Page History
...
I denne guide vil kommende udviklere af stamdataindlæsere kunne se, hvordan de griber opgaven an, når en ny eller eksisterede stamdataindlæser skal udvikles efter referencearkitekturens principper.
En stor del af den kode som bruges, er fælles for alle stamdata indlæser. Den ligger i et stamdataindlæser fælles bibliotek og danner strukturen for indlæserne. Dette skal gøre det lette for udviklere af nye indlæsere at komme igang, så der kun fokuseres på konkret implementering af indlæser specifik kode.
1.2. Sammenhæng med øvrige dokumenter
...
Læseren forventes at have kendskab til Java softwareudvikling med anvendelse af Maven, WildFly, Flyway, LiquidBase, Docker, og Apache Camel (i det efterfølgende benævnt som Camel).
...
Bemærk at stamdataindlæserene benytter sig af et fælles-modul, der findes her:
- Gammel version: https://svn.nspop.dk/svn/libraries/stamdataindlaeser/trunk
- Ny version: https://git.nspop.dk/scm/lib/stamdata-indlaesere.git
2.1. Krav til software
Krav til applikationsserveren og operativsystemet er de samme som til produktionsmiljøet. De specifikke krav kan ses i https://www.nspop.dk/display/public/web/Husregler+for+udvikling+til+NSP
...
Denne bygger projektet, stopper og fjerner eventuelle gamle docker-containere, bygger nye og starter det igen.
3.2. Continous Integration & Delivery
CI/CD foregår ud fra NSP's vejledninger herom NSP Continuous Integration & Delivery.
Der eksisterer for stamdataindlæsere følgende byg
3.2.1.1. Build
Til hver indlæser oprettes et jenkins-byg, ved navn <indlæser>_Build som bygger koden, kører unittests og bygger det docker-image som danner indlæseren.
De automatiserede tests der implementeres til en Stamdataindlæser, vil ofte være af integrations-lignende natur, idet en sådan løsning nemmest testes ved at køre filer med forskellige karakteristika igennem det etablerede flow.
Dette, i kombination med brugen af TestContainers til MariaDB og SFTP servere kan gøre det tidskrævende at udføre hele testsuiten.
For at imødegå frustrationer som følge af tidskrævende tests, opfordres udviklere til
- under udvikling af features at anvende ens IDE til at køre de aktuelle tests der er forbundet med den aktuelle feature i stedet for at køre f.eks
mvn clean packagefor at teste koden - ved behov for kørsel af test fra kommandolinjer, at køre de specifikke tests der er behov for med
mvn -Dtest=<test-klasse> - ved release af koden ved brug af Maven Release-plugin at bruge kommandoen
mvn release:prepare -Darguments=-DskipTests
3.2. Continous Integration & Delivery
CI/CD foregår ud fra NSP's vejledninger herom NSP Continuous Integration & Delivery.
Der eksisterer for stamdataindlæsere følgende byg
3.2.1.1. Build
Til hver indlæser oprettes et jenkins-byg, ved navn <indlæser>_Build som bygger koden, kører unittests og bygger det docker-image som danner indlæseren.
Dette byg bestemmes ud fra den Jenkinsfile der ligger i projektet (se fx. https://svn.Dette byg bestemmes ud fra den Jenkinsfile der ligger i projektet (se fx. https://svn.nspop.dk/svn/importers/yderindlaeser/trunk/Jenkinsfile for yderindlæseren).
...
Filen med data indlæses af Camel fra den lokale folder hvori modtagelsen har placeret den.
4.4. Validering af datasæt
Hvis data for indlæseren ikke kan håndtere samtidig indlæsning af data fra flere filer, kan der i dette trin indsættes en blokade, der sikrer, at der kun er én aktiv indlæsning igang på et givet tidspunkt.
4.4. Validering af datasæt
På en modtaget fil gennemføres der På en modtaget fil gennemføres der et antal valideringer, før data parses og splittes til events. Valideringen på dette trin sikrer, at når filen efterfølgende håndteres, så er den som udgangspunkt korrekt i henhold til det aftalte.
...
Denne tilgang sikrer, at aftagere af data kan forvente, at når de modtager en mængde af data, så er den konsistent, så de ikke selv skal tage højde for dette.
Til beskrivelsen af eksterne events anvender vi Apache Avro som også er forberedt på evt. senere levering af data via data-strømme, f.eks. via Apache Kafka. Til den interne håndtering af event anvendes simple POJOs.
Se eventuelt referencearkitekturen for stamdataindlæsere, der beskriver fordelene ved at anvende events i større detaljer.
Opret implicitte slette events
Efter parsning undersøges ved full load om der er data i databasen, som ikke findes i filen. Disse oprettes som slette events.
4.6. Validering af events
...
Hvis valideringen af en event fejler, så logges det til databasen og applikationsloggen, men håndteringen af de øvrige events fortsætter. Dermed sikrer vi, at vi indlæser så mange events som muligt, for at tilgodese aftageren, samtidig med at vi tilbageholder fejlbehæftede data.
Dele af denne validering foretages/sikres via det anvendte skal sikre at der ikke senere opstår problemer når Avro skema udfyldes.
4.7. Berigelse af events med metadata
...
Disse data er f.eks. identifikation af kildefilen og en entitets placering i kildefilen, og de har til formål at højne kvaliteten i efterfølgende logninger ved fejl, så driftssupporten nemt kan finde frem til årsagen af sådanne fejl.
Slette filter
De tidligere oprettede slette events fjernes fra det flow, der sender events eksternt.
Berig event før persistering
Her kan justeringer på en event udføres. F.eks. kan der tilføjes slette entiteter på events. Hvis det modtagne datasæt ikke indholder en given subentitet, som findes i databasen skal den slettes senere i flowet.
4.8. Dublet filter
Selvom stamdataindlæseren modtager et fuldt dump af data, ønsker aftagerne kun at få reelle ændringer.
...
Begge kanaler leverer de samme data, men der kan være historiske og/eller tekniske omstændigheder der der gør den ene kanal mere velegnet end den anden.
...
- PREFIX_DataSet - indeholder en række for hver modtagen fil. Den UUID som identificerer datasættet, knyttes også til forretningsdata, så det er entydigt hvilken fil, der sidst har påvirket en given række af forretningsdata.
- PREFIX_DataSetLog - indeholder evt. fejl der er registreret under behandling af den pågældende fil
- PREFIX_RegisterStatus - indeholder den akkumulerede status for det pågældende register
- PREFIX_RegisterFejl - indeholder et registers fejlede entiteter og er linket til den senest relaterede række i PREFIX_DataSetLog.
Hvor PREFIX er det stamdataindlæser Hvor PREFIX er det stamdataindlæser specifikke prefix som anvendes i navngivningen af tabeller for en given stamdataindlæser, f.eks. "YDS" for Yderindlæseren.
...
|
5. Beskrivelse af kildekodens struktur og design
Kildekoden er struktureret i henhold til systemdesignet, der er bygget op omkring udførelsen af en pipeline.
Der er defineret et stamdataindlæser-bibliotek som indeholder fælleskomponenter der anvendes på tværs af stamdataindlæsere.
Koden for både fælleskomponenter og stamdataindlæsere er struktureret som et standard Maven projekt med en tilhørende pom.xml fil der definerer afhængigheder til 3. parts biblioteker.
5.1. Kodestruktur for fælleskomponenter
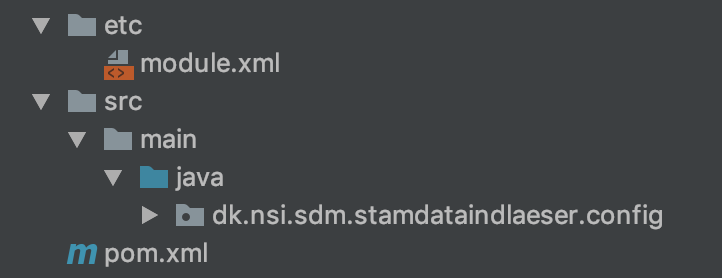
Strukturen for fælleskomponenterne består af
|
5. Beskrivelse af kildekodens struktur og design
Kildekoden er struktureret i henhold til systemdesignet, der er bygget op omkring udførelsen af en pipeline.
Der er defineret et stamdataindlæser-bibliotek som indeholder fælleskomponenter der anvendes på tværs af stamdataindlæsere. Dette er lavet ud fra en betragtning om, at de enkelte indlæsere ikke skal kende til Camel og ruter som sådan. Men alene beskæftige sig med indlæser specifikke detaljer.
Koden for både fælleskomponenter og stamdataindlæsere er struktureret som et standard Maven projekt med en tilhørende pom.xml fil der definerer afhængigheder til 3. parts biblioteker.
5.1. Kodestruktur for fælleskomponenter

Strukturen for fælleskomponenterne består af
java- indeholder koden for fælleskomponenteretc- indeholder modul definition af biblioteketpom.xml- indeholder definition af afhængigheder til 3. parts komponenter
Java delen består af følgende pakker:
- config indeholder konfiguration af databaser, logning og andet relevant
- database.dao indeholder klasser til database adgang
- database.model indeholder den model som dao klasserne arbejder med
- monitoring indeholder logik til status servicen
- route indeholder default ruter, som indlæserne kan anvende til at bygge deres ruter med
- route.components indeholder de klasser default ruterne bruger, for at pakke camel/rute relateret logik væk fra yder indlæserne
- route.model indeholder modellen, der generaliserer de events, som default ruterne og deres komponenter arbejder på.
- service indeholder interfaces der skal anvendes af de enkelte indlæsere
- utils indeholder pt. funktionalitet til at tjekke ftp forbindelser, men har til formål at indeholde diverse utils klasser.
etc- indeholder modul definition af biblioteketjava- indeholder koden for fælleskomponenterpom.xml- indeholder definition af afhængigheder til 3. parts komponenter
5.2. Kodestruktur for stamdataindlæser
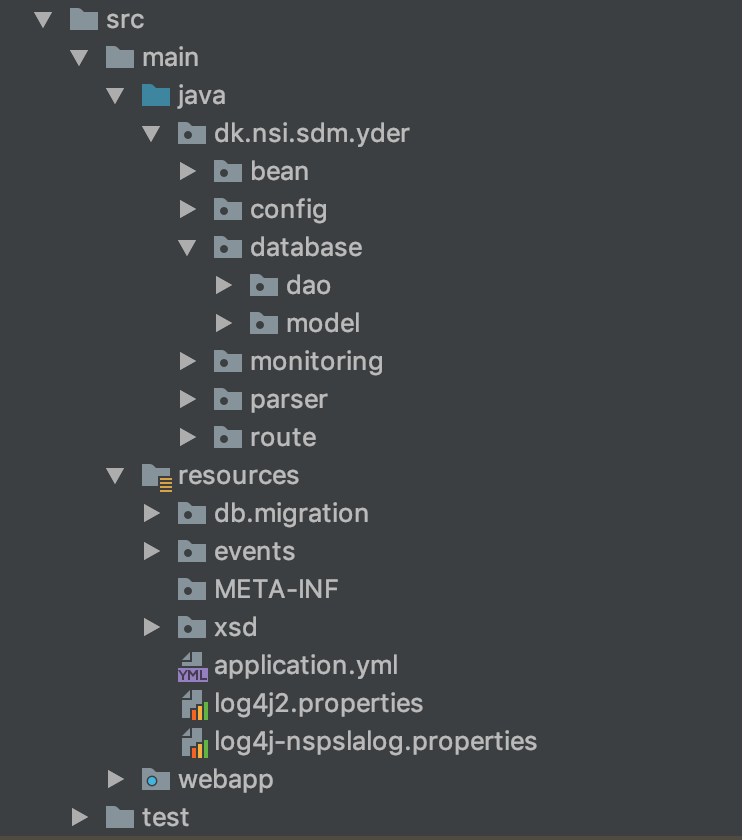

Her er strukturen projektets struktur eksemplificeret fra Yderindlæseren hvor hvor der er følgende moduler/foldere:
- compose folder der indeholder docker-compose filer til test og relateret configuration
- yder-event folder, som har ansvaret for at generere source kode/klasser ud fra det aktuelle avro format til brug for de andre moduler
- yder-integrationtest, der indeholder integrations testen for yder indlæseren. Herunder de test filer, der anvendes i testen
- yder-service, der indeholder selve yder indlæser logik
- yder-testreport, der sammenfatter test rapporter fra de andre moduler til een.
- yder-war, bygger runtime filen og indeholder den Dockerfile, der anvendes til at skabe docker containeren.

Her er det essentielle modul, hvor selve indlæser logikken findes, eksemplificeret fra Yderindlæseren med følgende pakker:
- config indeholder konfiguration af database og rute.
- database.dao indeholder klasser til database adgang
- database.model indeholder den model som dao klasserne arbejder med
- route indeholder opsæt af yder indlæseren rute. Den anvender i høj grad default ruten fra fælles biblioteket.
- route.components indeholder yder specfikke klasser, der anvendes af componets.impl
- route.components.field indeholder yder felt relateret logik.
- route.model indeholder de interne POJOs der arbejdes på som Events. Klassen YderIndlaeserEvent "starter" træ-strukturen, og den implementerer IndlaeserEvent fra fælles biblioteket.
- service indeholder de servlet indlæseren stiller til rådighed.
- service.impl indeholder implementeringen af fælles bibliotekes interfaces
beanindeholder koden for de komponenter der orkestreres af pipelinenconfigindeholder indlæsning og udstilling af eksterne konfigurations-variabledatabaseindeholder model og database adgang for entiteterdaoindeholder database adgang til at læse, skrive og opdatere entitetermodelindeholder java klasser til at repræsenterer de entiteter som DAO klasserne håndterer
monitoring- indeholder koden der anvendes af status servlet til monitorering af stamdataindlæserens tilstand.parser- indeholder hjælpeklasser for parsning af stamdata filer, for Yderindlæseren er det SAX parser event handlere.route- indeholder den grundliggende opsætning af Camel router som orkestrerer udførelsen af pipelinenresources- indeholder bl.a. konfiguration af applikations- og NSP-logfilerdb-migration- indeholder sql scripts, der udføres af flyway til at vedligeholde og migrere databasenevents- indeholder specifikation af AVRO skema på JSON format - specifikationen beskriver struktur og indhold af de events, der flyder gennem pipelinenxsd- indeholder skema for Yderindlæserens stamdatafil og bruges under validering af en modtagen fil
webapp- indeholder visningsdelen for status-servlettest- indeholder unit- og integrations-tests
5.3. Versionskontrol
Kildekoden for hhv. fælles komponenter og stamdataindlæsere ligger i NSP'ens Subversion (SVN) installation eller GIT. For en given stamdataindlæser opretter NSP driften en placering som udvikleren af den givne stamdataindlæser kan anvende.
For fælles komponenter ligger koden i
- gammel version: https://svn.nspop.dk/svn/libraries/stamdataindlaeser/trunk/
- ny version: https://git.nspop.dk/scm/lib/stamdata-indlaesere.git
For Yderindlæseren ligger koden i https://svn.nspop.dk/svn/importers/yderindlaeser/trunk/ og andre stamdataindlæsere vil blive placeret i foldere på tilsvarende vis under https://svn.nspop.dk/svn/importers/
...
Til vedligehold af databasen anvendes Flyway LiquidBase eller Flyway (ældre indlæsere), som sikrer en kontrolleret afvikling af database migreringsscripts - dvs. LiquidBase/Flyway holder styr på, hvilke migreringsscripts der er afviklet, og hvilke der mangler at blive afviklet, når stamdataindlæseren startes.
LiquidBase/Flyway indeholder selv en tabel, som holder styr på hvilke scripts, der er afviklet.
For at undgå sammenblanding mellem stamdataindlæsere, anvendes det angivne prefix også ved initialisering og afvikling af Flyway. Hvordan prefixet anvendes kan ses i denne kodestump fra Yderindlæseren:
...
Det overordnede setup er beskrevet i NSP Continuous Integration & Delivery, og det er herved muligt at starte en specifik stamdataindlæser med lokalt kørende database samt stamdatakopiregisterservice (SKRS); således at hele flowet kan afprøves lokalt.
6.1. Unittest
Der anvendes unittests i alle stamdataindlæsere ved brug af JUnit.
Stamdataindlæseres unittest-setup er specielt på to punkter, i det der benyttes mocks for at kunne teste Camel, samt at der benyttes TestContainers, således at unittests kan ramme en rigtig lokalt kørende mariadb database kørende i docker (https://www.testcontainers.org).
Unittests kan køres ved at eksekvere
...
); således at hele flowet kan afprøves lokalt.
6.1. Unittest
Der anvendes unittests i alle stamdataindlæsere ved brug af JUnit.
Unittests kan køres ved at eksekvere
|
Der findes i fælles biblioteket en pakke (stamdataindlaeser-test), som med fordel kan anvendes når man laver unit test for den enkelt indlæser. Pt (sommer 2023) kan anvendelse af dette ses i yder indlæseren).
Indlæseren arbejder i noget af ruten på et batch af events. I forbindelse med unit testen angives dette i klassen YderRouteBuilderTestSetup i variablen Iterable<Object[]> data(). Denne er default sat til en værdi, for at holde test tiden nede. Men inden release bør man køre en test med de udkommenterede værdier, sådan at koden bliver udfordret i forhold til denne værdi. Det er konstateret, at den kan have indflydelse i, om noget kode virker eller ej.)
6.1.1.
...
Test i Camel
I det Camel kører asynkront, er det nødvendigt for unittests at vide, hvornår Camel er færdig med at indlæse en fil, hvis testen skal vide, hvornår den kan kontrollere, om det gik som forventet. Dette gøres i stamdataindlæsere som Yderindlæseren, i klassen BaseMockTest, hvor Camel-routen mockes ved at tilføje et sidste MockEndpoint, som en test kan vente påindlæseren, ved i en test klasse at holde øje med confirm filerne (.done og failure) og frigive en Semaphore (routeHandshake) der først frigives når de forventede filer er fundne.
Hvis ikke der benyttes mocks til dette trick i Camel kan man være nødsaget til at indsætte waits, hvilket gør testeksekveringen langsommere, samt kan være forskellige afhængig af eksekveringsmaskinens computerkraft.
6.1.2. Unittests med en kørende MariaDb
I ældre stamdata indæsere:
I det stamdataindlæsere selv migrerer databaseskemaet (via Flyway), samt i overensstemmelse med NSP husregler ikke benytter ORM som Hibernate, er det blevet godkendt at unittests selv starter en mariadb database via docker, og tester ved brug af den.
TestContainers er et java bibliotek som tillader programmatisk instruering af docker starter op, og herved starter en ny tom mariadb container op, som applikationen kan køre databasemigreringer mod, og herefter benytte i alle unittests. For eksempel se https://svn.nspop.dk/svn/importers/yderindlaeser/trunk/src/test/java/dk/nsi/sdm/yder/BaseTest.java klassen i yderindlæser-projektet.databasemigreringer mod, og herefter benytte i alle unittests.
For nyere stamdata indlæsere:
I det indlæseren selv migrerer databaseskemaet (via Liquibase), samt i overensstemmelse med NSP husregler ikke benytter ORM som Hibernate) anvender unit testene in memory databasen H2
6.2. Integrationstest
Til hver indlæser foreslås det, at der laves specielle automatiserede tests, som kan køres som integrationstests.
Disse integrationstests giver mulighed for at teste hele indlæseren med de afhængigheder den vil benytte sig af, når den kører i produktion, som fx. SKRS (registerkopiservice) eller SYES (enkeltopslagsservicen).
I ældre version af indlæserene er Unittests til integrationstests markeres i koden med en custom testkategori og projektet sættes op så disse kan køres ved at køre (mvn test -Pintegrationtest). Dette er ikke tilfældet i de reviderede.
Disse tests vil så kræve at indlæseren samt de korrekte afhængigheder allerede kører, hvilket typisk laves via docker-compose. For yderindlæseren er compose/test/docker-compose.yml lavet således, at denne starter yderindlæser, database samt SKRS i en opsætning som kan testes via integrationstestene. Så man kan starte denne docker-compose fil lokalt (docker-compose up) og så ved siden af køre integrationstestene, som vil lægge en fil op, vente på at den bliver indlæst, og herefter se efter i både database samt SKRS om indlæsningerne er gået godt.
...
- Kopier hele projektet (trunk) til ny mappe, og gå igennem og omdøb navne (fx. yder til cpr osv.)
- Ret skema til for både databasemigreringer, samt avro-skema (som genkompileres) og ret modeller til.
- Tilpas parser implementeringen som ligger i
bean, valider og anden implementeringen der gør brug af disse POJO's så den passer til de data der modtages - Gå igennem, udkommenter og fjern indtil en rudimentær version kan kompilere og teste.
...