INDHOLD
Beskrivelse
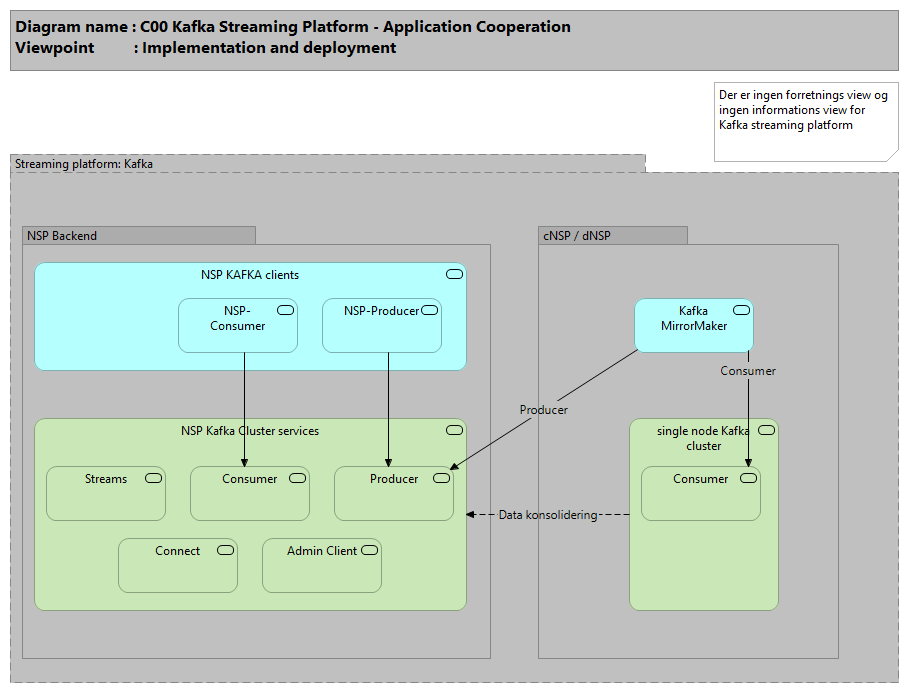
NSP har et midlewarelayer som skal anvendes når en komponent ønsker at bruge Kafka.NSP Kafka Clients skal anvendes af alle på samme måde som Kafka Java Clients bortset fra at man anvender NSP versioner af KafkaProducer og KafkaConsumer klasserne.
Kafka er blevet indført på NSP primært for at tilbyde en måde at samle data fra NSP noderne (dNSP og cNSP) ind på NSP Backend (Der hvor f.eks. stamdata i dag bliver til). Dette er tydelig i den måde Kafka er sat op på de forskellige NSP noder. På hver dNSP søjle og hver cNSP søjle er der opsat en single-node Kafka instans hvorimod der på NSP Backend er opsat et rigtig Kafka Cluster med replikering og disaster recovery. Data lagt på udvalgte topics på single-node instanserne vil automatisk blive konsolideret ind på NSP Backend hvor en komponent vil kunne modtage dette.
Ved brug af Kafka MirrorMaker replikeres alle beskeder fra NSP noder ind i det centrale cluster. Herfra kan applikationer abonnere på udvalgte topics og derved få beskeder fra alle NSP noder.
MirrorMaker er et simpelt program der melder sig som consumer på et Kafka cluster og som producer på et andet Kafka cluster. MirrorMaker kan konfigureres med et regulært udtryk for hvilke topics der skal replikeres, det anbefales derfor at der laves en namingconvention i husreglerne, som tydeliggør at et topic skal replikeres.
Desuden benyttes Kafka som streaming platform, bl.a. til National Advisering Service (NAS2).
Support ansvarlig: Arosii
NSP, Kafka leverancebeskrivelse: Kafka, samt Den Gode Brug af Kafka
Forretningsanvendelse
Der er ingen forretningsbeskrivelse.
Applikationsbeskrivelse
A streaming platform has three key capabilities:
- Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
- Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
Kafka is generally used for two broad classes of applications:
- Building real-time streaming data pipelines that reliably get data between systems or applications
- Building real-time streaming applications that transform or react to the streams of data
Kafka includes five core apis:
1) The Producer API allows applications to send streams of data to topics in the Kafka cluster.
2) The Consumer API allows applications to read streams of data from topics in the Kafka cluster.
3) The Streams API allows transforming streams of data from input topics to output topics.
4) The Connect API allows implementing connectors that continually pull from some source system or application into Kafka or push from Kafka into some sink system or application.
5) The AdminClient API allows managing and inspecting topics, brokers, and other Kafka objects.
Any message queue that allows publishing messages decoupled from consuming them is effectively acting as a storage system for the in-flight messages. What is different about Kafka is that it is a very good storage system.
Data written to Kafka is written to disk and replicated for fault-tolerance. Kafka allows producers to wait on acknowledgement so that a write isn't considered complete until it is fully replicated and guaranteed to persist even if the server written to fails.
The disk structures Kafka uses scale well—Kafka will perform the same whether you have 50 KB or 50 TB of persistent data on the server.
As a result of taking storage seriously and allowing the clients to control their read position, you can think of Kafka as a kind of special purpose distributed filesystem dedicated to high-performance, low-latency commit log storage, replication, and propagation.
Datastruktur
Der er ingen databeskrivelse.