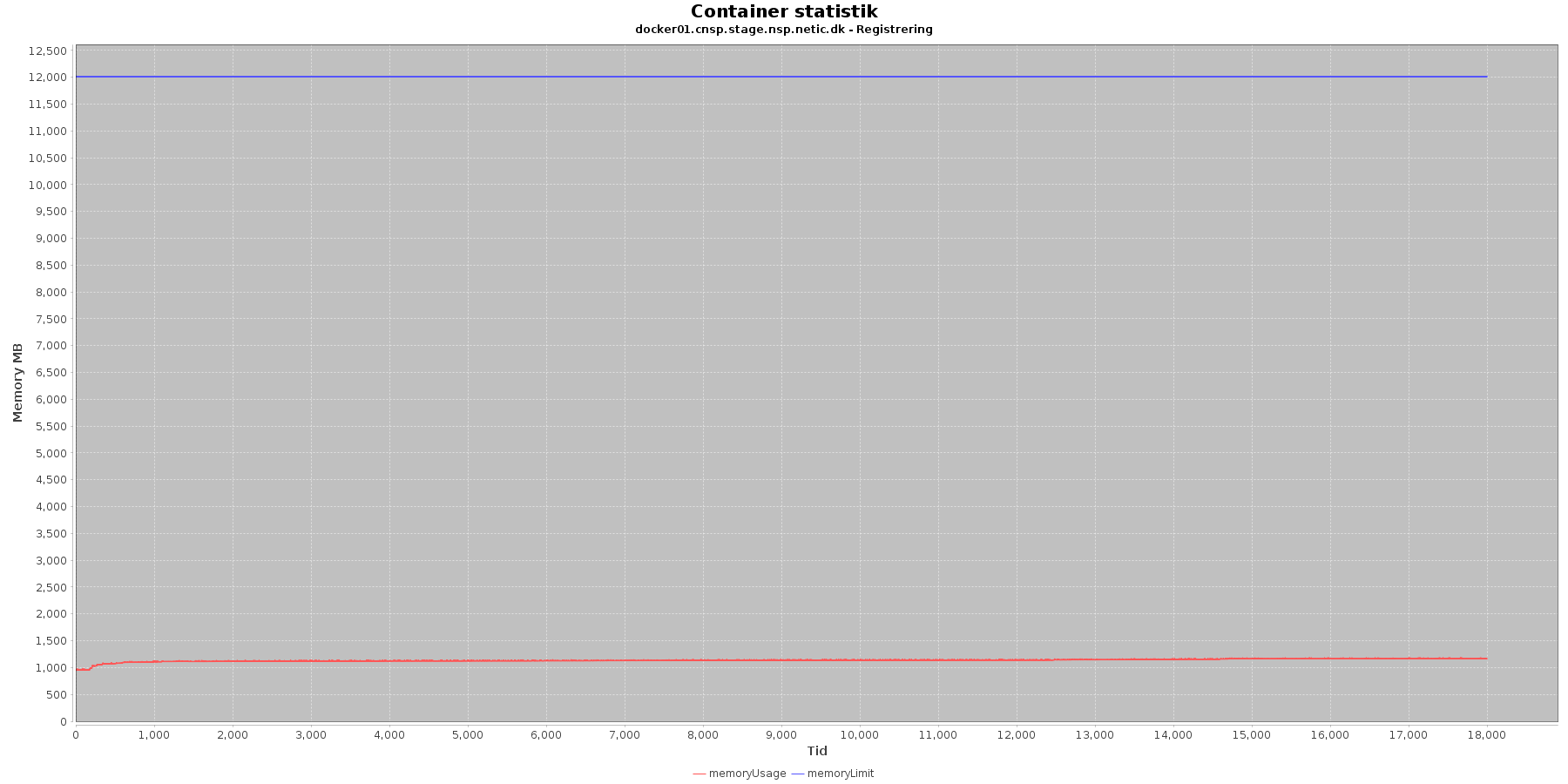
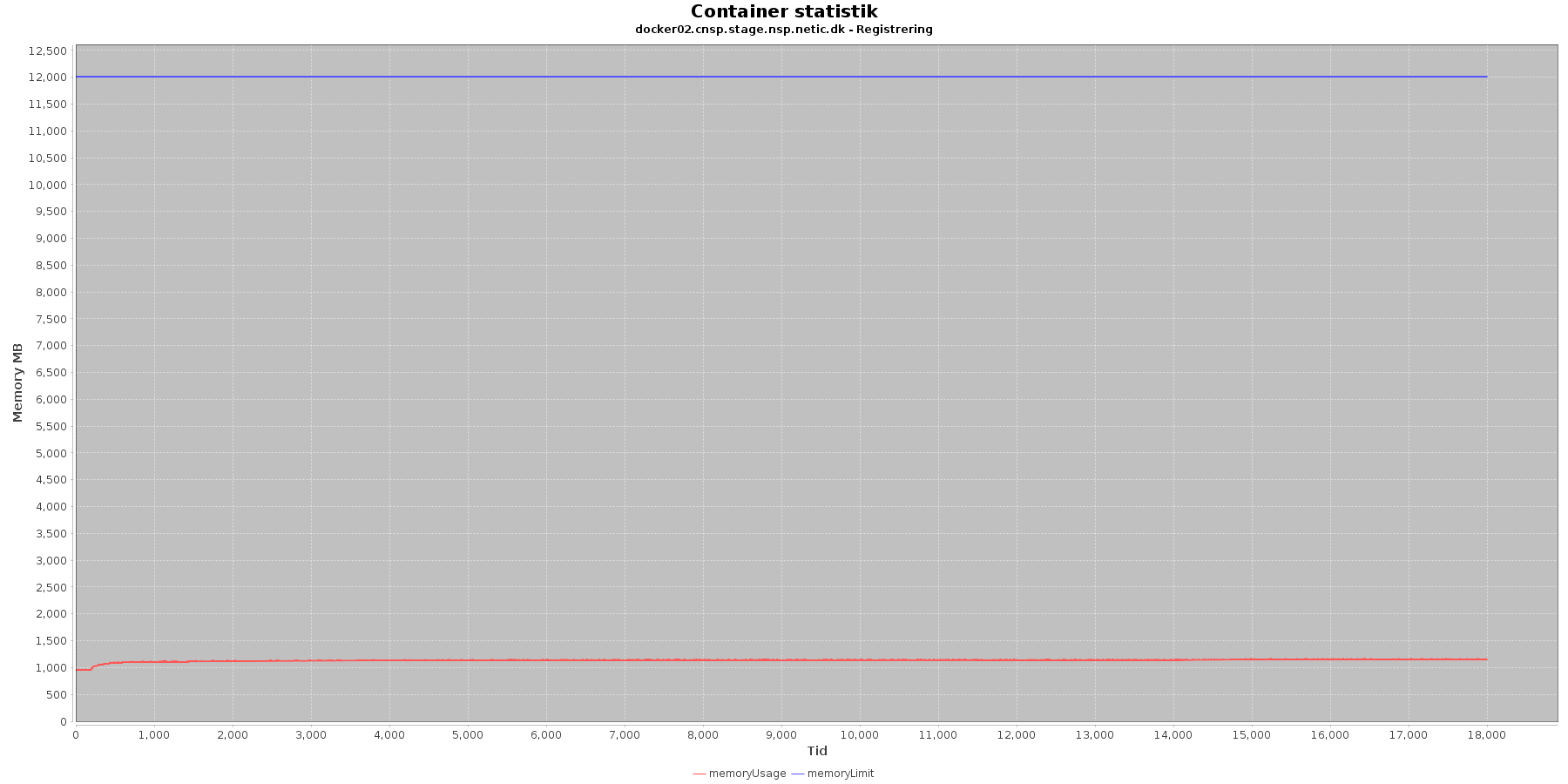
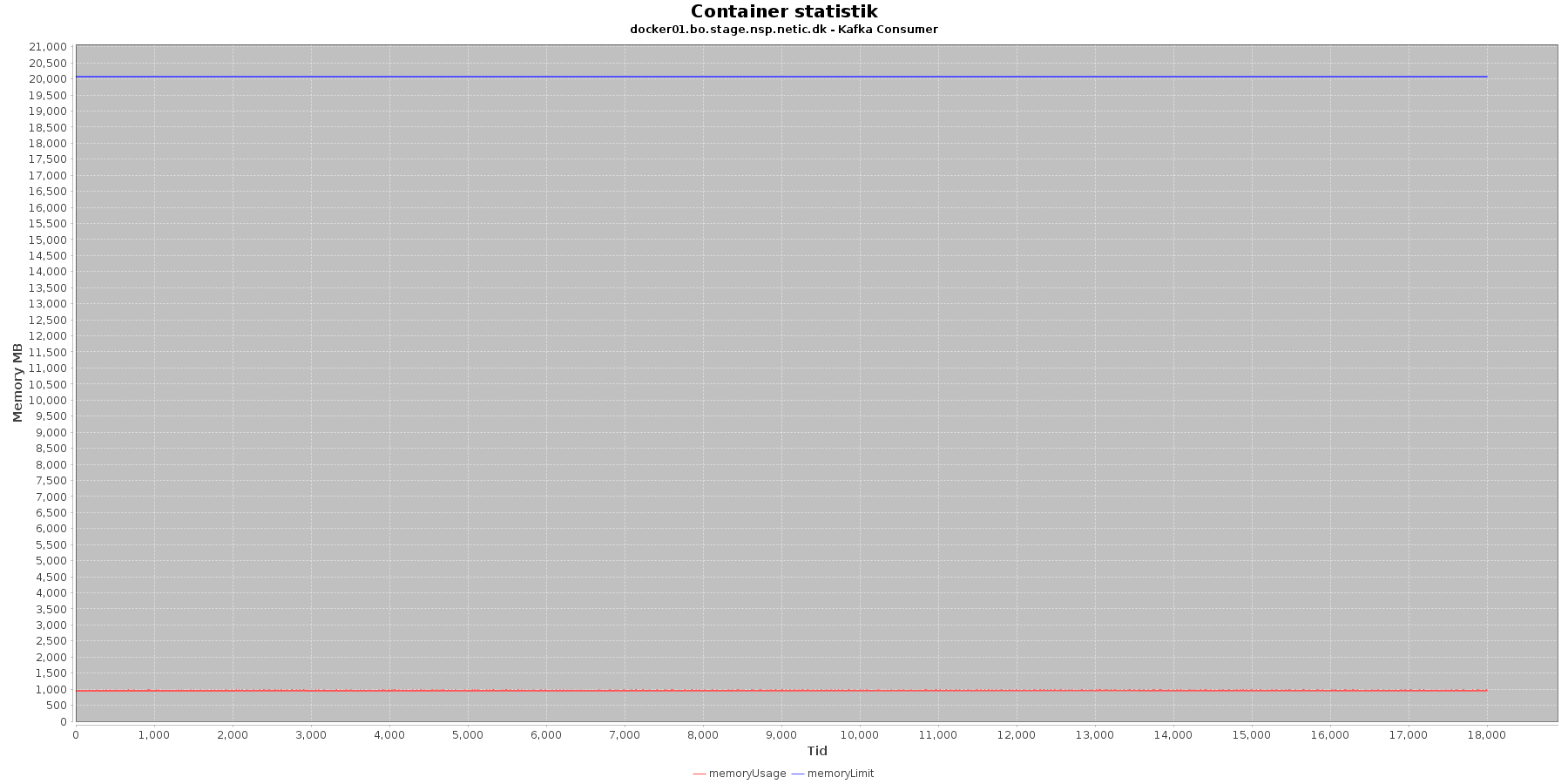
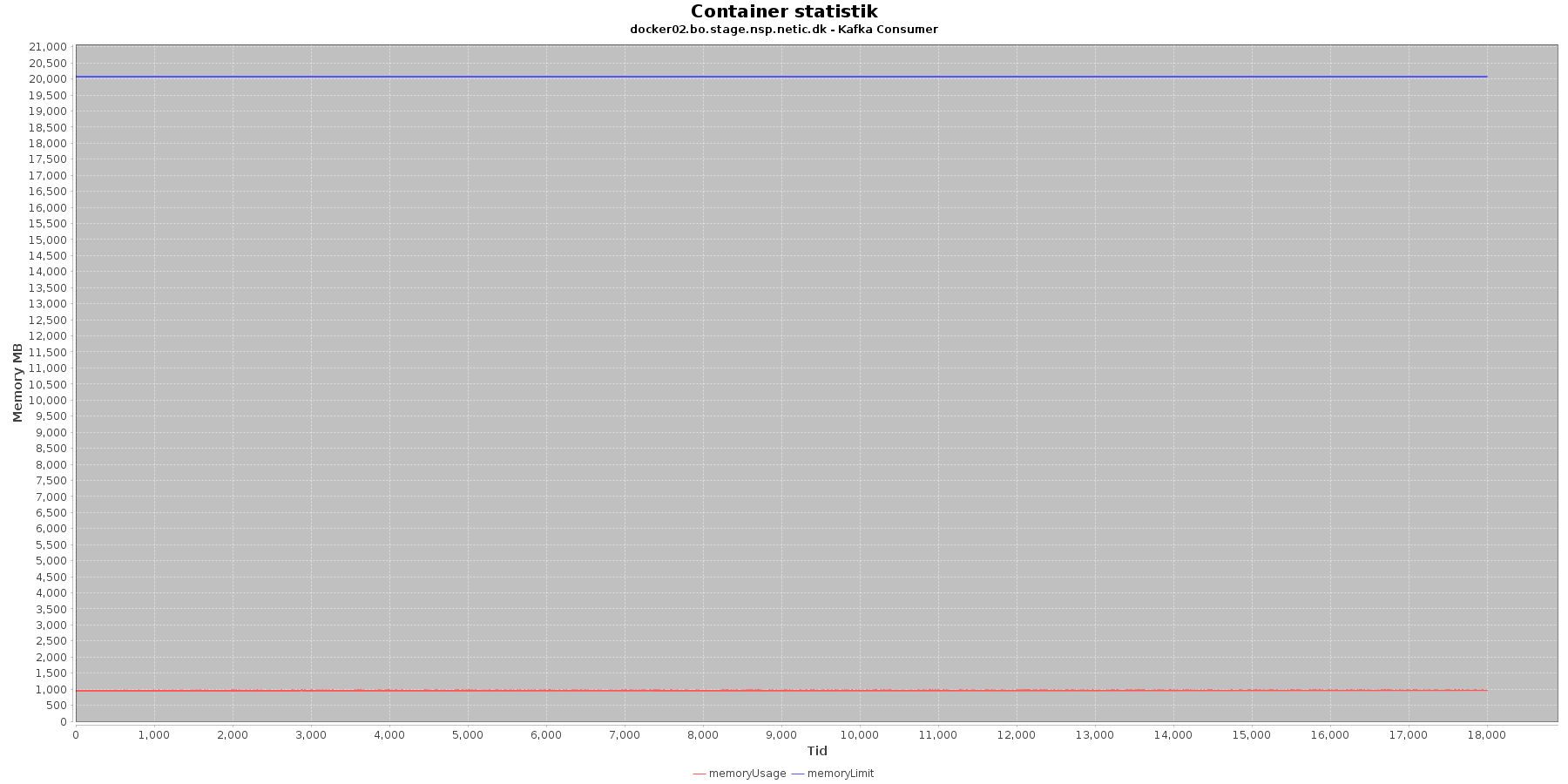
Data serier i grafen er:
- memoryUsage (rød): den totale mængde hukommelse containeren bruger
- memoryLimit (blå): den totale mængde hukommelse contaneren kan bruge
Registration:
- Den forbrugte hukommelse er meget stabil.
Kafka-consumer:
- Den forbrugte hukommelse er meget stabil.
Cpu og hukommelse procent:
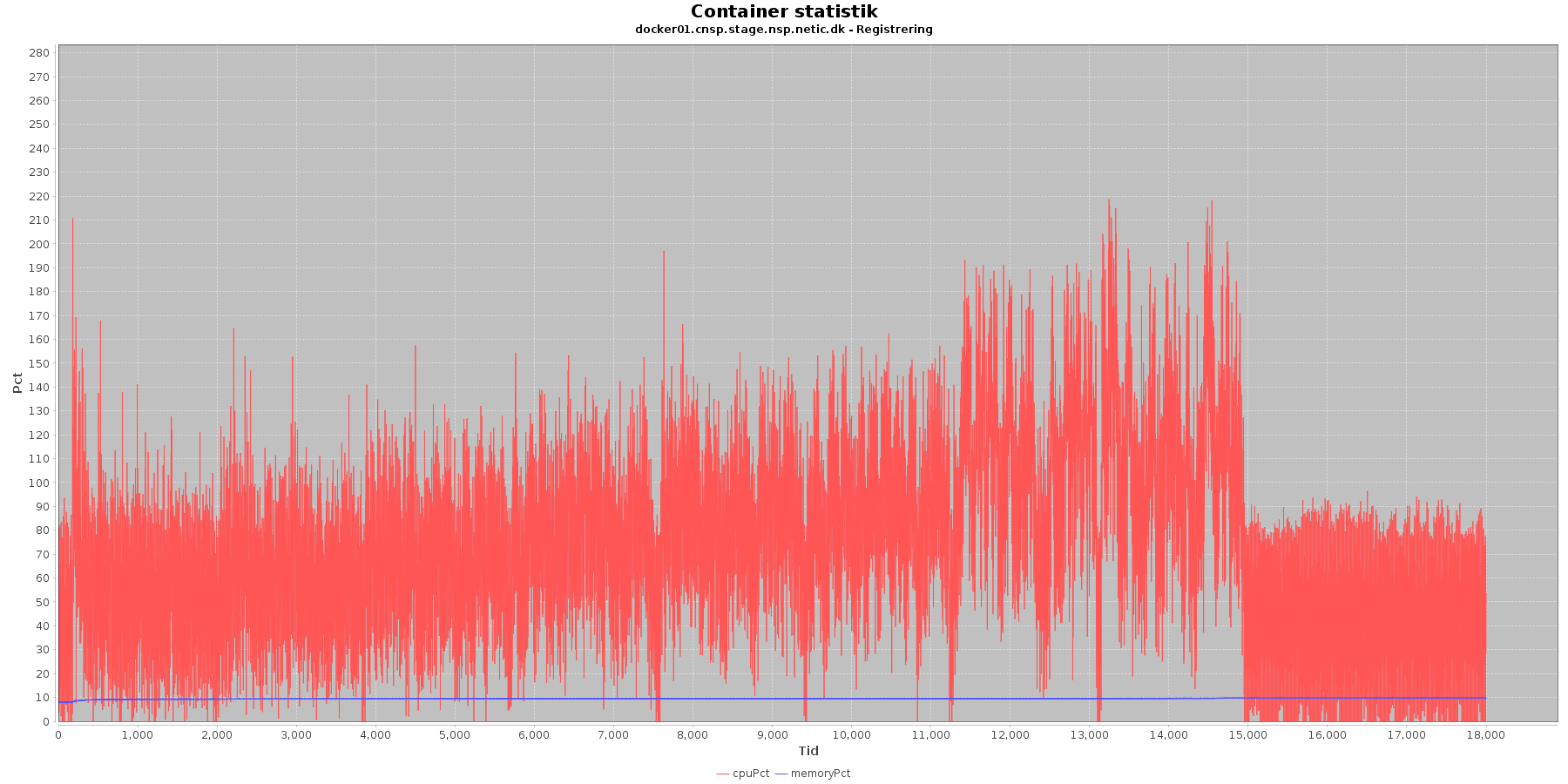
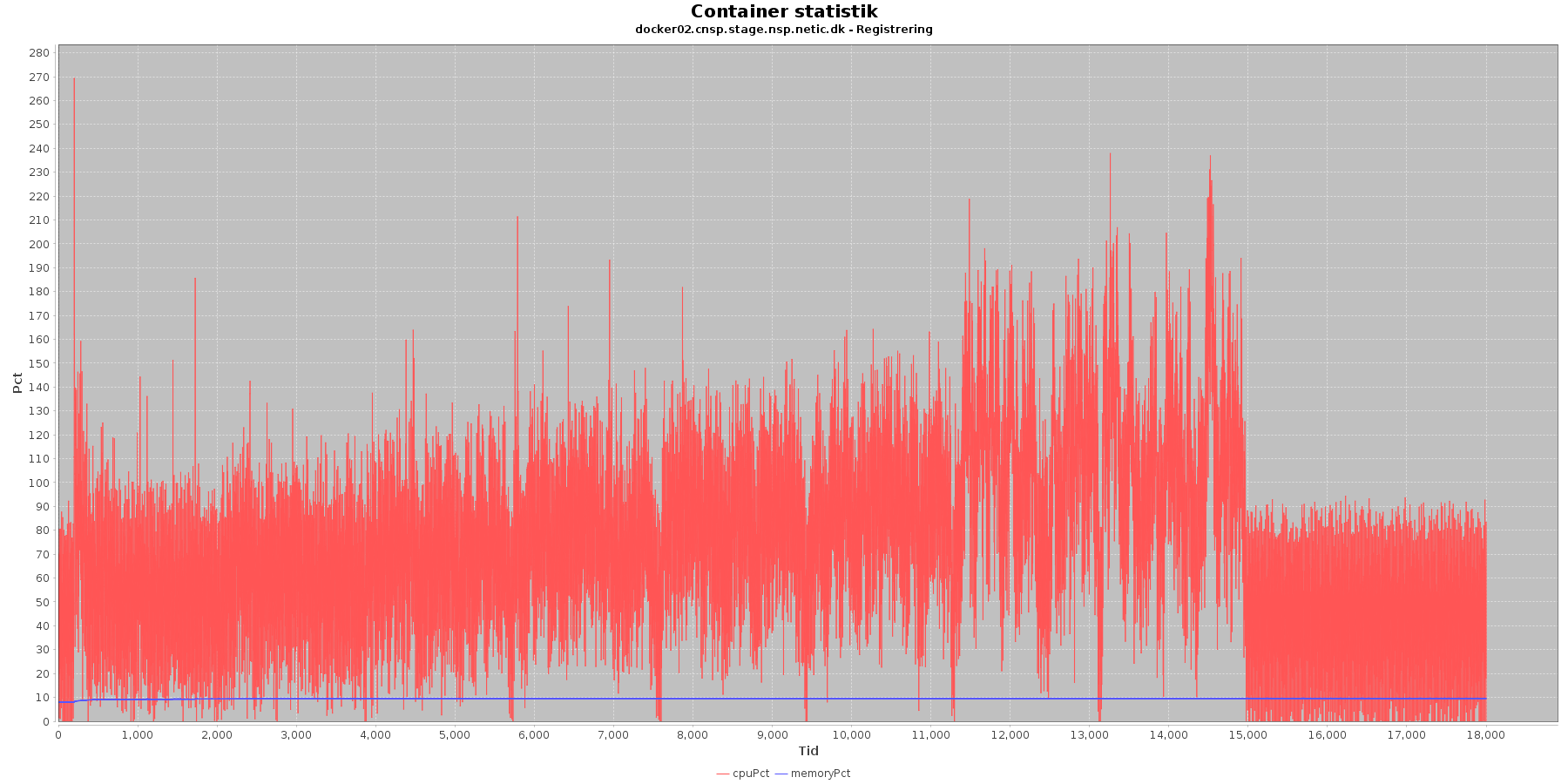
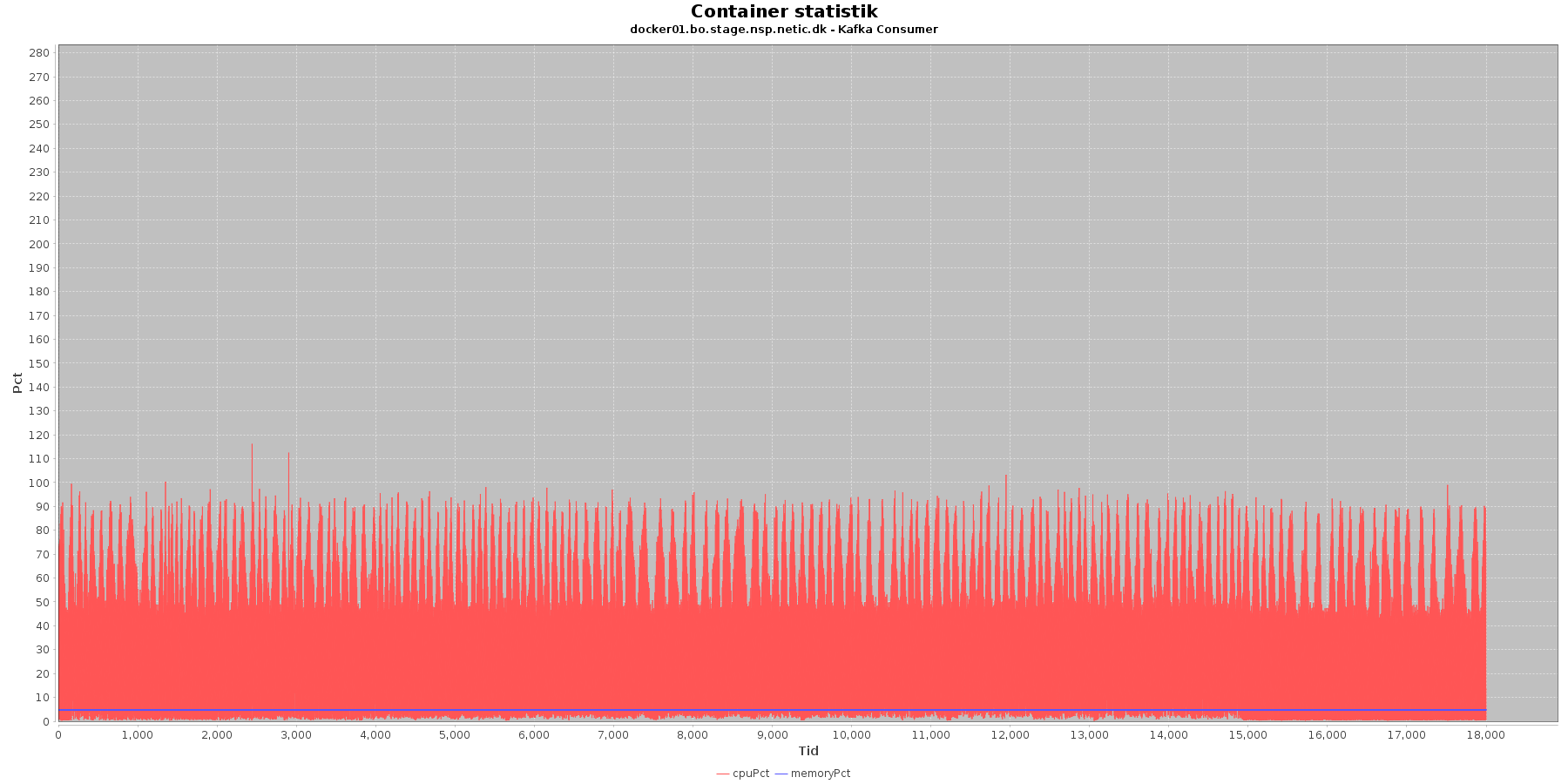
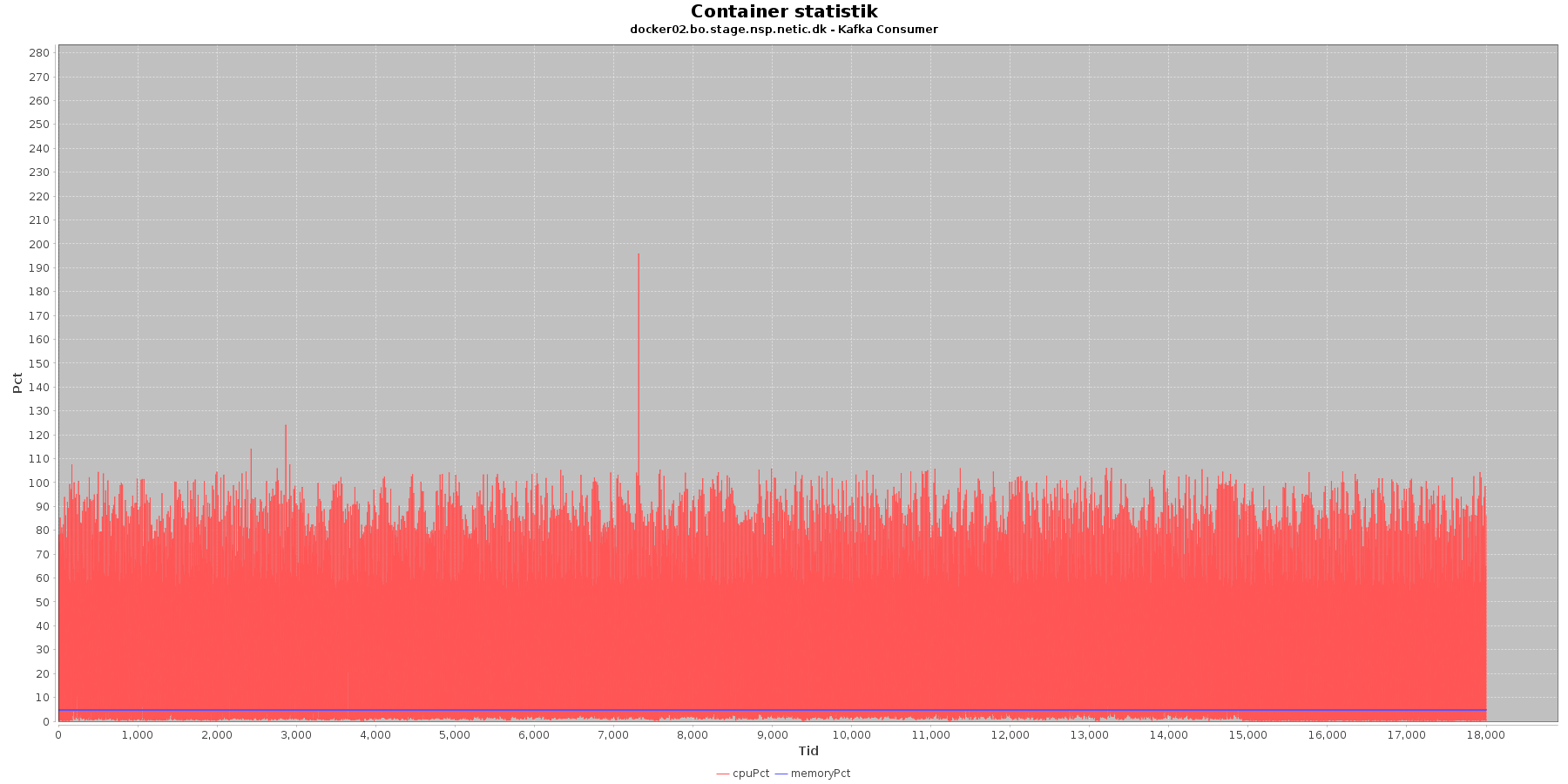
Data serier i grafen er:
- cpuPct (rød): hvor mange procent af hostens cpu containeren bruger
- memoryPct (blå): hvor mange procent af hostens hukommelse containeren bruger
Registration:
- Servicen viser et stabilt forbrug af hukommelse. Den envendte cpu er stigende som servicen bliver presset. Der sker et lille hop i iteration 7 og 8
Kafka-consumer:
- Både forbruget af hukommelse og cpu er stabilt igennem testen.
Netværk:
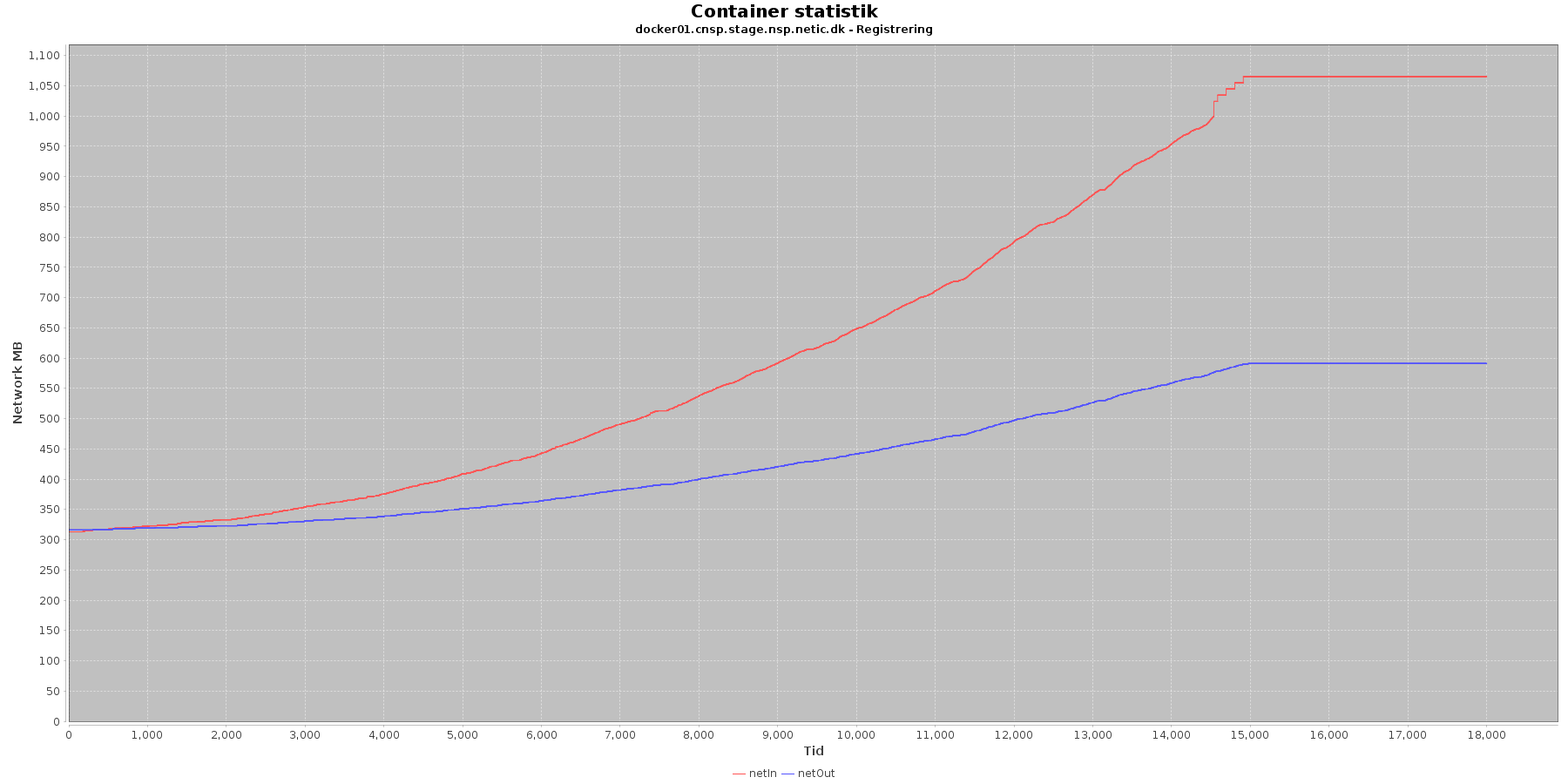
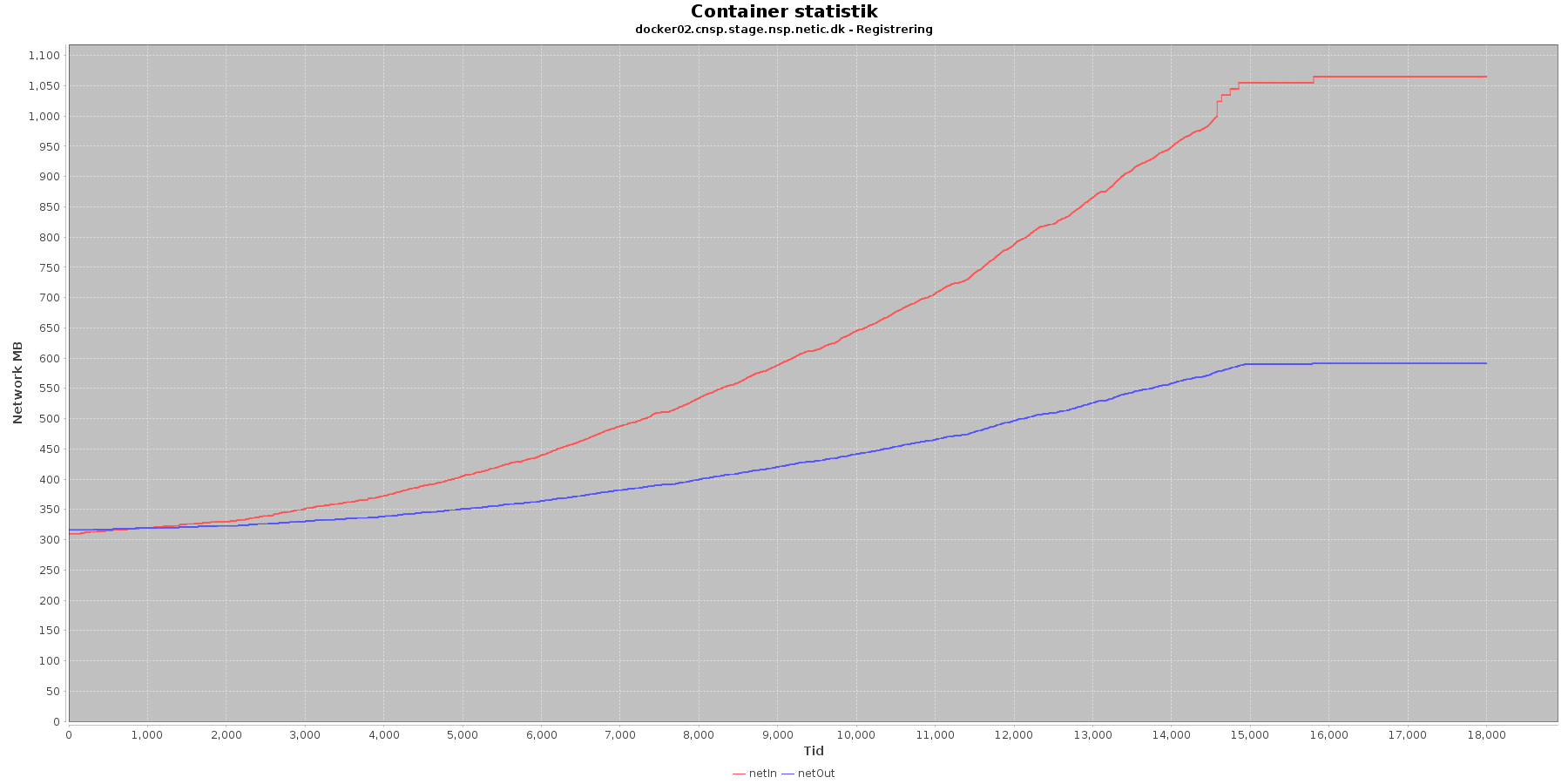
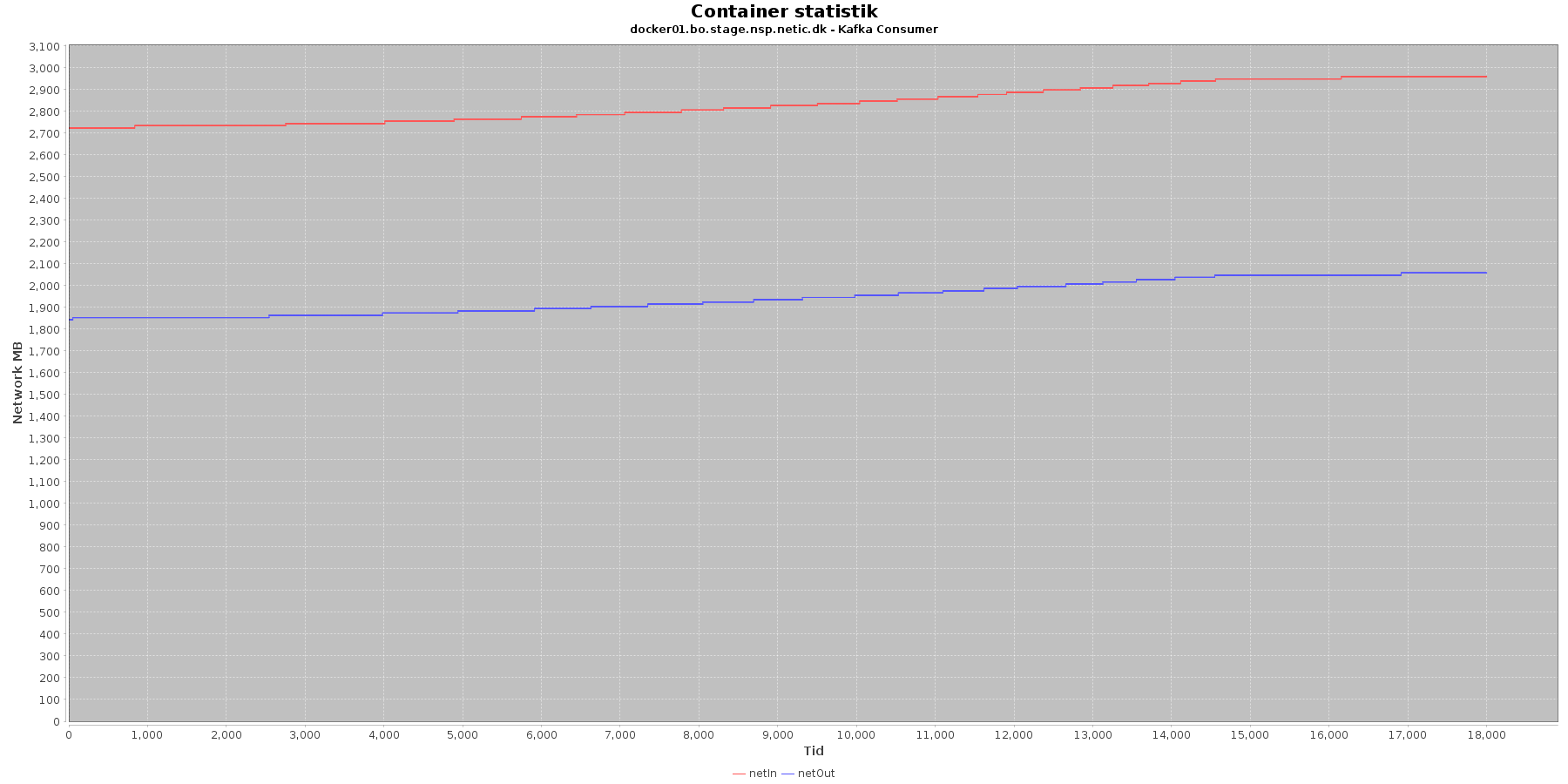
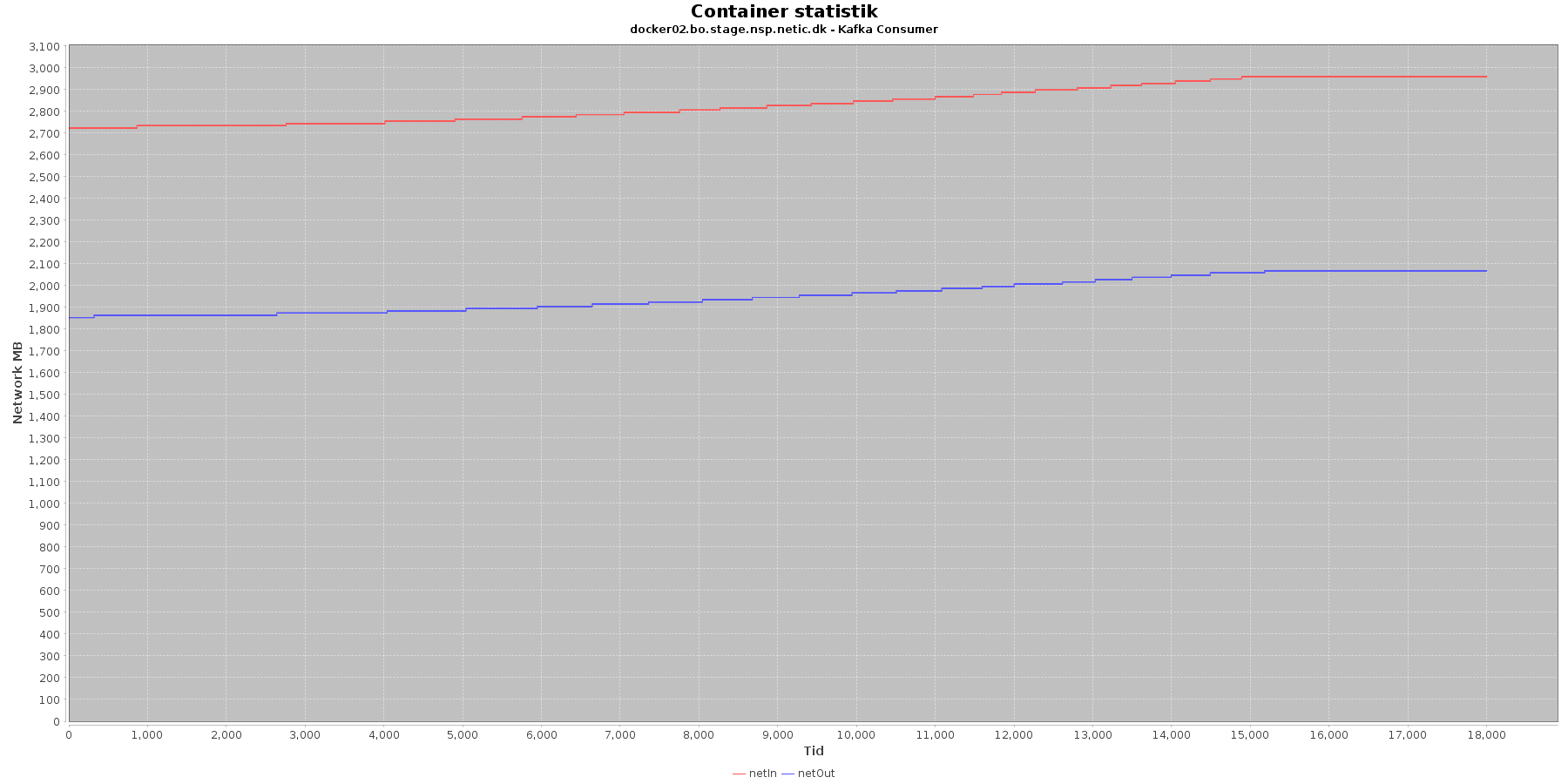
Data serier i grafen er:
- netIn (rød): den mængde data som er modtaget af containeren over netværket
- netOut (blå): den mængde data som er sendt ud af containeren over netværket
Registration:
- De 2 grafer for ind- og udsendt data stiger. Indkommen trafik stiger mest
Kafka-consumer:
- De 2 grafer for ind- og udsendt data stiger svagt og følges ad.
Vurdering
Intet at bemærke.
Kafka consumer lag
Denne log findes for hver applikations server (docker container). Både for registration og kafka-consumer.
For registration fortæller loggen noget om, hvor hurtigt mirrorMaker er til at tage fra på den "lokale" kafka og lægge ting over i den centrale kafka på backoffice. For kafka-consumer fortæller den noget om, hvor hurtigt, der tages fra på den centrale kafka og ned i databasen. Lag er forskellen mellem de data, som bliver produceret (producer) til kafka og forbrugt (consumer) fra kafka køen.
Udtræk omkring registerings komponentens kafka og lag i løbet af testen:
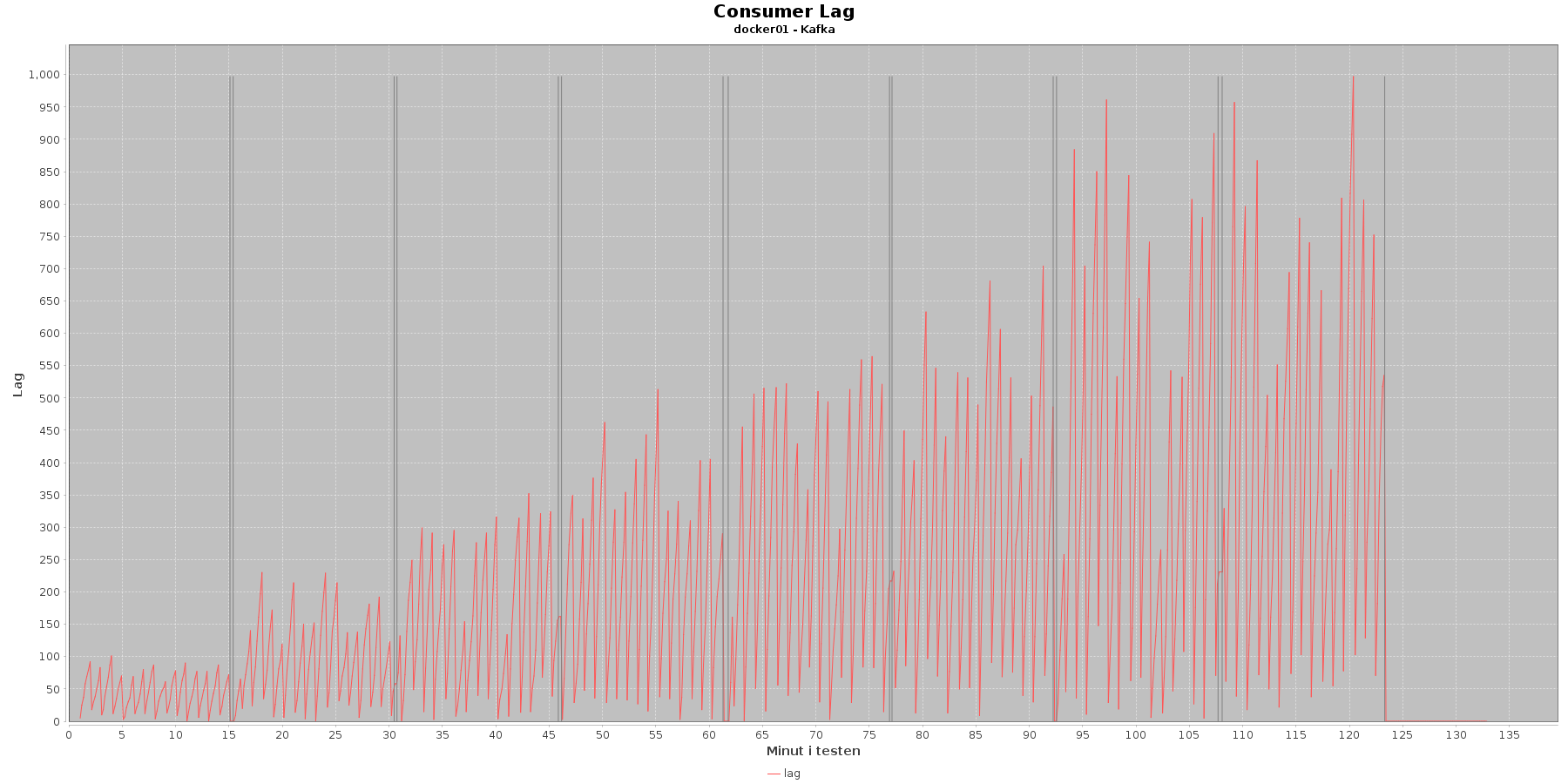
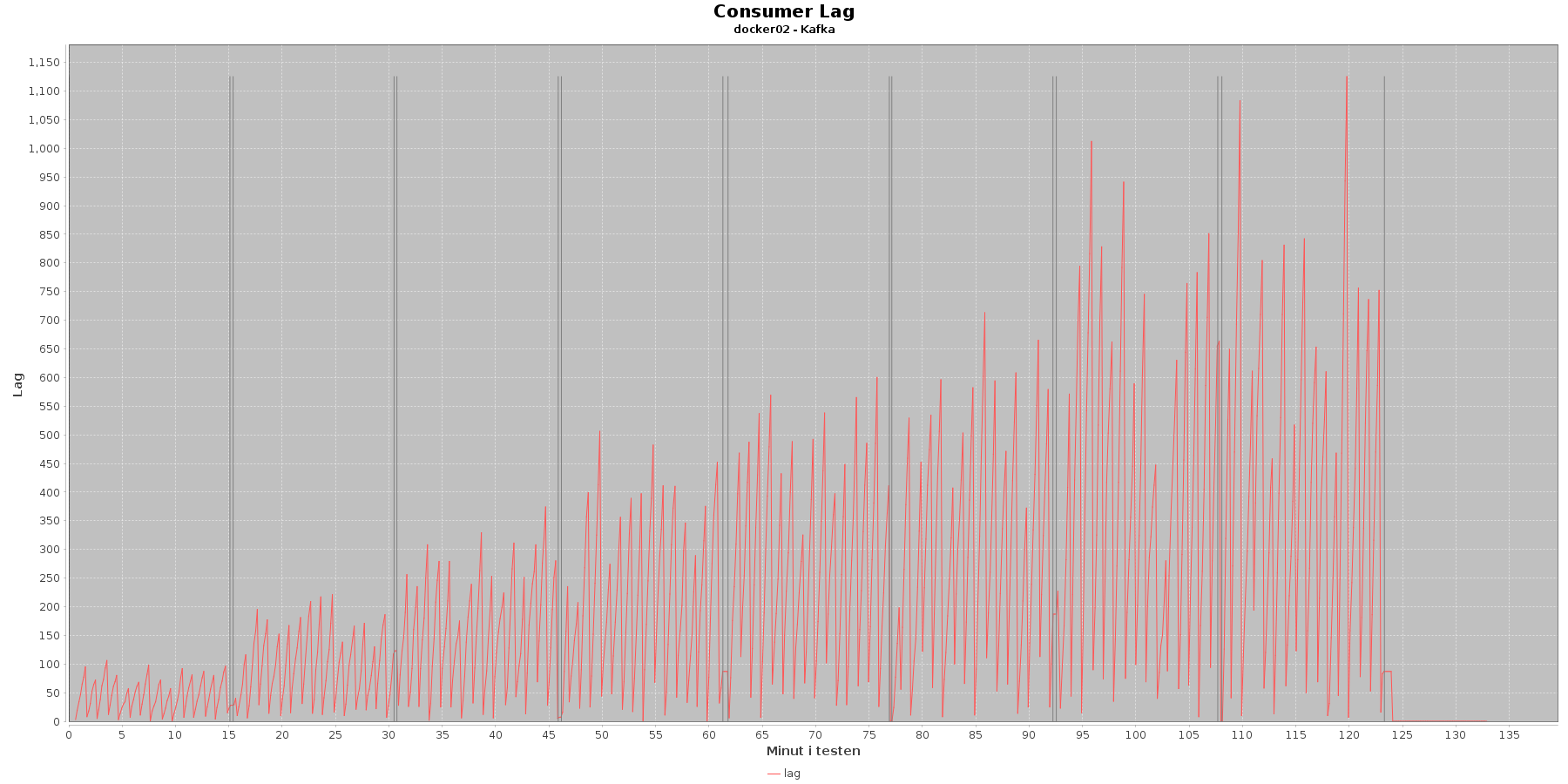
Data serier i grafen er:
- lag (rød): den lag som findes på et givet tidspunkt
Registeringskomponentens kafka har kun en partition, om man kan se at lag stiger som testen skrider frem. Især i de senerer iterationer lag ikke at komme ned inden ny data får den til at stige igen.
Udtræk omkring den centrale kafka og lag i løbet af testen:
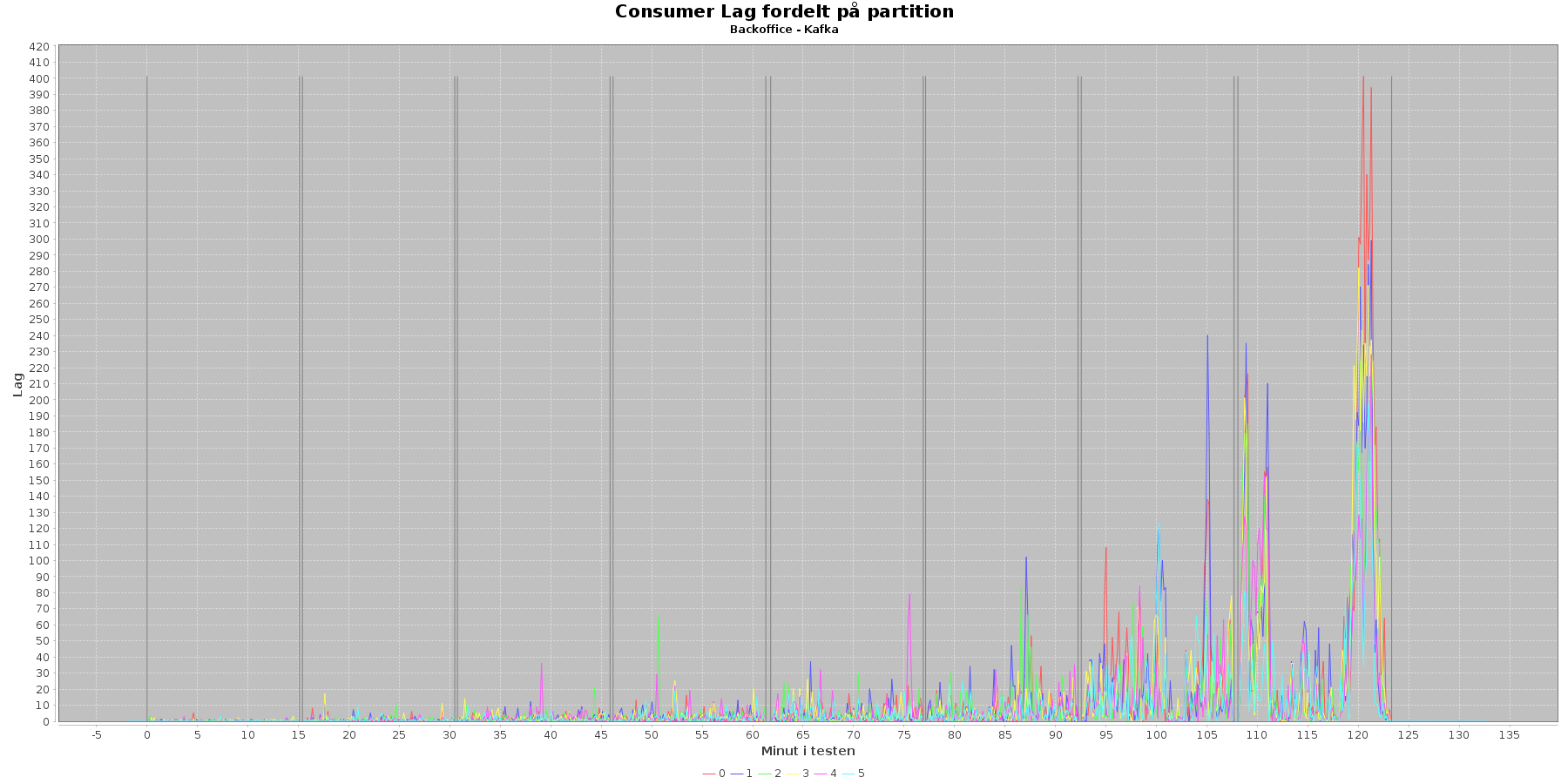
Data serier i grafen er:
- 0 (rød): den lag som findes på et givet tidspunkt for partition 0
- 1 (blå): den lag som findes på et givet tidspunkt for partition 1
- 2 (grøn): den lag som findes på et givet tidspunkt for partition 2
- 3 (gul): den lag som findes på et givet tidspunkt for partition 3
- 4 (pink): den lag som findes på et givet tidspunkt for partition 4
- 5 (tyrkis): den lag som findes på et givet tidspunkt for partition 5
Den centrale kafka har 6 partitioner, og man kan se, at lag stiger som testen skrider frem.
Vurdering
Både registrering komponentens kafka og den centrale kafka har det bedst før iteration 7. Herefter kan læsningen ikke rigtig følge med input. Registreringskomponentens kafka er den, som har de største peaks inden iteration 7, og kunne gøres mere effektiv, ved at tilføje flere partitioner til den ene, den har nu.
Konklusion
Efter at have analyseres data fra performance testen kan følgende trækkes frem:
- Max throughput på testen er 52,96 kald per sekund, den kører sundets ved et throughput på 37,73 kald per sekund
- Svartid for servicen:
Kravet er 95% skal være under 6,5 sekund og 98 % under 15,5 sekund. Resultatet viste 99,5 % lå under både 6,5 og 15,5 sekund. - Cpu status: cpu forbruget stiger lidt over test perioden, som registration servicen presses mere. Dog kun kortvarigt.
- io på netværk: stiger over tid, hvilket er forventet
- Hukommelses forbrug: servicen håndterer brug af hukommelse fint
- Garbage collection: servicen kører jævnligt garbage collection og dermed stiger hukommelses forbruget ikke over tid. Dette er et tegn på, at vi ikke har memory leaks.
- Kafka Consumer Lag: når iteration 7 og 8 viser alle 3 kafka instanser tegn på at lag stiger end del
Oprindeligt var det planlagt, at der skulle være kørt 2 applikationer med registration komponenten. Istedet er testen kørt med 4 applikationer, hvorfor man kan forvente at servicen i testen, får et højere throughput isoleret set på en given iteration, og belastningen på den enkelte applikation lavere end, hvis det samme throughput skulle have været udført at 2.
Når det er sagt, kører der i produktion 18 registrerings komponenter fordelt på dNSP og cNSP, så her vil maskinkraften være højere end i det anvendte test setup.
Kafka-consumer komponenten har arbejdet med data, produceret fra 4 applikationer og er derfor blevet mere belastet end oprindeligt planlagt.
Ser man på graferne over de forskellige iterationer, er iteration 6 er den sidste, som er helt fin: Herefter stiger svartider og resource forbruget de forskellige steder.
Iteration 6 har 37,73 kald per sekund. Dette bliver til ca. 23 mio kald på en uge. Det er hvad den centrale kafka-consumer håndterer uden at vise tegn på problemer. Og man må forvente at 18 registreringskomponenter i produktion vil kunne følge med her, når de 4 i testen kunne.