Scope
Performancetesten består af et antal kald til læsning af allergier for en liste af 50.000 personer (cpr numre).
Testen involverer følgende komponenter
- LAR service som første led (v. 1.0.2)
- CAVE service som andet led (v. 1.0.2)
- FHIR database som tredie led (v. 3.7.0)
- Derforuden har integrationen til minlog, MinSpæring og behandler relation check være aktiveret under kørslen (Herefter benævnt som MSB servicene)
- NSP standard performancetest framework version 2.0.0
Performance krav
Kravene fra fra kravspecifikationen lyder som følger:
- Systemets svartider måles på en klient i umiddelbar nærhed af LAR service snitfladen, således at der medregnes et netværkskald mellem klient og service.
- Systemets gennemsnitlige svartid ved læsning skal ligge under 200ms.
- Forudsætninger for ovenstående svartider er, at:
- systemet anvendes af 10 samtidige brugere, der udfører et kald pr. sekund med 1000ms tidsmæssig forskydning på forskellige CPR numre.
- databasen indeholder 50.000 allergi-registreringer på et tilsvarende antal patienter.
- eksterne servicekald er deaktiveret
- der er ikke andre services der anvender infrastrukturen.
- der anvendes to applikationsservere til hver service, svarende til en NSP med to søjler til LAR servicen og to Back-End servere til CAVE servicen. Servicekald fordeles efter Round-Robin princippet mellem hver af de to servere.
- Serverne er hardwaremæssigt konfigureret svarende til NSP applikationsservere.
Kommentarer til krav og forudsætninger:
- Svartiderne er målt via access loggen. Dermed er netværkstiden ikke med i resultatet.
- Dette vil bleve vurderet med udgangspunkt i test resultaterne
- Forudsætnigner
- NSP standard test framework vil blive brugt, hvor belastningen gradvis øges fra 2 nodes og 7 tråde. Kravet med 10 samtidige brugere, der udfører et kald per sekund, kan omsættes til et throughput på 10 kald per sekund, hvilket kan vurderes vha. NSP test frameworkets output.
- inden testen startes er en database med 50.000 allergier fordelt på 50.000 patiener klargjort
- de eksterne servicekald var aktiveret under kørslen. Da svartiderne for disse kan findes i log filerne kan der laves en beregning, der viser svartiderne uden de eksterne servicekald.
- der var ikke andet end performance testen, som kaldte noget på test systemet under testen
- der er ialt anvendt 4 søjler, hvor LAR og CAVE har kørt på alle 4.
- testen blev afviklet på hardware identisk til NSP produktionsmiljøerne
Afvikling
Performance testen er afviklet på følgende måde
- Der er anvendt et test certifikat. Og der trækkes et idkort i setup fasen af testen, dvs hver gang en node startes. Den del er holdt ude af performance målingen
- Testen er kørt på et test system opsat at Netic: cstag-lb.cnsp.netic.dk:8080
- Testen er lavet i standard NSP performance frameworket (v.2.0.0), udviklet af Arosii i JMeter.
- Der er kørt en testplan med stadig øget belastning ved at øge antallet af tråde og noder indtil det målte throughput ikke længere vokser med tilsvarende mængde.
- Testplanen, der er kørt, er test900, og den kører 15 minutter per iteration.
- System under test (LAR og CAVE servicen) er kørt på på 4 docker containere
- Kald til de 3 eksterne service MSB har været aktiveret under testen
Se iøvrigt LAR test vejledning afsnit 2.3 performance test for detaljer.
De rå test resultater er vedhæftet denne side (lar-cave-perftest.tgz)
Performance tal
Udover det fremsatte performance krav med en svartid på under 200 ms, er der en række andre punkter som bør analyseres for at vurdere servicens sundhed.
Følgende punkter bliver derfor undersøgt:
- Svartid per kald
- Antal kald per sekund
- Cpu status
- io på netværk
- Hukommelses forbrug
- Garbage collection
Da hverken LAR eller CAVE servicen skriver til disk selv, bliver io til disk ikke undersøgt. Der er ikke målinger på database serveren.
Undersøgelserne foregår vha. de forskellige log filer, som er genereret under performance testen. De følgende afsnit gennemgår de vigtigste tal fra disse filer:
- JMeter log data belyser
- Faktisk antal test iteration kørt
- Throughput
- (/stress01.nsp-test.netic.dk-lar/lar_listallergy_test900_stress01.nsp-test.netic.dk_master_20190513_114050.tar.gz.log)
- Access log og sla log (applikations server information) belyser
- Antal kald per sekund
- Svartid per kald
- (Ex: docker01.cnsp.stage.nsp.netic.dk-lar/logs/lar/access.log)
- vmstat log (system information) belyser
- cpu status
- Logning sker hver 10. sekund
- (Ex: docker01.cnsp.stage.nsp.netic.dk-lar/stats/docker01.cnsp.stage.nsp.netic.dk-cpu-20190513110936.log)
- jstat log (JVM information) belyser
- Hukommelse (heap) forbrug
- Garbage collection
- Der er tidsstempel per log linie
- (Ex: docker01.cnsp.stage.nsp.netic.dk-lar/stats/docker01.cnsp.stage.nsp.netic.dk-cave-jstat-20190513110936.log)
- docker stats log (container information) belyser
- Hukommelse
- io på netværk
- Der er ikke noget fast logningsinterval.
- (Ex: docker01.cnsp.stage.nsp.netic.dk-lar/stats/docker01.cnsp.stage.nsp.netic.dk-cave-container-20190513110936.log)
Hver kørsel/iteration (øgning af belastning) har en start og slut tid. Filerne access.log og jstat.log indeholder tidstempler. Dette muliggør at de kan mappes til en given iteration. Filen vmstat har ikke tidstempel. Men da den er startet samtidig med jstat loggen og logintervallet er kendt på 10 sekunder, kan iterationernes placering i data beregnes. Docker stats loggen har hverken tidsstempel eller fast logninginterval, hvorfor tallene/graferne kun kan bruges som en generel betragtning over hele test perioden.
Hvor der i nedenstående er grupper af 4 grafer, skal de læses fra venstre mod højre og ned og mod højre: dette viser app server 1, 2, 3 og 4. Klik på den enkelt graf for større billede. De enkelte iterationer er tegnet ind som lodrette mørke streger; 8 streger, der sympolisere de 3 iterationers start og slut tidspunkt.
JMeter log data
JMeter hoved filen beskriver overordnet testens resultet.
Her kan kan ses, at der er kørt 3 iterationer med test, deres tidsinterval og throughput for hver.
| Iteration | Tråde | Nodes | Starttid | Sluttid | Throughput |
|---|---|---|---|---|---|
| 1 | 7 | 2 | 2019-05-13_11-10-14 | 2019-05-13_11-25-18 | 20,42 kald per sekund |
| 2 | 10 | 2 | 2019-05-13_11-25-41 | 2019-05-13_11-40-44 | 20,84 kald per sekund |
| 3 | 10 | 3 | 2019-05-13_11-41-12 | 2019-05-13_11-56-17 | 25,09 kald per sekund |
Det fremgår også af filen, at den endelige måling af throughput er 25,09 kald per sekund.
Samt at fejlprocentet på den fulde kørsel er 0,01 %.
Vurdering
Kravet til testen er, at der skal køres med 10 samtidige brugere med hver et kald per sekund. NSP's test framework fungerer med en bestemt belastning i testen som gradvis øges. I første iteration har testen kørt med 20 kald per sekund, hvilket ligger over kravet til testen. Da testen også har kørt med MSB servicene aktiveret, hvilket ikke er et krav, har det lagt yderligere pres på testen.
Derfor konkluderes det, at ud fra JMeter loggens data, er performance kravets forudsætning om 10 brugere med hver et kald per sekund så rigeligt overholdt.
Access log data
Denne log findes for hver applikations server (docker container) for både LAR og CAVE servicen.
Her findes data for hvert enkelt kald, der er lavet til de 2 LAR og CAVE services, herunder hvor lang tid et kald har taget (Duration). Ved at kigge på de kald, der er foretaget til LAR servicen kan den gennemsnitlige tid et kald tager beregnes.
Desuden kan tidsforbruget for kald til MSB servicene findes via via servicenes sla logs (nsputil-sla-lar.log) og messageid, og på den måde trækkes fra LAR servicens tid for at få netto tiden per kald.
Følgende tabel viser en række beregnede data fra access loggen fordelt på applikations server (container), test iteration og http kode. Nederst i tabellen er tallene for hver applikations server lagt sammen. Test iteration er beregnet ved at sammenligne tidstempel fra access log med start og sluttidspunktet for iterationen. Http koden findes i access loggen (kald returnerede med fejl (500) eller ingen fejl(200)).
De beregnede data er antal kald, kald per sekund i gennemsnit (hver iteration er 900 sekunder) samt tidsforbrug per kald i millisekunder.
| Applikations server | Iteration | HttpCode svar | Antal kald | Kald per sekund | Tidsforbrug (ms) | |
|---|---|---|---|---|---|---|
| Med MSB | Uden MSB | |||||
| docker01.cnsp.stage.nsp.netic.dk-lar | 1 | 200 | 4597 | 5,1 | 623 | 154 |
| 2 | 200 | 4693 | 5,2 | 868 | 177 | |
| 3 | 200 | 5650 | 6,3 | 1123 | 206 | |
| 500 | 1 | 0 | 32257 | 32189 | ||
| docker02.cnsp.stage.nsp.netic.dk-lar | 1 | 200 | 4597 | 5,1 | 612 | 149 |
| 2 | 200 | 4693 | 5,2 | 900 | 193 | |
| 3 | 200 | 5650 | 6,3 | 1125 | 197 | |
| 500 | 1 | 0 | 31634 | 31579 | ||
| docker03.cnsp.stage.nsp.netic.dk-lar | 1 | 200 | 4598 | 5,1 | 620 | 153 |
| 2 | 200 | 4693 | 5,2 | 885 | 173 | |
| 3 | 200 | 5650 | 6,3 | 1114 | 185 | |
| 500 | 1 | 0 | 33109 | 32917 | ||
| docker04.cnsp.stage.nsp.netic.dk-lar | 1 | 200 | 4598 | 5,1 | 624 | 162 |
| 2 | 200 | 4692 | 5,2 | 904 | 192 | |
| 3 | 200 | 5652 | 6,3 | 1124 | 197 | |
| Total | 59766 | 896 | 181 | |||
| Total for alle 4 servere | 1 | 200 | 18390 | 20,4 | 620 | 155 |
| 2 | 200 | 18771 | 20,9 | 889 | 184 | |
| 3 | 200 | 22602 | 25,1 | 1122 | 196 | |
| 3 | 500 | 3 | 0 | 32333 | 32228 | |
Udtræk af svartid og antal kald fordelt over testens løbetid vises i følgende 4 grafer. Svartiderne er uden MSB tidsforbruget:
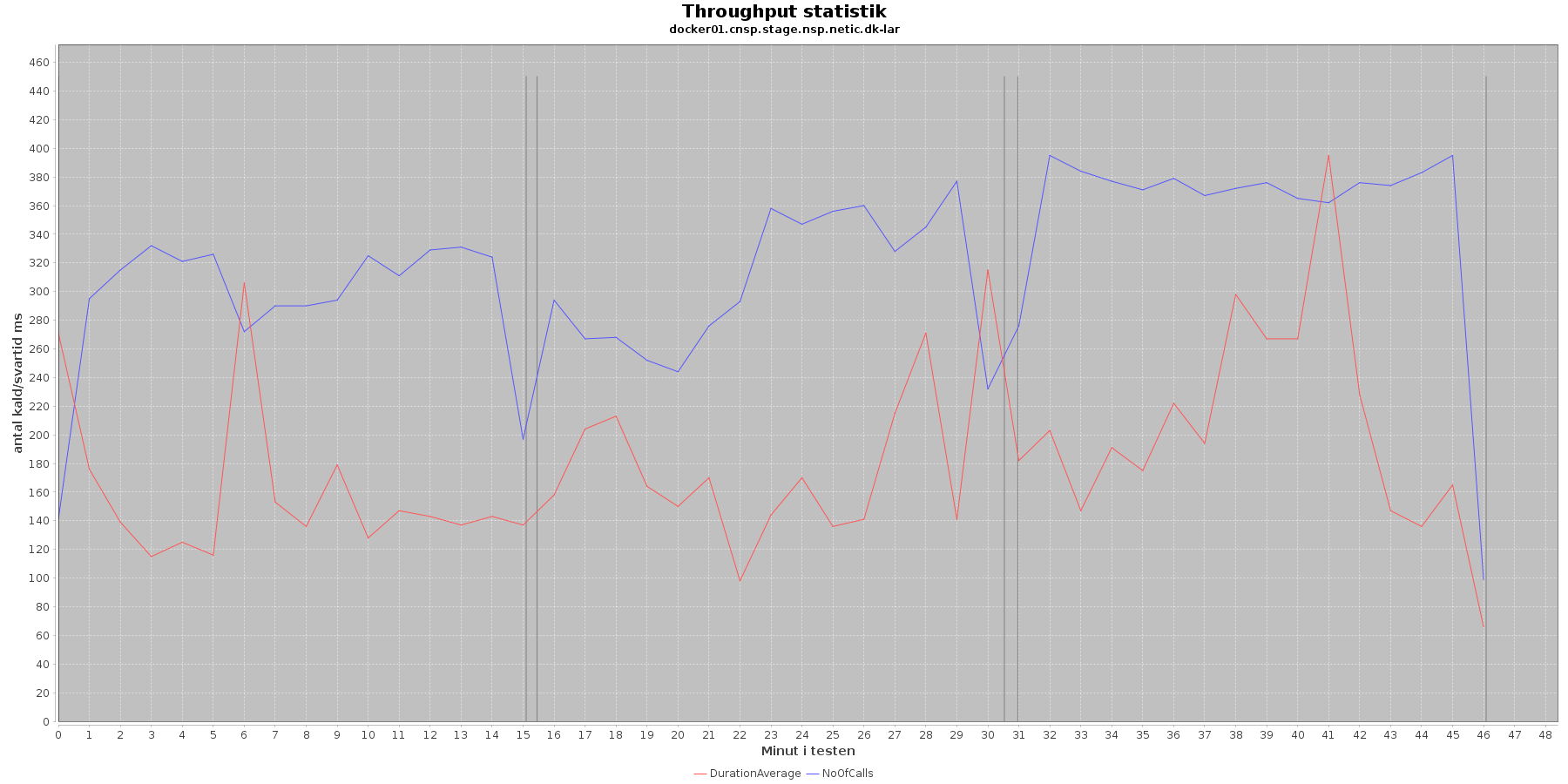
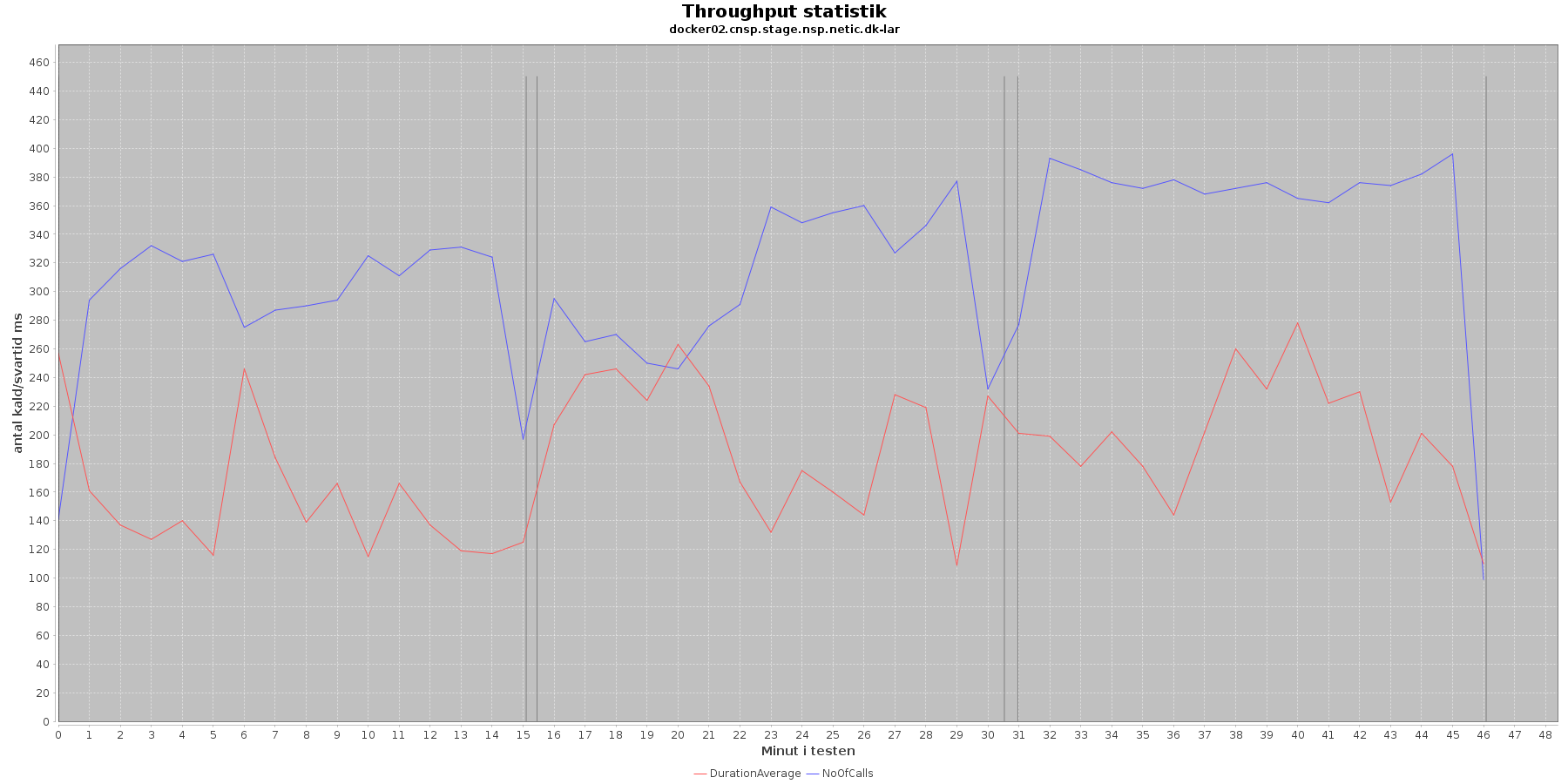
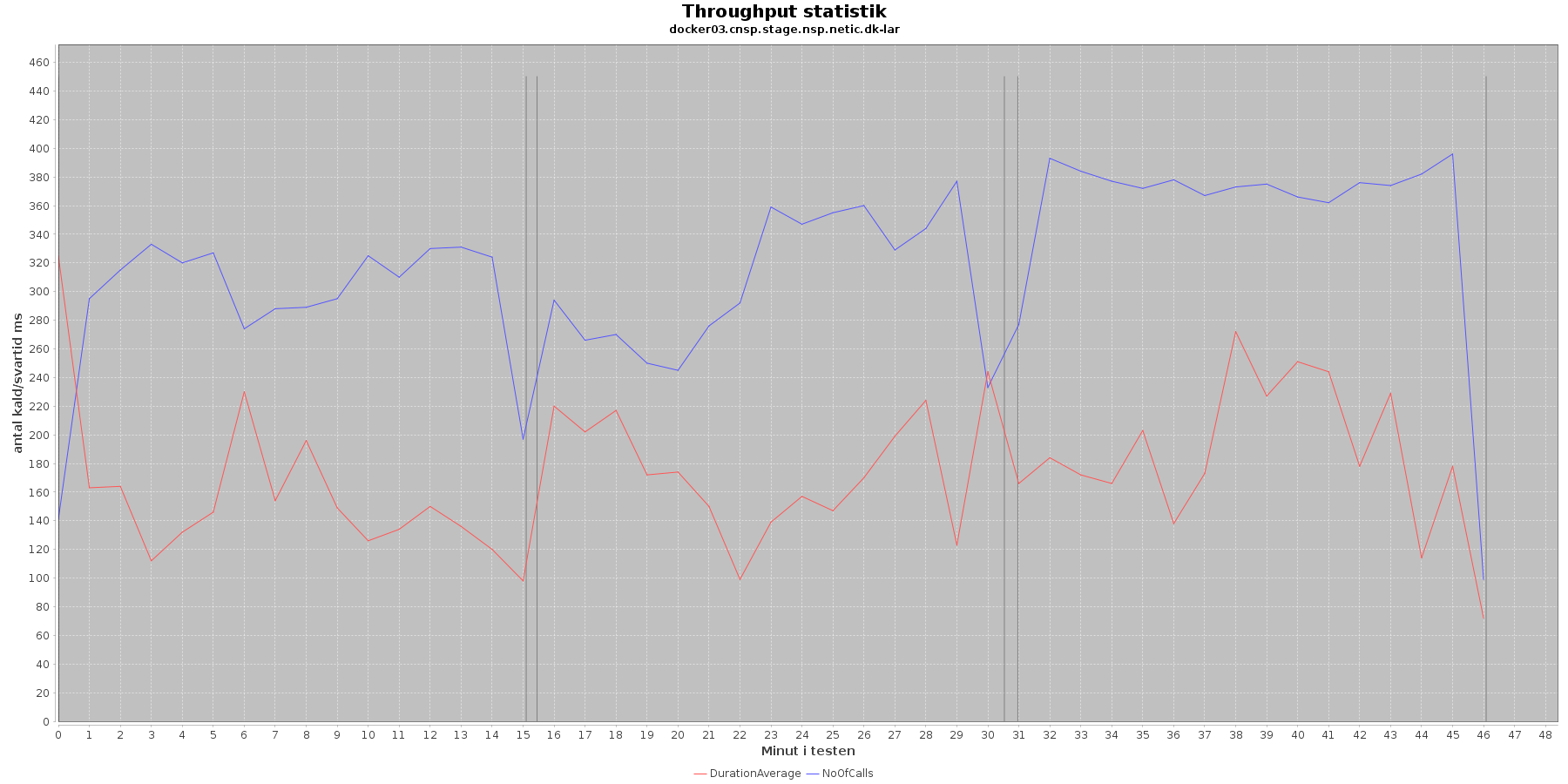
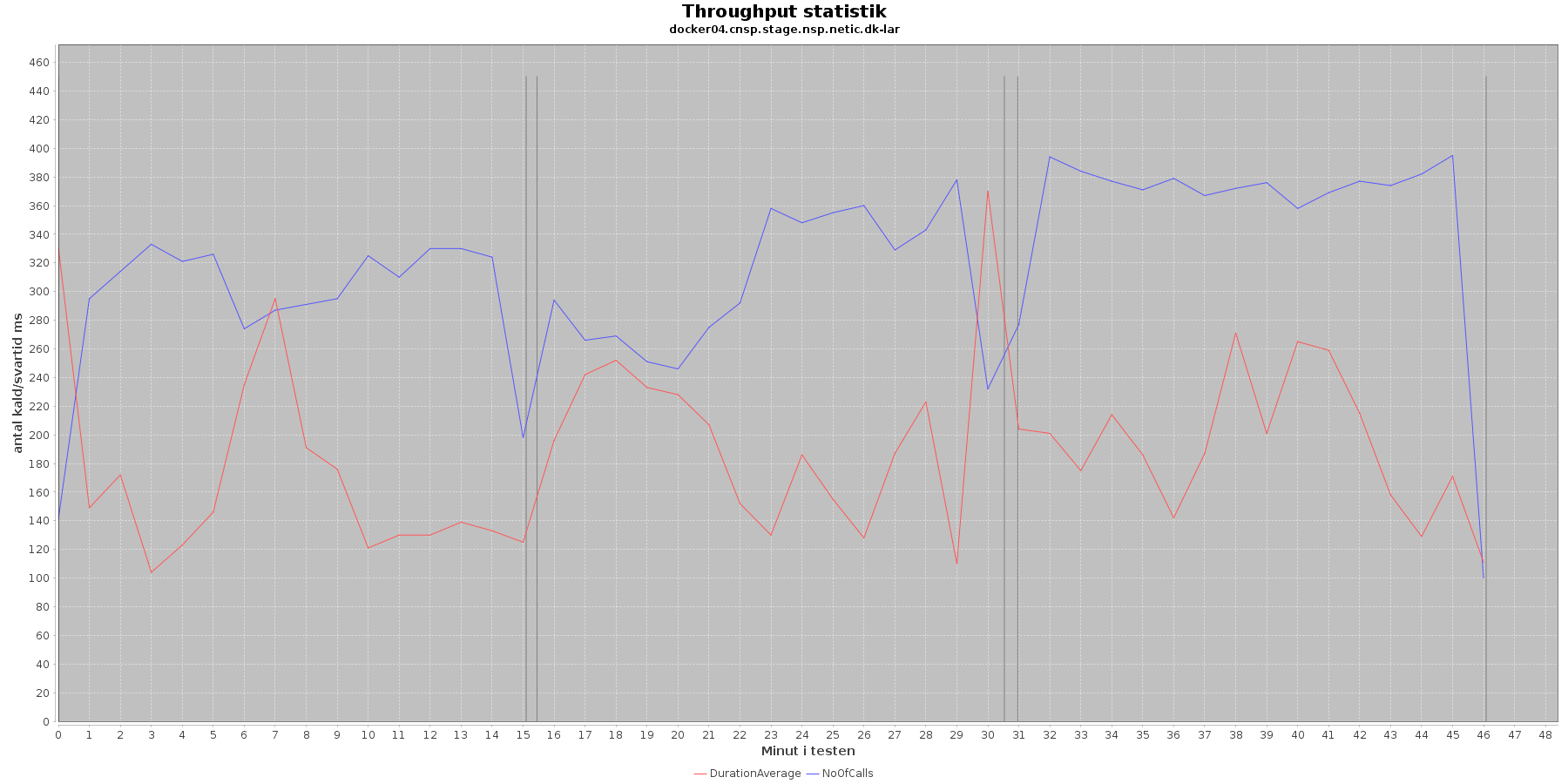
Data serier i grafen er:
- DurationAverage (rød): den gennemsnitlige svartid (ms) for hvert minut (uden MSB kald)
- NoOfCalls (blå): det gennemsnitlige antal kald hvert minut
- De 3 iterationer (sort) er baseret på det tidstempel, som findes i jstatloggen
Vurdering
Af tabel og grafer fremgår det, at jo flere nodes og tråde (disse øges per iteration) jo flere kald kommer der igennem per sekund. Tallene svarer overens med de tal JMeter kom frem til som throughput.
Det ses (tydligst i tabellen), at jo flere nodes/tråde jo højere bliver svar tiden. Performance kravet er 200 ms ved 10 brugere uden MSB services slået til. Ovenstående tabel viser, at ved iteration 1 er svartiden 155 ms, og tidligere fremgik det at througput her var 20 kald per sekund. Vi er inden for performance kravet.
Man kan undres over, hvorfor det skal tages så meget mere tid når MSB servicene medtages. Det har vist sig at kaldet til BRS er lavet uhensigtmæssigt, hvilket bliver rettet på Jira CAVE-78.
Vmstat log
Denne log findes for hver applikations server (docker container). Den viser resultatet af kommandoen vmstat
Udtræk omkring cpu fra denne log vises i de følgende 4 grafer.
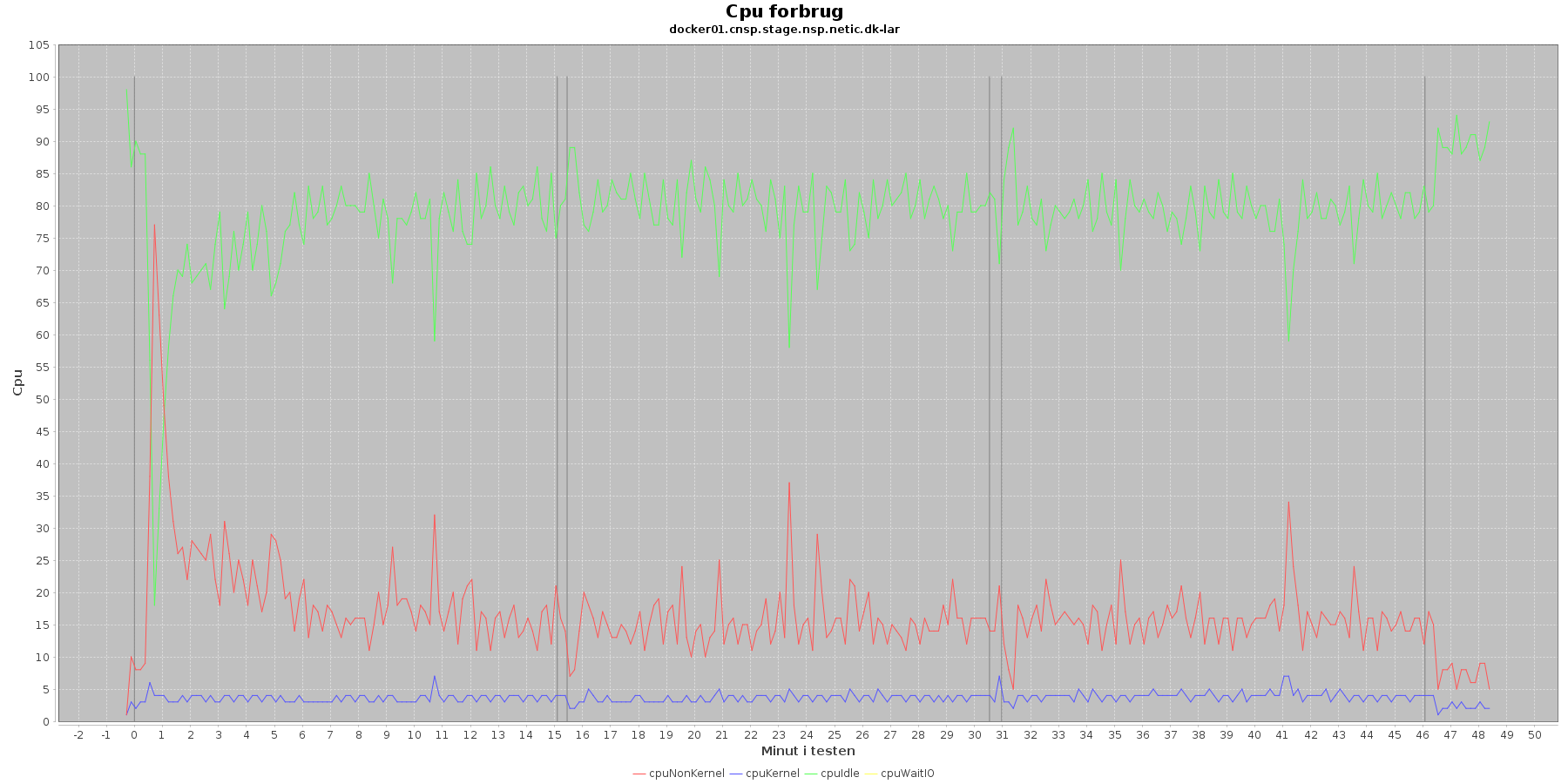
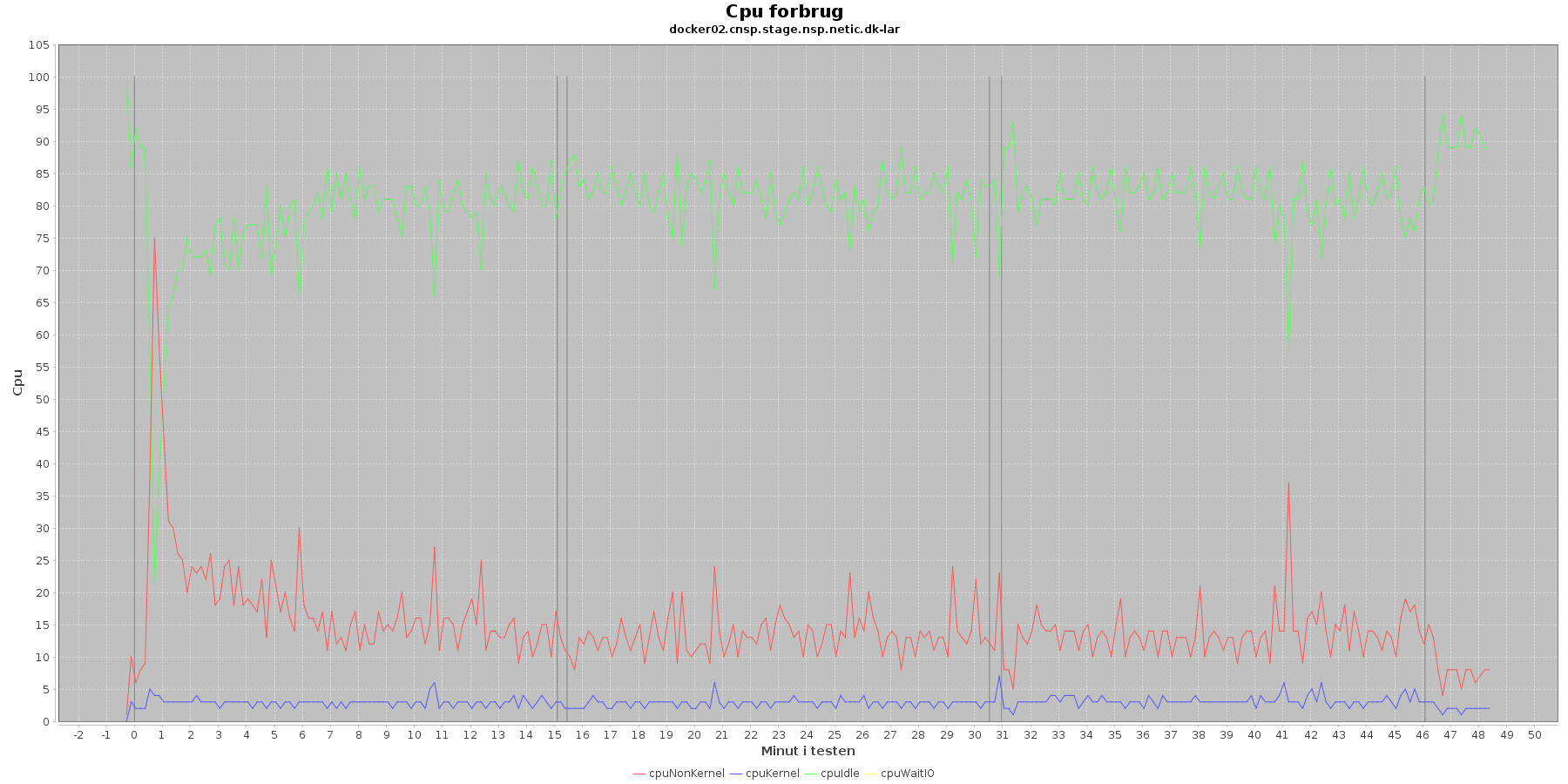
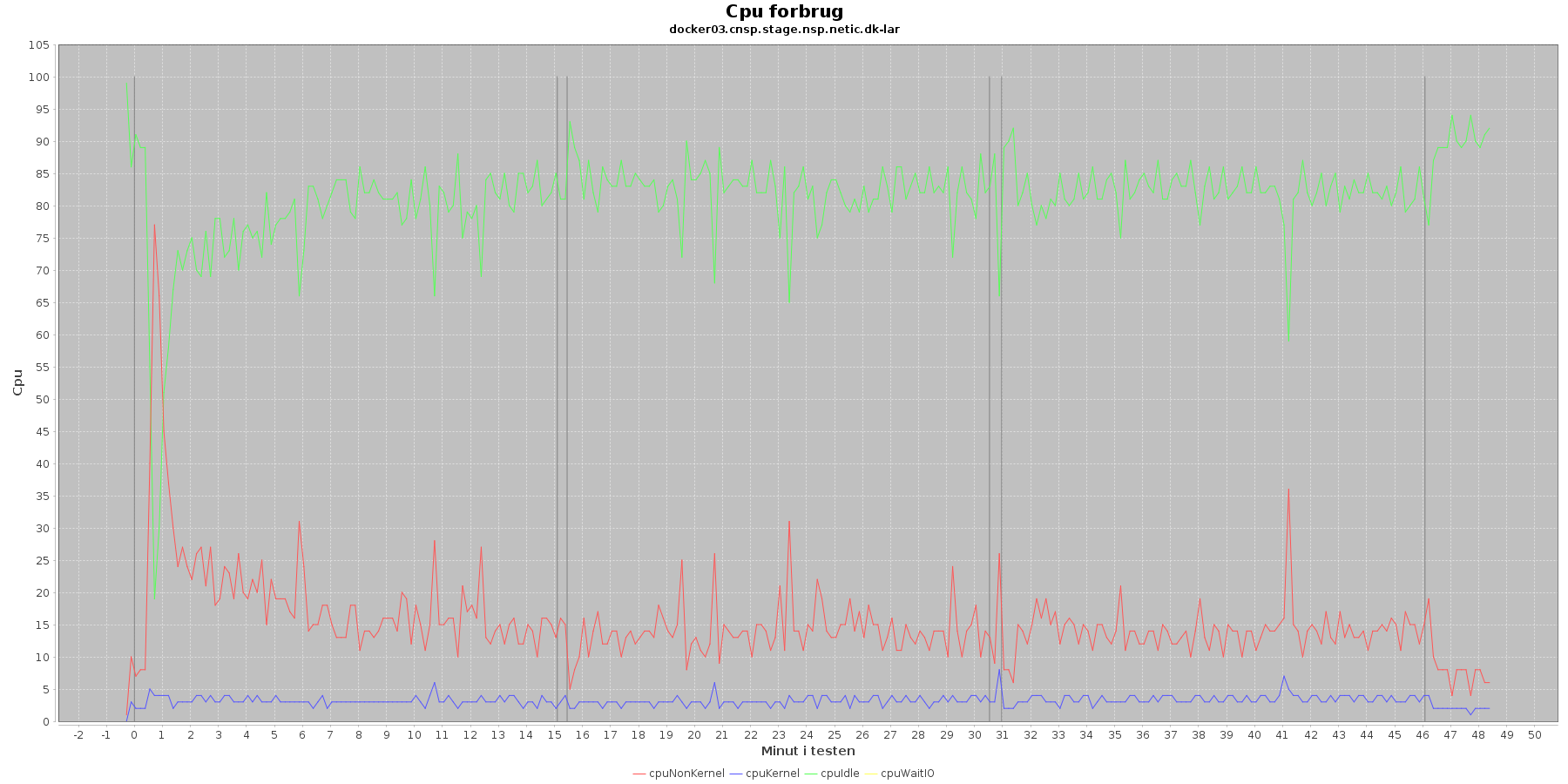
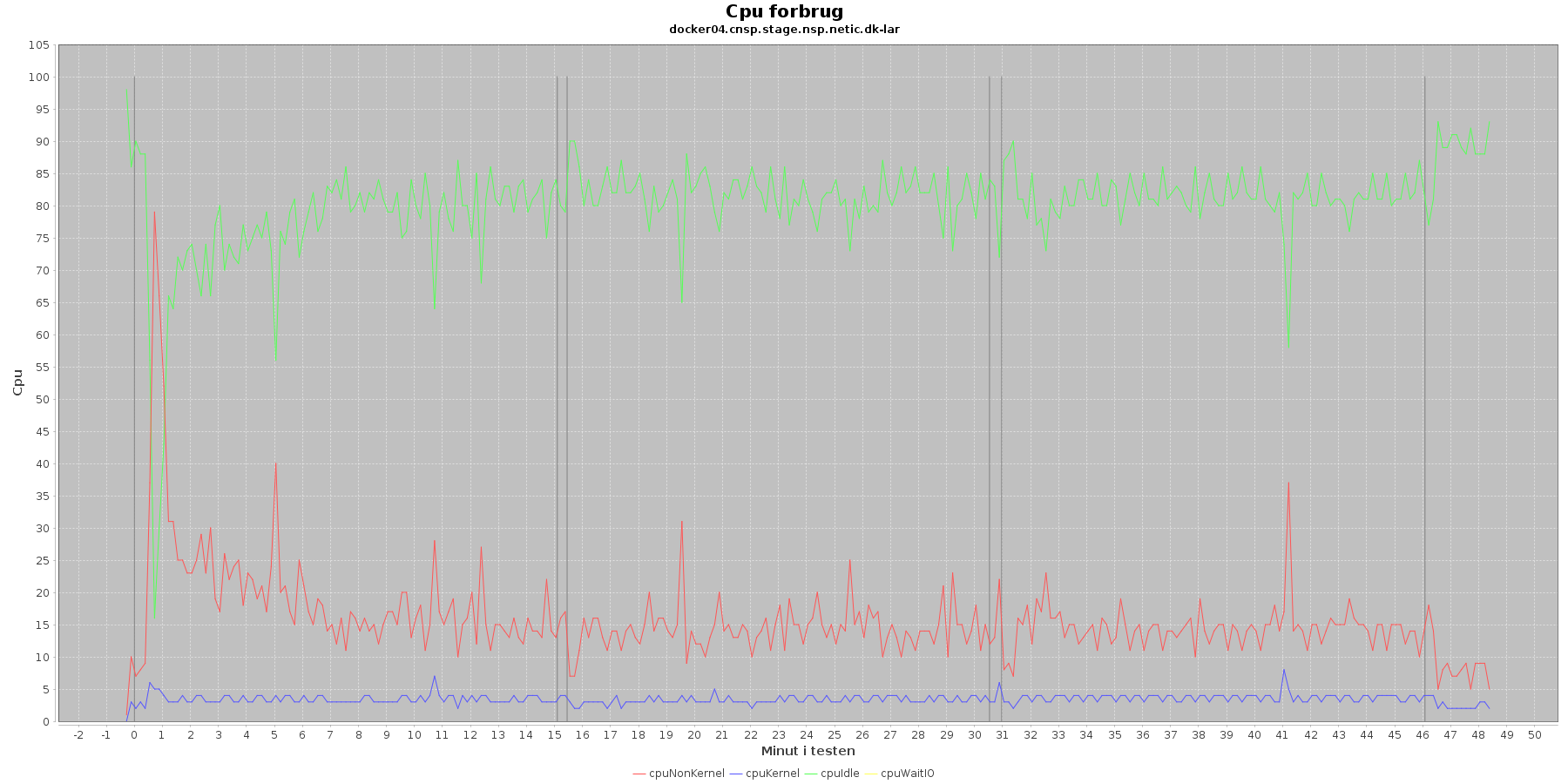
Data serier i grafen er:
- cpuNonKernel (rød): tid brugt på non-kernel opgaver
- cpyKernel (blå): tid brugt på kernel opgaver
- cpuIdle (grøn): tid brugt på ingenting
- cpuWaitIO (gul): tid brugt på at vente på i/o
- De 3 iterationer (sort) er en cirka placering, da wmstat loggen ikke indeholder tidstempel
De 4 dataserier i graferne er meget stabile. Man ser en aktivitet omkring start og slut af de 3 iterationer. Størst udsving er der ved opstart af testen, hvor den cpu der bliver brugt af applikationen (cpuNonKernel) stiger meget og idle cpu tilsvarende falder. Men det er kun kortvarigt.
Vurdering
Der er intet negativt at bemærke omkring cpu forbruget.
Jstat log
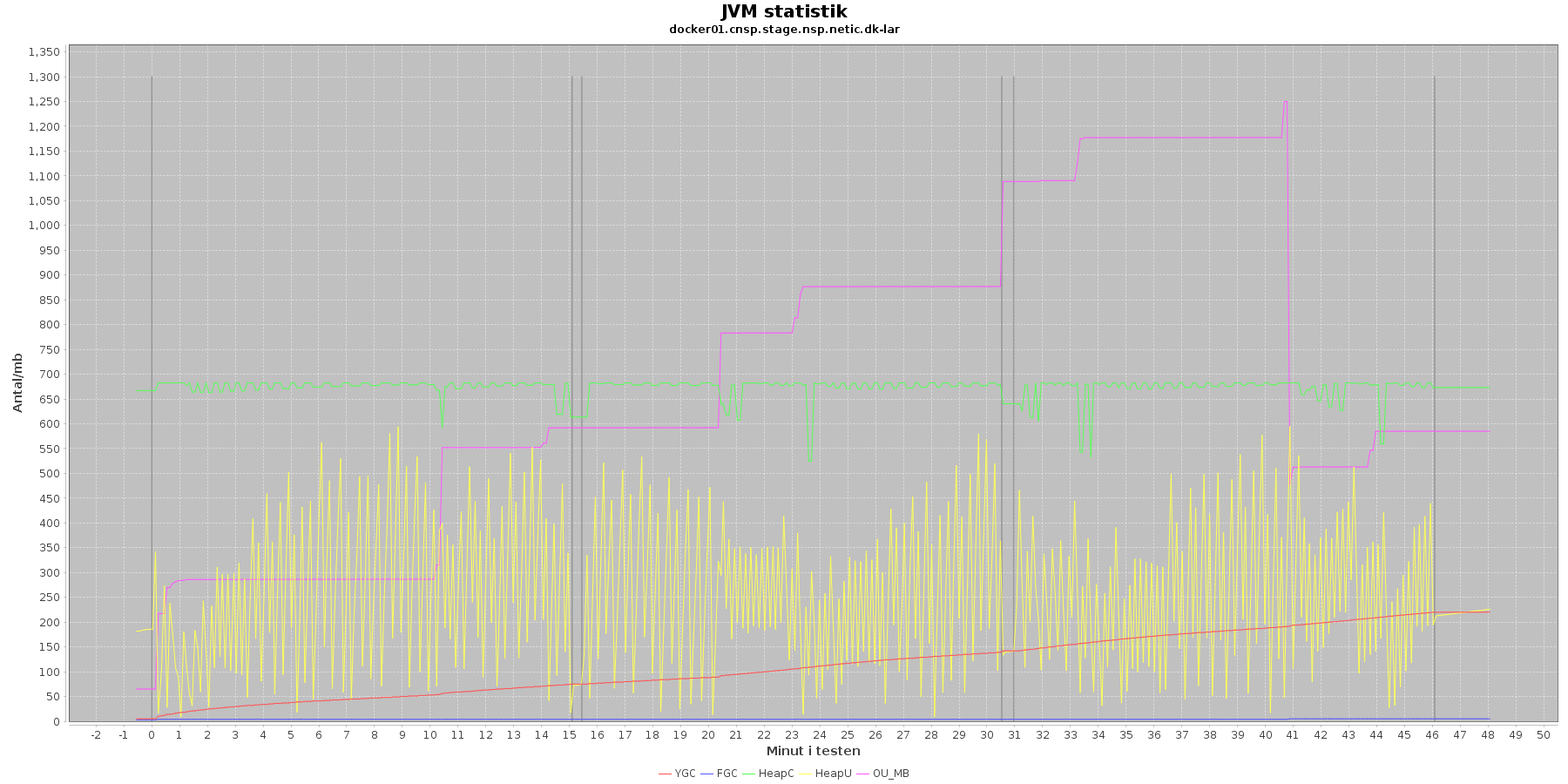
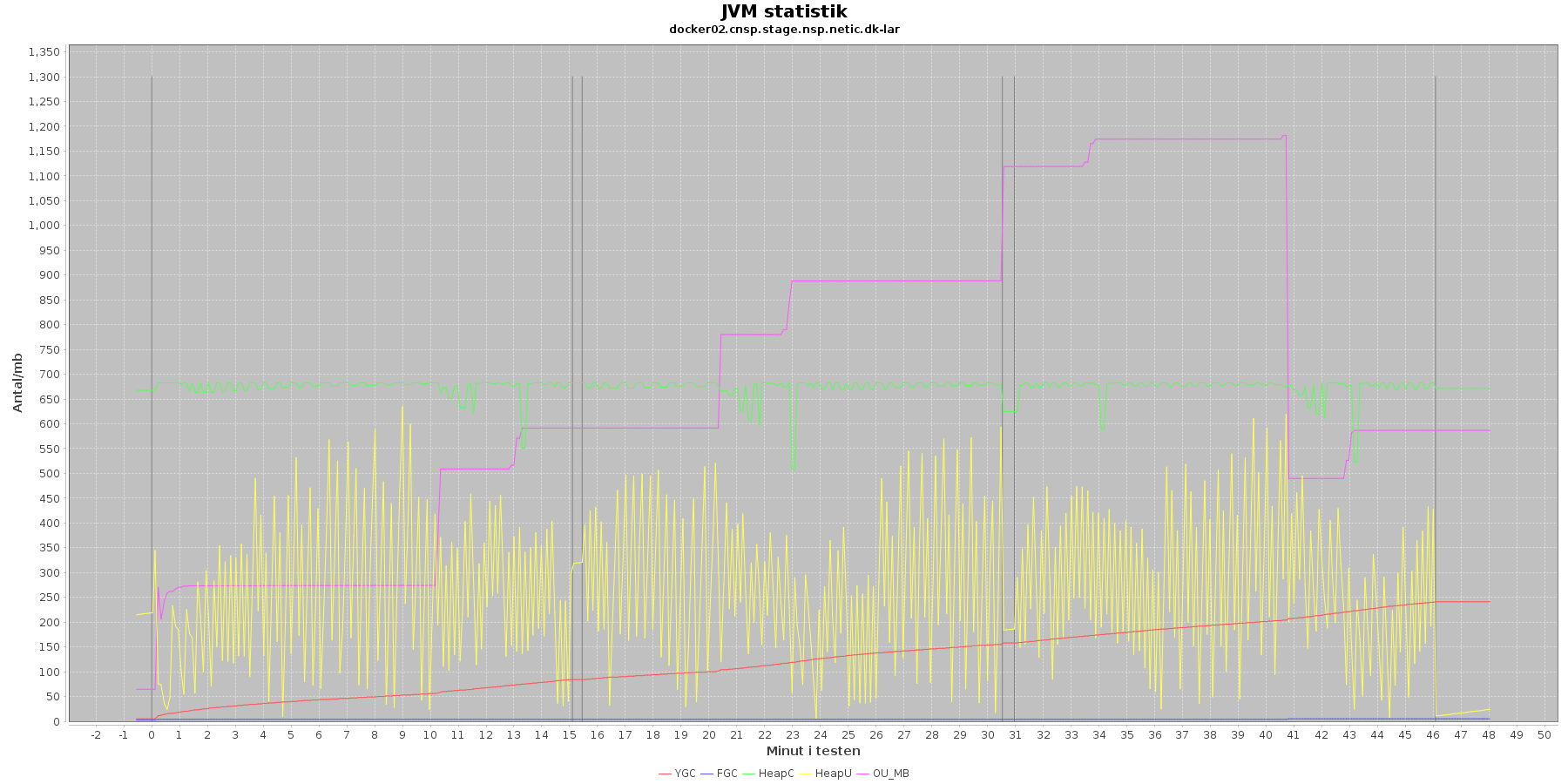
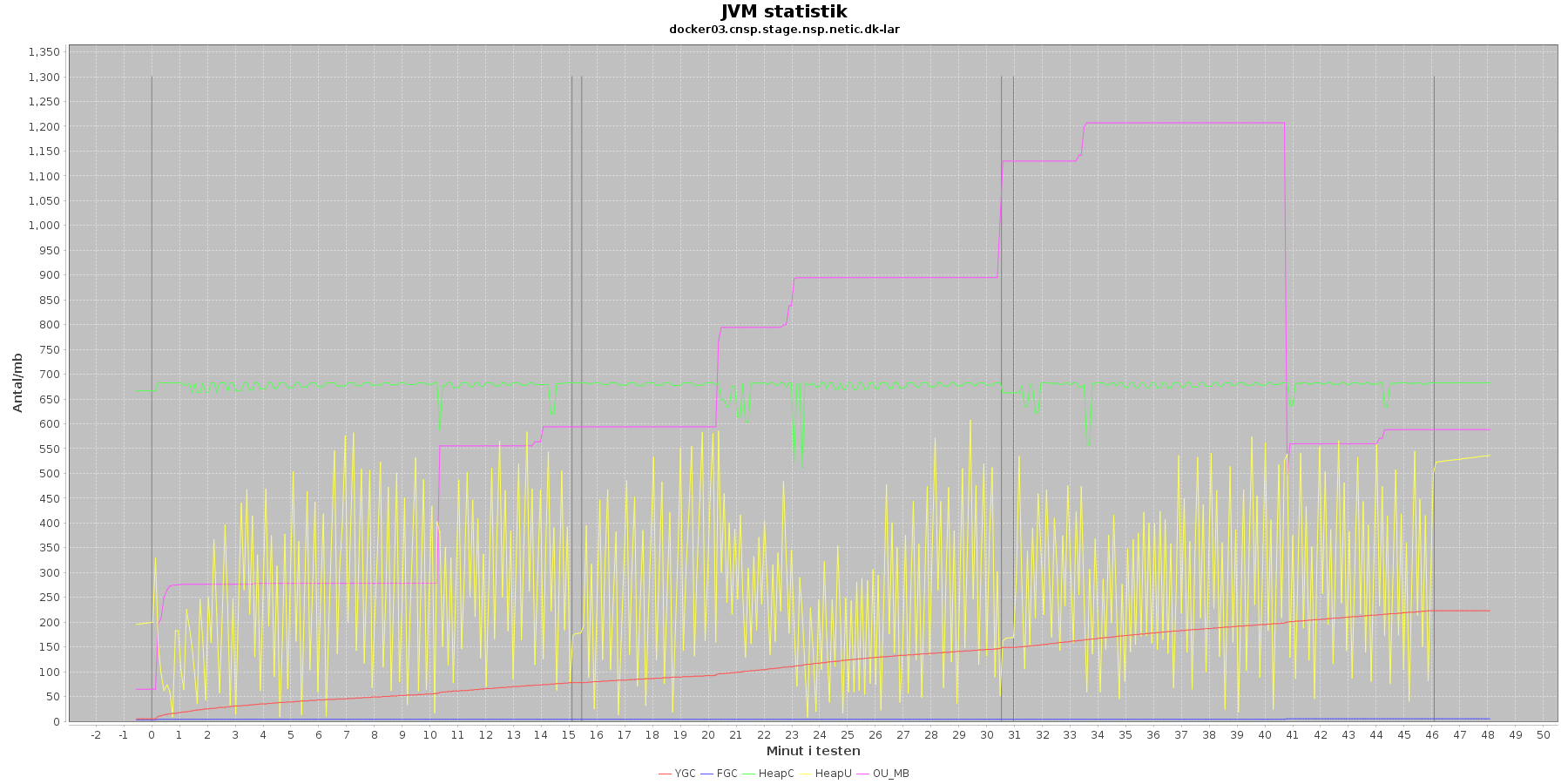
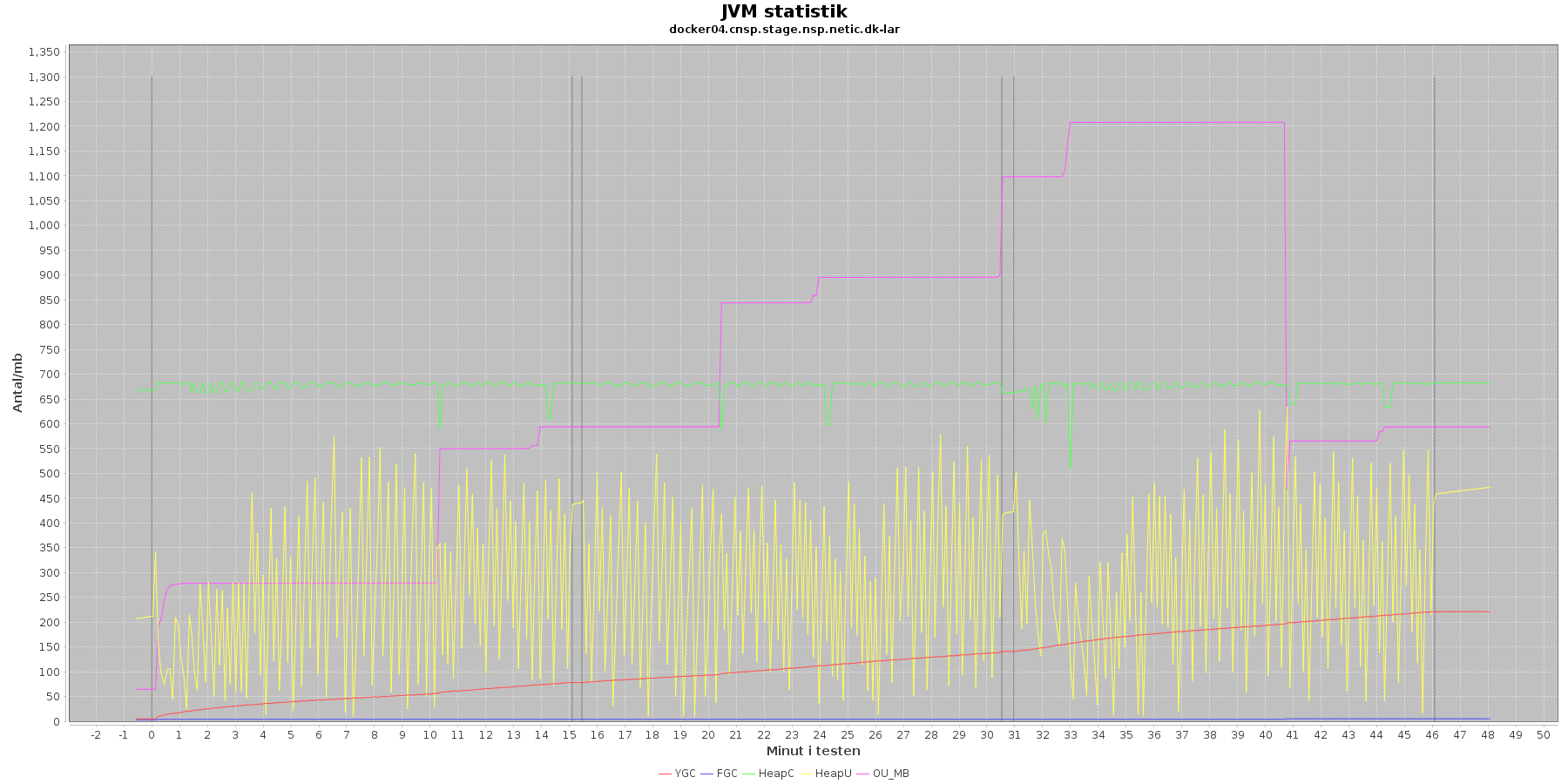
Denne log findes for hver applikations server (docker container) - en for LAR og en for CAVE. Loggen viser resultatet af kommandoen jstat. Jstat siger noget om, hvordan JVM'en har det.
Udtræk omkring hukommelse og garbage collection fra denne log vises i de følgende 4 grafer for henholdsvis LAR og CAVE.
LAR servicen:
CAVE servicen:
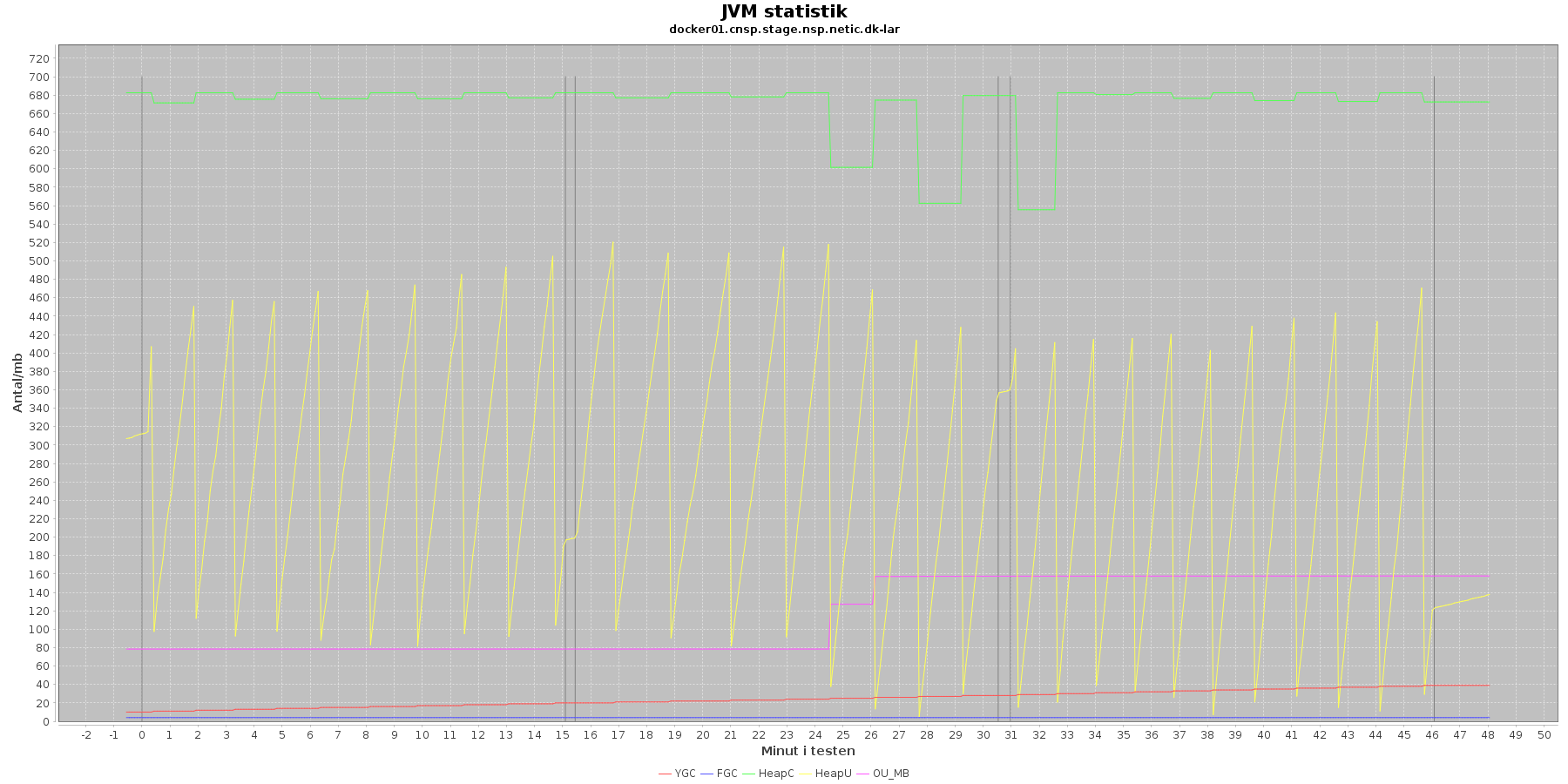
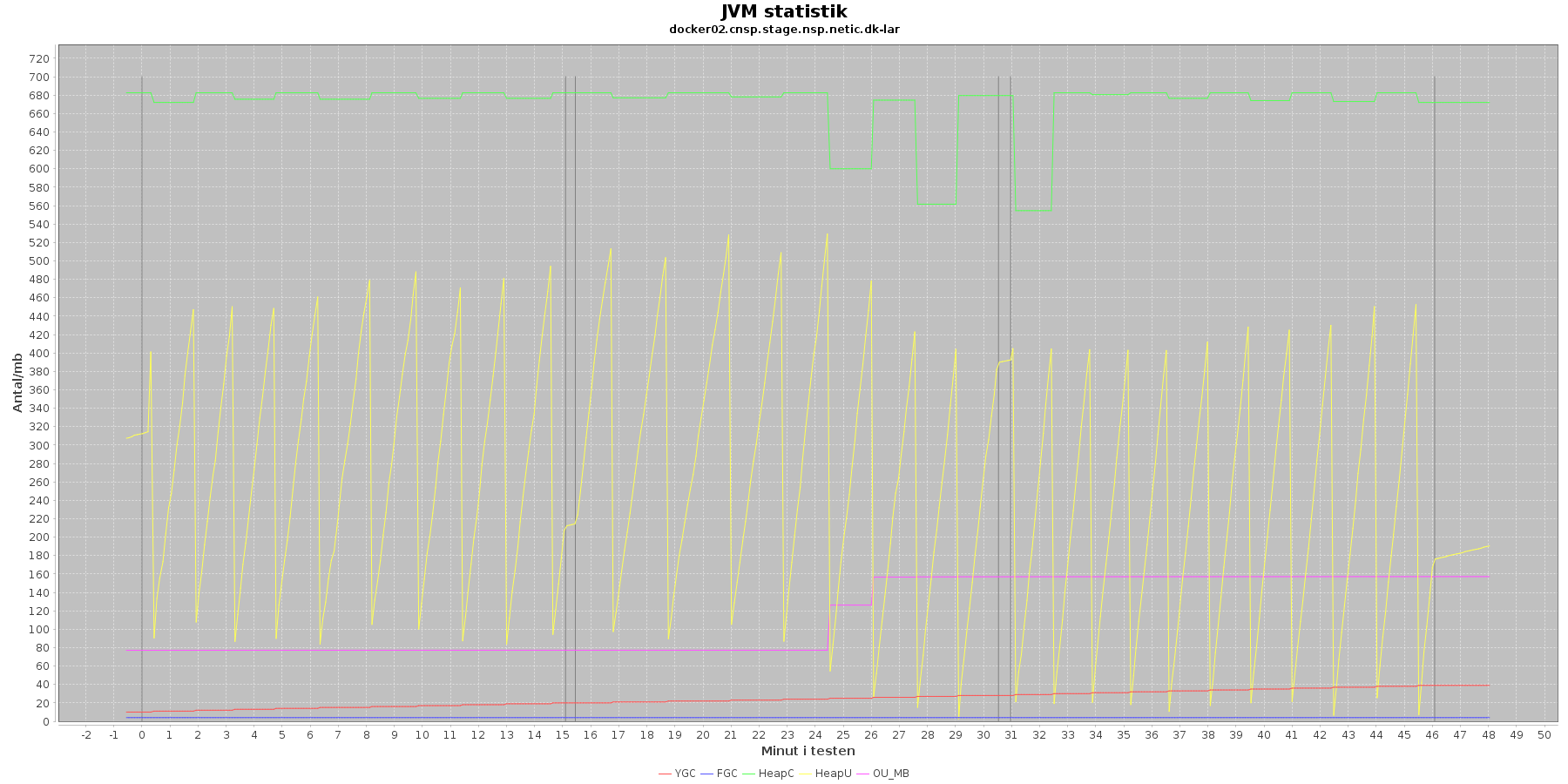
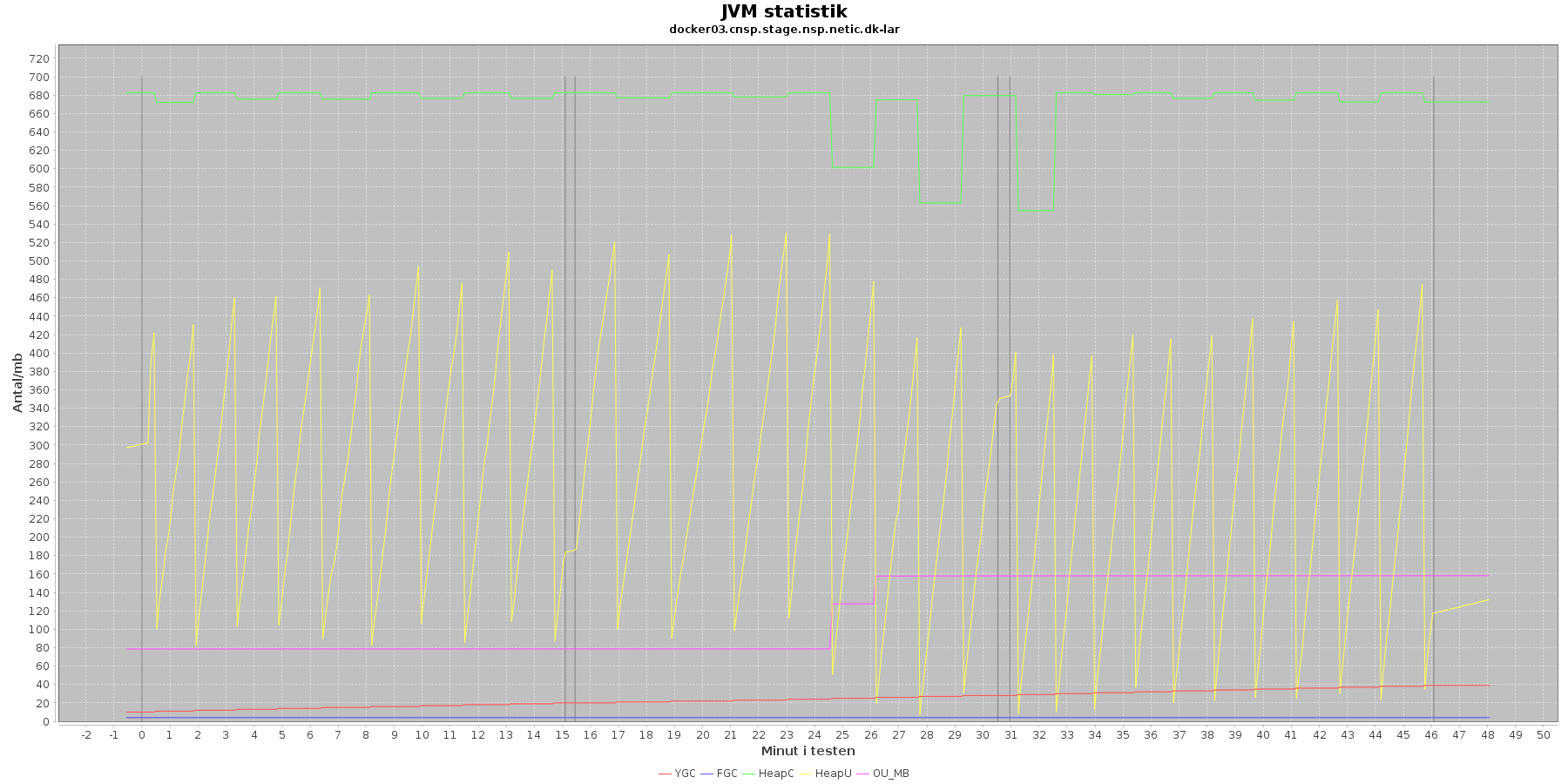
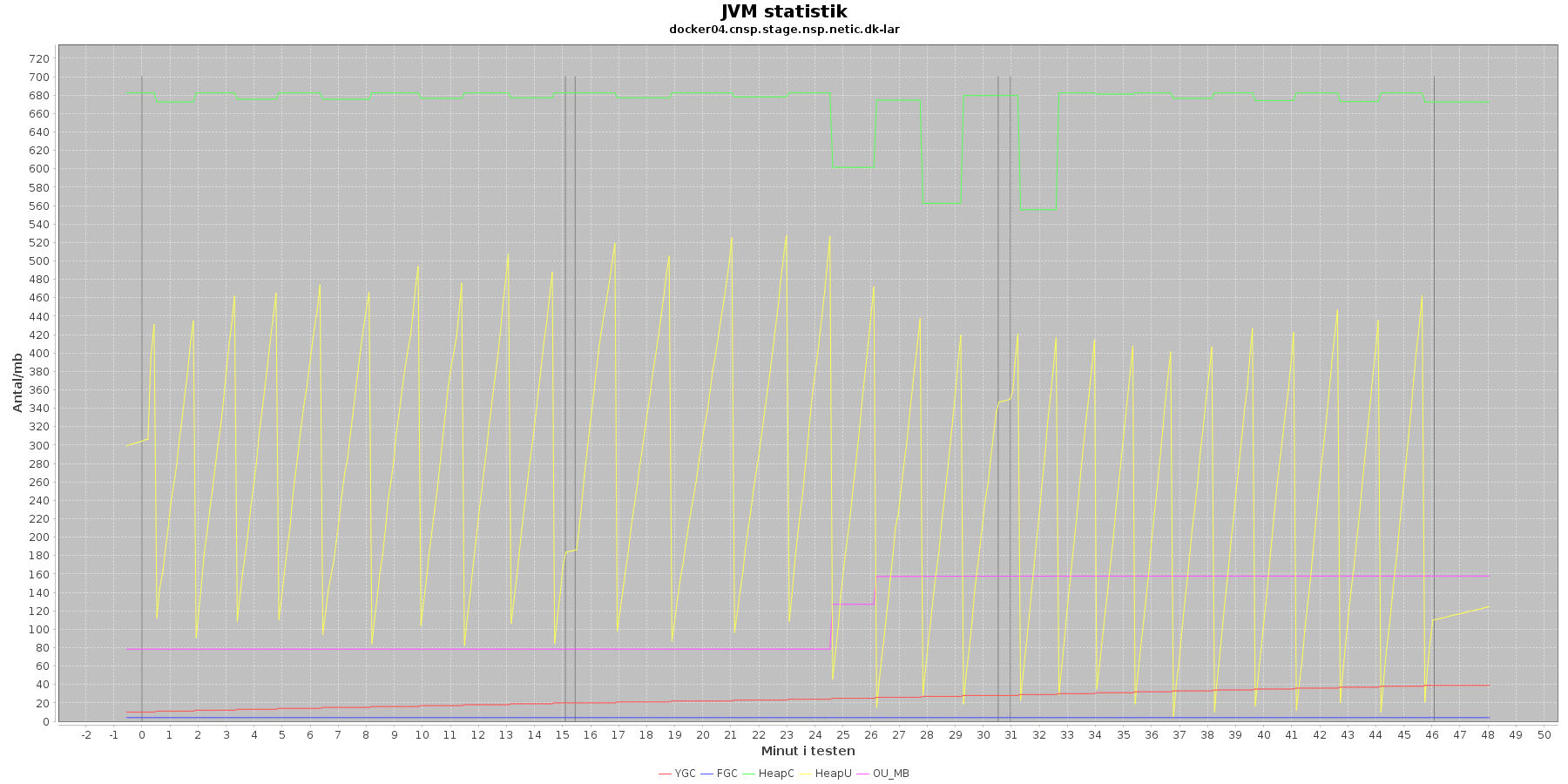
Data serier i grafen er:
- YGC (rød): young generation garbage collection events, antal af "ung" garbage collection siden start
- FGC (blå): full garbage collection events, antal af fuldstændig garbage collection siden start
- HeapU (gul): består af S0U+S1U+EU fra jstat loggen. Young generation memory utilization. "Ung" hukommelses forbrug
- HeapC (grøn): består af S0C+S1C+EC fra jstat loggen. Young generation memory capacity. "Ung" hukommelses kapacitet
- OU_MB (pink): old space utilization. "Ældre" hukommelses forbrug
- OC: old space capacity. "Ældre" hukommelses kapacitet er ikke en del af grafen men er konstant på 1.398.272 KB for både LAR og CAVE.
- De 3 iterationer (sort) er baseret på det tidstempel, som findes i jstatloggen
Det kan være lidt svært at se ændringer i graferne for full garbage collection (FGC). Kigger man nærmere på datagrundlaget bag graferne, ses det, at der er kørt full garbage collection for LAR servicen i testens 1. minut (8. loglinie - i starten af iteration 1) og i testens 41. minut (420. loglinie - midt i 3. iteration).
For CAVE kan man se, at der ikke er kørt fuld garbage collection. Der køres også oftere garbage collection på den yngre hukommelse på LAR servicen end der gør på CAVE.
Den brugte yngre hukommelse svinger noget for både LAR og CAVE, men dog i et konstant interval.
Vurdering
Den yngre forbrugte hukommelse eskalerer ikke for hverken LAR eller CAVE. Garbage collecteren gør sit arbejde.
Docker stats log
Denne log findes for hver applikations server (docker container) - en for LAR og en for CAVE. Loggen viser resultatet af kommandoen docker stats. Docker stats siger noget om, hvordan containeren forbruger sine ressourcer.
Udtræk omkring hukommelse, cpu netværkstrafik vises i følgende 3 * 4 grafer.
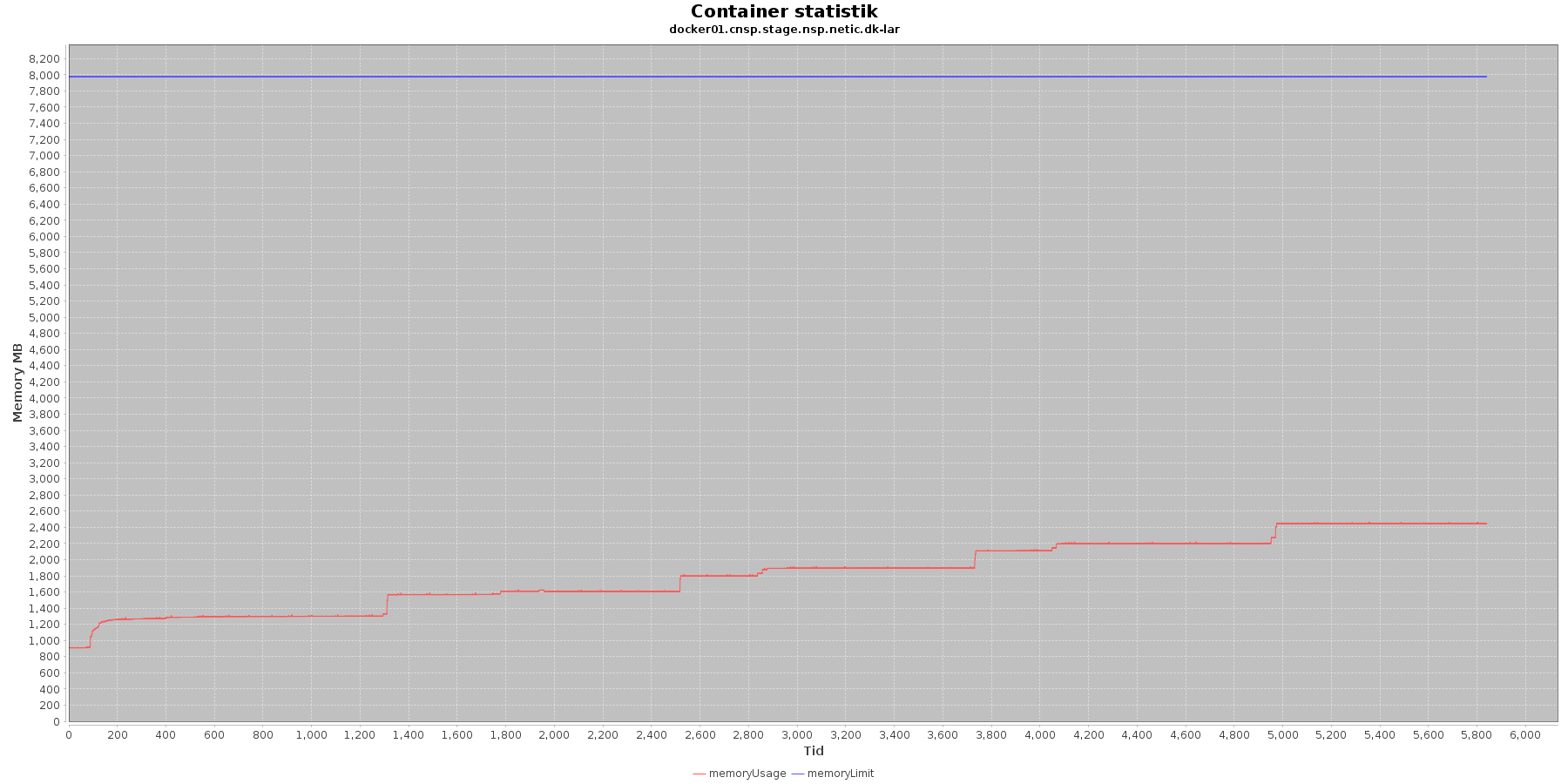
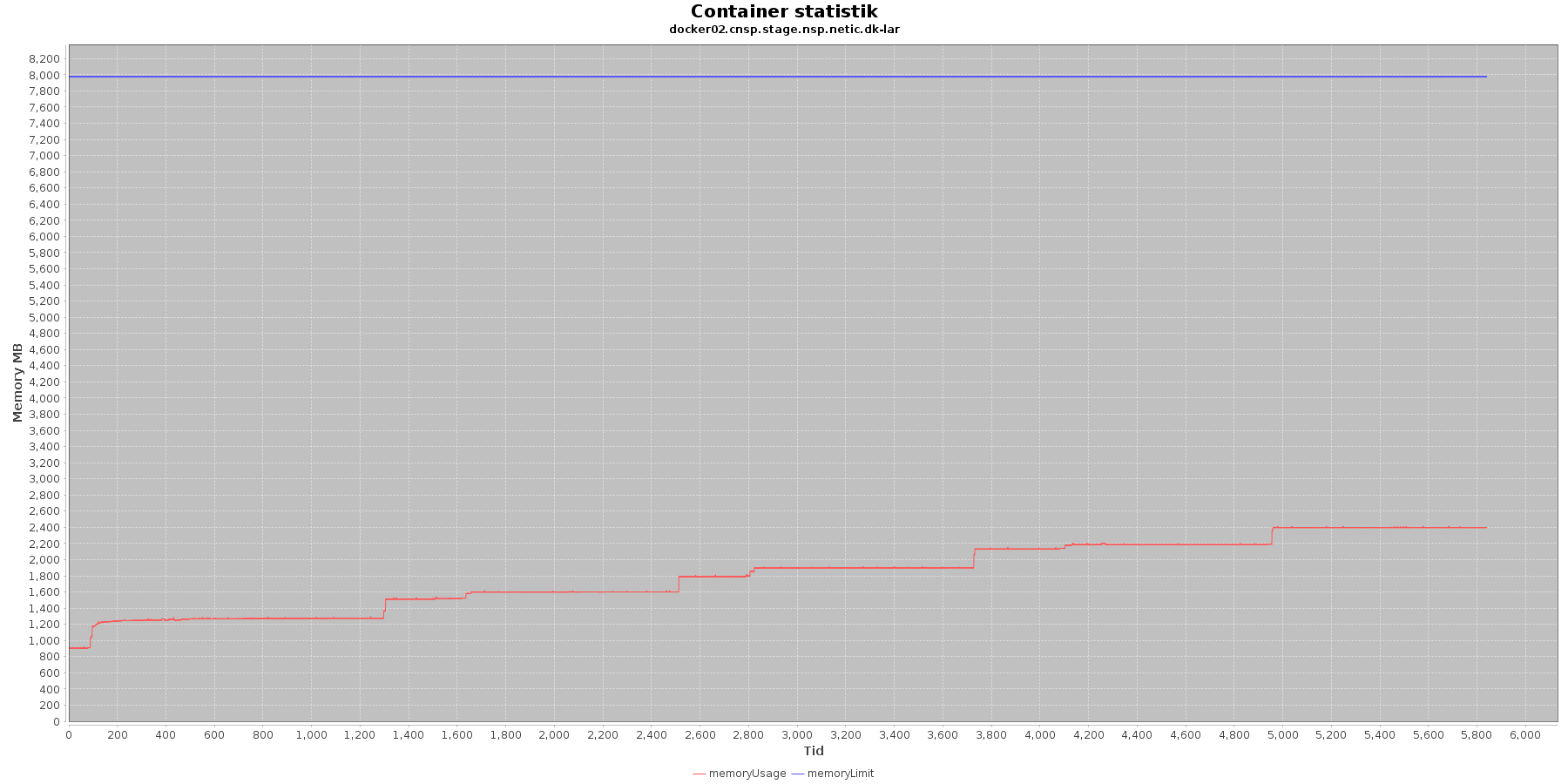
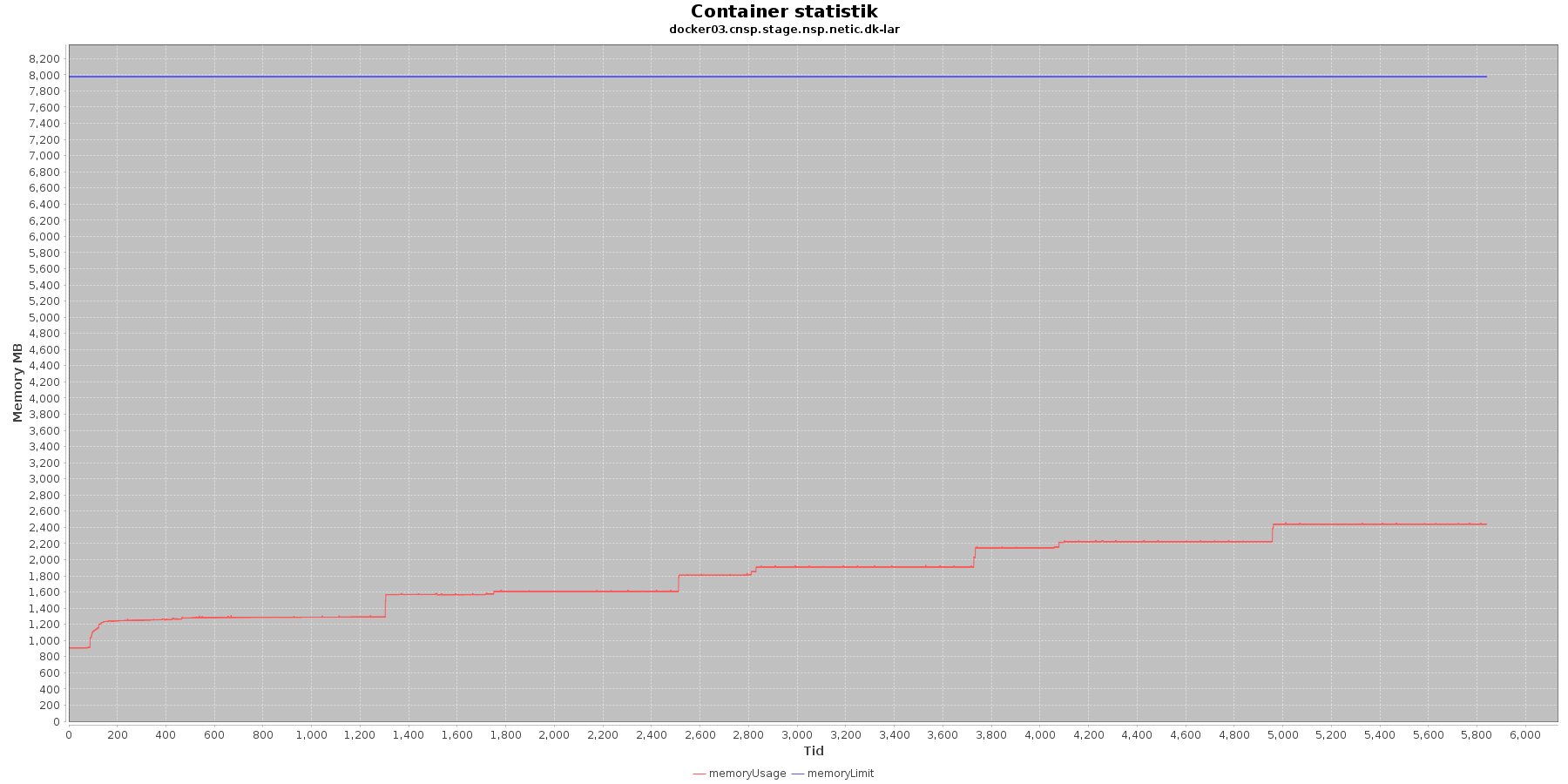
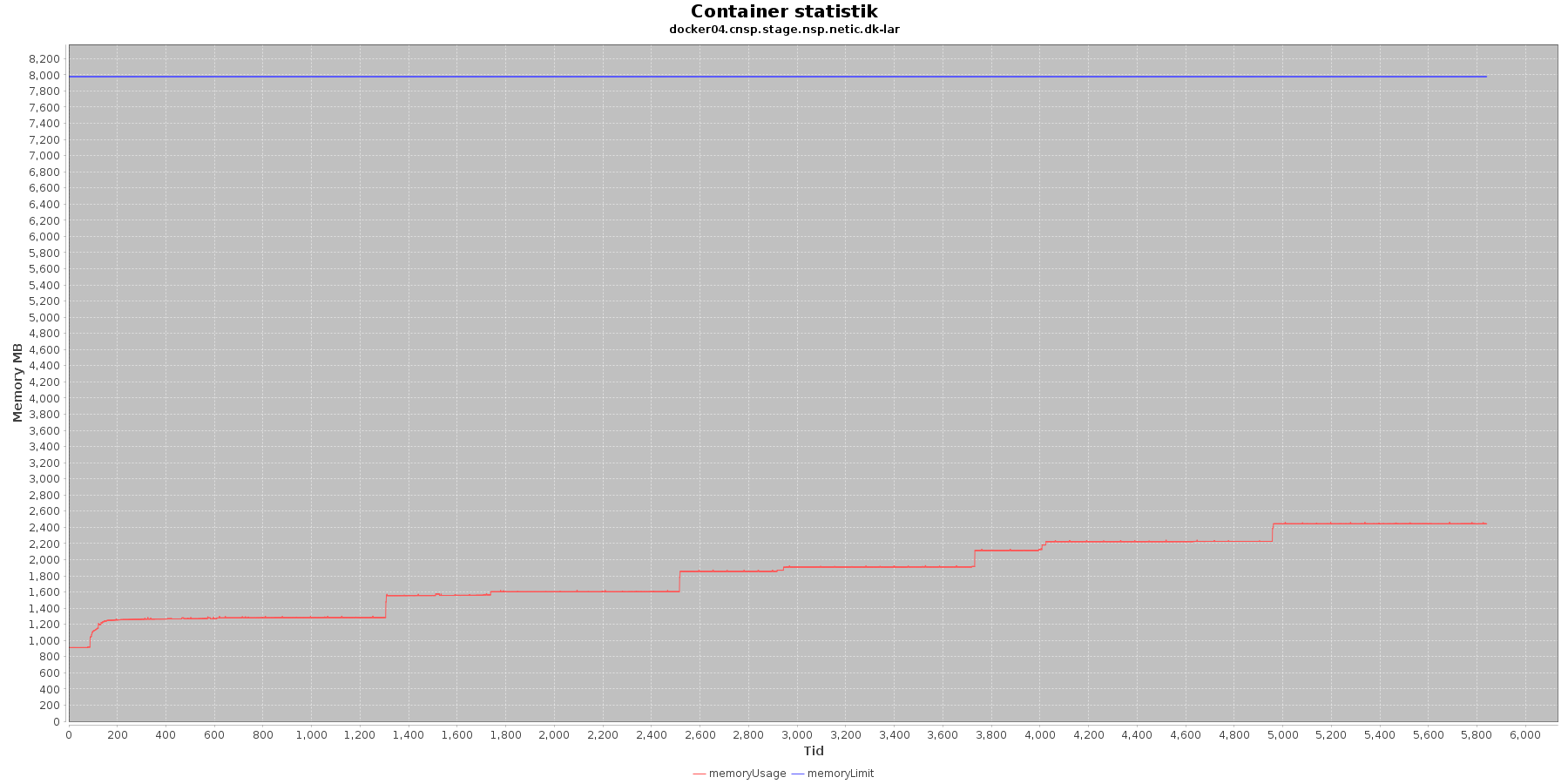
LAR service - Hukommelse:
CAVE service - Hukommelse:
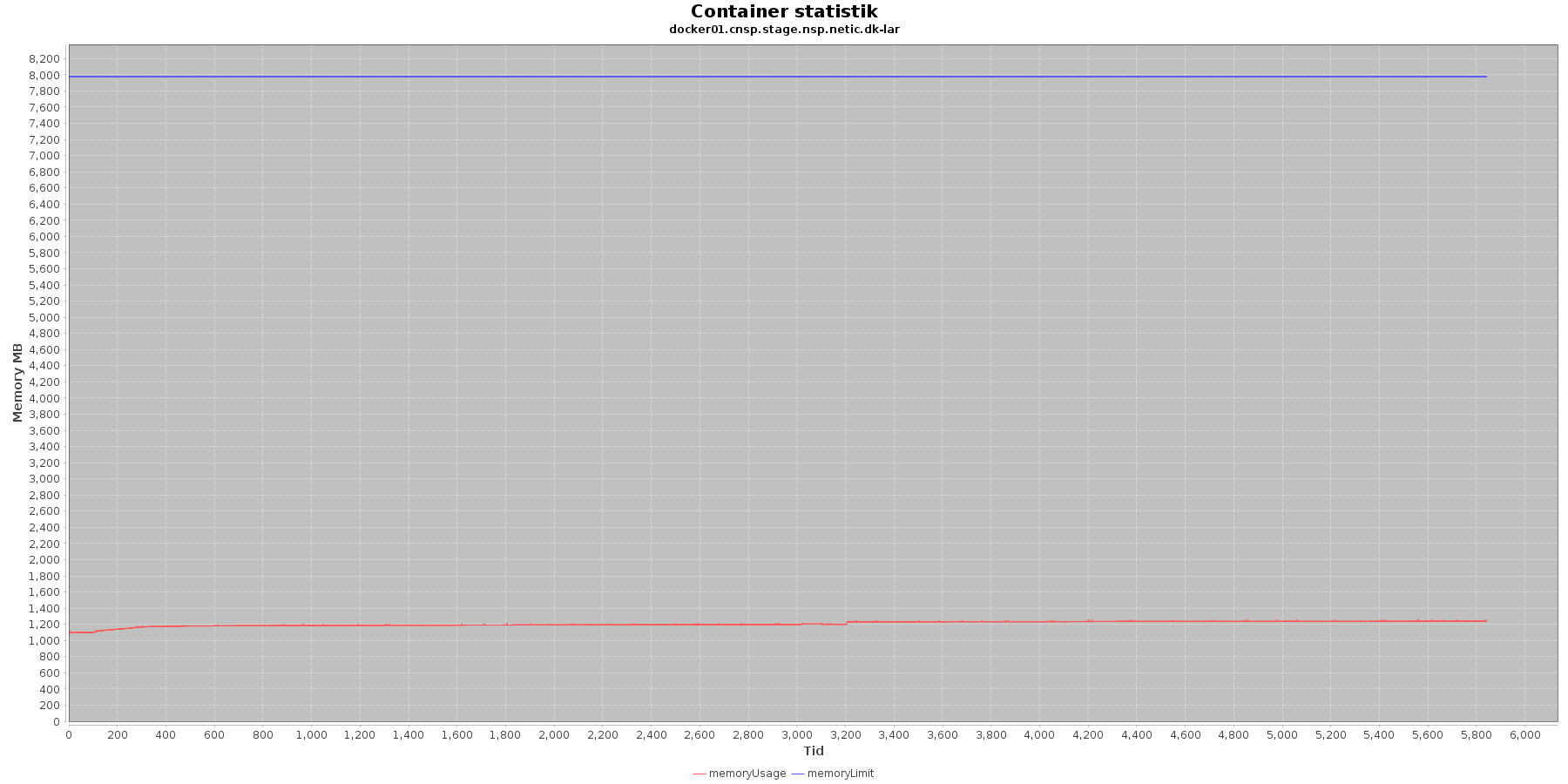
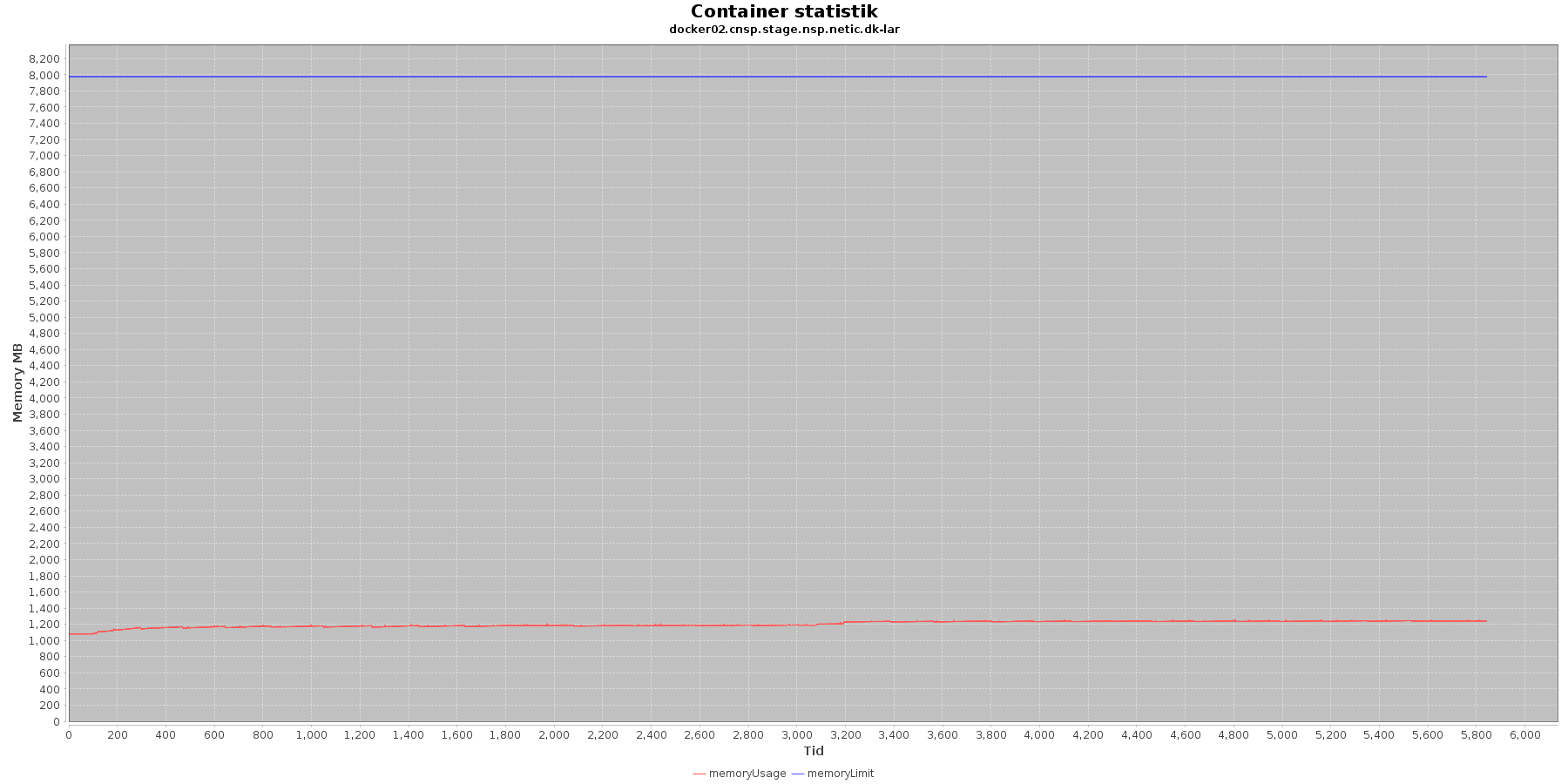
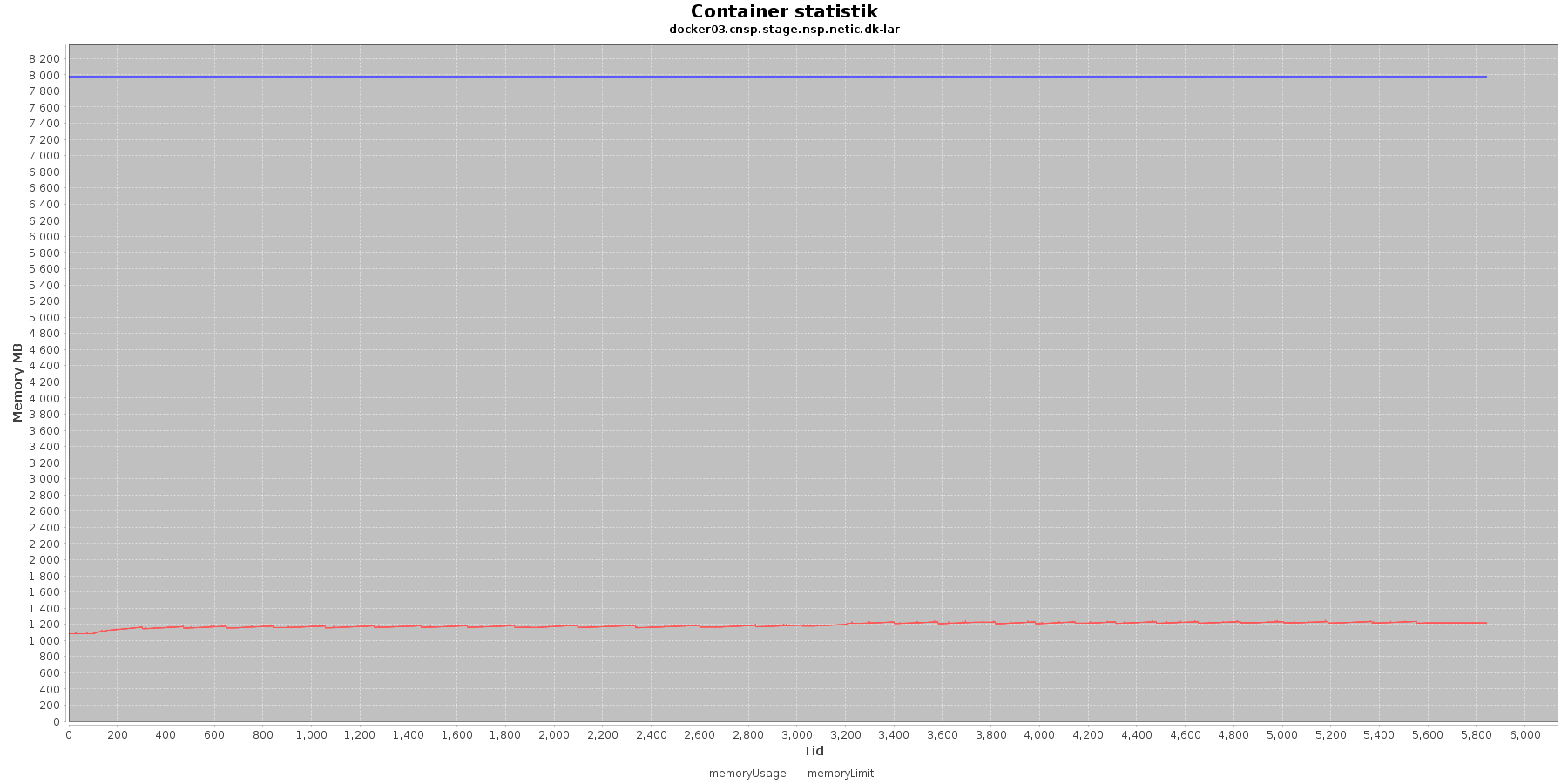
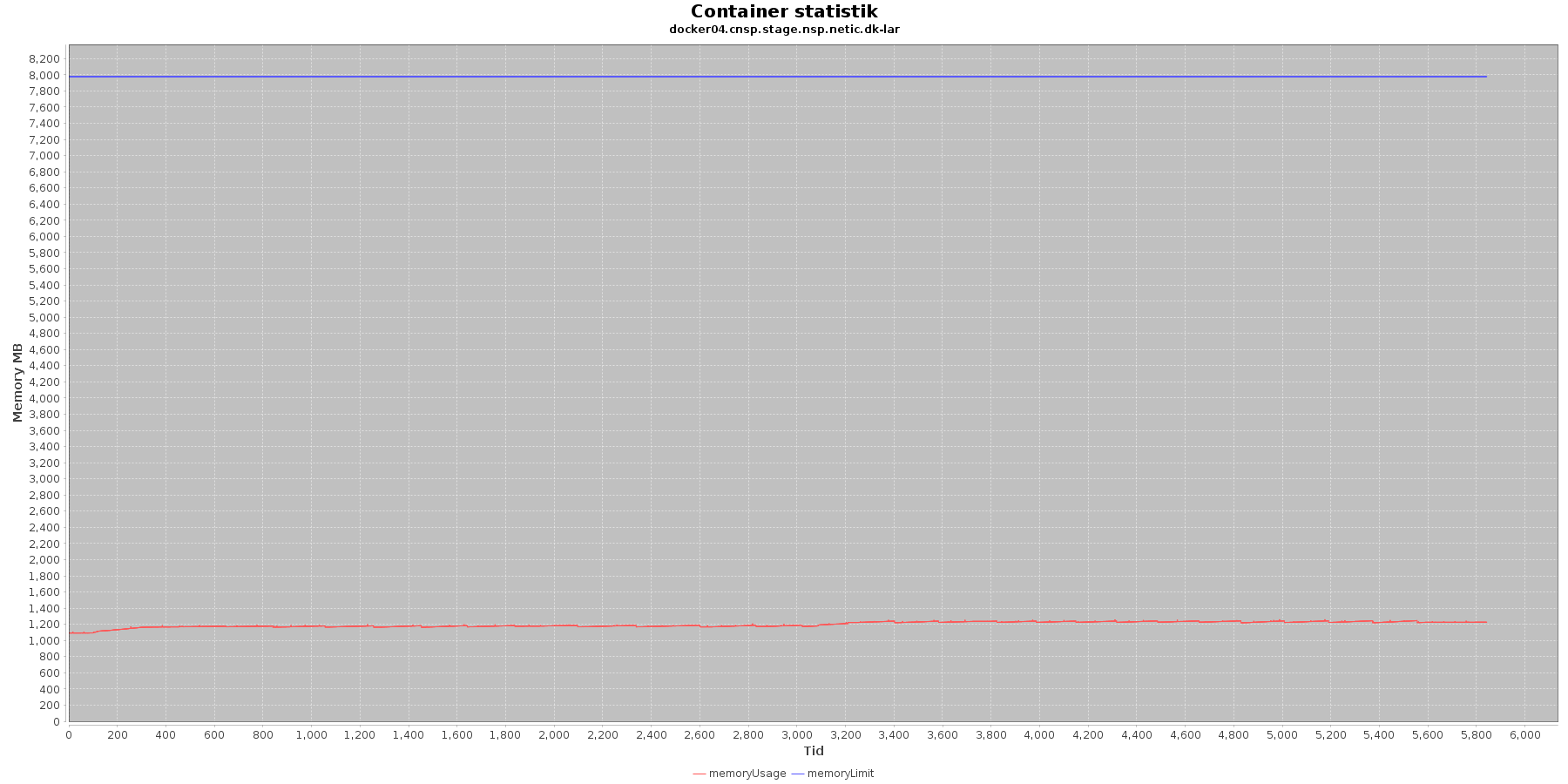
Data serier i grafen er:
- memoryUsage (rød): den totale mængde hukommelse containeren bruger
- memoryLimit (blå): den totale mængde hukommelse contaneren kan bruge
Den forbrugte hukommelse for CAVE servicen er meget stabil. For LAR servicen er den svagt stigende, men da jstat statistikken ikke indikerer at selve applikationen øger forbruget af hukommelse, anses det ikke som et problem.
LAR service - Cpu og hukommelse procent:
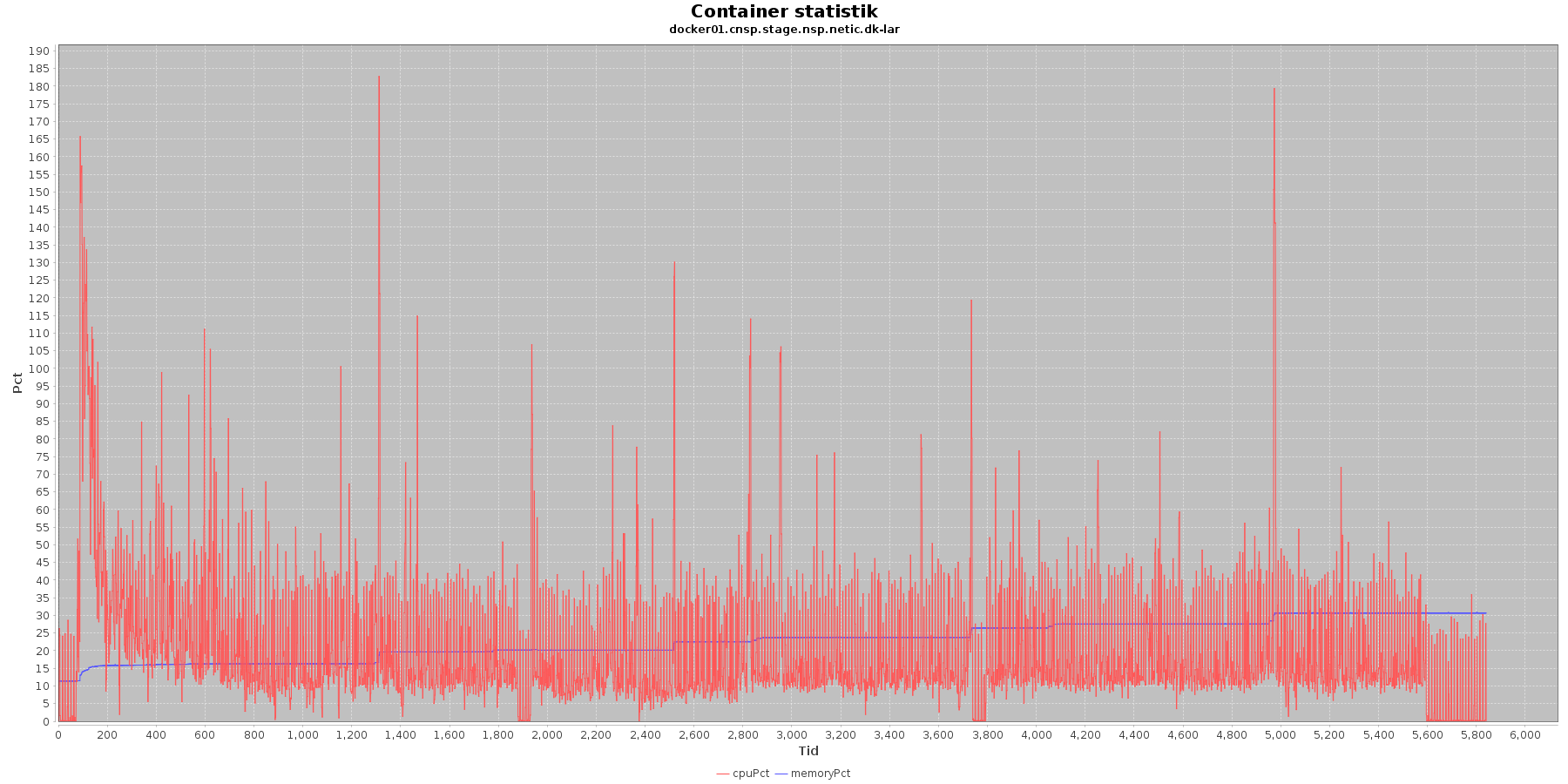
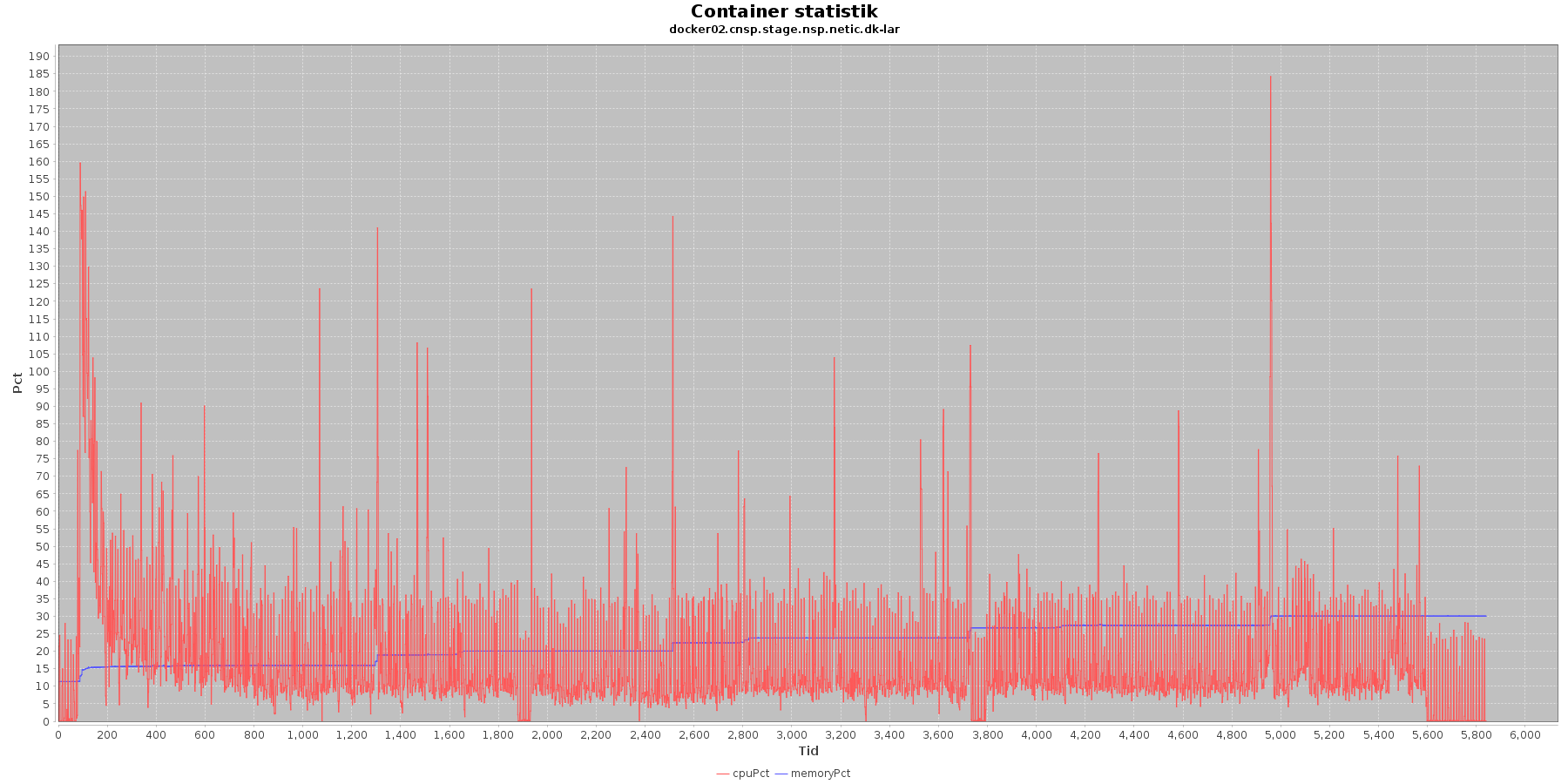
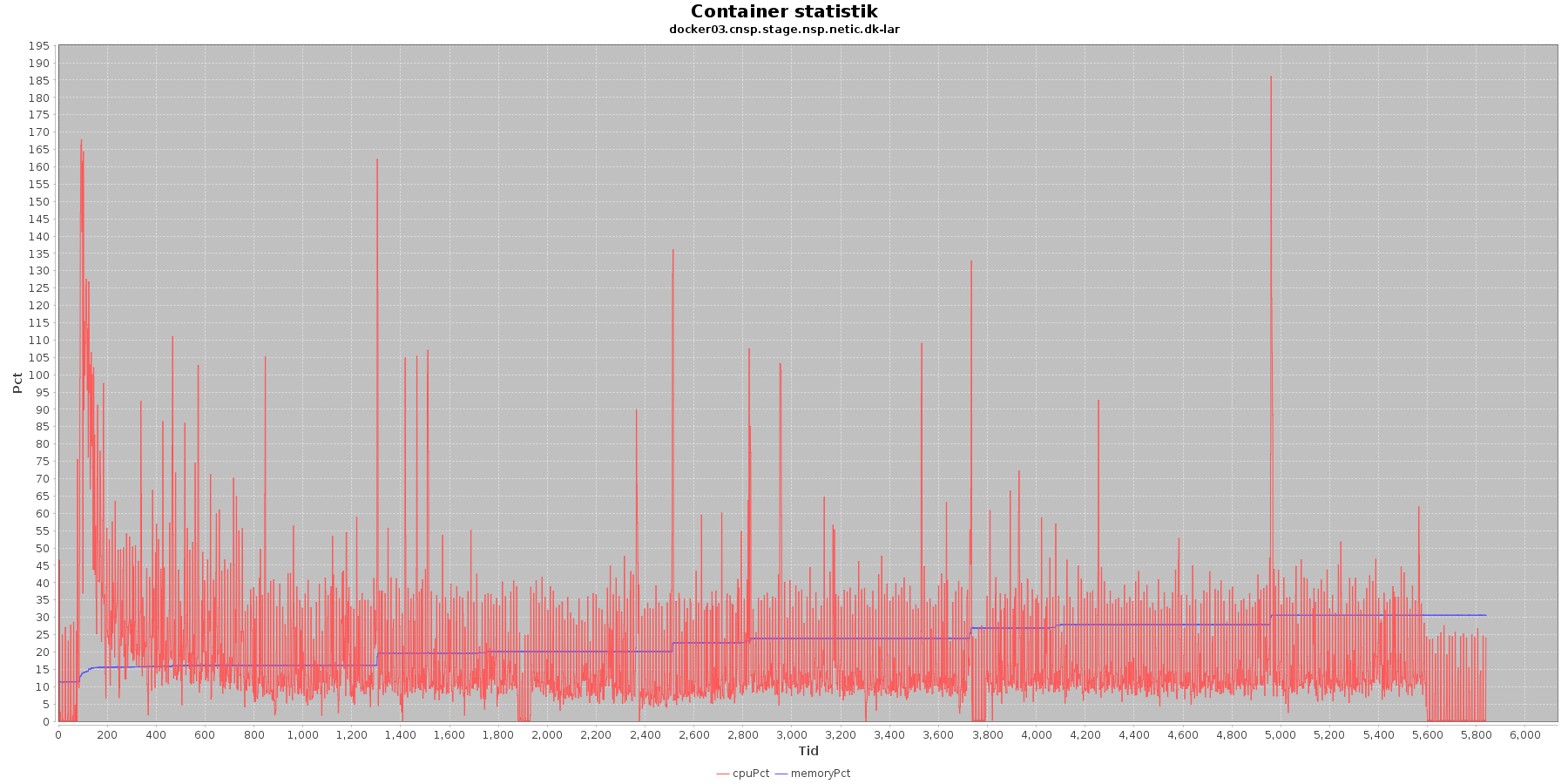
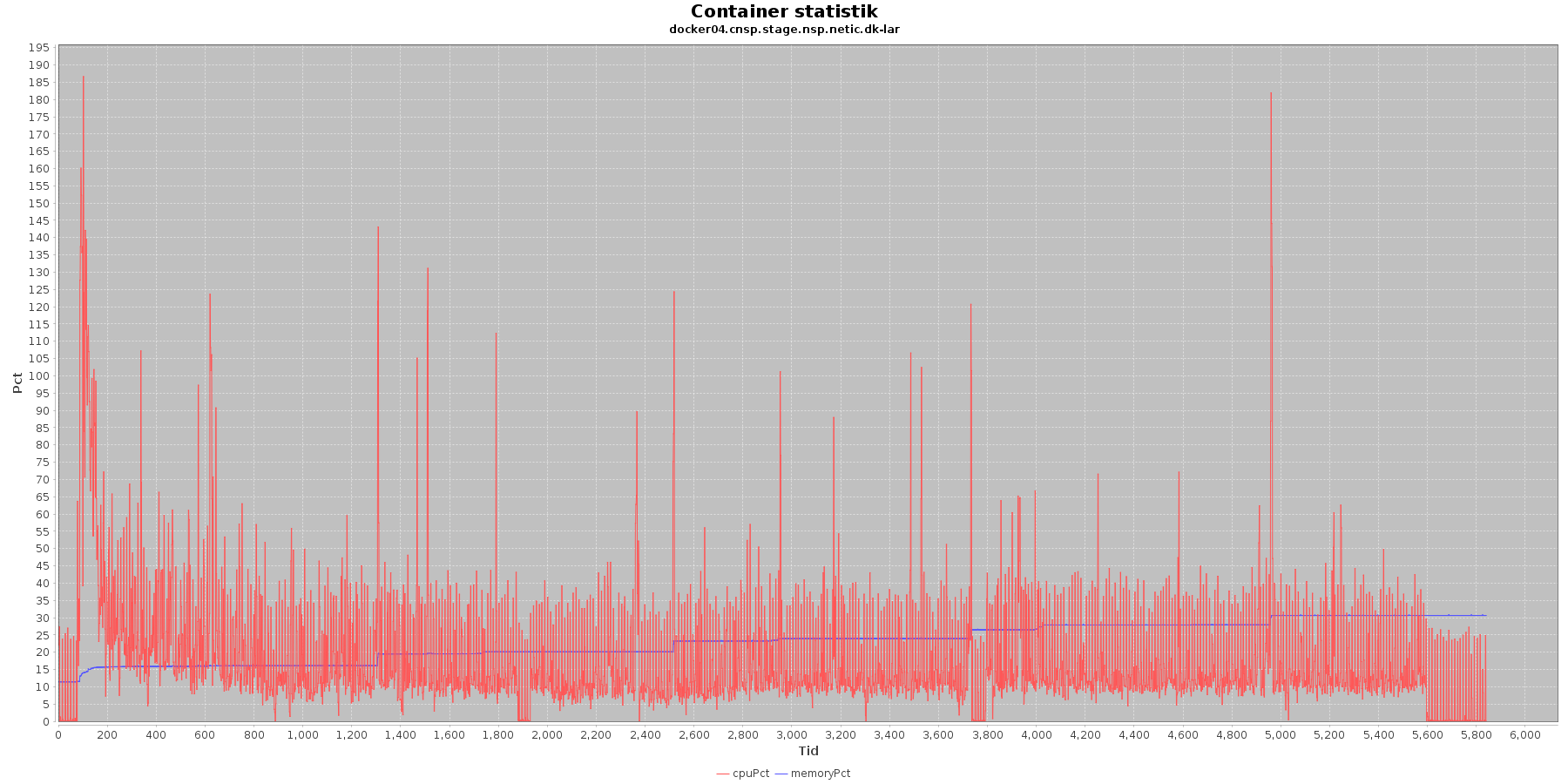
CAVE service - Cpu og hukommelse procent:
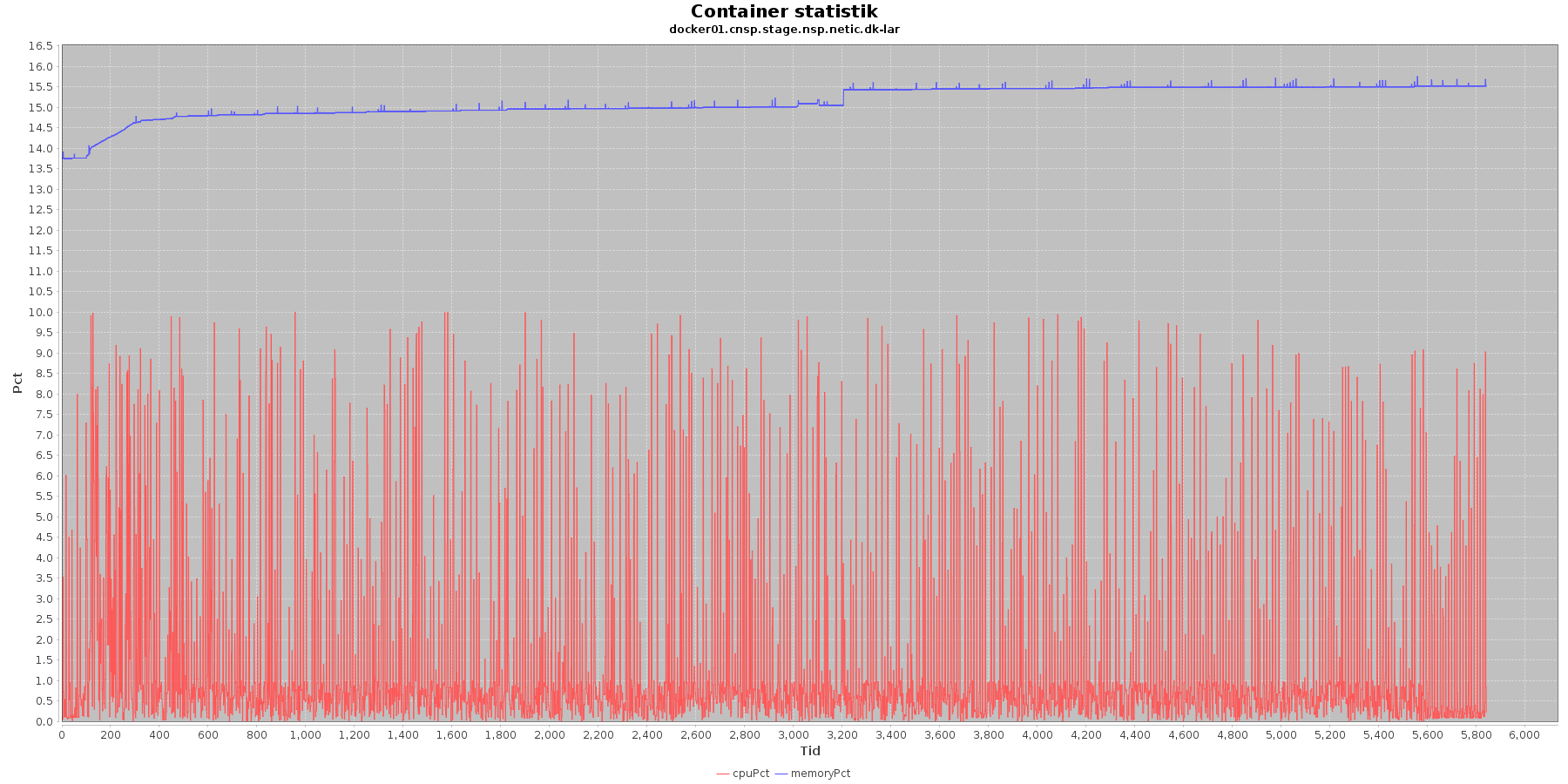
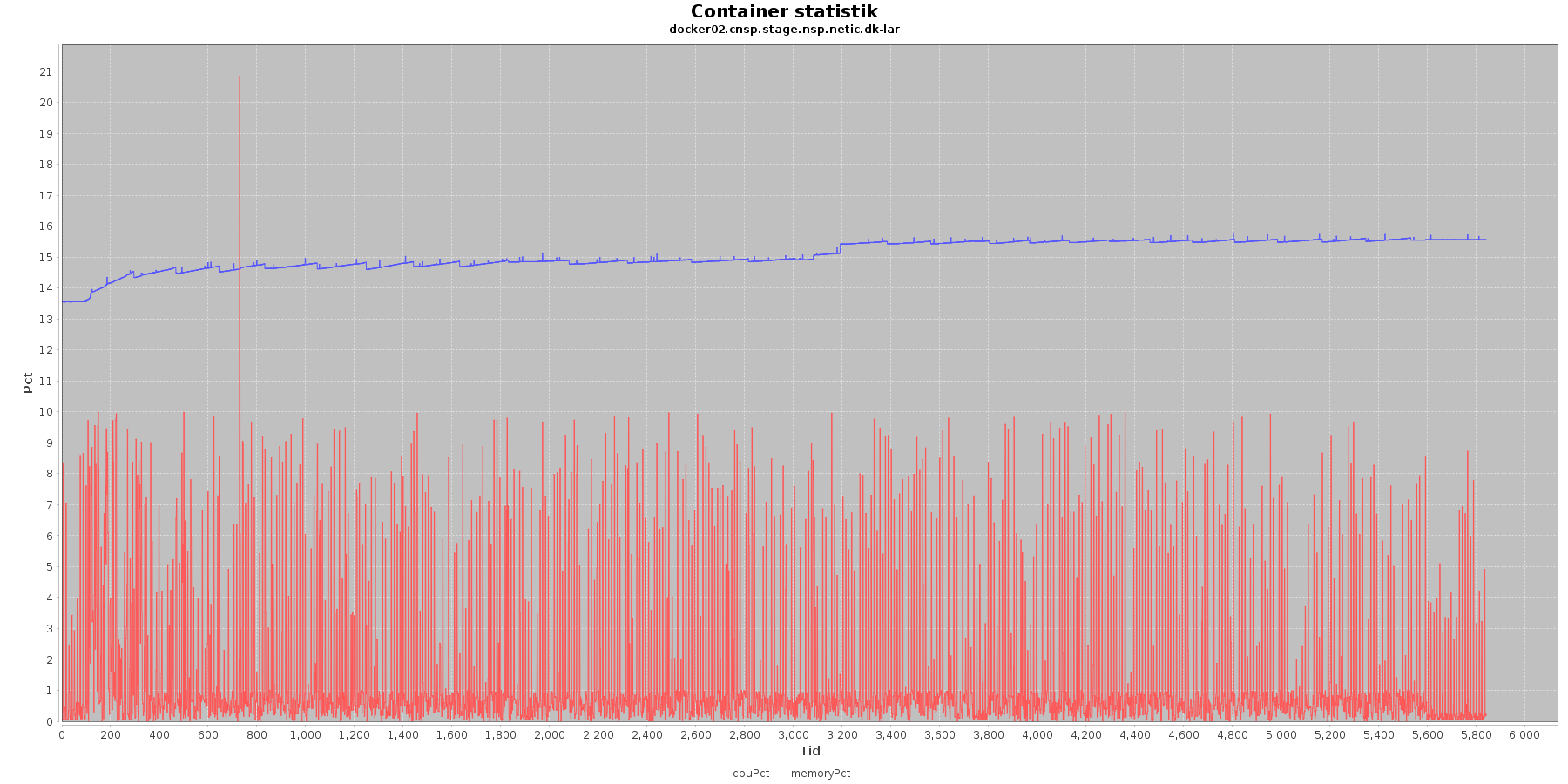
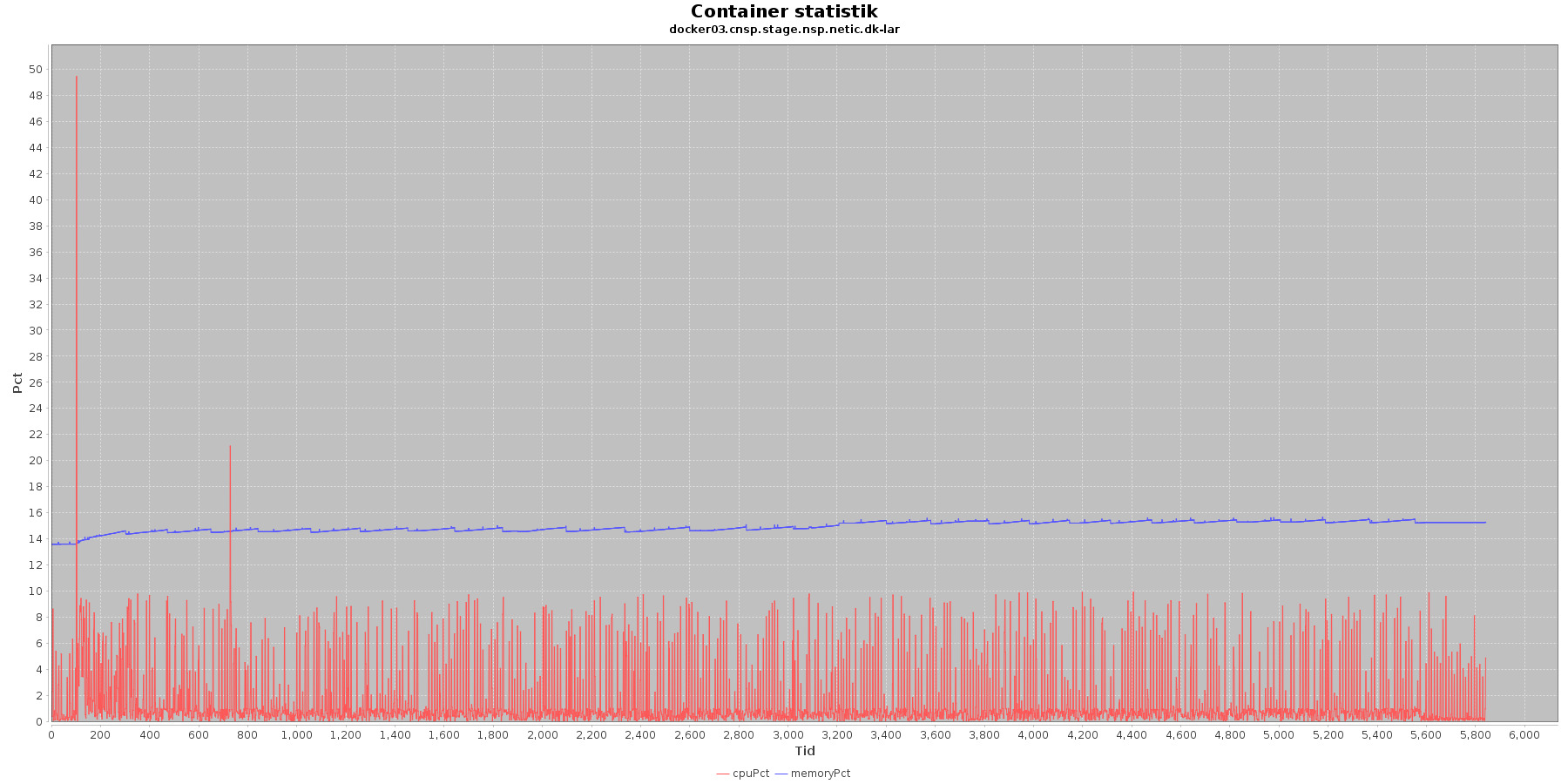
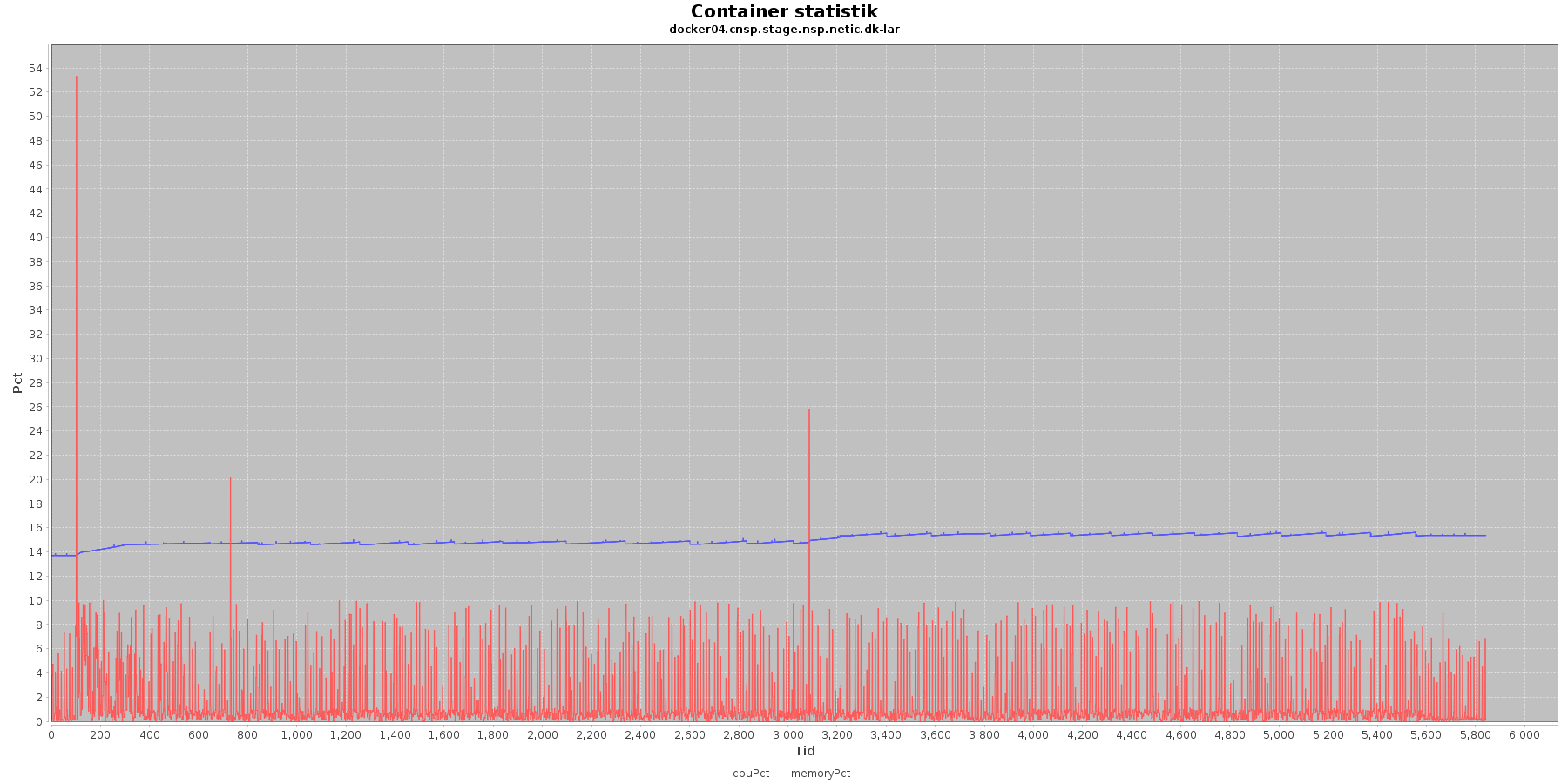
Data serier i grafen er:
- cpuPct (rød): hvor mange procent af hostens cpu containeren bruger
- memoryPct (blå): hvor mange procent af hostens hukommelse containeren bruger
Begge procenter er stabil for CAVE servicen. LAR servicen viser et stigende forbrug af hukommelse, men som skrevet for forrige graf anses det ikke som et problem.
LAR service - netværk:
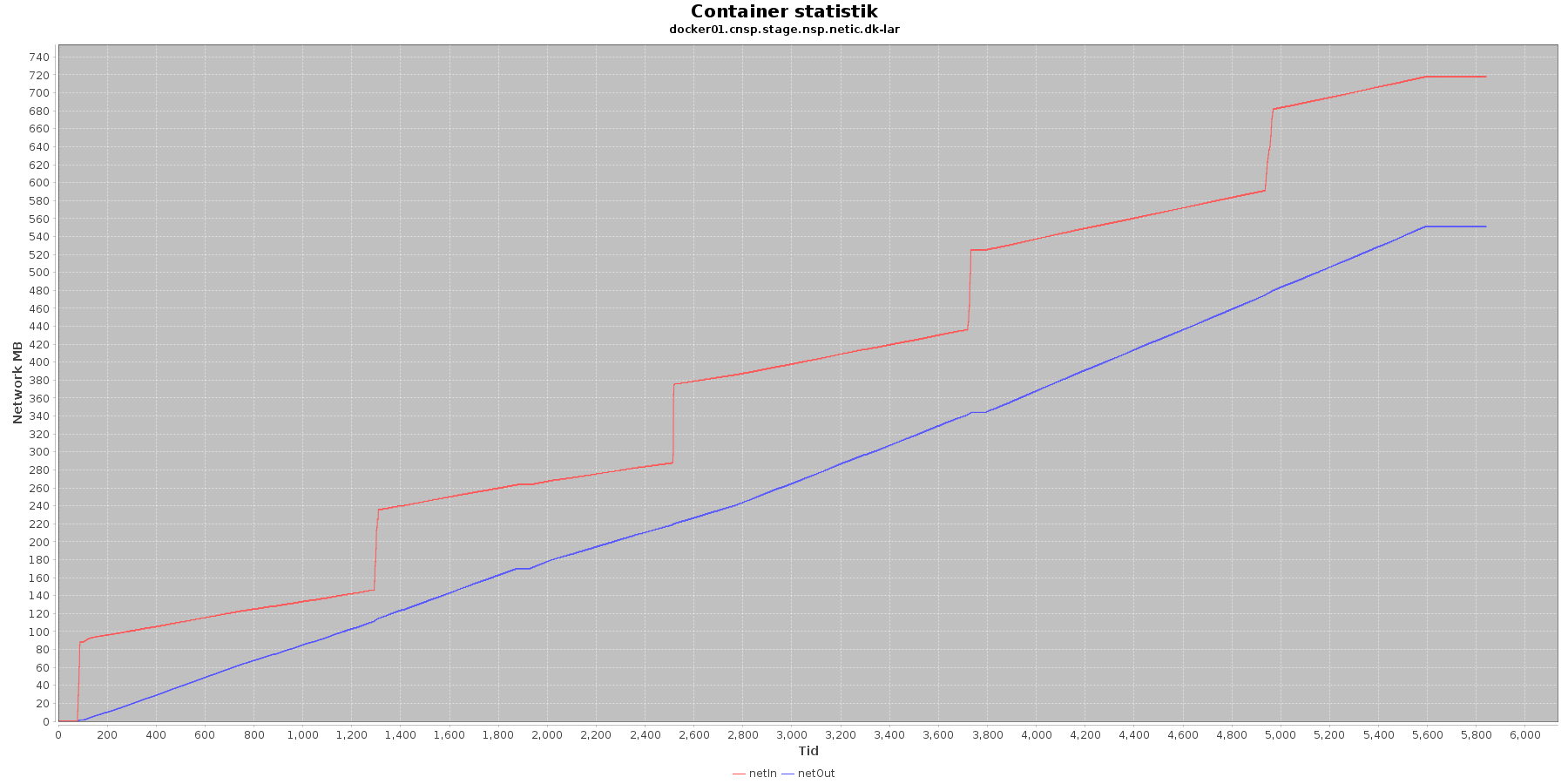
CAVE service - Netværk:
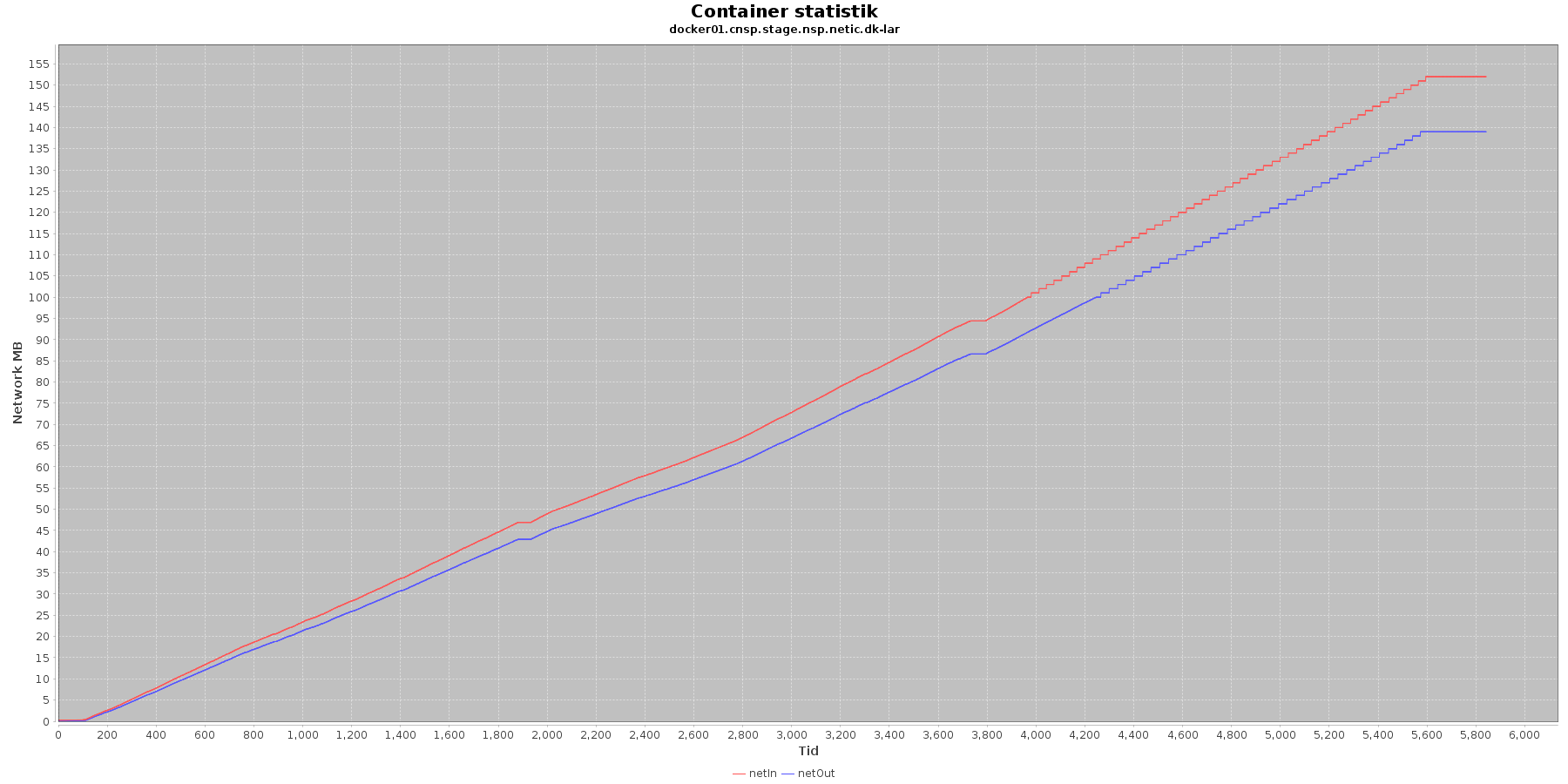
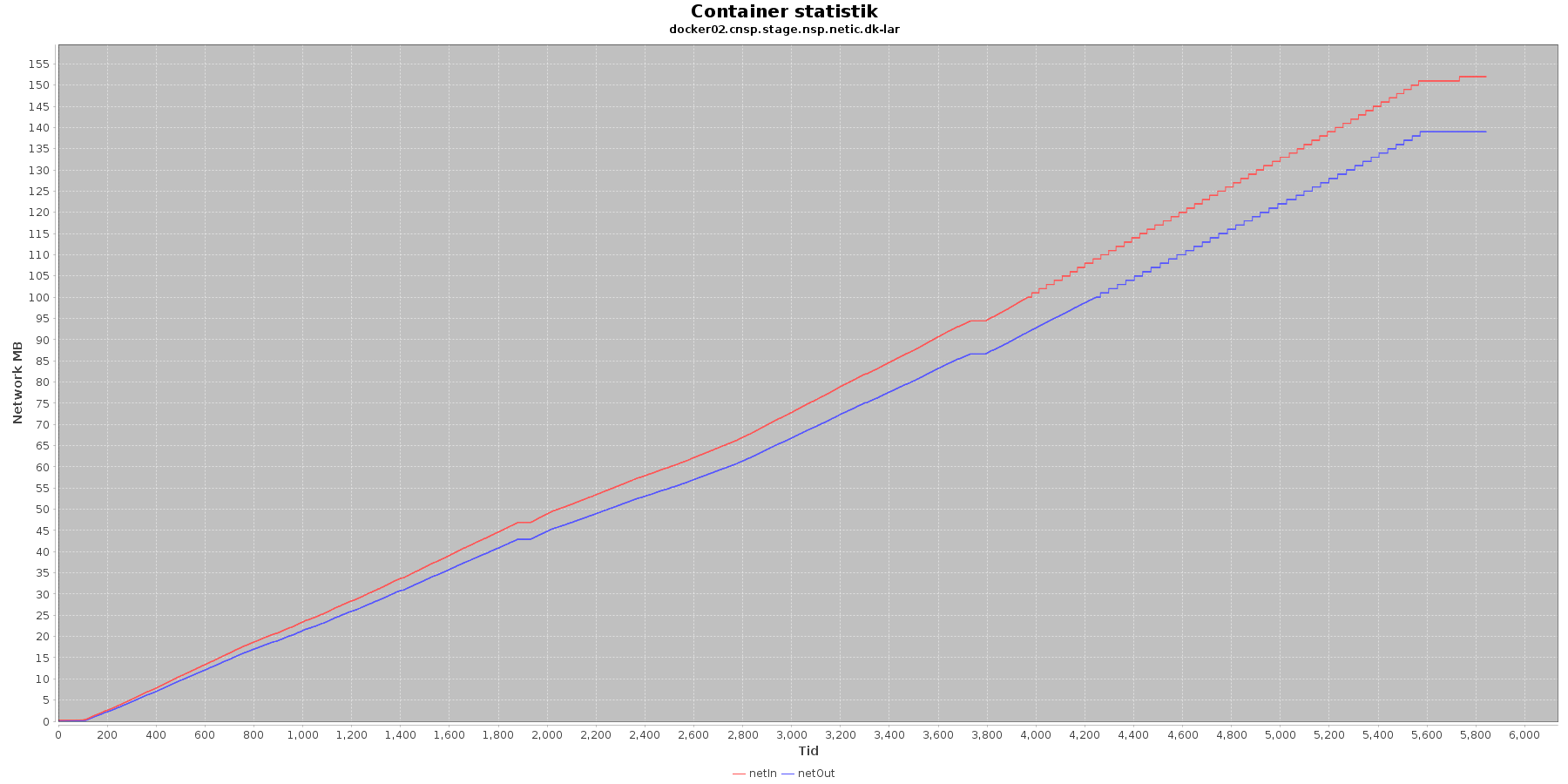
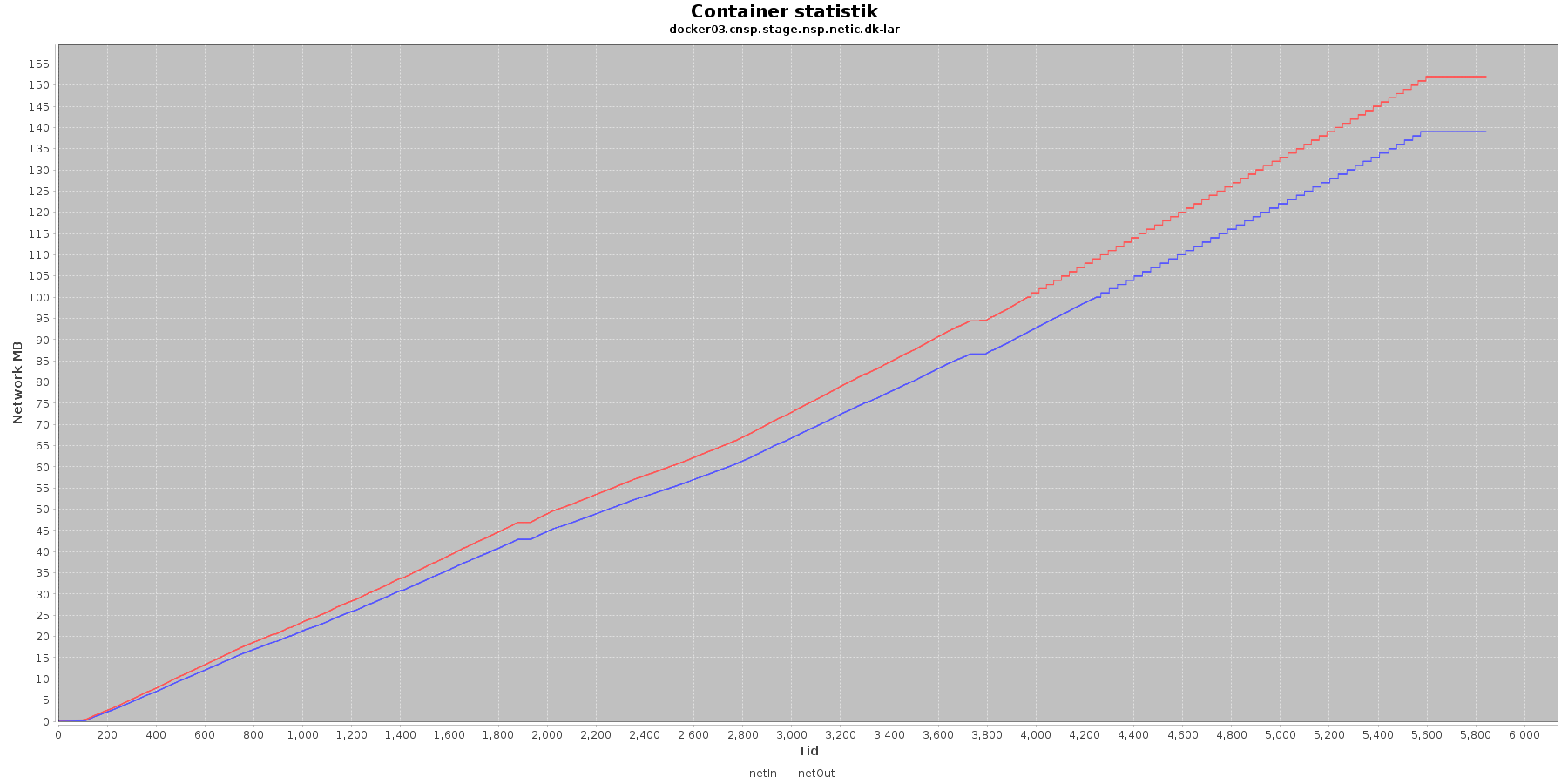
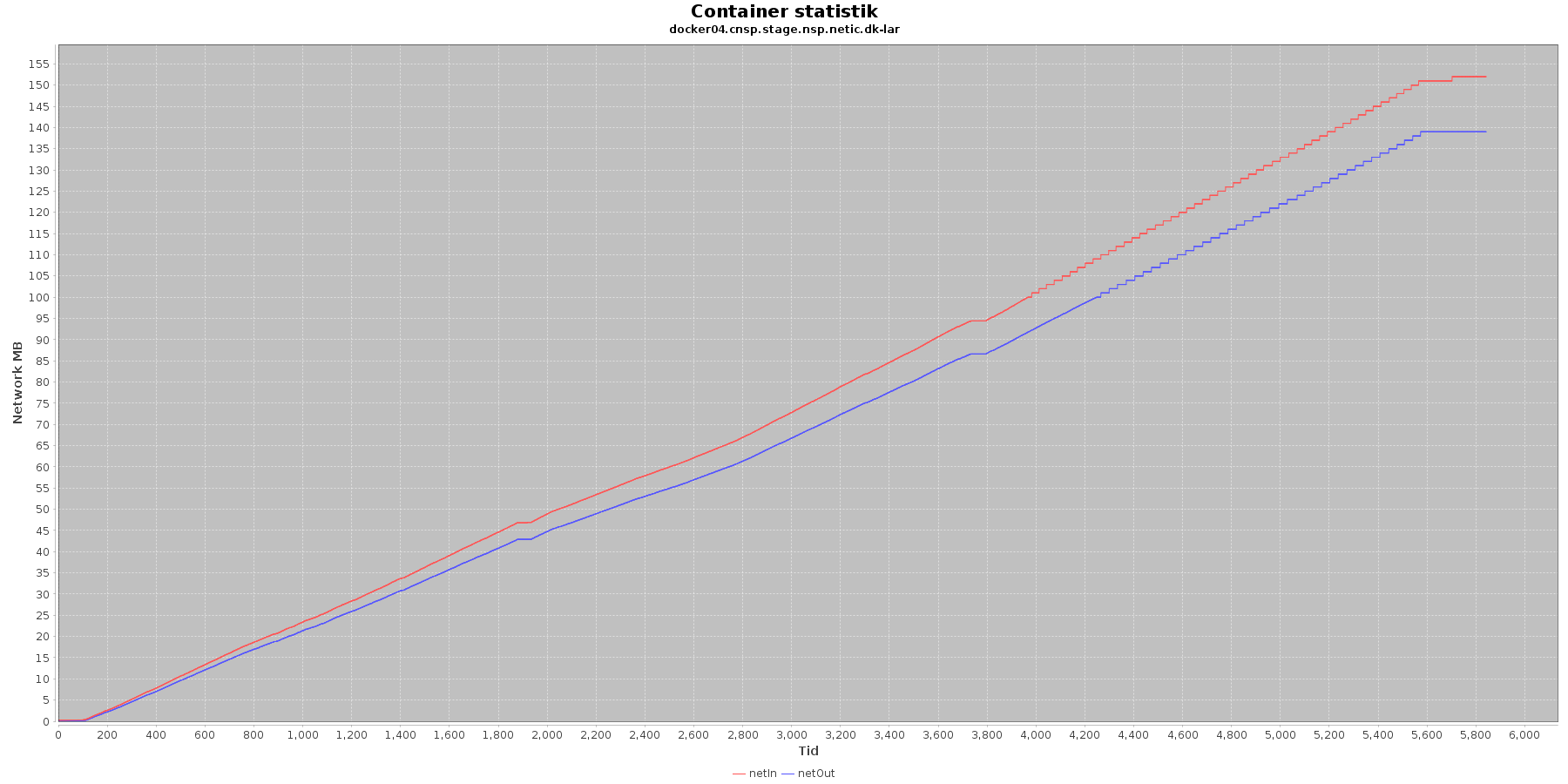
Data serier i grafen er:
- netIn (rød): den mængde data som er modtaget af containeren over netværket
- netOut (bl): den mænde data som er sendt ud af containeren over netværket
De 2 grafer for ind- og udsendt data følges ad, hvilket er forventeligt; LAR kalder videre til CAVE, der kalder videre til database serveren. Når der er trafik ind på LAR og CAVE, må der også nødvendigvis også være trafik ud og videre til database serveren, som er den, der gemmer dataene.
Vurdering
Intet at bemærke.
Konklusion
Efter at have analyseres data fra performance testen kan følgende trækkes frem:
- Svartid per kald til servicen: 155 ms for 2 nodes og 7 tråde, og med et throughput på 20 kald per sekund
Kravet er, at et kald skal tage mindre end 200 ms med 10 brugere der hvert har et kald per sekund
Dette opfyldes, endda under øget belastning med flere nodes og tråde. - Cpu status: for både LAR og CAVE er cpu forbruget konstant over test perioden. Det svinger inden for et interval og rammer aldrig i nærheden af loftet.
- io på netværk: for både LAR og CAVE er der er en jævn strøm af læs og skriv via netværket
- Hukommelses forbrug: både LAR og CAVE håndterer brug af hukommelse fint
- Garbage collection: både LAR og CAVE servicen kører jævnligt garbage collection og dermed stiger hukommelses forbruget ikke over tid. Dette er et tegn på, at vi ikke har memory leaks.
Derudover kan nævnes, at de 3 kald der gik galt under testen og returnerede http 500, fejlede pga. manglende svar fra en af de 3 MSB service kald: Service Unavailable.