Page History
...
| Table of Contents |
|---|
Introduktion
Formål
Formålet med dette dokument er at beskrive systemarkitekturen for GM-BFF.
Læsevejledning
Nærværende dokument er tiltænkt udviklere og IT-arkitekter med interesse i GM-BFF og dens opbygning.
Definitioner og referencer
| NSP | National Service Platform |
| GM | Graviditetsmappen |
Overblik over GM-BFF
Graviditetsmappens Backend For Frontend (GM-BFF) er en service, som skal servicere MinGraviditet app. Den følger BFF mønsteret (https://samnewman.io/patterns/architectural/bff/), hvilket resulterer i en række operationer, der stiller data til rådighed i klumper tilpasset klientens (appens) behov, uanset at disse kan komme fra flere datakilder eller i strukturer der ikke egner sig til appens brug. BFF'en har til opgave at sammenstille og omforme data efter appens behov.
1Gliffy Diagram macroId 7a93aae7-1fd2-43dd-a8e5-454c52b0acbf displayName gm-bff component overview name gm-bff component overview pagePin 2
BFF'en henter data fra 2 kilder: gm-facade på NSP for journaldata og CMS for artikler , og tekster og tjeklister. Journal data caches i en lokal database, for at undgå gentagne opslag efter de samme data. BFF udstiller søgning i CMS via Meilisearch.
Løsningens afhængigheder
BFF'en udstilles som en Spring Boot server med et REST API.
CMS er en Strapi (https://strapi.io/) instans, hostet i samme kubernetes miljø som BFF'en. Strapi stiller et API til rådighed til udlæsning af ressourcer i Strapi, fx kategorier, artikler eller tjeklister. API'et er et REST agtigt api med en lidt speciel syntaks for søgninger og specificering af returnerede værdier. Disse særheder gemmes bag BFF'en, så appen kan få et API der er lettere at arbejde med.
gm-facade komponenten ligger på NSP, og udstiller en FHIR model for graviditetsmappen. Da der ikke er indført et forløbsbegreb eller lignende strukturerende begreber, er der kun én operation på gm-facade, nemlig "hent hele journalen for den angivne borger". Denne udstilles i en FHIR model som BFF læser og omformer til en intern model, der benyttes til de enkelte operationer på BFF.
Løsningens arkitektur
Internt er BFF'en struktureret i delkomponenter som følger:
...
Ovenstående sekvensdiagram ignorerer to yderligere kompleksiteter, nemlig cachen af journaldata og sammenstilling af journaldata med CMS indhold. Sammenstilling af data foregår ved at data hentes fra CMS (fx i dette tilfælde ordforklaringer) og fra gm-facaden, og i mapperen plukkes data så fra hhv. CMS'ens eller gm-facadens returnerede data.
Cache
Caching foregår ved at UnstructuredJournal objektet serialiseres til JSON og gemmes i databasen. Ved senere operationer for samme borger checkes i databasen om der er en cachet værdi der kan bruges, og i så fald undgås kaldet til gm-facaden.
Svar fra gm-facaden caches i lokal database for gm-bff.
Nøglen Nøglen til opslag i cachen er borgerens CPR (taget fra bearer token) kombineret med BFF'ens release nummer. CPR er fordi det er borgerens journal... BFF'ens release nummer er for at gamle cachede data ikke genbruges med potentielle kodeændringer, der gør man ikke kan læse det cachede korrektDette sikre at en ny version af gm-bff vil invalidere cachen og data hentes igen fra gm-facade.
Cachen er tidsbegrænset, dvs. en cachet værdi genbruges kun hvis den er hentet for nyligt. Hvor lang tid cachen skal gælde er konfigurerbart, men er i udgangspunktet konfigureret til en halv time. Dog er det lavet sådan at hver gang man bruger data nulstilles uret. Så hvis man læser journalen op og lægger den i cachen, og så læser den igen 20 minutter senere, vil den så igen gælde 30 minutter derfra, altså 50 minutter i alt, hvis den ikke tilgås igen inden.
...
For de lukkede endpoints er adgangskontrollen baseret på bearer token sikkerhed i form af json web tokens med standarden JTP-H. Tokens valideres for gyldighed, for issuer og for om de har det forventede scope. Det givne token sendes i øvrigt videre med til kald på gm-facaden.
BFF'en kobles på sundhedsdatanettet til al adgang til NSP'en.
Driftsmiljø og netværk
BFF og CMS driftes separat fra NSP, i et TCS (Trifork Cloud Stack) Kubernetes miljø. Al indgående og udgående trafik går gennem Kubernetes Ingress, hvor udstillede end points, routing, TLS terminering og IP-whitelisting håndteres.
BFF'en og de omkringliggende komponenter i driftsmiljøet, og hvordan de kommunikerer, er vist i nedenstående diagram.
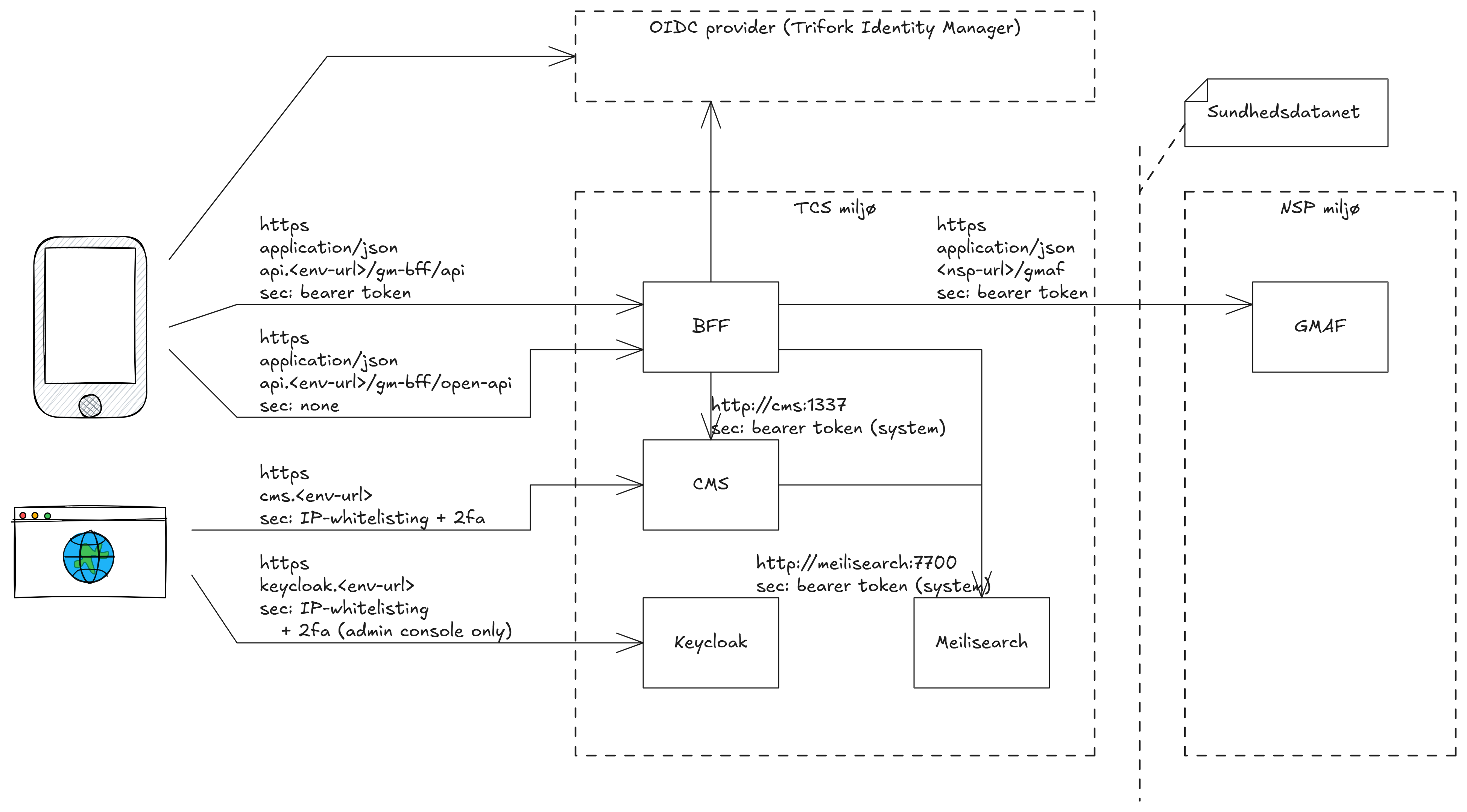
Her illustreres hvordan appen tilgår OIDC providere og hhv lukkede og åbne endpoints på BFF'en, mens CMS Admin konsollen tilgår CMS komponenten, samt Keycloak til to-faktor login.
BFF komponenten udstiller lukkede endpoints, der kræver en gyldig JTP-H bearer token (til alt der indeholder persondata), og åbne endpoints, der ikke har nogen sikkerhedskrav (til artikler mm. fra CMS'en). Begge grupper af end points udstilles kun på HTTPS.
Internt i TCS driftsmiljøet, snakker komponenterne sammen via interne definerede netværk, der er konfigureret i TCS miljøet og ikke tilgængelige udefra. Disse kommunikerer via HTTP for at mindske overhead. CMS'en opdaterer Meillisearch indexet ved opdateringer til artikler, og BFF tilgår CMS servicen og Meilisearch indexet.
BFF'en snakker med OIDC provideren ved validering af tokens, og endelig snakker BFF'en med GMAF (GM facade) på NSP. Al kommunikation til NSP foregår via tilkobling til sundhedsdatanettet.
Dokument Historik
| 3/4 2025 | Martin Henriksen/SDS | Etablering af dokumentation |
| 22/7 2025 | Anders Ringsmose/Trifork | Beskrivelse af arkitektur |
| 15/9 2025 | Thomas Glæsner/Trifork | Mindre rettelser |