Formålet med dette dokument er at beskrive systemarkitekturen for NXRG.
Nærværende dokument er tiltænkt udviklere og IT-arkitekter med interesse i NXRG og dens opbygning.
| NSP | National Service Platform |
| NXRG | NXP XDS Registry |
| IHE | Integrating the Healthcare Enterprise (se https://www.ihe.net/) |
I det følgende gives et overblik over NXRG. Først beskrives NXRG i forhold til dennes samarbejdende services og interne arkitektur (modulopdeling etc.)
Efterfølgende beskrives og begrundes den underliggende datamodel.
I nedenstående dokument vises overblik over NXRG. Diagrammet viser både løsningens snitflader og eksterne services, som denne samarbejder med. Derudover vises den NXRGs intern lagdelte opbygning (herunder specificering af ansvarsfordelingen i de forskellige lag i applikation).
NXRG samarbejder med følgende komponenter i NSP infrastrukturen:
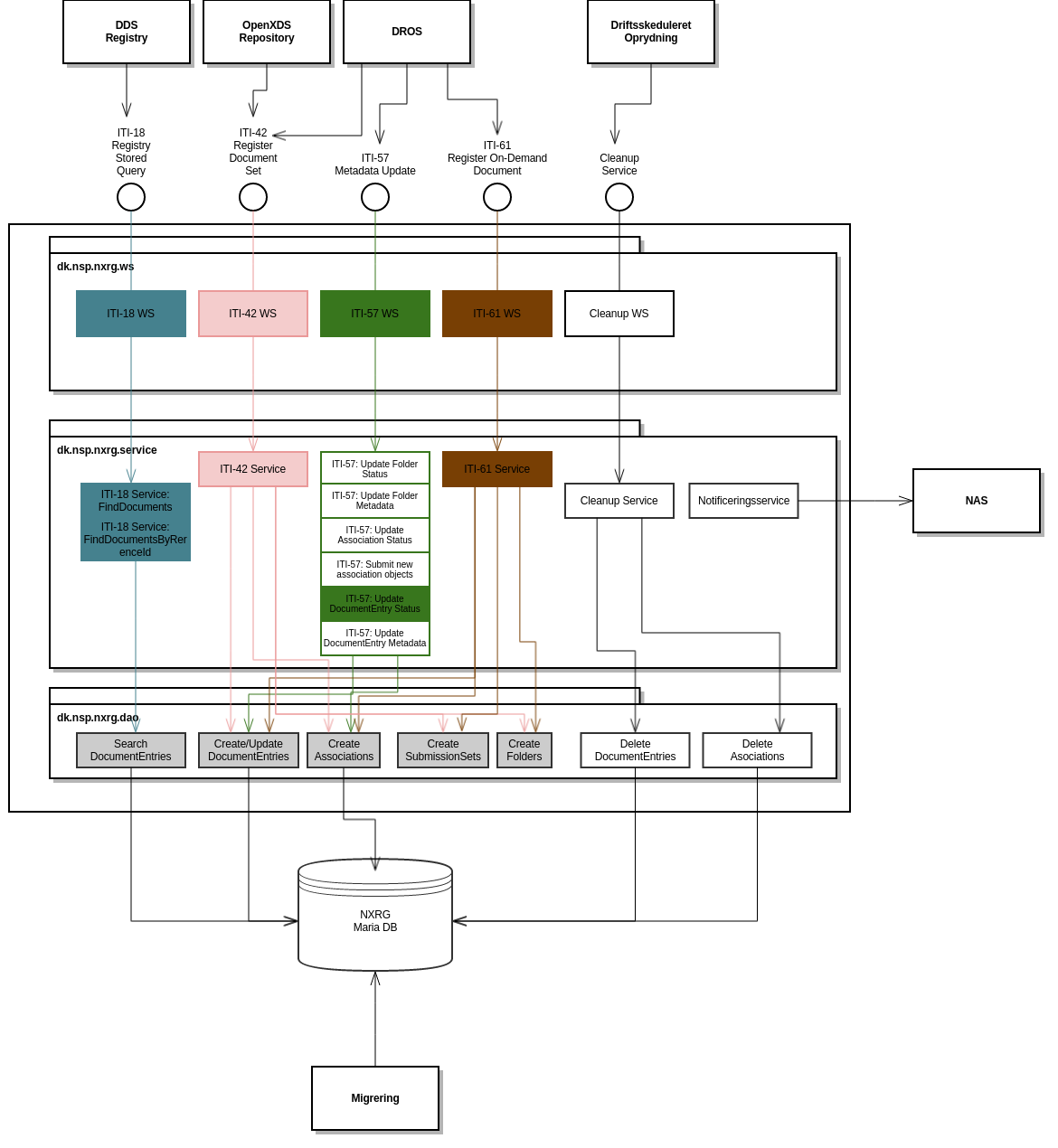
NXRG er opbygge i en lagdelt arkitektur. I ovenstående diagram er pakkenavne specificeret og giver en kobling til den konkrete sourcekode, der realiserer NXRG (se i øvrigt NXRG - Guide til Udviklere).
De udbudte snitflader er realiseret som SOAP webservices (dk.nsp.nxrg.ws). ITI-XX snitfladerne er specificeret i IHE XDS revision 17 fra juli 2020.
Se følgende:
Til at realisere disse ITI-XX snitflader anvendes tredjeparts biblioteker fra IPF Open eHealth Integration Platform til implementations- og hjælpeklasser (herunder mapning af XML baseret model til domænemodel).
Forretningsregler i relation til de udbudte ITI-XX services er implementeret udfra specifikationen af IHE XDS (dk.nsp.nxrg.service). For ITI-18 er det besluttet ikke at understøtte samtlige querytyper, der fremgår af specifikationen, men at nøjes med følende:
Kald af ITI-18 med andre querytyper vil resultere i en fejlkode fra NXRG (se NXRG - Guide til Anvendere).
Forespørgsler valideres efter reglerne beskrevet i IHE XDS specifikationen. Mere præcist udføres validering som beskrevet i følgende afsnit:
Ved validering af forespørgsler skal der sammenlignes patientId'er. Ifølge specifikationen skal denne sammenligning tage højde for sammensmeltning af patientId'er (This comparison shall take into consideration patient identity merges as described in ITI TF-2a: 3.8.4.2.4.). I NXRG er det antaget, at denne form for sammensmeltning ikke forekommer, og sammenligning af patientId'er er derfor implementeret ved simpel strengsammenligning.
NXRG har behov for at persistere data i en database. NXRGs datamodel er realiseret udfra følgende principper:
For en detaljeret beskrivelse af databasemodellen se afsnittet nedenfor.
I forhold til NXRG, så er det ikke hele IHE XDS specifikationen, der implementeres. I de følgende afsnit dokumenteres evt. fravalg og beslutninger ved de enkelte services.
I forhold til fremsøgning, så er det besluttet, at følgende query typer skal understøttes:
Specifikationen beskriver i afsnit "3.57.4.1.3.4 Patient ID Reconciliation", hvordan det skal håndteres, hvis patient-id opdateres som en del af et kald til ITI-57. I forhold til NXRG, så har vi valgt, at denne ikke skal understøtte dette, hvorfor et forsøg på ITI-57 kald, hvor patient id opdateres vil resultere i en fejl til anvenderen.
Patient ID Reconciliation vil resultere i øget kompleksitet i NXRG, og anvendere vil kunne opnå det samme ved f.eks. at deprecate eksisterende data på en patient, og dernæst oprette data på en anden.
Derudover vil anvendelsen af NXRGs ITI-57 service ikke foregå direkte men via DROS - Guide til anvendere. I forhold til auditlogning og diverse tjek, så er de fleste NSP anvender services tænkt til en brug, hvor der er netop én patient i kontekst ad gangen.
Vi vurderer, at skift af patient ID vil skabe øget unødvendig kompleksitet i de anvenderrettede services.
Følgende overblik viser, hvorledes datamodellen i NXGR er opbygget. Datamodellen er opbygget med udgangspunkt i følgende overordnede principper:
I det følgende beskriver vi datamodellen for NXRG og beskriver, hvorledes ovenstående principper er respekteret. Datamodellen præsenteres først i overbliksform i nedenstående E/R-diagram, og de enkelte tabeller beskrives derefter.
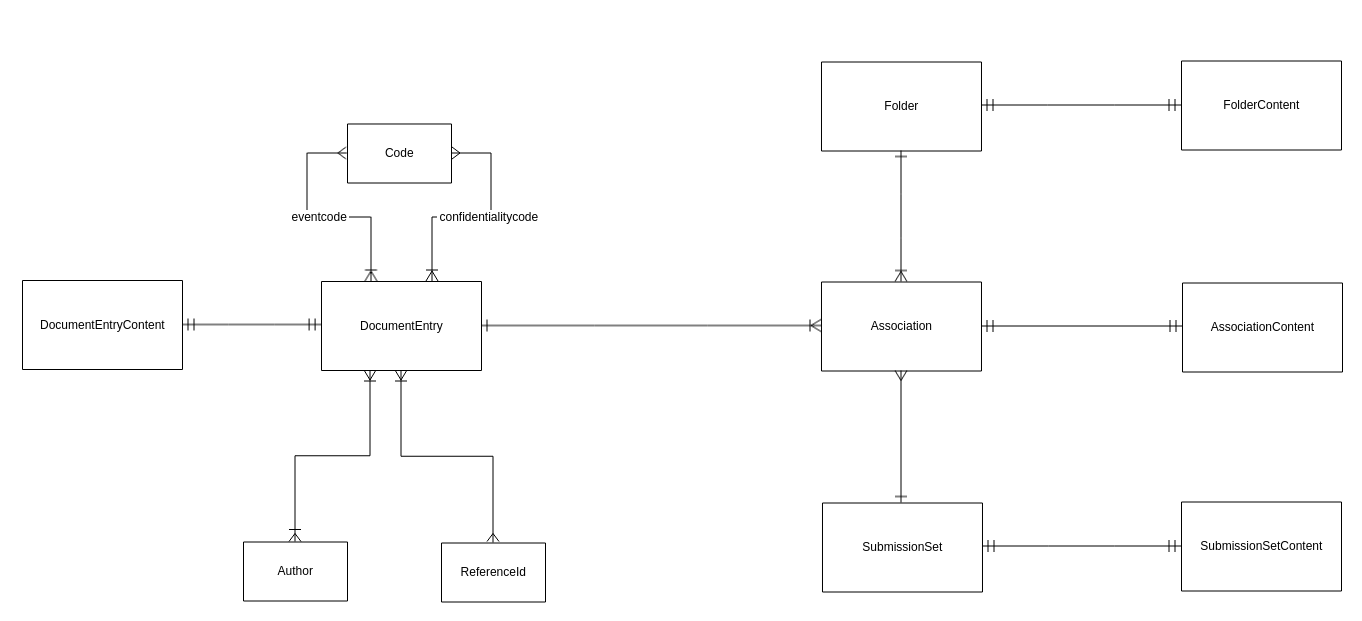
Hver entitet i diagrammet svarer til en tabel. Bemærk at mange-til-mange relationerne mellem DocumentEntry og Author, Code og ReferenceId er realiseret ved brug af relationstabeller, men at disse for overblikkets skyld er udeladt i diagrammet.
De vigtigste entiteter er Association, DocumentEntry, Folder og SubmissionSet, som er NXRG's repræsentation af de tilsvarende begreber fra IHE-specifikationen. I det følgende kaldes disse fire tabeller for objekttabeller. En række i en objekttabel svarer til et tilsvarende objekt, f.eks. svarer en række i Association-tabellen til et Association-objekt, en række i DocumentEntry-tabellen til et DocumentEntry-objekt, osv. Disse tabeller indeholder de attributter som der er brug for, for at NXRG kan realisere sine snitflader. Tabellerne er dog ikke fulstændige modeller af de objekter, de repræsenterer, da det er ganske omfattende at udarbejde og vedligeholde en sådan datamodel. De fulde objekter gemmes i stedet som xml i en tilhørende *Content-tabel (i det følgende kaldet en indholdstabel).
Objekttabellerne indeholder de attributter der er nødvendige for at understøtte søgning gennem ITI18-snitfladen, samt for at tjekke forretningsregler i ITI42-, ITI57- og ITI61-snitfladerne. Indholdstabellerne indeholder selve objekterne i et xml-format, der er nemt at parse og serialisere, men besværligt at søge i.
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| entryuuid | Uuid, der identificerer Association-objektet. | nej | x | varchar(64) |
| sourceuuid_association | Entryuuid på source, hvis denne er en Association. | varchar(64) | ||
| sourceuuid_documententry | Entryuuid på source, hvis denne er et DocumentEntry. | varchar(64) | ||
| sourceuuid_folder | Entryuuid på source, hvis denne er en Folder. | varchar(64) | ||
| sourceuuid_submissionset | Entryuuid på source, hvis denne er et SubmissionSet. | varchar(64) | ||
| targetuuid_association | Entryuuid på target, hvis denne er en Association. | varchar(64) | ||
| targetuuid_documententry | Entryuuid på target, hvis denne er et DocumentEntry. | varchar(64) | ||
| targetuuid_folder | Entryuuid på target, hvis denne er en Folder. | varchar(64) | ||
| targetuuid_submissionset | Entryuuid på target, hvis denne er et SubmissionSet. | varchar(64) | ||
| associationcontentid | Reference til række i AssoociationContent-tabellen. | nej | x | int(11) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| migrationerror | Angivelse af eventuel migreringsfejl. | varchar(128) | ||
| xml | Det rå objekt i ebxml 3.0-format. | blob |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| migrationerror | Angivelse af eventuel migreringsfejl. | varchar(128) | ||
| xml | Det rå objekt i ebxml 3.0-format. | blob |
En af de grundlæggende datatyper i et XDS Registry er DocumentEntry. Dette objekt beskriver en indexering af et dokument, der så senere kan hentes i et XDS Repository. Da ITI-XX snitfladerne er SOAP baserede er det i sidste ende XML, der skal returneres fra snitfladerne i NXRG. Det nuværende OpenText Registry baserer sig på en XML database (xDB), som indeholder sådanne XML baserede strukturer.
Indholdet i xml feltet i DocumentEntryContent er det rå XML, der beskriver sådan en DocumentEntry.
For at kunne understøtte de udbudte ITI-XX services er det nødvendigt at kunne søge på udvalgte felter i en DocumentEntry. Disse søgbare felter er trukket ud af den lagrede XML og lagres i den relaterede tabel DocumentEntries. En reference documentEntryId i DocumentEntryContent vedligeholder 1-0 relationen mellem de to tabeller.
I forhold til migrering er det således nødvendigt at loade XML ind i DocumentEntryContent tabellen. Migreringsfunktionaliteten (se nedenfor) anvender denne tabel som dens input.
Denne tabel er den søgbare udgave af det data, der ligger i DocumentEntryContent. Behovet for fremsøgning er i høj grad påvirket af kravene fra de enkelte ITI-XX services og i ITI-18's tilfælde i kravene fra de understøttede query typer. Nedenstående tabel er en oversigt over, hvilke elementer der findes i DocumentEntry (se ITI TF-3). Hvert af DocumentEntry's attributter giver anledning til en kolonne i tabellen.
De enkelte rækker i tabellen viser, hvilke attributter, som de enkelte ITI-XX transaktioner er afhængige af at kunne søge på (for ITI-18 listes de enkelte QueryTypes, der understøttes af NXRG). De øvrige ITI-XX services kan også have behov for at kunne fremsøge DocumentEntry's i forbindelse med validering af forrretningsregler. Forretningsreglen er markeret med en afsnitshenvisning til det afsnit i ITI-TF-2b som beskriver den konkrete forretningsregel.
| DocumentEntry | ITI-18 (FindDocuments) | ITI-18 (FindDocumentsByReferenceId) | ITI-42 (forretningsregler) | ITI-57 (forretningsregler) | ITI-61 (forretningsregler) |
|---|---|---|---|---|---|
| author.authorInstituion | |||||
| author.authorPerson | x (liste) | x (liste) | |||
| author.authorRole | |||||
| availabilityStatus | x (liste) | x (liste) | |||
| classCode(code) | x (liste) | x (liste) | |||
| comments | |||||
| confidentilityCode(code) | x (liste) | x (liste) | |||
| creationTime | x (interval) | x (interval) | |||
| entryUuid | 3.42.4.1.3.5(opslag) | ||||
| eventCodeList(list<code>) | x (flere lister) | x (flere lister) | |||
| formatCode(code) | x (liste) | x (liste) | |||
| hash(string) | 3.42.4.1.3.3.1(brug) | ||||
| healthcareFacilityTypeCode(code) | x (liste) | x (liste) | |||
| homeCommunityId(string) | |||||
| languageCode | |||||
| legalAuthenticator | |||||
| limitedMetadata | |||||
| mimeType | |||||
| objectType(stable/on-demand) | x (højst een) | x (højst een) | |||
| patientId | x (netop een) | x (netop een) | 3.42.4.1.3.5(brug) | ||
| practiceSettingCode(code) | x (liste) | x (liste) | |||
| referenceIdList | x (liste) | ||||
| reposistoryUniqueId(string) | |||||
| serviceStartTime | x (interval) | x (interval) | |||
| serviceStopTime | x (interval) | x (interval) | |||
| size | 3.42.4.1.3.3.1(brug) | ||||
| sourcePatientId | |||||
| sourcePatientInfo | |||||
| title | |||||
| typeCode | x (liste) | x (liste) | |||
| uniqueId | 3.42.4.1.3.3.1(opslag) | ||||
| URI |
NXRGs datamodel er normaliseret i forhold til alle behov beskrevet i tabellen ovenfor. D.v.s alle attributter, der anvendes af en ITI-XX er trukket ud og er en del af den søgbare tabel DocumentEntries.
Attributter, der ikke refereres af ovenstående tabel vil ikke være en del af DocumentEntries, men vil udelukkende persisteres som en del af xml feltet i tabellen DocumentEntryContent.
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| migrationerror | Angivelse af eventuel migreringsfejl. | varchar(128) | ||
| xml | Det rå objekt i ebxml 3.0-format. | blob |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| Feltnavn | Beskrivelse | Optional | Unik nøgle | Datatype |
|---|---|---|---|---|
| id | Intern, unik nøgle. | nej | x | int(11) |
| migrationerror | Angivelse af eventuel migreringsfejl. | varchar(128) | ||
| xml | Det rå objekt i ebxml 3.0-format. | blob |
Migrering af data fra OpenText Registry til NXRG skal sikre, at al data, der ligger i OpenText Registry overføres til NXRG på en måde, så data bevares: Det vil sige, at de data, der kan udsøges gennem NXRGs snitflader svarer 1:1 til det data, der kan udsøges gennem OpenText Registrys snitflader.
Den interne datarepræsentation vil ændre sig fra OpenText Registry til NXRG, men det logiske data skal bevares.
Der har i forbindelsen med migreringen været arbejdet med nedenstående diagram for at komme frem til en migreringsstrategi.
.jpg")
Diagrammet viser de forskellige niveauer, som data kan eksporteres henholdsvis importeres på. De forskellige muligheder er blevet diskuteret på workshops, og fravalg og tilvalg er dokumenteret på diagrammet.
Konklusionen på analysearbejdet er således, at:
Der har været et ønske om at kunne lave løbende (delta)migreringer af OpenText data til NXRG. Dette ønske bunder i, at der i produktion i dag er ca 11 mio XDS objekter (submissionsets med associations samt document entries) i OpenText Registry databasen.
Selv med et effektitivt migreringstool, så vil det tage tid (< 5 dage) at migrere al data. Hvis en migreringsstrategi kræver et servicevindue, så vil dokumentdeling på NSP være utilgængeligt i flere dage, hvilket er blevet vurderet til problematisk.
Da driften kan trække liste over nye/opdaterede data i OpenText Registry (se pkt 1 ovenfor) er det muligt at lave en trinvis migrering. Dette betyder yderligere, at det bliver muligt at komme i gang med migreringen på et tidligere tidspunkt (da det kan foretages uden at der skal meldes servicevinduer ud).
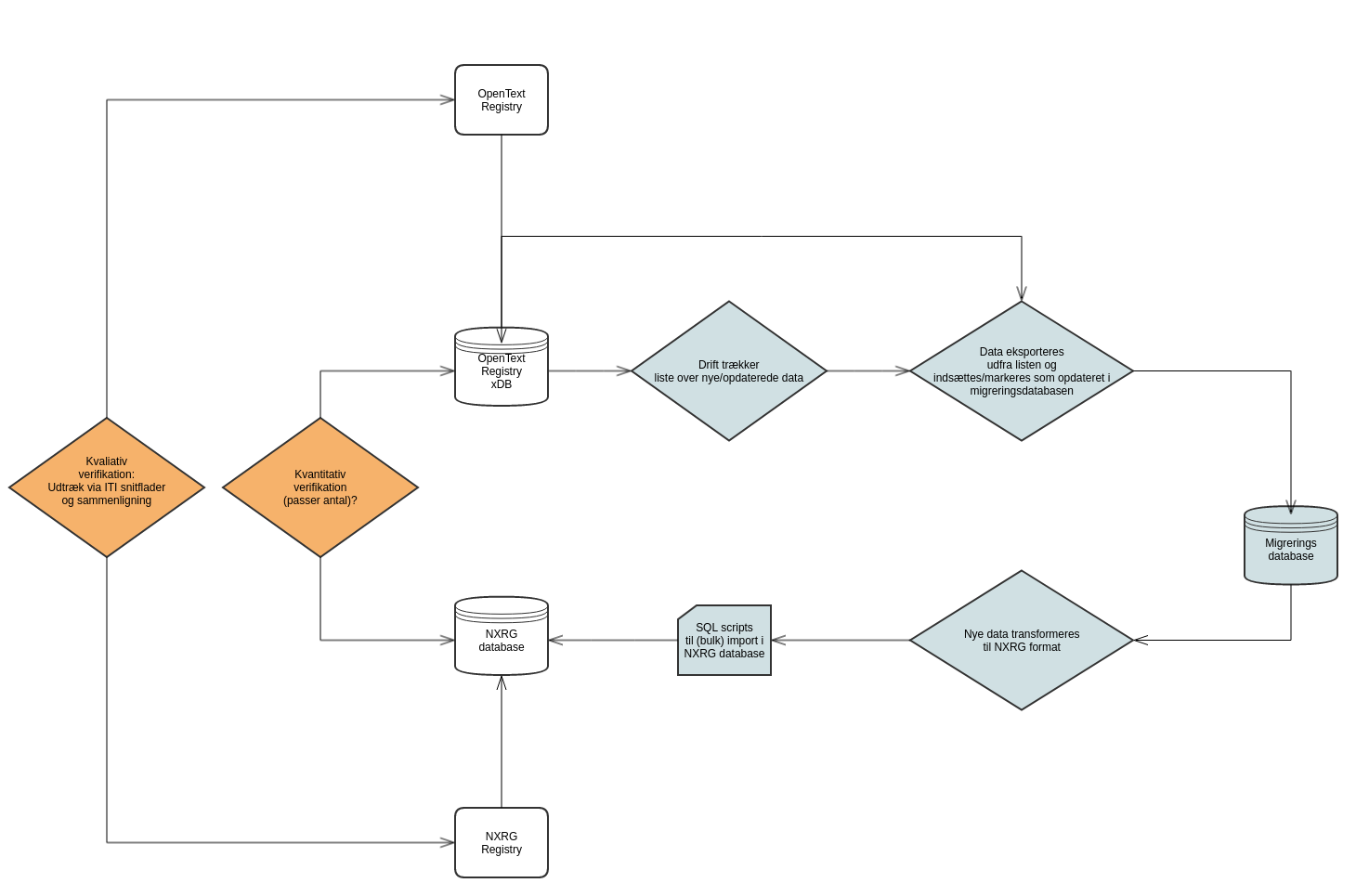
Migreringsprocessen er markeret med blå i diagrammet ovenfor. Det er tanken at bevare Migreringsdatabasen efterfølgende som en backup for OpenText Registry data. Når licensen udløber for xDB databasen, så vil migreringsdatabasen være masterdata (i tilfælde af, at man skulle opdage fejl i import til NXRG efterfølgende).
Der skal laves verifikation af migreringsprocessen - både en kvantitativ verifikation og en kvalitativ verifikation. Denne del af processen er beskrevet nedenfor.
Dataene fra OpenText registry'et i en MariaDB-database, som deles mellem eksport- og import-jobbet. Databasen indeholder to tabeller, contents og status. Tabellernes indhold beskrives nedenfor. Man kan hente et eksempel-datasæt på .
| Feltnavn | Datatype | Indhold |
|---|---|---|
| PID | bigint(20) | Unik nøgle. |
| RowModified | timestamp | Angivelse af, hvornår rækken sidst er opdateret. |
| DocID | varchar(255) | Id på dokument. |
| content | mediumblob | XML-repræsentation af dokumentet (kan være enten submissionset eller document). |
| Feltnavn | Datatype | Indhold |
|---|---|---|
| PID | bigint(20) | Unik nøgle. |
| RowModified | timestamp | Angivelse af, hvornår rækkken sidst er opdateret. |
| DocID | varchar(255) | Id på dokument. Refererer til DocID-kolonnen i contents-tabellen. |
| DocDate | timestamp | Angivelse af, hvornår dokumentet er oprettet. |
| DocExportState | int(11) | Status-felt, der bruges til at angive om et dokument er blevet eksporteret eller ej. Kan antage følgende værdier: 0 (NotReady), 1 (Ready), 2 (Migrating), 100 (Migrated). |
| DocImportState | int(11) | Status-felt, der bruges til at angive om et dokument er blevet importeret eller ej. Kan antage følgende værdier: 0 (NotReady), 1 (Ready), 2 (Migrating), 100 (Migrated). |
OpenText registry'et eksporterer sine data i et xml-format, som der ind til videre ikke er tilvejebragt noget schema for. Nedenfor kan man se et eksempel på et submissionset og et tilhørende document i dette format.
<?xml version="1.0"?>
<submissionSet id="urn:uuid:255d0bef-db11-482d-b2bd-dca0053d8045">
<xds:submissionSet xmlns:xds="http://www.openehealth.org/ipf/xds">
<entryUuid>urn:uuid:255d0bef-db11-482d-b2bd-dca0053d8045</entryUuid>
<logicalUuid>urn:uuid:255d0bef-db11-482d-b2bd-dca0053d8045</logicalUuid>
<version>
<versionName>1</versionName>
</version>
<uniqueId>7020798514690154282.7024117544796833076.1568187071790</uniqueId>
<patientId extension="2606481234" root="1.2.208.176.1.2"/>
<availabilityStatus>Approved</availabilityStatus>
<title language="en-US">769a1dbf-2c73-4cca-98b9-9c045231f309</title>
<limitedMetadata>false</limitedMetadata>
<sourceId>7020798514690154282.7024117544796833076.1568187071790</sourceId>
<submissionTime>2013-02-17T08:15:00Z</submissionTime>
<author>
<authorPerson>
<id/>
<name>
<given>M</given>
<family>Madsen</family>
</name>
</authorPerson>
<authorInstitution>
<idNumber>77668685</idNumber>
<assigningAuthority universalId="1.2.208.176.1.2" universalIdType="ISO"/>
<name>Odense Universitetshospital, Odense</name>
</authorInstitution>
</author>
<contentTypeCode code="NscContentType" codeSystemName="urn:uuid:aa543740-bdda-424e-8c96-df4873be8500" displayName="NscContentType"/>
</xds:submissionSet>
<xds:associations xmlns:xds="http://www.openehealth.org/ipf/xds">
<xds:association>
<entryUuid>urn:uuid:1b1d1134-c1d9-4a88-add6-3d580aadfed7</entryUuid>
<sourceUuid>urn:uuid:255d0bef-db11-482d-b2bd-dca0053d8045</sourceUuid>
<targetUuid>urn:uuid:5e6ac9ef-4633-46ea-96b1-786a948e7bb6</targetUuid>
<associationType>HasMember</associationType>
<label>Original</label>
<originalStatus>Approved</originalStatus>
<newStatus>Approved</newStatus>
<availabilityStatus>Approved</availabilityStatus>
</xds:association>
</xds:associations>
</submissionSet> |
<?xml version="1.0"?>
<document id="urn:uuid:da51d7ce-1a18-48ca-ba5f-03b0be78b906">
<xds:documentEntry xmlns:xds="http://www.openehealth.org/ipf/xds">
<entryUuid>urn:uuid:da51d7ce-1a18-48ca-ba5f-03b0be78b906</entryUuid>
<logicalUuid>urn:uuid:da51d7ce-1a18-48ca-ba5f-03b0be78b906</logicalUuid>
<version>
<versionName>1</versionName>
</version>
<uniqueId>437f8b60-9563-11e3-a5e2-0800200c7020^1.2.208.184</uniqueId>
<patientId extension="2606481234" root="1.2.208.176.1.2"/>
<availabilityStatus>Approved</availabilityStatus>
<title language="en-US">Hjemmemonitorering for 2606481234</title>
<limitedMetadata>false</limitedMetadata>
<sourcePatientId extension="2606481234" root="1.2.208.176.1.2"/>
<sourcePatientInfo>
<name>
<given>Janus</given>
<family>Berggren</family>
</name>
<gender>M</gender>
<birthTime>1948-06-26T00:00:00Z</birthTime>
</sourcePatientInfo>
<creationTime>2013-02-17T08:15:00Z</creationTime>
<author>
<authorPerson>
<id/>
<name>
<given>M</given>
<family>Madsen</family>
</name>
</authorPerson>
<authorInstitution>
<idNumber>77668685</idNumber>
<assigningAuthority universalId="1.2.208.176.1.2" universalIdType="ISO"/>
<name>Odense Universitetshospital, Odense</name>
</authorInstitution>
</author>
<legalAuthenticator>
<id/>
<name>
<given>Lars</given>
<family>Olsen</family>
</name>
</legalAuthenticator>
<serviceStartTime>2013-02-11T08:11:00Z</serviceStartTime>
<serviceStopTime>2013-02-16T10:14:00Z</serviceStopTime>
<classCode code="001" codeSystemName="1.2.208.184.100.9" displayName="Clinical report"/>
<confidentialityCode code="N" codeSystemName="2.16.840.1.113883.5.25" displayName="N"/>
<eventCode code="NPU03011" codeSystemName="1.2.208.176.2.1" displayName="O2 sat.;Hb(aB)"/>
<eventCode code="MCS88016" codeSystemName="1.2.208.184.100.8" displayName="FVC"/>
<formatCode code="urn:ad:dk:medcom:appointmentsummary:full" codeSystemName="1.2.208.184.100.10" displayName="DK Appointment Summary Document schema"/>
<healthcareFacilityTypeCode code="550621000005101" codeSystemName="2.16.840.1.113883.6.96" displayName="hjemmesygepleje"/>
<languageCode>da-DK</languageCode>
<practiceSettingCode code="419192003" codeSystemName="2.16.840.1.113883.6.96" displayName="intern medicin"/>
<typeCode code="53576-5" codeSystemName="2.16.840.1.113883.6.1" displayName="Personal Health Monitoring Report"/>
<repositoryUniqueId>1.2.208.176.43210.8.10.11</repositoryUniqueId>
<mimeType>text/xml</mimeType>
<size>27302</size>
<hash>da39a3ee5e6b4b0d3255bfef95601890afd80709</hash>
<type>stable</type>
</xds:documentEntry>
</document>
|
For at lette implementeringen af migreringen er der indført en staging-database. Denne database har samme schema som nxrg-databasen, men har foreign key- og unique key-constraints slået fra. Migreringen består af to faser:
1. Overførsel af data fra opentext-databasen til staging-databasen.
2. Overførsel af data fra staging-databasen til nxrg-databasen.
Denne stuktur er valgt af følgende grunde:
- Mulighed for at tjekke integritet af data i staging-databasen før indlæsning i nxrg-databasen.
- Mulighed for at få den endelige indlæsning til at køre hurtigt.
- Mulighed for håndtering af deltaer: Hvis f.eks. et allerede konverteret DocumentEntry bliver deprecated, så skal migreringen kunne håndtere dette.
Fase 1 er implementeret som en java kommandolinje-applikation. Fase 2 er implementeret med select into/load data-metoden. For flere detaljer henvises til projektets udviklerguide.
Migreringen fra OpenText til staging-databasen foregår ved at behandle hver række i status-tabellen i opentext-databasen, og gøre følgende:
Fejl logges til migreringsloggen til senere analyse. Efter endt behandling skrives til DocImportState-feltet i opentext-databasen, om behandlingen lykkedes eller ej.
Overførslen af data fra staging-databasen til nxrg-databasen foregår ved brug af select into/load data-metoden, som er beskrevet i mariadb-dokumentationen: https://mariadb.com/kb/en/how-to-quickly-insert-data-into-mariadb/.
TODO