Dette dokument beskriver brugen af Kafka på NSP samt hvilke krav der stilles for at en komponent kan få adgang til Kafka. Det forventes at læseren har forgående kendskab til NSP og har erfaring med Kafka integrationer.
Kafka på NSP
Kafka er blevet indført på NSP primært for at tilbyde en måde at samle data fra NSP noderne (dNSP og cNSP) ind på NSP Backoffice (Der hvor f.eks. stamdata i dag bliver til). Dette er tydelig i den måde Kafka er sat op på de forskellige NSP noder. På hver dNSP søjle og hver cNSP søjle er der opsat en single-node Kafka instans hvorimod der på NSP Backoffice er opsat et rigtig Kafka Cluster med replikering og disaster recovery. Data lagt på udvalgte topics på single-node instanserne vil automatisk blive konsolideret ind på NSP Backoffice hvor en komponent vil kunne modtage dette.
Husregler
Kafka skal, ligesom databaserne på NSP, bruges af flere komponenter, det er derfor vigtigt at alle husregler overholdes, så to komponenter ikke giver problemer for hinanden. Kafka skal betragtes på samme måde som databasen, dvs komponenter skal f.eks. kunne reconnecte til Kafka og komponentens status tjek skal indeholde detaljer omkring forbindelsen til Kafka.
Arkitektur diagram
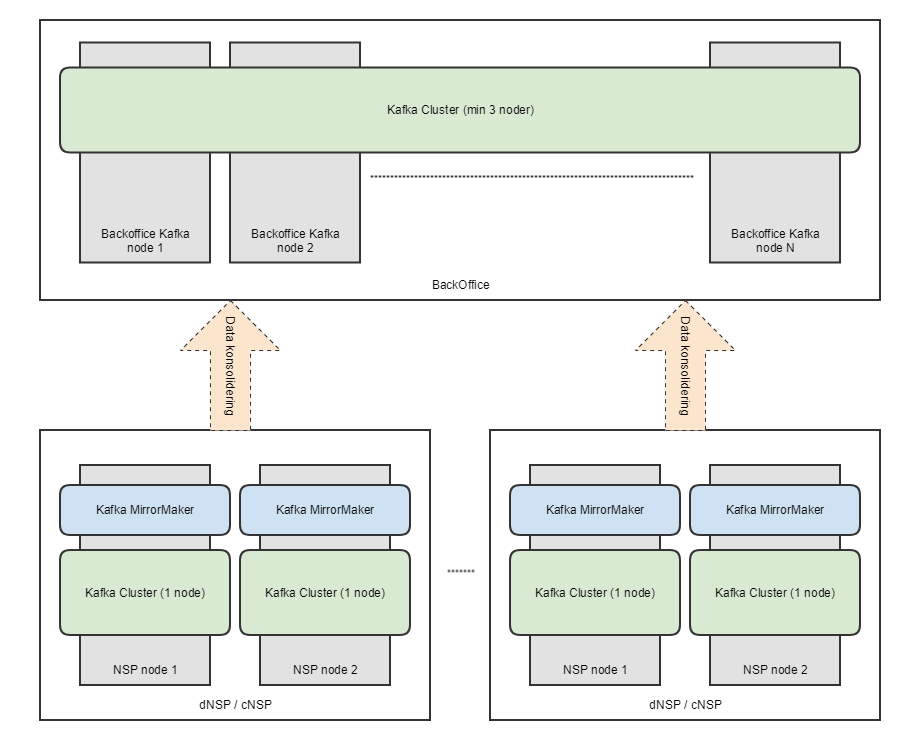
NSP Kafka API
NSP har et midlewarelayer som skal anvendes når en komponent ønsker at bruge Kafka. I det følgende gennemgåes dette.
NSP Kafka Clients
Ligesom Kafka Java Clients findes et NSP Kafka Clients bibliotek som skal anvendes på NSP. Biblioteket findes i NSP Nexus og defineres i projektes Maven fil på følgende måde:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>dk.sds.nsp.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.1.0</version>
<scope>provided</scope>
</dependency>
Vær opmærsom på at de to dependencies defineres med scope provided. Dette skyldes at begge biblioteker er tilgængelige på en NSP platform som Wildfly Moduler, derfor skal jboss-deployment-structure.xml også indeholde følgende:
<jboss-deployment-structure xmlns="urn:jboss:deployment-structure:1.2">
<deployment>
<exclude-subsystems>
<subsystem name="logging"/>
</exclude-subsystems>
<dependencies>
<module name="org.apache.kafka.clients"/>
<module name="dk.sds.nsp.kafka.clients"/>
</dependencies>
</deployment>
</jboss-deployment-structure>
NSP Kafka Clients anvendes på samme måde som Kafka Java Clients bortset fra at man anvender NSP versioner af KafkaProducer og KafkaConsumer klasserne:
producer = new NSPKafkaProducer<>(kafkaProperties); consumer = new NSPKafkaConsumer<>(kafkaProperties)
Ydermere er antallet af properties der skal sættes udvidet med et antal NSP specifikke properties defineret i klasserne NSPProducerConfig og NSPConsumerConfig. Disse gennemgåes i afsnittet Eksempler
Når NSP Kafka Clients anvendes i et miljø der ikke er et driftet NSP miljø vil følgende log linie blive produceret:
NSP Kafka Producer/Consumer Factory Service not found. Falling back to pure Kafka Producers/Consumers. This MUST NOT happend in a NSP environment
Denne besked skyldes at der på et driftet NSP miljø er placeret en NSP Kafka Provider som rent faktisk står for integrationen til Kafka. I et udviklingsmiljø kan denne besked derfor ignoreres.
NSP Kafka Provider
På NSP er der installeret et Wildfly Module der indeholder den NSP Kafka Provider. Denne wrapper alt adgang til Kafka således at NSP har mulighed for at foretage driftmæssige ændringer uden nye releases af komponenten.
Eksempler
Til denne guide hører der 3 kodeeksempler der viser hvodan man anvender NSP Kafka Clients og integrere med Kafka på NSP. Eksemplerne kan hentes via Subversion på følgende adresse:
Eksemplerne er lavet som et Maven projekt der producere en enkelt WAR fil der kan deployes på en NSP.
Alle eksempler følger samme struktur i forhold til indlæsning af properties (fra Wildfly modul) og opsætning af Kafka properties, så dette gennemgåes i sit eget afsnit.
Eksemplerne er simple og skal ikke repræsentere produktionsklar kode men derimod give indsigt i hvordan NSP ønsker at komponenter skal integrere med Kafka. Af denne grund indeholder eksemplerne f.eks. ikke noget fejlhåndtering mv.
NSP Kafka Examples
ProducerServlet.java
Denne servlet kan kaldes på /nsp-kafka-producer-example/produce og publiserer en enkelt besked til Kafka.
Dette eksempel er relativt simpelt. Servleten lytter på ændringer til ServletContext for at oprette og lukke sin Kafka Producer korrekt og sender blot en enkelt besked per http request. En Kafka Producers send metode er thread safe så dette skalere fint med antallet af request-threads i Wildfly.
ConsumerServlet.java
Denne servlet kan kaldes på /nsp-kafka-consumer-example/consume og forbruger et antal beskeder fra Kafka.
Igen et simpelt eksempel der ligeledes styres lifecykle via ServletContextListener. Forskellen her er dog at en Kafka Consumer ikke er thread-safe og brugen af den derfor sker i en synchronize block. Dette begrænser performance betragteligt og giver derfor kun mening i meget specifikke situationer hvor forbrug af Kafka beskeder sker med lav intensitet.
PooledConsumerServlet.java
Denne servlet kan kaldes på /nsp-kafka-consumer-example/pooled/continue og har en pool der kontinuerligt forbruger beskeder fra Kafka.
Dette eksempel er mere kompleks og viser hvordan man kan lave en baggrunds (batch) kørsel af et antal Kafka Consumers via en tråd-pool. Løsningen matcher den måde baggrundsjob skal opsættes og aktiveres på NSP (En Servlet der kaldes med en curl kommando skeduleret via cron). Ligesom de andre eksempler styres lifecykle via ServletContextListener.
I det følgende gennemgåes de relevante metoder ud fra det overordnede designprincip: Hver gang servletten kaldes stoppes og genstartes et antal ExampleConsumer instanser der alle består af et poll-loop hvor beskeder forbruges fra Kafka.
initConsumers()
Først oprettes en enkelt consumer som bruges til at få detaljer omkring antallet af Partitioner i det brugte Topic. Servletten konfigureres med antallet af noder som den deployes på således at antallet af Kafka Consumers/Tråde pr. node kan udregnes. Herefter oprettes det antal Kafka Consumers og de tegner alle abonnement på det valgte Topic. Til sidst laves en Java Executor Service med en tråd per Kafka Consumer.
closeConsumers()
Først stoppes alle ExampleConsumers og alle Kafka Consumers lukkes ned. Til sidst stoppes Java Executor Servicen.
stopConsumers()
Alle ExampleConsumers bliver bedt om at stoppe når de er færdige med deres nuværende poll-loop, derefter venter request-tråden på at alle Futures fra afvikling af ExampleConsumers har et resultat, dette betyder at alle ExampleConsumers nu er færdige med afvikling af deres call() metode og at Java Executor Service nu er idle.
startConsumers()
Først får alle fremtidige ExampleConsumers besked på at de gerne må køre deres poll-loop. Derefter wrappes alle Kafka Consumers i hver sin instans af ExampleConsumer og denne submittes til Java Executor Service. Dette resultere i et antal Futures som stopConsumers() kan bruge til at afvente afvikling af ExampleConsumers call() metode.
ExampleConsumer#call()
Denne metode kaldes af Java Executor Service og afvikler Kafka Consumer poll-loopet.
Først udregnes hvor lang tid denne iteration maks må køre. Dette gøres for at driften kan disable cron-triggeren og derved få den løbende afvikling til at stoppe automatisk.
Derefter starter selve poll-loopet der løber indtil vi bliver bedt om at stoppe eller tiden er gået.
I poll-loopet kalder vi Kafka Consumerens poll metode og processere resultatet.
Når poll-loopet slutter returnere vi antallet af processerede beskeder.
Konfiguration
Alle eksemplerne opsætter logning, applikations-properties og Kafka-properties på samme måde. Ideen i indlæsningen af properties er at NSP og driften kan ændre på både Kafka Java Clients konfigurationen og NSP Kafka Clients konfigurationen, uden en ny leverance er påkrævet.
Metoden initConfiguration() løber derfor alle properties igennem og gør følgende
- Er der tale om en Kafka Java Clients konfiguration (tjekkes ved unik prefix) fjernes prefixet og propertien tilføjes til Kafka-properties.
- Er der tale om en NSP Kafka Clients konfiguration (tjekkes med kald til NSPKafkaConfig#isNSPProperty) tilføjes propertien til Kafka-properties.
- Er der tale om en kendt applikations konfiguration gemmes værdien i den passende variabel.
Samtidig opsamles alle properties og disse logges således at driften kan se hvordan konfigurationen så ud da komponenten startede.
Anvendelsesaftale
En komponent på NSP må kun benytte Kafka hvis der ligger en godkendt aftale om hvorledes denne anvendelse skal finde sted. Det er derfor projekternes ansvar at indhendte denne godkendelse, hvilket kræver at følgende spørgsmål er besvaret:
- Hvilke Topics skal anvendes og hvad indeholder de.
- Skal data konsolideres på Backoffice.
- Hvad er typerne af Key og Value.
- Hvor mange Partitions skal hver Topic have og hvorfor.
- Hvad skal Replication Factor være for hver Topic og hvorfor.
- Hvor mange beskeder produceres i peak over de næste 5 år.
- Hvor mange beskeder forbruges i peak over de næste 5 år.
- Hvilken Retention Policy skal anvendes.
- Hvad er det forventede diskforbrug over de næste 5 år.
- Hvilke Consumer Groups findes der
Derudover skal projektet også beskrive hvorledes overvågningen af de anvendte Topics skal finde sted:
- Hvor langt bagud må hver Consumer Group være.
- Hvad er det forventede minimum antal beskeder per tidsenhed.
- Hvad er det forventede maximum antal beskeder per tidsenhed.
- Hvor langt bagud må konsolideringen være.