Page History
...
Der er defineret et stamdataindlæser-bibliotek som indeholder fælleskomponenter der anvendes på tværs af stamdataindlæsere. Dette er lavet ud fra en betragtning om, at de enkelte indlæsere ikke skal kende til Camel og ruter som sådan. Men alene beskæftige sig med indlæser specifikke detaljer.
Koden for både fælleskomponenter og stamdataindlæsere er struktureret som et standard Maven projekt med en tilhørende pom.xml fil der definerer afhængigheder til 3. parts biblioteker.
5.1. Kodestruktur for fælleskomponenter
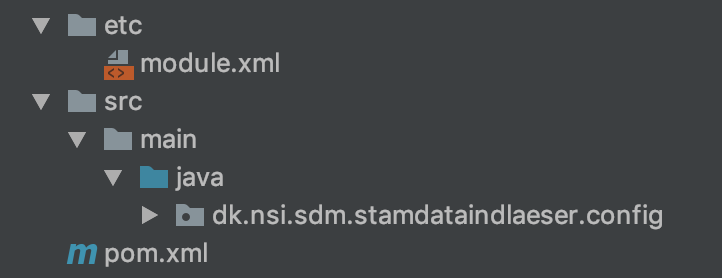

Strukturen for fælleskomponenterne består af
java- indeholder koden for fælleskomponenteretc- indeholder modul definition af biblioteketjava- indeholder koden for fælleskomponenterpom.xml- indeholder definition af afhængigheder til 3. parts komponenter
5.2. Kodestruktur for stamdataindlæser
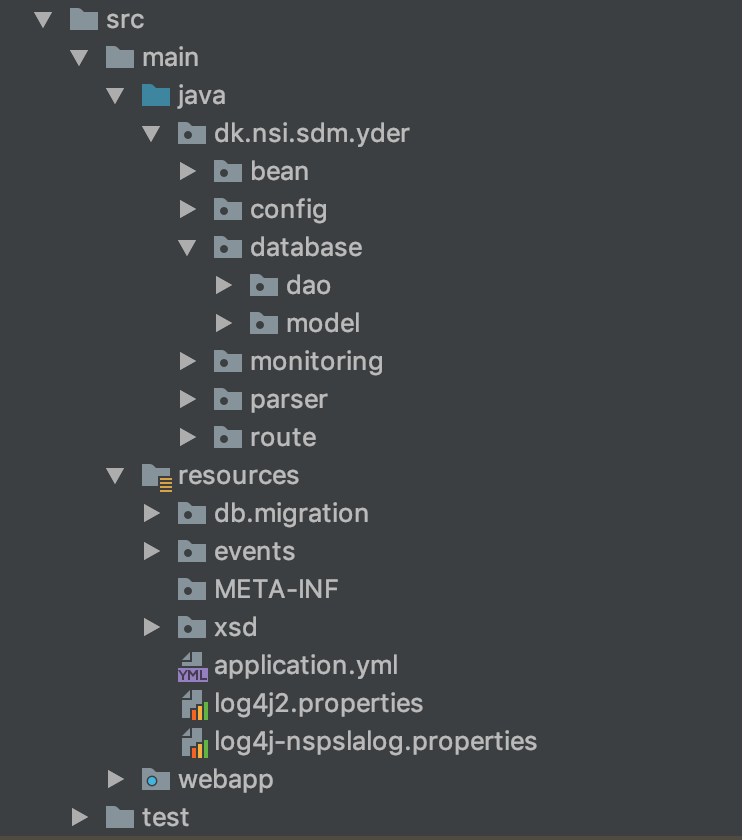
Her er strukturen eksemplificeret fra Yderindlæseren hvor
beanindeholder koden for de komponenter der orkestreres af pipelinenconfigindeholder indlæsning og udstilling af eksterne konfigurations-variabledatabaseindeholder model og database adgang for entiteterdaoindeholder database adgang til at læse, skrive og opdatere entitetermodelindeholder java klasser til at repræsenterer de entiteter som DAO klasserne håndterer
monitoring- indeholder koden der anvendes af status servlet til monitorering af stamdataindlæserens tilstand.parser- indeholder hjælpeklasser for parsning af stamdata filer, for Yderindlæseren er det SAX parser event handlere.route- indeholder den grundliggende opsætning af Camel router som orkestrerer udførelsen af pipelinenresources- indeholder bl.a. konfiguration af applikations- og NSP-logfilerdb-migration- indeholder sql scripts, der udføres af flyway til at vedligeholde og migrere databasenevents- indeholder specifikation af AVRO skema på JSON format - specifikationen beskriver struktur og indhold af de events, der flyder gennem pipelinenxsd- indeholder skema for Yderindlæserens stamdatafil og bruges under validering af en modtagen fil
webapp- indeholder visningsdelen for status-servlettest- indeholder unit- og integrations-tests
5.3. Versionskontrol
Kildekoden for hhv. fælles komponenter og stamdataindlæsere ligger i NSP'ens Subversion (SVN) installation eller GIT. For en given stamdataindlæser opretter NSP driften en placering som udvikleren af den givne stamdataindlæser kan anvende.
For fælles komponenter ligger koden i
- gammel version: https://svn.nspop.dk/svn/libraries/stamdataindlaeser/trunk/
- ny version: https://git.nspop.dk/scm/lib/stamdata-indlaesere.git
For Yderindlæseren ligger koden i https://svn.nspop.dk/svn/importers/yderindlaeser/trunk/ og andre stamdataindlæsere vil blive placeret i foldere på tilsvarende vis under https://svn.nspop.dk/svn/importers/
Ved frigivelse af koden tagges den med et SVN tag på formen
- for en release kandidat:
release-x.y.zrc - for en produktions release:
release-x.y.z
NSP driften kan efterfølgende bygge den ønskede release via Jenkins og igangsætte installation i test- og produktions-miljøer.
5.4. Databasenavnekonvention
Stamdataindlæsere vil afvikle på en og samme database. For at undgå, at de kolliderer omkring oprettelse af tabeller etc. skal alle tabeller som en stamdataindlæser anvender, prefixes med et unikt prefix. For en given stamdataindlæser vil NSP drift udstikke et unikt prefix som kan anvendes til de tilhørende tabeller. F.eks. for Yderindlæseren er prefixet "YDS" anvendt og alle tabelnavne er derfor på formen YDS_xxxx.
Til vedligehold af databasen anvendes LiquidBase eller Flyway (ældre indlæsere), som sikrer en kontrolleret afvikling af database migreringsscripts - dvs. LiquidBase/Flyway holder styr på, hvilke migreringsscripts der er afviklet, og hvilke der mangler at blive afviklet, når stamdataindlæseren startes.
LiquidBase/Flyway indeholder selv en tabel, som holder styr på hvilke scripts, der er afviklet.
For at undgå sammenblanding mellem stamdataindlæsere, anvendes det angivne prefix også ved initialisering og afvikling af Flyway. Hvordan prefixet anvendes kan ses i denne kodestump fra Yderindlæseren:
|
6. Beskrivelse af test opsætning
Stamdataindlæsere benytter i vid udstrækning docker til test, for at kunne teste så vidt muligt med de rigtige afhængigheder.
Det overordnede setup er beskrevet i NSP Continuous Integration & Delivery, og det er herved muligt at starte en specifik stamdataindlæser med lokalt kørende database samt stamdatakopiregisterservice (SKRS); således at hele flowet kan afprøves lokalt.
6.1. Unittest
Der anvendes unittests i alle stamdataindlæsere ved brug af JUnit.
Unittests kan køres ved at eksekvere
...
Java delen består af følgende pakker:
- config indeholder konfiguration af databaser, logning og andet relevant
- database.dao indeholder klasser til database adgang
- database.model indeholder den model som dao klasserne arbejder med
- monitoring indeholder logik til status servicen
- route indeholder default ruter, som indlæserne kan anvende til at bygge deres ruter med
- route.components indeholder de klasser default ruterne bruger, for at pakke camel/rute relateret logik væk fra yder indlæserne
- route.model indeholder modellen, der generaliserer de events, som default ruterne og deres komponenter arbejder på.
- service indeholder interfaces der skal anvendes af de enkelte indlæsere
- utils indeholder pt. funktionalitet til at tjekke ftp forbindelser, men har til formål at indeholde diverse utils klasser.
5.2. Kodestruktur for stamdataindlæser

Her er projektets struktur eksemplificeret fra Yderindlæseren hvor der er følgende moduler/foldere:
- compose folder der indeholder docker-compose filer til test og relateret configuration
- yder-event folder, som har ansvaret for at generere source kode/klasser ud fra det aktuelle avro format til brug for de andre moduler
- yder-integrationtest, der indeholder integrations testen for yder indlæseren. Herunder de test filer, der anvendes i testen
- yder-service, der indeholder selve yder indlæser logik
- yder-testreport, der sammenfatter test rapporter fra de andre moduler til een.
- yder-war, bygger runtime filen og indeholder den Dockerfile, der anvendes til at skabe docker containeren.

Her er det essentielle modul, hvor selve indlæser logikken findes, eksemplificeret fra Yderindlæseren med følgende pakker:
- config indeholder konfiguration af database og rute.
- database.dao indeholder klasser til database adgang
- database.model indeholder den model som dao klasserne arbejder med
- route indeholder opsæt af yder indlæseren rute. Den anvender i høj grad default ruten fra fælles biblioteket.
- route.components indeholder yder specfikke klasser, der anvendes af componets.impl
- route.components.field indeholder yder felt relateret logik.
- route.model indeholder de interne POJOs der arbejdes på som Events. Klassen YderIndlaeserEvent "starter" træ-strukturen, og den implementerer IndlaeserEvent fra fælles biblioteket.
- service indeholder de servlet indlæseren stiller til rådighed.
- service.impl indeholder implementeringen af fælles bibliotekes interfaces
5.3. Versionskontrol
Kildekoden for hhv. fælles komponenter og stamdataindlæsere ligger i NSP'ens Subversion (SVN) installation eller GIT. For en given stamdataindlæser opretter NSP driften en placering som udvikleren af den givne stamdataindlæser kan anvende.
For fælles komponenter ligger koden i
- gammel version: https://svn.nspop.dk/svn/libraries/stamdataindlaeser/trunk/
- ny version: https://git.nspop.dk/scm/lib/stamdata-indlaesere.git
For Yderindlæseren ligger koden i https://svn.nspop.dk/svn/importers/yderindlaeser/trunk/ og andre stamdataindlæsere vil blive placeret i foldere på tilsvarende vis under https://svn.nspop.dk/svn/importers/
Ved frigivelse af koden tagges den med et SVN tag på formen
- for en release kandidat:
release-x.y.zrc - for en produktions release:
release-x.y.z
NSP driften kan efterfølgende bygge den ønskede release via Jenkins og igangsætte installation i test- og produktions-miljøer.
5.4. Databasenavnekonvention
Stamdataindlæsere vil afvikle på en og samme database. For at undgå, at de kolliderer omkring oprettelse af tabeller etc. skal alle tabeller som en stamdataindlæser anvender, prefixes med et unikt prefix. For en given stamdataindlæser vil NSP drift udstikke et unikt prefix som kan anvendes til de tilhørende tabeller. F.eks. for Yderindlæseren er prefixet "YDS" anvendt og alle tabelnavne er derfor på formen YDS_xxxx.
Til vedligehold af databasen anvendes LiquidBase eller Flyway (ældre indlæsere), som sikrer en kontrolleret afvikling af database migreringsscripts - dvs. LiquidBase/Flyway holder styr på, hvilke migreringsscripts der er afviklet, og hvilke der mangler at blive afviklet, når stamdataindlæseren startes.
LiquidBase/Flyway indeholder selv en tabel, som holder styr på hvilke scripts, der er afviklet.
For at undgå sammenblanding mellem stamdataindlæsere, anvendes det angivne prefix også ved initialisering og afvikling af Flyway. Hvordan prefixet anvendes kan ses i denne kodestump fra Yderindlæseren:
|
6. Beskrivelse af test opsætning
Stamdataindlæsere benytter i vid udstrækning docker til test, for at kunne teste så vidt muligt med de rigtige afhængigheder.
Det overordnede setup er beskrevet i NSP Continuous Integration & Delivery, og det er herved muligt at starte en specifik stamdataindlæser med lokalt kørende database samt stamdatakopiregisterservice (SKRS); således at hele flowet kan afprøves lokalt.
6.1. Unittest
Der anvendes unittests i alle stamdataindlæsere ved brug af JUnit.
Unittests kan køres ved at eksekvere
|
Der findes i fælles biblioteket en pakke (stamdataindlaeser-test), som med fordel kan anvendes når man laver unit test for den enkelt indlæser. Pt (sommer 2023) kan anvendelse af dette ses i yder indlæseren).
Indlæseren arbejder i noget af ruten på et batch af events. I forbindelse med unit testen angives dette i klassen YderRouteBuilderTestSetup i variablen Iterable<Object[]> data(). Denne er default sat til en værdi, for at holde test tiden nede. Men inden release bør man køre en test med de udkommenterede værdier, sådan at koden bliver udfordret i forhold til denne værdi. Det er konstateret, at den kan have indflydelse i, om noget kode virker eller ej.)
6.1.1. Test i Camel
I det Camel kører asynkront, er det nødvendigt for unittests at vide, hvornår Camel er færdig med at indlæse en fil, hvis testen skal vide, hvornår den kan kontrollere, om det gik som forventet. Dette gøres i indlæseren, ved i en test klasse at holde øje med confirm filerne (.done og failure) og frigive en Semaphore (routeHandshake) der først frigives når de forventede filer er fundne.
...