Formålet med dette dokument er at beskrive systemarkitekturen for NXRG.
Nærværende dokument er tiltænkt udviklere og IT-arkitekter med interesse i NXRG og dens opbygning.
| NSP | National Service Platform |
| NXRG | NXP XDS Registry |
| IHE | Integrating the Healthcare Enterprise (se https://www.ihe.net/) |
I det følgende gives et overblik over NXRG. Først beskrives NXRG i forhold til dennes samarbejdende services og interne arkitektur (modulopdeling etc.)
Efterfølgende beskrives og begrundes den underliggende datamodel.
I nedenstående dokument vises overblik over NXRG. Diagrammet viser både løsningens snitflader og eksterne services, som denne samarbejder med. Derudover vises den NXRGs intern lagdelte opbygning (herunder specificering af ansvarsfordelingen i de forskellige lag i applikation).
NXRG samarbejder med følgende komponenter i NSP infrastrukturen:
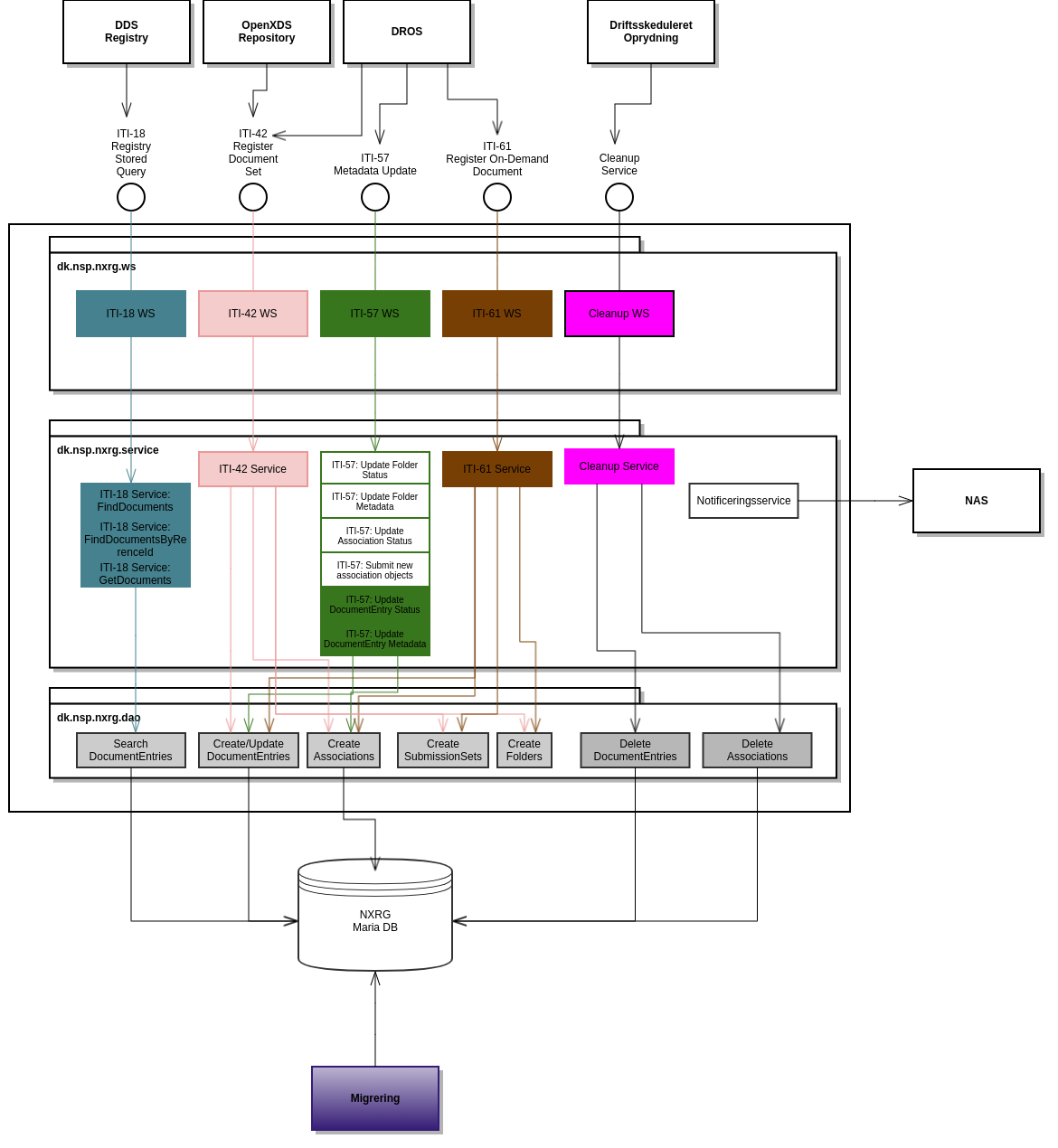
NXRG er opbygge i en lagdelt arkitektur. I ovenstående diagram er pakkenavne specificeret og giver en kobling til den konkrete sourcekode, der realiserer NXRG (se i øvrigt NXRG - Guide til Udviklere).
De udbudte snitflader er realiseret som SOAP webservices (dk.nsp.nxrg.ws). ITI-XX snitfladerne er specificeret i IHE XDS revision 17 fra juli 2020.
Se følgende:
Til at realisere disse ITI-XX snitflader anvendes tredjeparts biblioteker fra IPF Open eHealth Integration Platform til implementations- og hjælpeklasser (herunder mapning af XML baseret model til domænemodel).
Forretningsregler i relation til de udbudte ITI-XX services er implementeret udfra specifikationen af IHE XDS (dk.nsp.nxrg.service). For ITI-18 er det besluttet ikke at understøtte samtlige querytyper, der fremgår af specifikationen, men at nøjes med følende:
Kald af ITI-18 med andre querytyper vil resultere i en fejlkode fra NXRG (se NXRG - Guide til Anvendere).
Forespørgsler og svar valideres efter reglerne beskrevet i IHE XDS specifikationen. Mere præcist udføres validering som beskrevet i følgende afsnit:
Open eHealth frameworket, der anvendes af både OpenText og NXRG, stiller muligheden for validering af request og responses til rådighed. Det er denne validering, som i stor udstrækning anvendes som validerings mekanisme i NXRG.
Både NXRG og Open Text har det som konfiguration, om sådanne valideringer skal udføres i forbindelse med forespørgsel og svar (request/response) og for de forskellige typer kald (ITI-42, ITI-61, ITI-57 og ITI-18).
Følgende tabel viser, hvordan denne konfiguration af validering er sat op:
| NXRG lokal test | Open Text - Test 1 | Open Text - Test 2 | Open Text - Produktion | |||||
|---|---|---|---|---|---|---|---|---|
| Request | Response | Request | Response | Request | Response | Request | Response | |
| ITI-42 | Disabled | Disabled | Disabled | Disabled | Disabled | |||
| ITI-61 | Disabled | Disabled | Disabled | Disabled | Disabled | |||
| ITI-57 | Disabled | Disabled | ||||||
| ITI-18 | Disabled | Disabled | Disabled | Disabled | Disabled | Disabled | ||
Ved validering af forespørgsler skal der sammenlignes patientId'er. Ifølge specifikationen skal denne sammenligning tage højde for sammensmeltning af patientId'er (This comparison shall take into consideration patient identity merges as described in ITI TF-2a: 3.8.4.2.4.). I NXRG er det antaget, at denne form for sammensmeltning ikke forekommer, og sammenligning af patientId'er er derfor implementeret ved simpel strengsammenligning.
NXRG har behov for at persistere data i en database. NXRGs datamodel er realiseret udfra følgende principper:
For en detaljeret beskrivelse af databasemodellen se afsnittet nedenfor.
Der er i dag eksterne services, der tilgår OpenText Registry direkte (dvs udenom de i forgående afsnit skitserede NSP services).
Det drejer sig om følgende:
De fleste andre eksterne services (f.eks. PLSP, Bookplan, Laboratoriesvarportalen) udbyder data ved selv at udstille XDS Registry+XDS Repository snitflader, som Dokumentdelingsservicen så integrerer med. Ændringer i det nationale registry vil ikke berøre disse typer.
KIH databasen (repository) indeholder dokumenter af typerne PHMR og QRD dvs hjemmemålinger og spørgeskemabesvarelser. KIH Repository anvender det nationale registry til at få indexeret disse dokumenter og gøre dem søgbare via Dokumentdelingsservicen.
KIH databasen kalder således ITI-42 på det nationale registry. Der er to muligheder i fremtiden:
Inden driftsstart for NXRG skal det afklares, hvilket af de to punkter ovenfor, der ønskes.
Derudover skal der udarbejdes en plan i samarbejde med Medcom om, hvordan det skal foregå.
I forhold til NXRG, så er det ikke hele IHE XDS specifikationen, der implementeres. I de følgende afsnit dokumenteres evt. fravalg og beslutninger ved de enkelte services.
I forhold til fremsøgning, så er det besluttet, at følgende query typer skal understøttes:
Specifikationen beskriver i afsnit "3.57.4.1.3.4 Patient ID Reconciliation", hvordan det skal håndteres, hvis patient-id opdateres som en del af et kald til ITI-57. I forhold til NXRG, så har vi valgt, at denne ikke skal understøtte dette, hvorfor et forsøg på ITI-57 kald, hvor patient id opdateres vil resultere i en fejl til anvenderen.
Patient ID Reconciliation vil resultere i øget kompleksitet i NXRG, og anvendere vil kunne opnå det samme ved f.eks. at deprecate eksisterende data på en patient, og dernæst oprette data på en anden.
Derudover vil anvendelsen af NXRGs ITI-57 service ikke foregå direkte men via DROS - Guide til anvendere. I forhold til auditlogning og diverse tjek, så er de fleste NSP anvender services tænkt til en brug, hvor der er netop én patient i kontekst ad gangen.
Vi vurderer, at skift af patient ID vil skabe øget unødvendig kompleksitet i de anvenderrettede services.
Dette kald tillades ikke for OnDemand dokumenter. Det anvendte biblioteks fra Open eHealth afviser typen OnDemand i forbindelse med opdatering af metadata. Det fungerer sådan for både Open Text registry og NXRG.
Dette kald opfører forskelligt for Stable og OnDemand dokumenter. Ved replace af Stable dokument deprecates de gamle dokument. Dette sker ikke for onDemand dokumenter. Der er i ovenstående specifikationen ikke nævnt noget med status ændring for OnDemand Det fungerer sådan for både Open Text registry og NXRG.
Følgende overblik viser, hvorledes datamodellen i NXGR er opbygget. Datamodellen er opbygget med udgangspunkt i følgende overordnede principper:
I det følgende beskriver vi datamodellen for NXRG og beskriver, hvorledes ovenstående principper er respekteret. Datamodellen præsenteres først i overbliksform i nedenstående E/R-diagram, og de enkelte tabeller beskrives derefter.
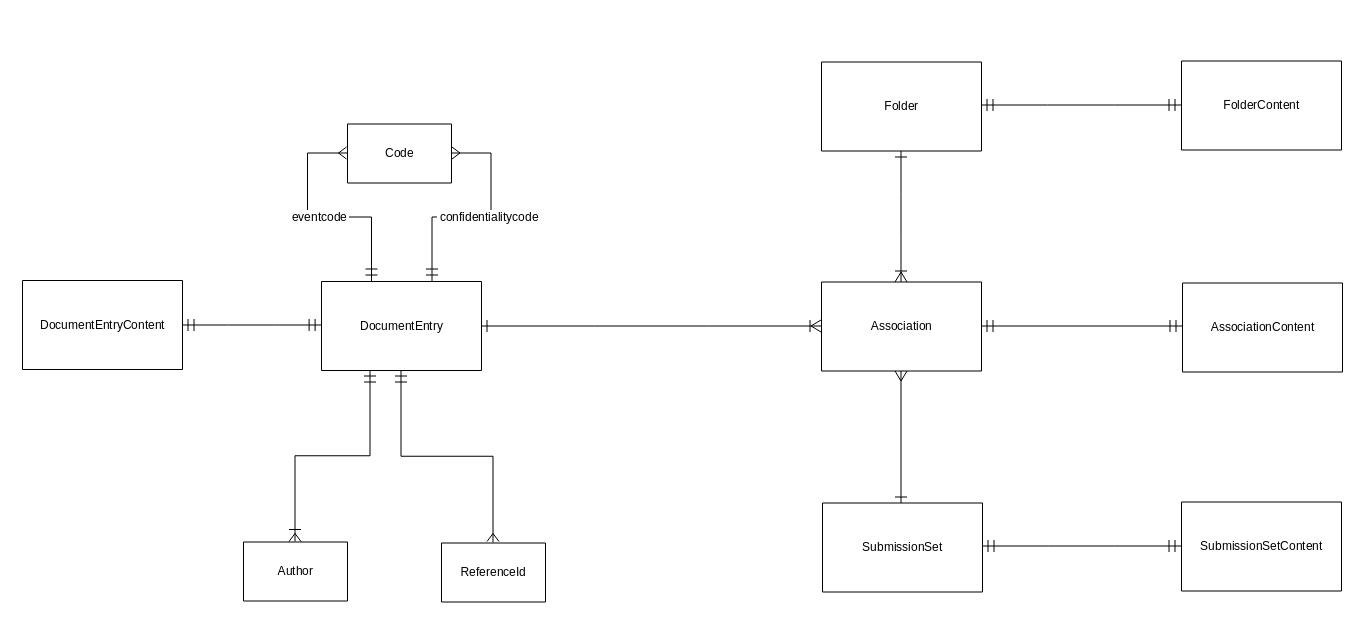
Hver entitet i diagrammet svarer til en tabel.
De vigtigste entiteter er Association, DocumentEntry, Folder og SubmissionSet, som er NXRG's repræsentation af de tilsvarende begreber fra IHE-specifikationen. I det følgende kaldes disse fire tabeller for objekttabeller. En række i en objekttabel svarer til et tilsvarende objekt, f.eks. svarer en række i Association-tabellen til et Association-objekt, en række i DocumentEntry-tabellen til et DocumentEntry-objekt, osv. Disse tabeller indeholder de attributter som der er brug for, for at NXRG kan realisere sine snitflader. Tabellerne er dog ikke fulstændige modeller af de objekter, de repræsenterer, da det er ganske omfattende at udarbejde og vedligeholde en sådan datamodel. De fulde objekter gemmes i stedet som xml i en tilhørende *Content-tabel (i det følgende kaldet en indholdstabel).
Objekttabellerne indeholder de attributter der er nødvendige for at understøtte søgning gennem ITI18-snitfladen, samt for at tjekke forretningsregler i ITI42-, ITI57- og ITI61-snitfladerne. Indholdstabellerne indeholder selve objekterne i et xml-format, der er nemt at parse og serialisere, men besværligt at søge i.
Alle tabellerne har felterne creation_time og last_update_time, der indeholder tidspuntk for oprettelse henholdsvis ændring.
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| entryuuid | Uuid, der identificerer Association-objektet. | nej | varchar(64) | |
| association_type | nej | varchar(32) | ||
| source_association | id på source, hvis denne er en Association. | int(11) | ||
| sourceuuid_documententry | Entryuuid på source, hvis denne er et DocumentEntry. | varchar(64) | ||
| sourceuuid_folder | Entryuuid på source, hvis denne er en Folder. | varchar(64) | ||
| sourceuuid_submissionset | Entryuuid på source, hvis denne er et SubmissionSet. | varchar(64) | ||
| target_association | id på target, hvis denne er en Association. | int(11) | ||
| targetuuid_documententry | Entryuuid på target, hvis denne er et DocumentEntry. | varchar(64) | ||
| targetuuid_folder | Entryuuid på target, hvis denne er en Folder. | varchar(64) | ||
| targetuuid_submissionset | Entryuuid på target, hvis denne er et SubmissionSet. | varchar(64) | ||
| associationcontentid | Reference til række i associationcontent-tabellen. | nej | x | int(11) |
| migration_pid | Link til oprindelig migreringsdata - default 0 | nej | int(11) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| xml | Det rå objekt i ebxml 3.0-format. | blob |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| documententry_entryuuid | Reference til række i documententry-tabellen. | nej | int(64) | |
| family_name | Efternavn fra Author-strukturen. | nej | varchar(64) | |
| given_name | Fornavn fra Author-strukturen. | varchar(64) | ||
| further_given_names | Øvrige fornavne fra Author-strukturen. | varchar(64) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| documententry_entryuuid | Reference til række i documententry-tabellen. | nej | int(64) | |
| codename | Name-delen af Code-strukturen. | nej | varchar(64) | |
| schemename | Scheme-delen af Code-strukturen. | nej | varchar(64) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| xml | Det rå objekt i ebxml 3.0-format. | blob |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| entryuuid | EntryUuid på DocumentEntry-objektet. Unik identifikation af den versionen af objektet. | nej | x | varchar(64) |
| logicaluuid | LogicalUuid på DocumentEntry-objektet. Identificerer DocumentEntry-objektet på tværs af versioner. For version 1 er EntryUuid og LogicalUuid identiske, for andre versioner er de forskellige. | nej | varchar(64) | |
| version | Versionsnummer på DocumentEntry-objektet. Antager værdierne 1, 2, 3, ... | nej | int(11) | |
| patientid | Id-delen af PatientId-strukturen. | nej | varchar(32) | |
| patientid_assigningauthorityid | AssigningAuthorityId-delen af PatientId-strukturen. | nej | varchar(32) | |
| patientid_assigningauthoritytype | AssigningAuthorityType-delen af PatientId-strukturen. | nej | varchar(16) | |
| availabilitystatus | Objektets status (Approved, Deprecated, etc.) | nej | varchar(64) | |
| documententrytype | Objektets typpe (Stable eller OnDemand) | nej | varchar(64) | |
| uniqueid | UniqueId på objektet (NB: ikke nødvendigvis unik for DocumentEntries). | nej | varchar(128) | |
| classcode_codename | Navn for ClassCode. | nej | varchar(64) | |
| classcode_schemename | Scheme for ClassCode. | nej | varchar(64) | |
| typecode_codename | Navn for TypeCode. | nej | varchar(64) | |
| typecode_schemename | Scheme for TypeCode. | nej | varchar(64) | |
| practicesettingcode_codename | Navn for PracticeSettingCode. | nej | varchar(64) | |
| practicesettingcode_schemename | Scheme for PracticeSettingCode. | nej | varchar(64) | |
| creationtime | Oprettelsestidspunkt som angivet af anvenderen. | datetime(6) | ||
| servicestarttime | Starttidspunkt som angivet af anvenderen. | datetime(6) | ||
| servicestoptime | Sluttidspunkt som angivet af anvenderen. | datetime(6) | ||
| healthcarefacilitytypecode_codename | Navn for HealthcareFacilityTypeCode. | nej | varchar(64) | |
| healthcarefacilitytypecode_schemename | Scheme for HealthcareFacilityTypeCode. | nej | varchar(64) | |
| formatcode_codename | Navn for FormatCode. | nej | varchar(64) | |
| formatcode_schemename | Scheme for FormatCode. | nej | varchar(64) | |
| documententrycontentid | Reference til række i documententrycontent-tabellen. | nej | x | int(11) |
| migration_pid | Link til oprindelig migreringsdata - default 0 | nej | int(11) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| entryuuid | EntryUuid på Folder-objektet. Unik identifikation af den versionen af objektet. | nej | x | varchar(64) |
| logicaluuid | LogicalUuid på Folder-objektet. Identificerer Folder-objektet på tværs af versioner. For version 1 er EntryUuid og LogicalUuid identiske, for andre versioner er de forskellige. | nej | varchar(64) | |
| version | Versionsnummer på Folder-objektet. Antager værdierne 1, 2, 3, ... | nej | int(11) | |
| patientid | Id-delen af PatientId-strukturen. | nej | varchar(32) | |
| patientid_assigningauthorityid | AssigningAuthorityId-delen af PatientId-strukturen. | nej | varchar(32) | |
| patientid_assigningauthoritytype | AssigningAuthorityType-delen af PatientId-strukturen. | nej | varchar(16) | |
| availabilitystatus | Objektets status (Approved, Deprecated, etc.) | nej | varchar(64) | |
| uniqueid | UniqueId på objektet (NB: ikke nødvendigvis unik for DocumentEntries). | nej | varchar(64) | |
| lastupdatetime | Seneste opdateringstidspunkt for Folder-objektet. | nej | datetime(6) | |
| foldercontentid | Reference til række i foldercontent-tabellen. | nej | x | int(11) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| xml | Det rå objekt i ebxml 3.0-format. | blob |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| documententry_entryuuid | Reference til række i documententry-tabellen. | nej | int(64) | |
| reference_id | Nøgle på ReferenceId'et. | nej | varchar(64) | |
| assigningauthority_id | Id fra AssigningAuthority-strukturen. | varchar(64) | ||
| assigningauthority_type | Type fra AssigningAuthority-strukturen. | varchar(64) | ||
| typecode | TypeCode på ReferenceId'et. | nej | varchar(64) | |
| homecommunityid_id | Id fra HomeCommunityId-strukturen. | varchar(64) | ||
| homecommunityid_type | Type fra HomeCommunityId-strukturen. | varchar(64) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| entryuuid | Uuid, der identificerer SubmissionSet-objektet. | nej | x | varchar(64) |
| patientid | Id-delen af PatientId-strukturen. | nej | varchar(32) | |
| patientid_assigningauthorityid | AssigningAuthorityId-delen af PatientId-strukturen. | nej | varchar(32) | |
| patientid_assigningauthoritytype | AssigningAuthorityType-delen af PatientId-strukturen. | nej | varchar(16) | |
| uniqueid | UniqueId på objektet. | nej | x | varchar(64) |
| migration_uniqueid_fix | Sikring af uniqueness på migreringstidspunktet. Se afsnit nedenfor med findings. Default 0 | nej | int(11) | |
| submissionsetcontentid | Reference til række i submissionsetcontent-tabellen. | nej | x | int(11) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| xml | Det rå objekt i ebxml 3.0-format. | blob |
Migrering af data fra OpenText Registry til NXRG skal sikre, at al data, der ligger i OpenText Registry overføres til NXRG på en måde, så data bevares: Det vil sige, at de data, der kan udsøges gennem NXRGs snitflader svarer 1:1 til det data, der kan udsøges gennem OpenText Registrys snitflader.
Den interne datarepræsentation vil ændre sig fra OpenText Registry til NXRG, men det logiske data skal bevares.
Der har i forbindelsen med migreringen været arbejdet med nedenstående diagram for at komme frem til en migreringsstrategi.
.jpg")
Diagrammet viser de forskellige niveauer, som data kan eksporteres henholdsvis importeres på. De forskellige muligheder er blevet diskuteret på workshops, og fravalg og tilvalg er dokumenteret på diagrammet.
Konklusionen på analysearbejdet er således, at:
Der har været et ønske om at kunne lave løbende (delta)migreringer af OpenText data til NXRG. Dette ønske bunder i, at der i produktion i dag er ca 11 mio XDS objekter (submissionsets med associations samt document entries) i OpenText Registry databasen.
Selv med et effektitivt migreringstool, så vil det tage tid (< 5 dage) at migrere al data. Hvis en migreringsstrategi kræver et servicevindue, så vil dokumentdeling på NSP være utilgængeligt i flere dage, hvilket er blevet vurderet til problematisk.
Da driften kan trække liste over nye/opdaterede data i OpenText Registry (se pkt 1 ovenfor) er det muligt at lave en trinvis migrering. Dette betyder yderligere, at det bliver muligt at komme i gang med migreringen på et tidligere tidspunkt (da det kan foretages uden at der skal meldes servicevinduer ud).
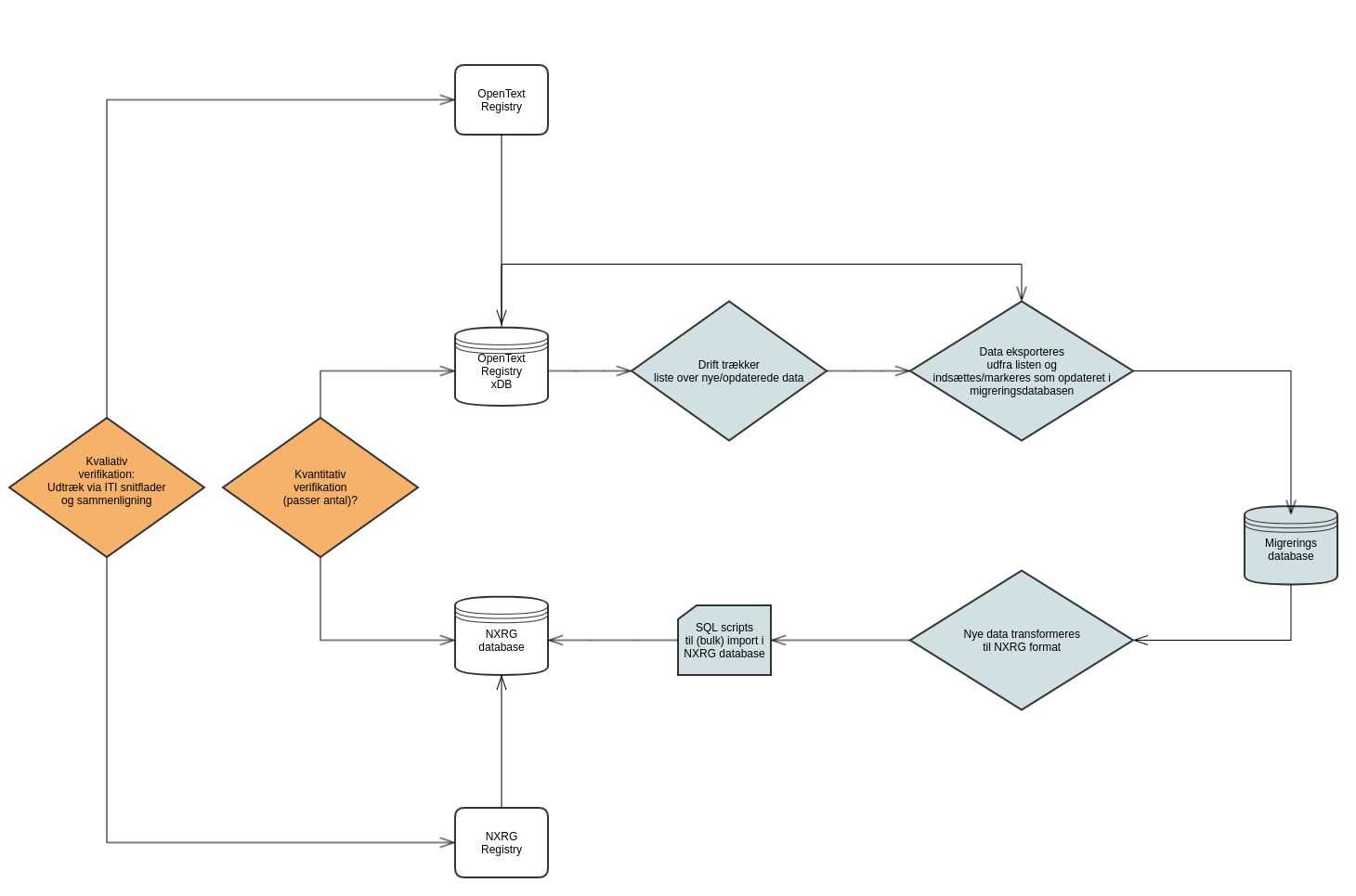
Migreringsprocessen er markeret med blå i diagrammet ovenfor. Det er tanken at bevare Migreringsdatabasen efterfølgende som en backup for OpenText Registry data. Når licensen udløber for xDB databasen, så vil migreringsdatabasen være masterdata (i tilfælde af, at man skulle opdage fejl i import til NXRG efterfølgende).
Der skal laves verifikation af migreringsprocessen - både en kvantitativ verifikation og en kvalitativ verifikation. Denne del af processen er beskrevet nedenfor.
Dataene fra OpenText registry'et i en MariaDB-database, som deles mellem eksport- og import-jobbet. Databasen indeholder to tabeller, contents og status. Tabellernes indhold beskrives nedenfor. Man kan hente et eksempel-datasæt på .
Desuden opdateres til tabellen migration_properties under migreringskørslen. Formålet med dette er at holde styr på, hvor langt man er nået med id'erne for association og documententry, sådan at man kan fortsætte herfra ved næste kørsel.
| Feltnavn | Datatype | Indhold |
|---|---|---|
| PID | bigint(20) | Unik nøgle. |
| RowModified | timestamp | Angivelse af, hvornår rækken sidst er opdateret. |
| DocID | varchar(255) | Id på dokument. |
| content | mediumblob | XML-repræsentation af dokumentet (kan være enten submissionset eller document). |
| Feltnavn | Datatype | Indhold |
|---|---|---|
| PID | bigint(20) | Unik nøgle. |
| RowModified | timestamp | Angivelse af, hvornår rækkken sidst er opdateret. |
| DocID | varchar(255) | Id på dokument. Refererer til DocID-kolonnen i contents-tabellen. |
| DocDate | timestamp | Angivelse af, hvornår dokumentet er oprettet. |
| DocExportState | int(11) | Status-felt, der bruges til at angive om et dokument er blevet eksporteret eller ej. Kan antage følgende værdier: 0 (NotReady), 1 (Ready), 2 (Migrating), 100 (Migrated). |
| DocImportState | int(11) | Status-felt, der bruges til at angive om et dokument er blevet importeret eller ej. Kan antage følgende værdier: 0 (NotReady), 1 (Ready), 2 (Migrating), 100 (Migrated). |
| Feltnavn | Datatype | Indhold |
|---|---|---|
| Id | int(11) | Unik nøgle. |
| finish_time | datetime | Angivelse af, hvornår migreringskørslen afsluttede |
| current_association_id | int(11) | Angivelse af, hvor langt man nåede i række af id på associations i NXRG databasen |
| current_documententry_id | int(11) | Angiver hvor langt man nåede i række af id på documententry i NXRG databasen |
OpenText registry'et eksporterer sine data i et xml-format, som der ind til videre ikke er tilvejebragt noget schema for. Nedenfor kan man se et eksempel på et submissionset og et tilhørende document i dette format.
<?xml version="1.0"?>
<submissionSet id="urn:uuid:255d0bef-db11-482d-b2bd-dca0053d8045">
<xds:submissionSet xmlns:xds="http://www.openehealth.org/ipf/xds">
<entryUuid>urn:uuid:255d0bef-db11-482d-b2bd-dca0053d8045</entryUuid>
<logicalUuid>urn:uuid:255d0bef-db11-482d-b2bd-dca0053d8045</logicalUuid>
<version>
<versionName>1</versionName>
</version>
<uniqueId>7020798514690154282.7024117544796833076.1568187071790</uniqueId>
<patientId extension="2606481234" root="1.2.208.176.1.2"/>
<availabilityStatus>Approved</availabilityStatus>
<title language="en-US">769a1dbf-2c73-4cca-98b9-9c045231f309</title>
<limitedMetadata>false</limitedMetadata>
<sourceId>7020798514690154282.7024117544796833076.1568187071790</sourceId>
<submissionTime>2013-02-17T08:15:00Z</submissionTime>
<author>
<authorPerson>
<id/>
<name>
<given>M</given>
<family>Madsen</family>
</name>
</authorPerson>
<authorInstitution>
<idNumber>77668685</idNumber>
<assigningAuthority universalId="1.2.208.176.1.2" universalIdType="ISO"/>
<name>Odense Universitetshospital, Odense</name>
</authorInstitution>
</author>
<contentTypeCode code="NscContentType" codeSystemName="urn:uuid:aa543740-bdda-424e-8c96-df4873be8500" displayName="NscContentType"/>
</xds:submissionSet>
<xds:associations xmlns:xds="http://www.openehealth.org/ipf/xds">
<xds:association>
<entryUuid>urn:uuid:1b1d1134-c1d9-4a88-add6-3d580aadfed7</entryUuid>
<sourceUuid>urn:uuid:255d0bef-db11-482d-b2bd-dca0053d8045</sourceUuid>
<targetUuid>urn:uuid:5e6ac9ef-4633-46ea-96b1-786a948e7bb6</targetUuid>
<associationType>HasMember</associationType>
<label>Original</label>
<originalStatus>Approved</originalStatus>
<newStatus>Approved</newStatus>
<availabilityStatus>Approved</availabilityStatus>
</xds:association>
</xds:associations>
</submissionSet> |
<?xml version="1.0"?>
<document id="urn:uuid:da51d7ce-1a18-48ca-ba5f-03b0be78b906">
<xds:documentEntry xmlns:xds="http://www.openehealth.org/ipf/xds">
<entryUuid>urn:uuid:da51d7ce-1a18-48ca-ba5f-03b0be78b906</entryUuid>
<logicalUuid>urn:uuid:da51d7ce-1a18-48ca-ba5f-03b0be78b906</logicalUuid>
<version>
<versionName>1</versionName>
</version>
<uniqueId>437f8b60-9563-11e3-a5e2-0800200c7020^1.2.208.184</uniqueId>
<patientId extension="2606481234" root="1.2.208.176.1.2"/>
<availabilityStatus>Approved</availabilityStatus>
<title language="en-US">Hjemmemonitorering for 2606481234</title>
<limitedMetadata>false</limitedMetadata>
<sourcePatientId extension="2606481234" root="1.2.208.176.1.2"/>
<sourcePatientInfo>
<name>
<given>Janus</given>
<family>Berggren</family>
</name>
<gender>M</gender>
<birthTime>1948-06-26T00:00:00Z</birthTime>
</sourcePatientInfo>
<creationTime>2013-02-17T08:15:00Z</creationTime>
<author>
<authorPerson>
<id/>
<name>
<given>M</given>
<family>Madsen</family>
</name>
</authorPerson>
<authorInstitution>
<idNumber>77668685</idNumber>
<assigningAuthority universalId="1.2.208.176.1.2" universalIdType="ISO"/>
<name>Odense Universitetshospital, Odense</name>
</authorInstitution>
</author>
<legalAuthenticator>
<id/>
<name>
<given>Lars</given>
<family>Olsen</family>
</name>
</legalAuthenticator>
<serviceStartTime>2013-02-11T08:11:00Z</serviceStartTime>
<serviceStopTime>2013-02-16T10:14:00Z</serviceStopTime>
<classCode code="001" codeSystemName="1.2.208.184.100.9" displayName="Clinical report"/>
<confidentialityCode code="N" codeSystemName="2.16.840.1.113883.5.25" displayName="N"/>
<eventCode code="NPU03011" codeSystemName="1.2.208.176.2.1" displayName="O2 sat.;Hb(aB)"/>
<eventCode code="MCS88016" codeSystemName="1.2.208.184.100.8" displayName="FVC"/>
<formatCode code="urn:ad:dk:medcom:appointmentsummary:full" codeSystemName="1.2.208.184.100.10" displayName="DK Appointment Summary Document schema"/>
<healthcareFacilityTypeCode code="550621000005101" codeSystemName="2.16.840.1.113883.6.96" displayName="hjemmesygepleje"/>
<languageCode>da-DK</languageCode>
<practiceSettingCode code="419192003" codeSystemName="2.16.840.1.113883.6.96" displayName="intern medicin"/>
<typeCode code="53576-5" codeSystemName="2.16.840.1.113883.6.1" displayName="Personal Health Monitoring Report"/>
<repositoryUniqueId>1.2.208.176.43210.8.10.11</repositoryUniqueId>
<mimeType>text/xml</mimeType>
<size>27302</size>
<hash>da39a3ee5e6b4b0d3255bfef95601890afd80709</hash>
<type>stable</type>
</xds:documentEntry>
</document>
|
Migreringen består af to faser:
Denne stuktur er valgt af følgende grunde:
Fase 1 er implementeret som en java kommandolinje-applikation. Fase 2 består af indlæsning af genererede scripts i navngivne rækkefølge.
Det er blevet fundet, at der optræder dubletter i uniqueid på submissionsets i data trukket ud fra test1 (se detaljer på ). Der er blevet indført en ekstra kolonne i datamodellen for submissionsets (migration_uniqueid_fix), som giver følgende egenskaber:
Det er ikke helt klart, om de sammenfaldende id'er er en egenskab, som udelukkende begrænser sig til testsystemet. Følgende SQL kan fremfinde de række, hvor der er problemer med ikke-unikke uniqueids:
select * from submissionsets where migration_uniqueid_fix > 0; |
Hvis problemet ikke eksisterer i produktion, så kan kolonnen 'migration_uniqueid_fix' fjernes efterfølgende (de testdata på testsystemerne, der giver problemer kan så enten slettes eller id'et kan opdateres til noget andet).
Migreringen fra OpenText til SQL script foregår ved at behandle hver række i status-tabellen i opentext-databasen, og gøre følgende:
Fejl logges til senere analyse. Efter endt behandling skrives til DocImportState-feltet i opentext-databasen, om behandlingen lykkedes eller ej. Der skrives ligeledes til migration_properties.
Indlæsning af SQL script i NXRG databasen, gøres vha "source <file>".
Eventuelle fejl vil blive sendt til konsollen og kan læses heri.
I forbindelse med migreringen vil det give mening at definere et sæt af validerings- og verifikationsmekanismer, som vil kunne øge tilliden til, at migreringen er forløbet korrekt. I de kommende afsnit beskrives de validerings- og verifikationsmekanismer, som anvendes i NXRG migreringen.
Det er tanken, at verifikation kan køres både efter initiel load og efterfølgende efter hver deltamigrering, så vi får løbende overblik overblik over korrektheden.
Valideringen for NXRG samt verifikation kører fra en docker container. Se Driftvejledning for detaljer om faktisk kørsel og output format.
Efter migreringen er tilendebragt kan der trækkes en række metrikker ud af hhv xDB og NXRGs mariadb baserede databasesetup.
De følgende metrikker foreslås. Det skal afklares, om det kan lade sig gøre at trække disse ud af både xDB og NXRG.
| Nr | Beskrivelse af validering | NXRG | xDB |
|---|---|---|---|
| 1 | Antal documententries i alt | OK | |
| 2 | Antal documententries fordelt på type (stable/on-demand) | OK | |
| 3 | Antal documententries fordelt på status | OK | |
| 4 | Antal documententries fordelt på typecode | OK | |
| 4.5 | Antal documententries fordelt på version | OK | |
| 5 | Antal forskellige patient-id'er for documententries (id, OID/idtype) | OK | |
| 5.1 | Trække lister ud af patient-id'er for documententries | OK | |
| 5.2 | Antal documententries, som ikke har en association | OK | |
| 6 | Antal submissionsets i alt | OK | |
| 7 | Antal forskellige patient-id'er for submissionsets | OK | |
| 7.1 | Trække lister ud af patient-id'er for submissionset | OK | |
| 7.2 | Antal submissionsets, som ikke har en association | OK | |
| 8 | Antal associations i alt | OK | |
| 9 | Antal forskellige patient-id'er for associations | OK | |
| 9.1 | Trække lister ud af patient-id'er for associations | OK | |
| 9.2 | Antal associations som ikke har documentEntries, submissionsets eller folders | OK | NA |
| 9.3 | Antal associations som peger på forskellige patient-id'er i source og target | OK | |
| 9.3 | Antal associations som peger på folders eller associations | OK | |
| 99 | Antal anvendte patientid assigningauthorityid og assigningauthoritytype | OK | |
| 100 | Udtræk af top-100 cpr numre for documententries (dem med flest), tælle docentries også | OK |
Der er et issue omkring, hvornår valideringen kører, hvis der tikker ny data ind i xDB. Vi antager, at vi kan køre migrering-validering/verifikation-cyklen, uden at det eksisterende OpenText slettejob fjerner data fra xDB (det skal være slået fra). I udtrækket fra xDB er der styr på en skæringsdato, som kan anvendes til at begrænse tælle-queries mod xDB opadtil, hvorfor resultaterne mellem NXRG og xDB ventes at være ens - både efter første migrering og efterfølgende efter deltaerne.
Vi forventer at antallene i 7, 9 og 5 er ens.
Yderligere burde summen over tallene i hhv 2, 3, 4, 4.5 summerere til 1.
9.2 forventes af være 0, tjekkes for at sikre ugyldige associations 9.3 forventesl igeledes at være 0. 99 forventes at være en.
Udover valideringskontrollerne beskrevet ovenfor giver det mening, at det undersøges, om NXRG svarer "det samme" som OpenText registry givet at de mødes af de samme input (søgninger).
Det foreslås derfor, at der foretages en ITI-18 søgning (søger på alle documententries på en række af cprnumre). Der kan tages udgangspunkt i det, der allerede er udviklet i NXRG i forbindelse med integrationstesten.
Verifikationstoolet laver den samme forespørgsel mod NXRG hhv OpenText Registry og sammenligner derefter svaret på følgende måde:
Der kan opstå et issue som i validering i forhold til nye data, der tikker ind. Så verifikationen skal indeholde nok detaljer i diff'en, så vi efterfølgende kan udersøge om diff'en er resultat af nye data.
Der sammenlignes følgende metrikker for hver kørsel (dvs for hvert cpr nummer)
| Beskrivelse af verifikation |
|---|
| Antal document entries i NXRG |
| Antal document entries i OpenText |
| Forskel i antal mellem NXRG og OpenText for document entries |
| Forskel i antal mellem NXRG og OpenText for dokumenter |
| Forskel i antal mellem NXRG og OpenText for associationer |
| Forskel i antalmellem NXRG og OpenText for foldere |
| Forskel i antal mellem NXRG og OpenText ror submissionsets |
| Forskel i antal mellem NXRG og OpenText for referencer |
| Forskel i antal mellem NXRG og OpenText for fejl |
| Forskel mellem NXRG og OpenText for status |
| For document entries: hver document entry konverteres til en XML streng og sammenlignes, hvis forskellig skrives entryuuid til en liste |
| For document entries: findes et entryuuid kun i NXRG skrives det til en liste |
| For document entries: findes et entryuudi kun i OpenText skrives det til en liste |
| Alle kald og svar logges |
De to første variable er for at se, at der kommer data retur i det hele taget. Da de øvrige værdier er sammenligniner, som gerne skulle være 0. Men 0 minus 0 er også 0, så det viser ikke om der er dokumenter i svaret.
Ved sammenligning af document entries i ovenstående anvendes entryuuid som nøgle.
I forbindelse med risikovurderingen af NXRG er blandt andet identificeret følgende to overordnede risici i forhold til idriftsættelsen af NXRG:
I forhold til punkt 1, så har vi i projektet tidligere identificeret dette, og skitseret mitigeringsforslag (se afsnit om Migrering ovenfor).
Punkt 2 handler om, at NXRG skal kunne svare sammenligneligt [med OpenText Registry] på requests fra anvenderne (via samarbejdende NSP services) efter idriftsættelsen. Dette betyder, at et request, der rammer NXRG skal give nogenlunde samme response, som hvis det havde ramt OpenText Registry.
Snitfladerne er velbeskrevne i specifikationerne, og der anvendes samme versioner (Netic må kunne se dette???) af openehealth library i NXRG, som der anvendes i OpenText. Som beskrevet i afsnittet om Validering ovenfor, så er det muligt både på OpenText og på NXRG at disable/enable validering af requests og responses for de enkelte ITI-XX services. Dog vil der sikkert være andre forretningsregler i OpenText, som ikke kan overstyres på denne måde. F.eks. kan vi konstatere, at det ikke er muligt at foretage en ITI-18 søgning uden at angive patientid, mens det er muligt at søge uden at angive statuskode, hvis validering af requests er disablet.
Indtil videre har vi identificeret følgende forslag til mitigeringstrategier i forhold til risikoen for utilsigtede snitfladeændringer i forbindelse med idriftsættelsen af NXRG:
De forskellige strategier kan implementeres uafhængigt og i supplemenet til hinanden. De enkelte punkter gennemgås nedenfor.
Da OpenText Registry er closed source er det ikke muligt ved kodeinspektion at danne sig et overblik over, hvilke valideringer, der findes i OpenText Registry. Vi har forsøgt at køre Tookit Tests op i mod test1 for enkelte test cases, for at give en ide om, hvorledes denne svarer (se NXRG - Testvejledning).
For en endelig anvendelse af dette forslag, skal prod og test1 open text konfigureres ens (hvis ikke allerede) og samtlige eller udvalgte test køres.
I dette forslag går vi efter hurtigt at sætte NXRG i drift. Idriftsættelsen skal ske efter initiel (+ evt delta) migrering af data (dvs. midt november).
Når migreringen er tilendebragt, så burde datagrundlaget for NXRG og OpenText Registry være ens. De to registries burde derfor kunne svare nogenlunde sammenligneligt i efterfølgende requests.
Der udvikles derfor en "xds-registry-duplexer", der er i stand til at sende alle indkommende requests til det "nationale registry" til begge bagvedliggende registries.
Duplexeren venter på at begge registries (OpenText og NXRG) svarer og laver en "sammenligning" af svarene (som minimum om det er gået godt eller ej).
Forskelle i svarene logges og det ene svar (det giver mening at anvende OpenText Registry i en periode) sendes tilbage til den kaldende part.
Fordele: Længere vindue, hvor forskelle kan indentifieres (i prod) og rettes op uden at genere anvendene
Ulemper: Kompleks løsning, der kræver både udvikling (KIT/Arosii?) og idriftsættelse (Netic) af duplexeren samt opfølgning på, hvordan det så går. Fare for at introducere problemer i drift med duplexeren (svartider/fejl/opsætning)
I stedet for "live" at sende requests til både OpenText og NXRG som foreslået i forgående afsnit, kan requests og responses opsamles ved processering af OpenText i produktion og afspilles mod en NXRG efterfølgende.
Igen kan svar sammenlignes (det skal defineres, hvad sammenligningen går ud på).
Fordele: Griber ikke ind i nuværende drift, simplere løsning at implementere (dog skal de defineres, hvordan "anvender tests" skal afvikles: Skal det være en anonymiseret udgave, som KIT skal køre som en del af udviklingen eller skal det være et "testtool", som kan afvikles af Arosii/Netic mod en NXRG i produktion (evt. efter migrering)?
Ulemper: Hvornår er udsnittet af tests "godt nok"? Muligvis en masse opgaver (manuelle?), opfølgning og koordinering.
I dette forslag håber vi, at de requests, der rammer OpenText registry i NSP miljøet Test1 er sammenlignelige med dem, der senere rammer produktion.
Ved at rulle NXRG på test1 og lade anvenderne gå i gang med at bruge det nye registry, så bliver forskelle måske opdaget hurtigere.
Fordele: Kan bare lægges på. Ikke så farligt, da det "bare" er test.
Ulemper: Hvordan identificerer vi problemer og følger op? Hvad gør anvenderne, hvis det ikke virker? Måske rammes test1 også i dag af en masse skrald, som vi ikke skal kunne håndtere?