Page History
...
Cluster med to servere, der begge benyttes
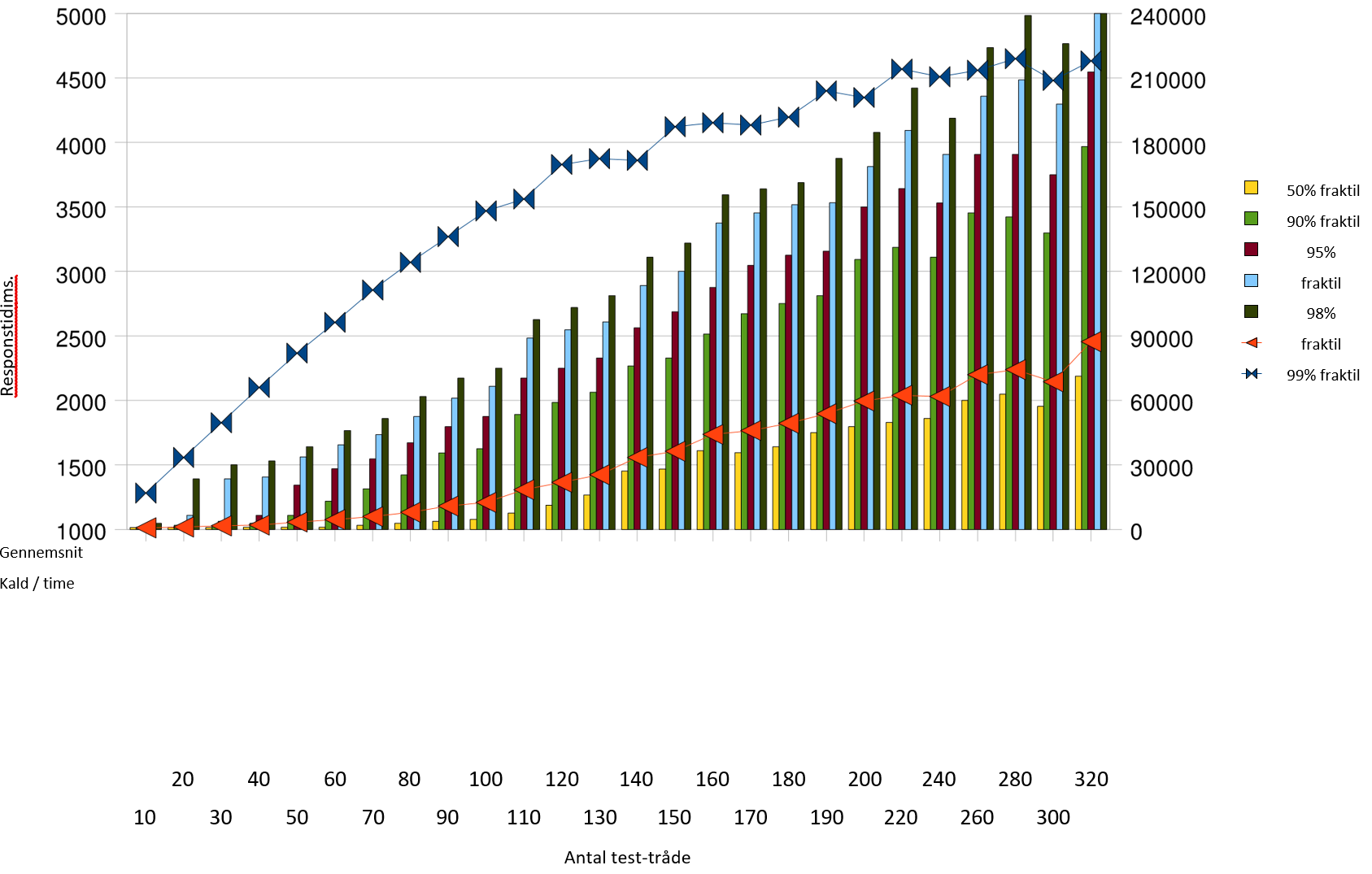
Bemærk at grafen her og i skaleringstest- afsnittet har forskellige skalaer på de begge akser og dermed skal sammenlignes med varsomhed. Ved omkring 150.000
kald pr. time rammer 95% fraktilen grænsen på 1 sekund. Det er en klar forbedring over de ca. 90.000 fra enkelt-server testen. Det er muligt at gennemføre omkring 210.000 kald pr. time i denne konfiguration, med acceptable svartider, der dog ikke lever op til kravet til 95% fraktilen.
Ved belastning over 150.000 kald pr. time begynder der at opstå fejl, som det ses af søjlen Fejl rate . Denne angiver hvor mange kald, der fejlede ud af det totale antal, der er forsøgt gennemført. Fejlene består i, at der rammes en anden server efter et login, og at denne endnu ikke kender id-kortet, hvorfor den svarer implicit login.
...
Vi sammenligner her resultaterne af skaleringstesten for 60 tråde med loadbalanceringstesten for 60 tråde. De 60 tråde er den højest målte belastning, hvor svartiderne overholdes i skaleringstesten.
| Antal |
|---|
| Tråde | Kald / time |
|---|
Gennemsnit |
|---|
| 50% fraktil | 90% fraktil | 95% fraktil | 98% fraktil | 99% fraktil |
|---|
...
| 1 | 86242 | 1303 | 1187 | 1766 | 1938 | 2125 | 2297 |
| 2 | 96300 | 1076 | 1016 | 1218 | 1469 | 1656 | 1765 |
Det samme antal tråde når at gennemføre flere kald på grund af den gennemgående lavere svartid. Gennemsnitssvartiden falder fra 303 ms til 76 ms, mens 95% fraktilen halveres fra 938 ms til 469 ms. Der altså en markant forbedring i svartid for brugerne ved at benytte to servere frem for en.
Loadbalancering af SOSIGW
Blå grafer viser én server, røde viser to.
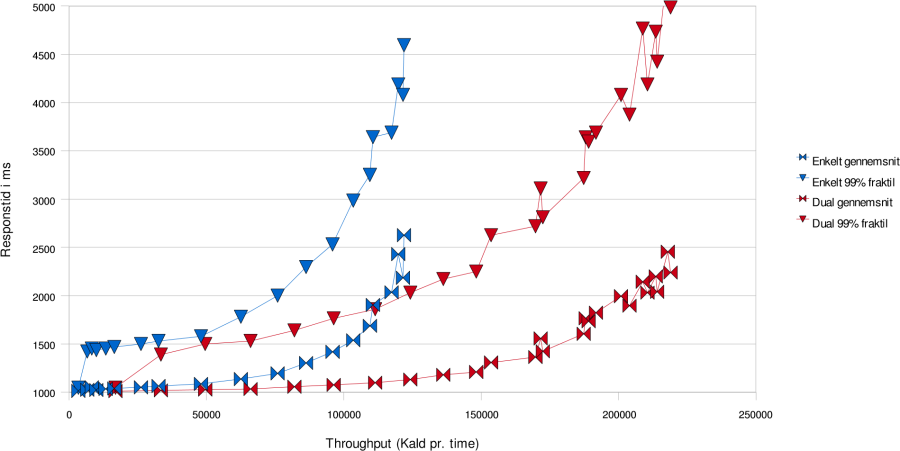
Denne graf viser hvordan svartiderne udvikler sig i skaleringstesten og loadbalanceringstesten. Det ses at det er muligt at have væsentligt større belastning med rimelige svartider ved to servere i forhold til en. I den følgende graf ses det at der også ved lavere belastninger er en genvist ved at benytte to servere frem for en, idet det er muligt at holde 99% fraktilen meget lavere. Loadbalancering af SOSIGW
Blå grafer viser én server, røde viser to.
050001000015000200002500030000350001000110012001300140015001600Enkelt gennemsnitEnkelt 99% fraktilDual gennemsnitDual 99% fraktilThroughput (Kald pr. time)Responstid i ms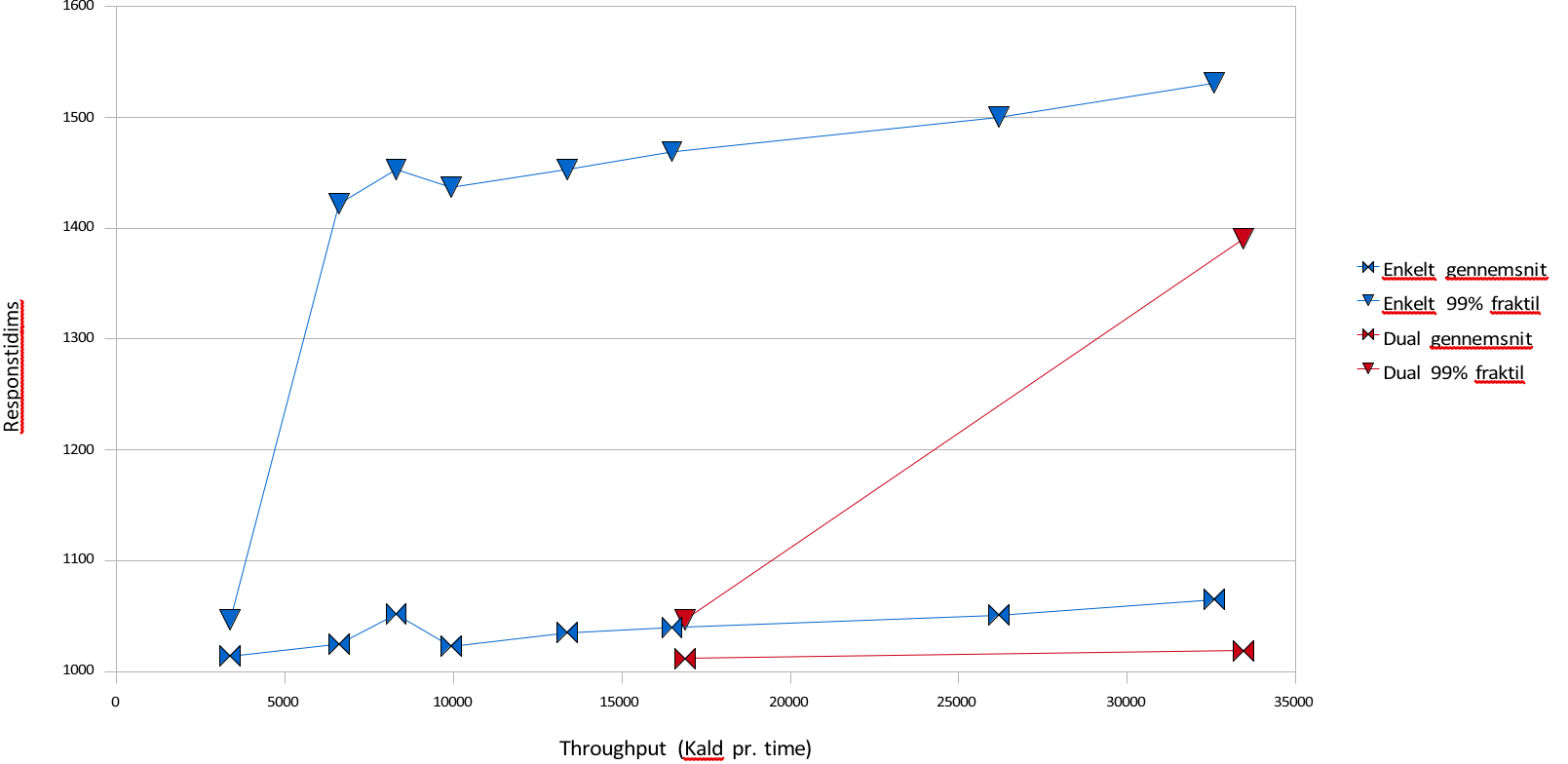
Load/stresstest
I forlængelse af skaleringstesten fastslås den belastningsgrad hvor throughput ikke længere stiger som funktion af antal afsendte requests. Det verificeres, at overbelastning ikke fører til fejlbehandlede requests samt at systemet efterfølgende kommer sig uden nogen blivende degradering. I praksis udføres denne test ved at udføre loadbalanceringstesten med noget højere belastning end den viste sig at kunne bære, og derefter udføre samme tests lave belastninger. Derefter sammenlignes resultatet med resultatet fra loadbalanceringstesten og det verificeres at der ikke forekommer fejl, samt at svartiden falder i takt med belastningen, til samme niveau som før overbelastningen. 1500025000350004500055000650007500085000950001000120014001600180020002200Svartider
Svartider før og efter stress testGennemsnit, før95% fraktil, før99% fraktil, førGennemsnit, efter95% fraktil, efter99% fraktil, efterthroughput, kald pr. timeResponstid i mstest
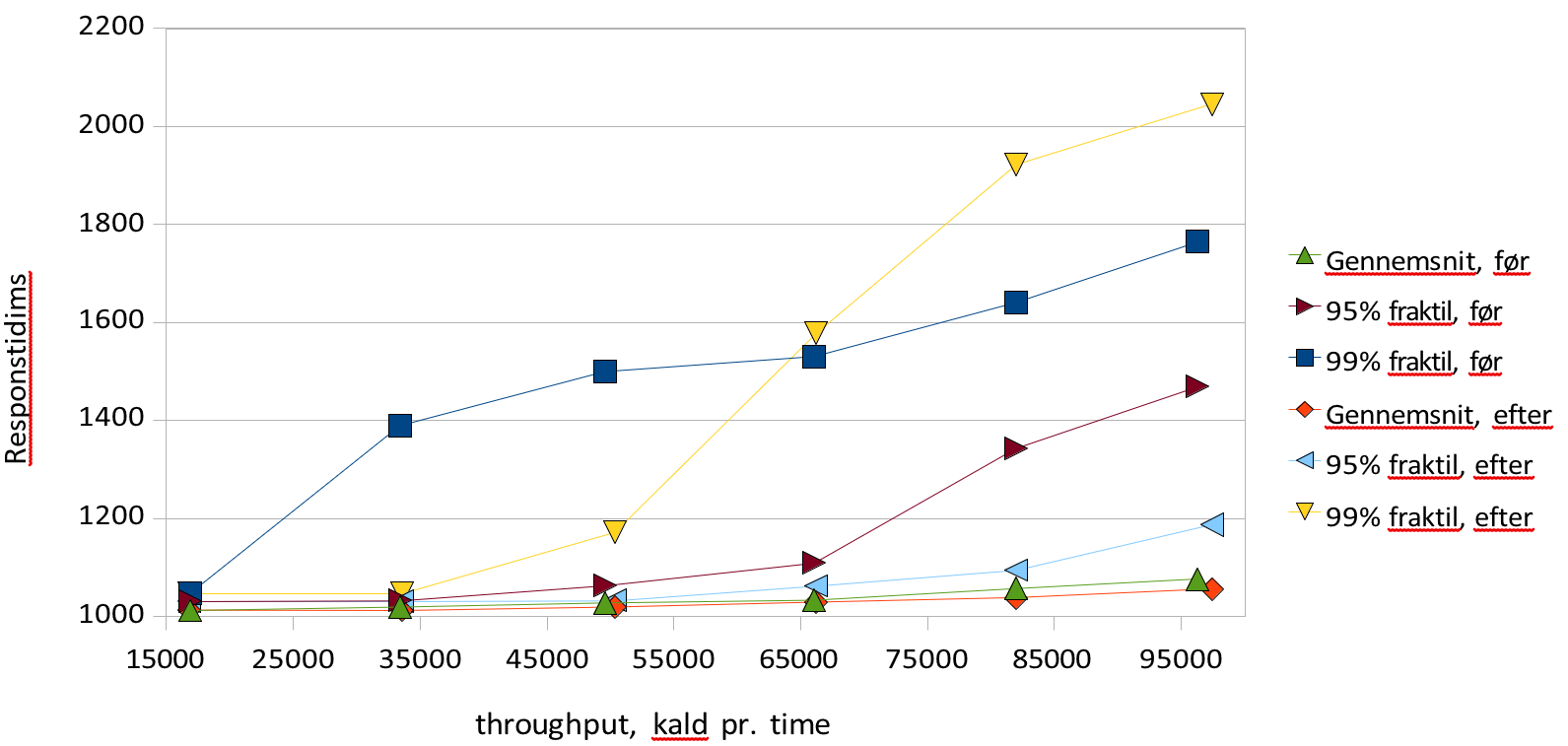
Grafen viser resultatet at gennemføre den samme test før og efter en kørsel med markant overbelastning. Der ses stort set uændrede gennemsnitlige svartider og throughput, mens 99% fraktilerne varierer lidt mere kaotisk, uden at der er nogen markant forskel. 95% fraktilen er lidt lavere efter stress - perioden end før, men ikke markant. Konklusionen er at der ikke er nogen blivende eftervirkning af en stress - pediode at spore.
...
- 100 tråde
- Der ventes 8 sekunder mellem kaldene.
- Test-servicen venter 10 sekunder før den svarer med et svar, som er en streng på 4096 tegn, pakket ind i SOAP-transport. Der sendes også en 4096 tegns streng med hvert kald.
- Hver tråd ventes af tage lidt over 10 sekunder i alt på kaldene. Med i alt 18 sekunder pr kald kan en tråd nå 3600/18=200 kald i timen. Med 100 tråde ventes dermed op mod 100*200=20.000 kald i timen. I praksis ventes mellem 19.000 og 20.000
- Hver tråd har et ID-kort. Hver tråd laver login uden at kalde logout på det gamle kort ved 5% af kaldene til proxy. Dette har den effekt at der i løbet af 24 timers kørsel skabes omkring 5% * 20.000 * 24 = 24.000 id-kort i cachen på SOSI-GW. Derefter vil de ældste af dem blive fjernet af cachen selv, efterhånden som de overskrider deres maksimale levetid på 24 timer.
- Testen køres i minimum 24 timer. De første 24 - 25 timer forventes resourceforbruget at vokse støt på grund af den tiltagende mængde id-kort i cachen, hvorefter det bør stabilisere sig. Der bør ikke være nogen nævneværdig ændring i svartiderne hen over perioden, omend der ventes en lille effekt af at have så mange ID-kort.
- Der forventes et memoryforbrug på omkring 32kb pr. id-kort, altså i alt omkring 768 MB heap til id-kort. Tallet er anslået ved at måle gennemsnitsstørrelsen af et ID-kort med Trifork P4. Det forholdsvis store forbrug skyldes at en id-kort instans, som den er i SEAL, indeholder en DOM repræsentation, der fylder temmelig meget. Oven i det kommer at den også gemmes serialiseret som XML-streng, hvad der fylder omkring 6kb, af hensyn til at kunnesende den til andre medlemmer i clusteret. Man kunne nøjes med at have den serialiserede udgave af hensyn til plads, men det er ikke en tids - effektiv måde at opbevare den på, da det så skulle parses ved hvert proxy-kald.
- For at validere at forældelse af gamle kort fungerer, køres i fortsættelse en test, hvor der foretages meget færre logins og ellers benyttes samme parametre. I praksis er valgt at lave login i 1% af kaldene, og samtidig foretage logout på det gamle nameID ved gen - login, så der ikke ophobes ret mange id-kort. Efter et døgn bør der være 100 id-kort i cachen, samt oplysninger om 1% * 20.000 * 24 = 4.800 brugte nameID'er med status REVOKED.
- For at teste cluster- delen mest muligt, benyttes 4 servere i clusteret i denne test. Der er kun behov for én maskine til test -servicen og én til at drive testen med denne lave belastning.
...
Der er kørt med den ovennævnte høje belastning i 40 timer, og derefter en lille uges tid med den lavere belastning. Her er grafer og memoryforbrug og svartider i denne periode. Svatiderne er for perioden med den høje belastning.
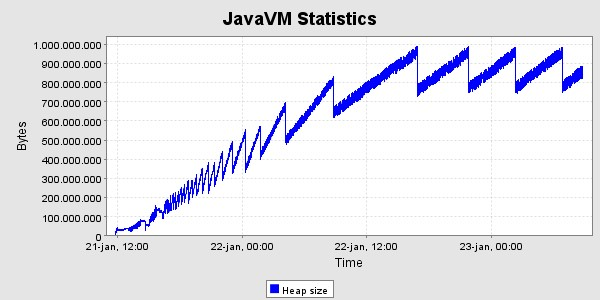
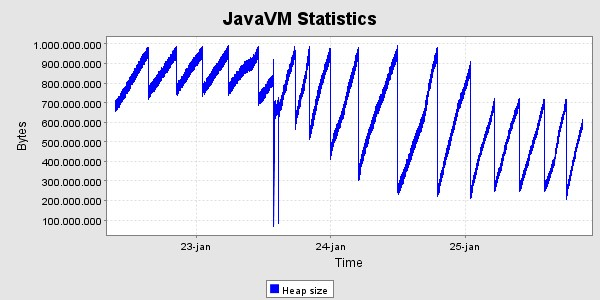
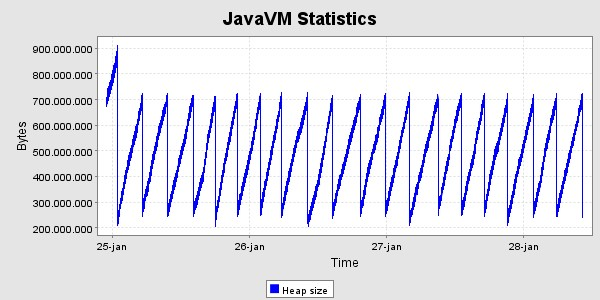
Svartider, set for hver time  ms
ms
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839
Time i endurancetesten

Der ses det forventede forløb i heap - udviklingen, nemlig en kraftig stigning de første 24 timer og derefter en kurve hvis bund er vandret , med den nøjagtighed det kan afgøres her. Der er gennemført 797513 kald i alt i løbet af de 40 timer, svarende til 19938 kald pr. time i gennemsnit. Heraf gav de 3 fejl tilbage til klienten, og i alle tre tilfælde er der tale om at testklienten ikke kunne gennemføre socketforbindelsen til SOSI-GW-servicen.
For at teste synkroniseringsmekanismen startes en ekstra server efter ca. 41 timers test. Denne server modtager tilstanden fra en af de eksisterende. Den modtog 122MB data i løbet af 37 sekunder, og det bestod af 22561 id-kort. Afsendelsen af disse data belastede den afsendende server med ca. 20% cpu, så den i alt var omkring 25% belastet.
Efterfølgende har clusteret af nu 4 servere fået lov at køre i en lille uges tid for at se heap - grafen for en længere periode. Den har et uproblematisk forløb.
CPU-forbruget er under testen næsten ikke målbart. Windos taskmanager viser det typisk som 2 - 5%.
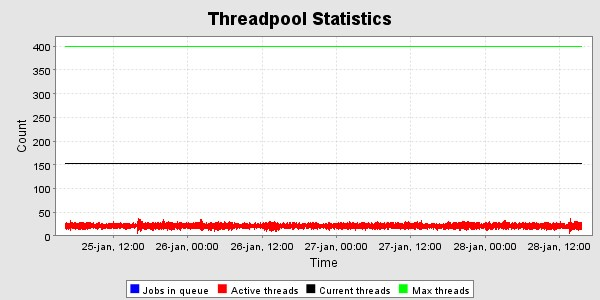
Trådpoolen i T4 er sat til max 400 http - tråde . Som det ses af følgende graf er der højst benyttet 150 i VM'ens levetid, og under endurance-testen er der omkring 20- 30 i brug i gennemsnit. Dette svarer med forventningerne, da der er 100 testtråde, hvis kald skal fordeles over 4 servere.
...