1. Introduktion
1.1. Formål
Formålet med dette dokument er at beskrive systemarkitekturen for NXRG.
1.2. Læsevejledning
Nærværende dokument er tiltænkt udviklere og IT-arkitekter med interesse i NXRG og dens opbygning.
1.3. Definitioner og referencer
| NSP | National Service Platform |
| NXRG | NXP XDS Registry (kendt som SDS patientindeks) |
| IHE | Integrating the Healthcare Enterprise (se https://www.ihe.net/) |
2. Overblik over NXRG
I det følgende gives et overblik over NXRG. Først beskrives NXRG i forhold til dennes samarbejdende services og interne arkitektur (modulopdeling etc.)
Efterfølgende beskrives og begrundes den underliggende datamodel.
2.1. Løsningsoverblik
XDS er baseret på, at dokumentkilder i et index registrerer metadata om dokumenter, de kan stille til rådighed. En dokumentanvender kan herefter foretage opslag på indexet og ud fra returnerede metadata, foretage indhentning af dokumenter til efterfølgende visning og/eller udtræk af informationer.
Implementeringen af XDS i NXRG er illustreret i nedenstående model.
* Hver kasse i ovenstående diagram har en kort forklaring, som kommer frem i et nyt browservindue, når der klikkes på kassen.
2.1.1. Samarbejdende services
NXRG samarbejder med følgende komponenter i NSP infrastrukturen:
- Dokumentdelingsservice : DDS anvender den af NXRG udbudte ITI-18 snitflade til at udføre søgninger efter data registreret i NXRG.
- OpenXDS Repository: OpenXDS Repository opbevarer de konkrete dokumenter, der registreres på NSP XDS. OpenXDS anvender NXRGs udbudte ITI-42 snitflade for at få indexeret det metadata, som følger med de konkrete dokumentregistreringer.
- DROS: DROS udbyder registrerings- og opdaterings snitflader ud mod anvendersystemerne. DROS proxy'er kald af ITI-42, ITI-57 og ITI-61 videre til NXRG på de udbudte snitflader.
- Driftsskeduleret oprydning (XDSCleanup): Da dokumentregistreringer kun skal leve i NXRG i begrænset tid (de konkrete regler for opbevaring besluttes af de tilsluttede projekter), skal driften have mulighed for at rydde op (slette) gamle dokumentregistreringer, som ikke længere skal opbevares i NXRG. Der udbydes snitflader til oprydning af NXRG.
- National Adviserings Service (NAS): I forbindelse med opdateringer via ITI-42, ITI-61 og ITI-57 tjekkes det, om der skal sendes udsendes notifikationer for dokumentet.
Diagrammet nedenfor viser både løsningens snitflader og eksterne services, som denne samarbejder med. Derudover vises den NXRGs intern lagdelte opbygning (herunder specificering af ansvarsfordelingen i de forskellige lag i applikation).
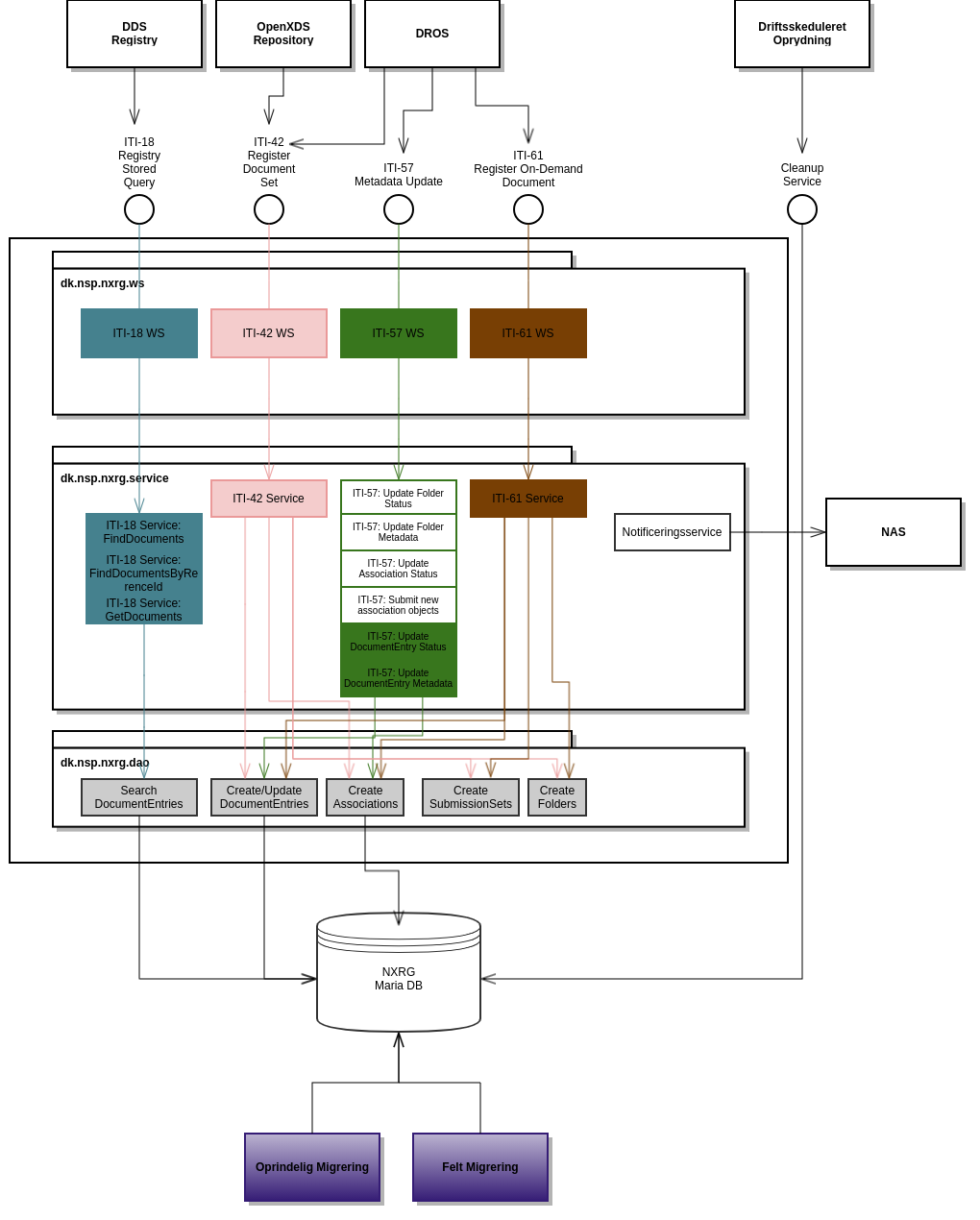
NXRG er opbygget i en lagdelt arkitektur. I ovenstående diagram er pakkenavne specificeret og giver en kobling til den konkrete sourcekode, der realiserer NXRG (se i øvrigt NXRG/SDS Patientindex - Guide til Udviklere).
2.1.2. Snitflader
De udbudte snitflader er realiseret som SOAP webservices (dk.nsp.nxrg.ws). ITI-XX snitfladerne er specificeret i IHE XDS revision 17 fra juli 2020.
Se følgende:
- ITI TF-1: IHE IT Infrastructure Technical Framework Volume 1 (ITI TF-1) Integration Profiles (Revision 17.0 – Final Text)
- ITI TF-2a: IHE IT Infrastructure Technical Framework Volume 2a (ITI TF-2a) Transactions Part A (Revision 17.0 – Final Text)
- ITI TF-2b: IHE IT Infrastructure Technical Framework Volume 2b (ITI TF-2b) Transactions Part B (Revision 17.0 – Final Text)
- ITI TF-3: IHE IT Infrastructure Technical Framework Volume 3 (ITI TF-3) Cross-Transaction Specifications and Content Specifications (Revision 17.0 – Final Text)
- ITI TF-Metadata: IHE IT Infrastructure Technical Framework Supplement XDS Metadata Update Rev. 1.11 – Trial Implementation July 12, 2019
Til at realisere disse ITI-XX snitflader anvendes tredjeparts biblioteker fra IPF Open eHealth Integration Platform til implementations- og hjælpeklasser (herunder mapning af XML baseret model til domænemodel).
2.1.3. Forretningslag
Forretningsregler i relation til de udbudte ITI-XX services er implementeret udfra specifikationen af IHE XDS (dk.nsp.nxrg.service). For ITI-18 er det besluttet ikke at understøtte samtlige querytyper, der fremgår af specifikationen, men at nøjes med følende:
- FindDocuments
- FindDocumentsByReferenceId
- GetDocuments
Kald af ITI-18 med andre querytyper vil resultere i en fejlkode fra NXRG (se NXRG/SDS Patientindex - Guide til Anvendere).
2.1.3.1. Validering af forespørgler og svar
Forespørgsler og svar valideres efter reglerne beskrevet i IHE XDS specifikationen. Mere præcist udføres validering som beskrevet i følgende afsnit:
- ITI-18: Afsnit 3.18.4 (Se ITI TF-2b).
- ITI-42: Afsnit 3.42.4 (Se ITI TF-2b).
- ITI-57: Afsnit 3.57.4 (Se ITI TF-Metadata).
- ITI-61: Afsnit 3.61.4 (Se ITI TF-2b).
2.1.3.1.1. Validerings opsætning
Open eHealth frameworket, der anvendes af både OpenText og NXRG, stiller muligheden for validering af request og responses til rådighed. Det er denne validering, som i stor udstrækning anvendes som validerings mekanisme i NXRG.
Både NXRG og Open Text har det som konfiguration, om sådanne valideringer skal udføres i forbindelse med forespørgsel og svar (request/response) og for de forskellige typer kald (ITI-42, ITI-61, ITI-57 og ITI-18).
Følgende tabel viser, hvordan denne konfiguration af validering er sat op for nuværende NXRG og tidligere anvendte Open Text:
|
|
NXRG generelt | Open Text - Test 1 | Open Text - Test 2 | Open Text - Produktion | ||||
|---|---|---|---|---|---|---|---|---|
|
|
Request | Response | Request | Response | Request | Response | Request | Response |
| ITI-42 |
|
|
Disabled |
|
Disabled |
|
Disabled |
|
| ITI-61 |
|
|
Disabled |
|
Disabled |
|
Disabled |
|
| ITI-57 |
|
|
|
|
|
|
|
|
| ITI-18 |
|
|
Disabled |
|
Disabled | Disabled | Disabled |
|
2.1.3.1.2. Sammenligning af patientId'er
Ved validering af forespørgsler skal der sammenlignes patientId'er. Ifølge specifikationen skal denne sammenligning tage højde for sammensmeltning af patientId'er (This comparison shall take into consideration patient identity merges as described in ITI TF-2a: 3.8.4.2.4.). I NXRG er det antaget, at denne form for sammensmeltning ikke forekommer, og sammenligning af patientId'er er derfor implementeret ved simpel strengsammenligning.
2.1.3.1.3. Validering af ITI-18 fremsøgning response
Da Open Text var registry, var der ikke request (input) validering på oprettelses kalende (ITI-42 og ITI-61). Derfor er der herfra fejlbehæftet metadata, som ikke overholder IHE standarden. Når der laves en fremsøgning (ITI-18), og bare eet af disse dokumenter er imellem, vil kaldet gå i fejl, og ingen af dokumenterne blive returneret.
For at undgå denne situation er, er der i NXRG lavet sådan, at hvert dokuments metadata, der returneres fra fremsøgningen, valideres for sig selv. De dokumenter, som fejler i valideringen, returneres ikke i resultatsættet. Der indsættes istedet for disse en fejl linie i svaret, ligesom dokumentet logges til applikations loggen. Dokumentet identificeres her ved entryUuid. Er der sådanne frasorteringer i fremsøgning sættes status til Partial success, og hvis alle fremsøgte dokumenter frasorteres sættes status til Failure.
2.1.4. Databaselag
NXRG har behov for at persistere data i en database. NXRGs datamodel er realiseret udfra følgende principper:
- Muligt at udvide med nye querytyper, hvis dette skulle ønskes senere
- Muligt at implementere en passende migreringsstrategi for data i det gamle NSP XDS Registry uden tab eller forvansking af data
For en detaljeret beskrivelse af databasemodellen se afsnittet nedenfor.
2.1.5. XDSCleanup service
De data, der opbevares i NXRG, skal slettes efter noget tid. Hvor lang tid der er tale om, kommer an på typen af data. Til at afgøre denne klassifikation anvendes metadata-attributten typeCode (den består af to komponenter: en typeCode-kode og en typeCode-scheme) på DocumentEntry.
Foreløbigt gælder følgende regler:
- Aftaledokument (Typekode: 56446-8): Skal slettes efter 2 år
Sletning varetages af den separate service XDSCleanup. Der henvises til dokumentationen for denne service for en beskrivelse af reglerne for, hvordan og hvornår sletning af dokumentmetadata finder sted.
2.1.6. Eksterne services
Der er i dag eksterne services, der tilgår OpenText Registry direkte (dvs udenom de i forgående afsnit skitserede NSP services).
Det drejer sig om følgende:
- KIH Repository
De fleste andre eksterne services (f.eks. PLSP, Bookplan, Laboratoriesvarportalen) udbyder data ved selv at udstille XDS Registry+XDS Repository snitflader, som Dokumentdelingsservicen så integrerer med. Ændringer i det nationale registry vil ikke berøre disse typer.
2.1.6.1. KIH Repository
KIH databasen (repository) indeholder dokumenter af typerne PHMR og QRD dvs hjemmemålinger og spørgeskemabesvarelser. KIH Repository anvender det nationale registry til at få indexeret disse dokumenter og gøre dem søgbare via Dokumentdelingsservicen.
KIH databasen kalder således ITI-42 på det nationale registry. Der er to muligheder i fremtiden:
- KIH kalder direkte på NXRG ITI-42: Denne løsning er tilsvarende det, der sker i dag
- KIH kalder DROS ITI-42: DROS ventes at komme til at indeholde valideringer, der vil øge kvaliteten af de metadata, der i sidste ende havner i det nationale registry. Ved at lade KIH anvende denne snitflade vil KIH metadata blive underlagt samme valideringer. NB ITI-42 på DROS findes både i en DGWS og en ikke-DGWS (IP whitelisting eller SDN aftale) udgave. For KIHs vedkommende vil det være relevant at kalde ikke-DGWS snitfladen for at undgå snitfladeændringer.
Inden driftsstart for NXRG skal det afklares, hvilket af de to punkter ovenfor, der ønskes.
Derudover skal der udarbejdes en plan i samarbejde med Medcom om, hvordan det skal foregå.
2.2. Afvigelser fra IHE XDS standarden
I forhold til NXRG, så er det ikke hele IHE XDS specifikationen, der implementeres. I de følgende afsnit dokumenteres evt. fravalg og beslutninger ved de enkelte services.
2.2.1. ITI-18: Registry Stored Query
I forhold til fremsøgning, så er det besluttet, at følgende query typer skal understøttes:
- FindDocuments
- FindDocumentsByReferenceId
- GetDocuments
Dog forholder det sig sådan, at "FindDocumentsByReferenceId" ikke understøttes af DDS'en og dermed kan den i praksis ikke kaldes. Der anses ikke for nuværende behov for at ændre dette.
Når man laver en fremsøgning med ITI-18, kan man få to typer af objekter tilbage, baseret på den retur type man sætter i kaldet.
- LeafClass: her returnes en liste af matchende documentEntry med fuld metadata
- ObjectRef: her returnes en liste af objekt referencer, som entryuuid
En måde at fremsøge meget store datamængder på, kan derfor laves med først en fremsøgning retur type ObjektRef og efterfølgende anvende disse værdier til at lave en GetDocuments med retur typen LeafClass.
DDS'en understøtter dog ikke "ObjectRef" retur typen, og der anses ikke for nuværende behov for at ændre dette. En detalje ved returnering af objekt referencer er, at man ikke vil kunne lave spærringer på dokumenter alene på disse. Men det vil kunne ske efterfølgende når id'erne anvendes i en GetDocuments og metadata faktisk hentes frem.
2.2.2. ITI-57: Update Document Set
Specifikationen beskriver i afsnit "3.57.4.1.3.4 Patient ID Reconciliation", hvordan det skal håndteres, hvis patient-id opdateres som en del af et kald til ITI-57. I forhold til NXRG, så har vi valgt, at denne ikke skal understøtte dette, hvorfor et forsøg på ITI-57 kald, hvor patient id opdateres vil resultere i en fejl til anvenderen.
Patient ID Reconciliation vil resultere i øget kompleksitet i NXRG, og anvendere vil kunne opnå det samme ved f.eks. at deprecate eksisterende data på en patient, og dernæst oprette data på en anden.
Derudover vil anvendelsen af NXRGs ITI-57 service ikke foregå direkte men via DROS - Guide til anvendere. I forhold til auditlogning og diverse tjek, så er de fleste NSP anvender services tænkt til en brug, hvor der er netop én patient i kontekst ad gangen.
Vi vurderer, at skift af patient ID vil skabe øget unødvendig kompleksitet i de anvenderrettede services.
2.3. Andet væsentlige at notere for design af NXRG
2.3.1. ITI-57 Update metadata
Dette kald tillades ikke for OnDemand dokumenter. Det anvendte biblioteks fra Open eHealth afviser typen OnDemand i forbindelse med opdatering af metadata. Det fungerer sådan for både Open Text registry og NXRG.
2.3.2. ITI-61 replace document
Dette kald opfører forskelligt for Stable og OnDemand dokumenter. Ved replace af Stable dokument deprecates de gamle dokument. Dette sker ikke for onDemand dokumenter. Der er i ovenstående specifikationen ikke nævnt noget med status ændring for OnDemand Det fungerer sådan for både Open Text registry og NXRG.
2.3.3. ITI-42 Register document set
For dette kald, tillades 'replay' requests. Dvs. hvis servicen modtager to gyldige identiske requests, vil den i begge tilfælde give succes svar, selvom dataen kune gemmes første gang.
To requests anses dog kun som identiske hvis alle elementer har et gyldigt entry uuid. Hvis ikke, genererer servicen nye entry uuid'er, og de to requests bliver dermed forskellige.
2.3.4. Håndterede type koder (type codes)
NXRG kan konfigureres med en liste af type codes, sådan at en instans håndtere en eller flere type koder. Dette resulterer i følgende opførsel
- ITI-18 Registry Stored Query: hvis typecode indgår i søge parametrene og ingen af dem håndteres, returneres et tomt kald. Ellers udføres søgningen.
- ITI-42 Register document set: hvis typecode indgår i dokumentets metadata (documententry) og den ikke håndteres afvises kaldet med en fejl.
- ITI-61 Register on demand document: hvis typecode indgår i dokumentets metadata (documententry) og den ikke håndteres afvises kaldet med en fejl.
- ITI-57 Update metadata: hvis typecode indgår i dokumentets metadata (documententry) og den ikke håndteres afvises kaldet med en fejl.
2.4. Databasemodel
Modellen nedenfor viser to databaser: Metadata, som er den database der vedligeholdes og ejes af NXRG, og Dokumenter, som er den database der vedligeholdes og ejes af OpenXDS.
xDB indeholder således metadata for det centrale registry, hvorimod mariaDB indeholder dokumenterne i repository.
* Hver kasse i ovenstående diagram har en kort forklaring, som kommer frem i et nyt browservindue, når der klikkes på kassen.
Datamodellen er opbygget med udgangspunkt i følgende overordnede principper:
- Understøtte MVP: NXRG er startet som et Minimal Viable Product med intentionen om senere at kunne skifte til et andet mere modent produkt. Dette betyder, at modellen ikke skal være mere kompliceret, end højst nødvendigt.
- Kunne understøtte udvidelser af NXRG: Selvom kravene (MVP) fra starten er begrænsede, så giver det mening at overveje, at det skal være muligt at udvide NXRG f.eks. med flere ITI-18 query typer. Datamodellen skal i denne sammenhæng være robust over for denne slags ændringer (dvs det skal være velforstået, hvad sådanne udvidelser betyder i forhold til databasemodellen).
- Understøtte migrering: Da en væsentlig del af MVP indeholder migrering af data fra OpenText Registry til NXRG, så skal databasemodellen være lavet på en måde, således at migreringen er understøttet.
- Driftsvenlig: Det skal være muligt for driften at foretage opgaver i forbindelse med support og drift (f.eks. oprydningsjob)
I det følgende beskriver vi datamodellen for NXRG og beskriver, hvorledes ovenstående principper er respekteret. Datamodellen præsenteres først i overbliksform i nedenstående E/R-diagram, og de enkelte tabeller beskrives derefter.
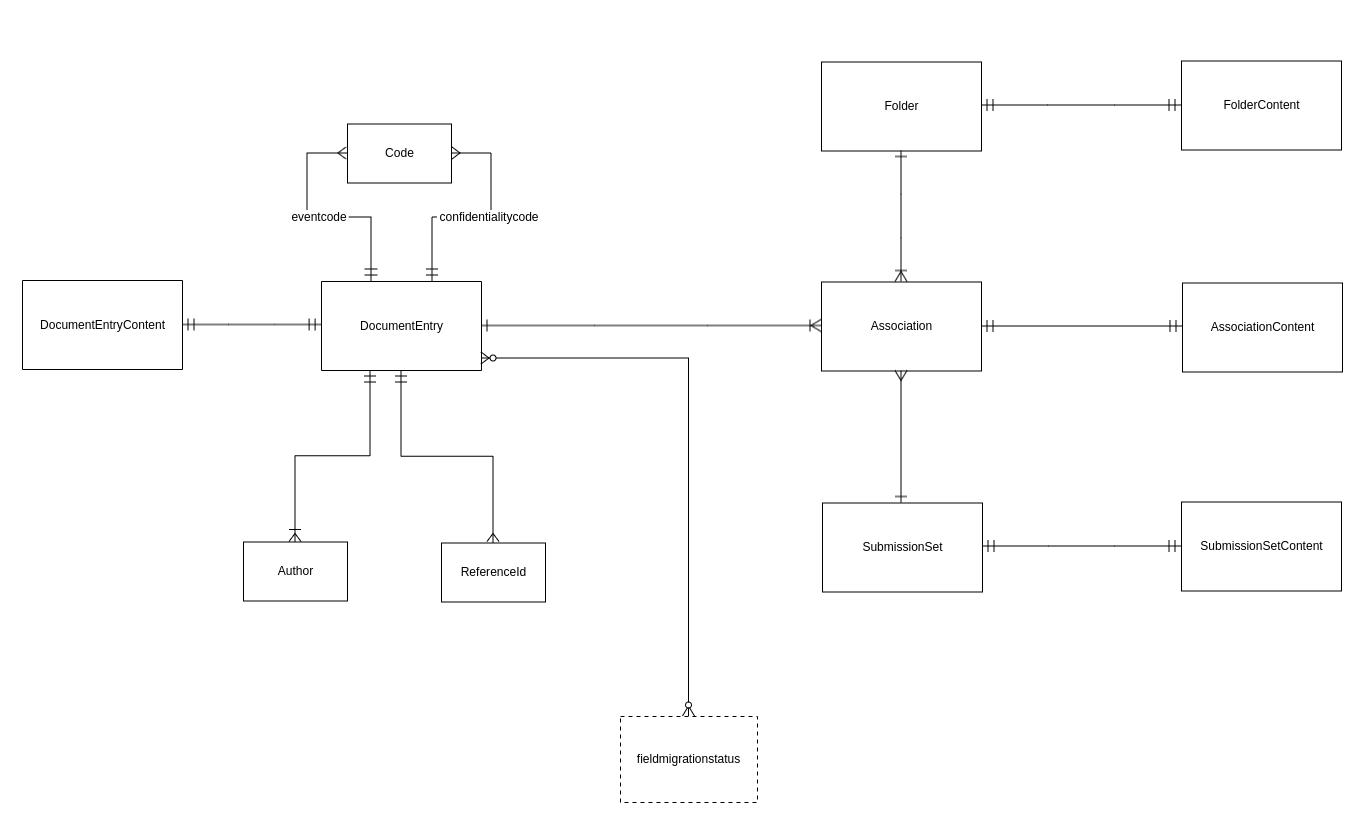
Hver entitet i diagrammet svarer til en tabel.
De vigtigste entiteter er Association, DocumentEntry, Folder og SubmissionSet, som er NXRG's repræsentation af de tilsvarende begreber fra IHE-specifikationen. I det følgende kaldes disse fire tabeller for objekttabeller. En række i en objekttabel svarer til et tilsvarende objekt, f.eks. svarer en række i Association-tabellen til et Association-objekt, en række i DocumentEntry-tabellen til et DocumentEntry-objekt, osv. Disse tabeller indeholder de attributter som der er brug for, for at NXRG kan realisere sine snitflader. Tabellerne er dog ikke fulstændige modeller af de objekter, de repræsenterer, da det er ganske omfattende at udarbejde og vedligeholde en sådan datamodel. De fulde objekter gemmes i stedet som xml i en tilhørende *Content-tabel (i det følgende kaldet en indholdstabel).
Objekttabellerne indeholder de attributter der er nødvendige for at understøtte søgning gennem ITI18-snitfladen, samt for at tjekke forretningsregler i ITI42-, ITI57- og ITI61-snitfladerne. Indholdstabellerne indeholder selve objekterne i et xml-format, der er nemt at parse og serialisere, men besværligt at søge i.
Alle tabellerne har felterne creation_time og last_update_time, der indeholder tidspuntk for oprettelse henholdsvis ændring.
Tabellen fieldmigrationstatus indeholder ikke registry relateret data, men er en "arbejdstabel", der anvendes til at holde styr på, hvor langt potentielle felt migreringer er (se afsnit "felt migrering" nedenfor).
2.4.1. Associations
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| entryuuid | Uuid, der identificerer Association-objektet. | nej |
|
varchar(64) |
| association_type |
|
nej |
|
varchar(32) |
| source_association | id på source, hvis denne er en Association. |
|
|
bigint(20) |
| sourceuuid_documententry | Entryuuid på source, hvis denne er et DocumentEntry. |
|
|
varchar(64) |
| sourceuuid_folder | Entryuuid på source, hvis denne er en Folder. |
|
|
varchar(64) |
| sourceuuid_submissionset | Entryuuid på source, hvis denne er et SubmissionSet. |
|
|
varchar(64) |
| target_association | id på target, hvis denne er en Association. |
|
|
bigint(20) |
| targetuuid_documententry | Entryuuid på target, hvis denne er et DocumentEntry. |
|
|
varchar(64) |
| targetuuid_folder | Entryuuid på target, hvis denne er en Folder. |
|
|
varchar(64) |
| targetuuid_submissionset | Entryuuid på target, hvis denne er et SubmissionSet. |
|
|
varchar(64) |
| associationcontentid | Reference til række i associationcontent-tabellen. | nej | x | bigint(20) |
| migration_pid | Link til oprindelig migreringsdata - default 0 | nej |
|
int(11) |
2.4.2. AssociationContent
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| xml | Det rå objekt i ebxml 3.0-format. |
|
|
blob |
2.4.3. Author (documententry_author)
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| documententry_entryuuid | Reference til række i documententry-tabellen. | nej |
|
int(64) |
| family_name | Efternavn fra Author-strukturen. | nej |
|
varchar(64) |
| given_name | Fornavn fra Author-strukturen. |
|
|
varchar(64) |
| further_given_names | Øvrige fornavne fra Author-strukturen. |
|
|
varchar(64) |
2.4.4. Code (documententry_eventcode og documententry_confidentialitycode)
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| documententry_entryuuid | Reference til række i documententry-tabellen. | nej |
|
int(64) |
| codename | Name-delen af Code-strukturen. | nej |
|
varchar(64) |
| schemename | Scheme-delen af Code-strukturen. | nej |
|
varchar(64) |
2.4.5. DocumentEntryContent
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| xml | Det rå objekt i ebxml 3.0-format. |
|
|
blob |
2.4.6. DocumentEntries
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| entryuuid | EntryUuid på DocumentEntry-objektet. Unik identifikation af den versionen af objektet. | nej | x | varchar(64) |
| logicaluuid |
LogicalUuid på DocumentEntry-objektet. Identificerer DocumentEntry-objektet på tværs af versioner. For version 1 er EntryUuid og LogicalUuid identiske, for andre versioner er de forskellige. |
nej |
|
varchar(64) |
| version | Versionsnummer på DocumentEntry-objektet. Antager værdierne 1, 2, 3, ... | nej |
|
int(11) |
| patientid | Id-delen af PatientId-strukturen. | nej |
|
varchar(32) |
| patientid_assigningauthorityid | AssigningAuthorityId-delen af PatientId-strukturen. | nej |
|
varchar(32) |
| patientid_assigningauthoritytype | AssigningAuthorityType-delen af PatientId-strukturen. | nej |
|
varchar(16) |
| availabilitystatus | Objektets status (Approved, Deprecated, etc.) | nej |
|
varchar(64) |
| documententrytype | Objektets typpe (Stable eller OnDemand) | nej |
|
varchar(64) |
| uniqueid | UniqueId på objektet (NB: ikke nødvendigvis unik for DocumentEntries). | nej |
|
varchar(128) |
| classcode_codename | Navn for ClassCode. | nej |
|
varchar(64) |
| classcode_schemename | Scheme for ClassCode. | nej |
|
varchar(64) |
| typecode_codename | Navn for TypeCode. | nej |
|
varchar(64) |
| typecode_schemename | Scheme for TypeCode. | nej |
|
varchar(64) |
| practicesettingcode_codename | Navn for PracticeSettingCode. | nej |
|
varchar(64) |
| practicesettingcode_schemename | Scheme for PracticeSettingCode. | nej |
|
varchar(64) |
| creationtime | Oprettelsestidspunkt som angivet af anvenderen. |
|
|
datetime(6) |
| servicestarttime | Starttidspunkt som angivet af anvenderen. |
|
|
datetime(6) |
| servicestoptime | Sluttidspunkt som angivet af anvenderen. |
|
|
datetime(6) |
| healthcarefacilitytypecode_codename | Navn for HealthcareFacilityTypeCode. | nej |
|
varchar(64) |
| healthcarefacilitytypecode_schemename | Scheme for HealthcareFacilityTypeCode. | nej |
|
varchar(64) |
| formatcode_codename | Navn for FormatCode. | nej |
|
varchar(64) |
| formatcode_schemename | Scheme for FormatCode. | nej |
|
varchar(64) |
| documententrycontentid | Reference til række i documententrycontent-tabellen. | nej | x | bigint(20) |
| migration_pid | Link til oprindelig migreringsdata - default 0 | nej |
|
int(11) |
| creation_time | Teknisk timestamp, hvornår rækken blev oprettet i databasen | nej |
|
date(6) |
| last_update_time | Teknisk timestamp, hvornår rækken blev opdateret i databasen | nej |
|
date(6) |
| deletetrigger_time | Persistent timestamp, der fremkommer som COALESCE(servicestarttime, creation_time) og anvendes af slettejobbet til at afgøre, hvor "gammelt" et dokument er | nej |
|
date(6) |
2.4.7. Folder
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| entryuuid | EntryUuid på Folder-objektet. Unik identifikation af den versionen af objektet. | nej | x | varchar(64) |
| logicaluuid |
LogicalUuid på Folder-objektet. Identificerer Folder-objektet på tværs af versioner. For version 1 er EntryUuid og LogicalUuid identiske, for andre versioner er de forskellige. |
nej |
|
varchar(64) |
| version | Versionsnummer på Folder-objektet. Antager værdierne 1, 2, 3, ... | nej |
|
int(11) |
| patientid | Id-delen af PatientId-strukturen. | nej |
|
varchar(32) |
| patientid_assigningauthorityid | AssigningAuthorityId-delen af PatientId-strukturen. | nej |
|
varchar(32) |
| patientid_assigningauthoritytype | AssigningAuthorityType-delen af PatientId-strukturen. | nej |
|
varchar(16) |
| availabilitystatus | Objektets status (Approved, Deprecated, etc.) | nej |
|
varchar(64) |
| uniqueid | UniqueId på objektet (NB: ikke nødvendigvis unik for DocumentEntries). | nej |
|
varchar(64) |
| lastupdatetime | Seneste opdateringstidspunkt for Folder-objektet. | nej |
|
datetime(6) |
| foldercontentid | Reference til række i foldercontent-tabellen. | nej | x | bigint(20) |
2.4.8. FolderContent
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| xml | Det rå objekt i ebxml 3.0-format. |
|
|
blob |
2.4.9. ReferenceId (documententry_referenceid)
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| documententry_entryuuid | Reference til række i documententry-tabellen. | nej |
|
int(64) |
| reference_id | Nøgle på ReferenceId'et. | nej |
|
varchar(64) |
| assigningauthority_id | Id fra AssigningAuthority-strukturen. |
|
|
varchar(64) |
| assigningauthority_type | Type fra AssigningAuthority-strukturen. |
|
|
varchar(64) |
| typecode | TypeCode på ReferenceId'et. | nej |
|
varchar(64) |
| homecommunityid_id |
Id fra HomeCommunityId-strukturen. |
|
|
varchar(64) |
| homecommunityid_type | Type fra HomeCommunityId-strukturen. |
|
|
varchar(64) |
2.4.10. SubmissionSet
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| entryuuid | Uuid, der identificerer SubmissionSet-objektet. | nej | x | varchar(64) |
| patientid | Id-delen af PatientId-strukturen. | nej |
|
varchar(32) |
| patientid_assigningauthorityid | AssigningAuthorityId-delen af PatientId-strukturen. | nej |
|
varchar(32) |
| patientid_assigningauthoritytype | AssigningAuthorityType-delen af PatientId-strukturen. | nej |
|
varchar(16) |
| uniqueid | UniqueId på objektet. | nej | x | varchar(64) |
| migration_uniqueid_fix | Sikring af uniqueness på migreringstidspunktet. Se afsnit nedenfor med findings. Default 0 | nej |
|
int(11) |
| submissionsetcontentid | Reference til række i submissionsetcontent-tabellen. | nej | x | bigint(20) |
2.4.11. SubmissionSetContent
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| xml | Det rå objekt i ebxml 3.0-format. |
|
|
blob |
2.4.12. Deleted_Documententries
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| entryuuid | EntryUuid på slettet DocumentEntry. | nej |
|
varchar(64) |
| uniqueid | UniqueId på slettet DocumentEntry. | nej |
|
varchar(64) |
| deletion_status | Status på sletningen. Kan være DELETED_FROM_REGISTRY, DELETED_FROM_REPOSITORY, DELETION_FROM_REPOSITORY_FAILED. | nej |
|
varchar(64) |
| deletion_attempts | Antal gange hvor sletning fra repository er gået galt. | nej |
|
int(11) |
| creation_time | Tidspunkt for indsættelse af rækken. | nej |
|
datetime(6) |
2.4.13. Fieldmigrationstatus
Denne tabel, skal indeholde en række for hver type felt migrering, som skal laves. Rækkes indsættes i forbindelse med at database scriptene bliver kørt i forbindelse med opgraderinger. Og opdateres af "felt migrerings servicen".
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| migrationid | en logisk nøgle, der siger noget om hvad der migreres. F.eks. 'documententry-repositoryid-add'. | nej |
|
varchar(64) |
| progressid | peger på et id i documentEntries. Er 0 sålænge migreringen ikke er startet. Når en migrering er kørt, vil progressid pege på den sidste documentEntries, der er migreret i kørslen. Når progressid = targetid, er der ikke mere at migrere. | nej |
|
int(11) |
| targetid | peger på det sidste id i documentEntries der skal migreres. Denne værdi sættes når rækken indsættes og ændres ikke efterfølgende. | nej |
|
bigint(20) |
| migration_start_time | tidspunkt for, hvornår den første kørsel af migreringen er startet |
|
|
datetime(6) |
| migration_end_time | tidspunkt for, hvornår migreringen er afsluttet (da progressid ramte targetid) |
|
|
datetime(6) |
| last_update_time | tidspunkt for, hvornår rækken senest er opdateret |
|
|
datetime(6) |
Alle tider er tider er databasens tidszone.
2.4.14. Nas integration tabeller
Integrationen til NAS har 2 tabeller i databasen:
notification_configuration:
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| classcode_codename | Navn for ClassCode. | nej |
|
varchar(64) |
| classcode_schemename | Scheme for ClassCode. | nej |
|
varchar(64) |
| typecode_codename | Navn for TypeCode. | nej |
|
varchar(64) |
| typecode_schemename | Scheme for TypeCode. | nej |
|
varchar(64) |
| formatcode_codename | Navn for FormatCode. | nej |
|
varchar(64) |
| formatcode_schemename | Scheme for Formatcode. | nej |
|
varchar(64) |
| topic | Den topic, som der sendes til på NAS | nej |
|
varchar(128) |
| notification_type | Notifikationens type. Skal være defineret i NXRG logik, sådan at den kendes i respektiv dao klasse og Notifications jobbet. | nej |
|
varchar(128) |
| creation_time | Tidspunkt for indsættelse af rækken. |
|
|
datetime(6) |
unsent_notifications:
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | bigint(20) |
| uuid | Unik nøgle | nej | x | varchar(64) |
| patient_id | CPR nummer som notifikationen drejer sig om | nej |
|
varchar(64) |
| created_date | Dato og tid for hvornår notifikationen blev skabt | nej |
|
VARCHAR(50) |
| topic | Den topic, som der sendes til på NAS | nej |
|
varchar(128) |
| notification_type | Notifikationens type. Skal være defineret i NXRG logik, sådan at den kendes i respektiv dao klasse og Notifications jobbet. | nej |
|
varchar(128) |
3. Migrering af data
Den oprindelige data migrering fra openText registry er ikke længere aktuel, og indholdet er flyttet til "Yderligere dokumentation - Migration"
3.1. Felt migrering
På tidspunktet for NXRG tilblivelse blev der udvalgt en række felter fra kaldets metadata (XMl baseret RIM format), som var interessante som søgbare felter. Disse felter, gemmes som selvstændige felter i tabeller som documententries og referenceid. Der opstår siden behov for at få flere af disse felter trukket ud af XML formatet. Dvs. der i princippet skal køres en migrering af eksisterende metadata for at trække disse felter ud. Dette er lavet som en selvstændig service. Source koden ligger sammen med resten af NXRG, men servicen starter op selvstændig og aktiveres ved at tilgå et specifik endpoint. Detaljerne er beskrevet i "NXRG - driftvejledning til felt migrering".
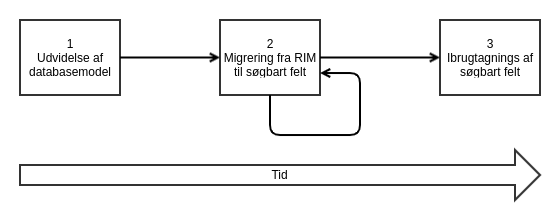
Som ovenstående figur viser, består felt migreringen af 3 trin:
- udvidelse af databasemodel. Her tilføjes det søgbare felt databasen og NXRG justeres sådan at nye dokumentregistreringer vil gemme feltet, som et søgbart felt.
- migrering af data. Denne kan foregå af flere omgange (batch) da kørslen kan være tidskrævende. Servicen konfigureres med en batch størrelse, som det antal dokumenter, der håndteres i en enkelt kørsel.
- anvendelse af det søgbare felt. Når alt data er migreret kan det nye felt tages i anvendelse. Dvs først her kan ny funktionatlitet, der gør brug af feltet, udvikles.