Page History
...
| Gliffy Diagram | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Sundhedsvæsenenets elektroniske Brugerstyring (SEB) bruges ikke i nuværende version af eCPR. I øjeblikket kan eCPR koordinatorer/Web administratorer indskrives direkte i den interne MariaDB. I fremtiden vil denne brugerstyring foregå gennem SEB.
Sekvensdiagrammer
Nedenfor ses 2 sekvensdisagrammer. De blå komponenenter hører alle til eCPR-servicen, og illustrerer hvordan flowet overordnet set forløber internt.
...
| Gliffy Diagram | ||||||||
|---|---|---|---|---|---|---|---|---|
|

...

Løsningen giver alle med adgang til NSP mulighed for at aflevere adviseringer til øvrige parter i sundhedssektoren gennem NSP.
Løsningen er en realisering af et ”publish-subscribe” kommunikationsmønster.
* Hver kasse i ovenstående diagram har en kort forklaring, som kommer frem i et nyt browservindue, når der klikkes på kassen.
2.2. Software blueprint og logisk model
Nedenstående blueprint viser lagdelingen i NAS:
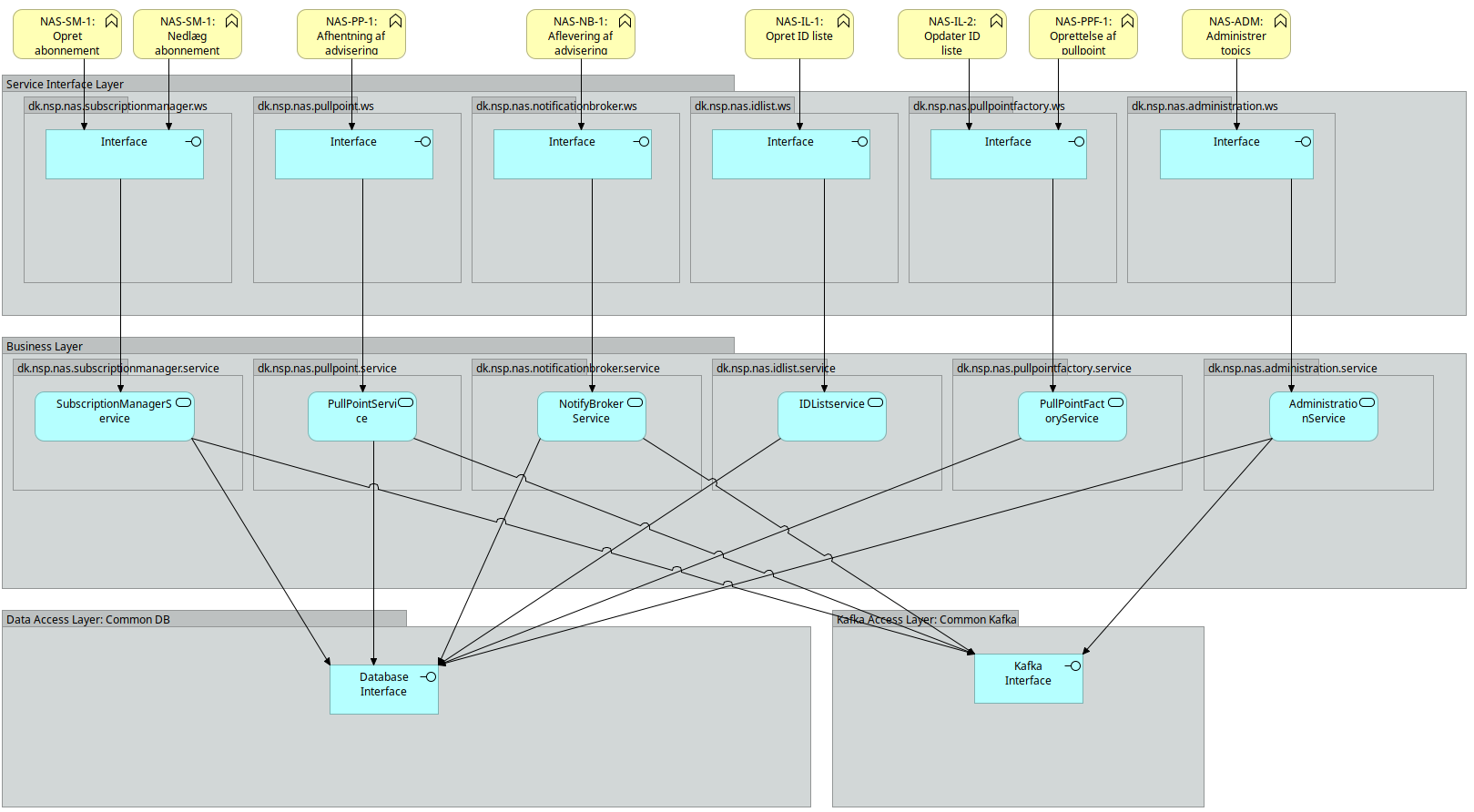
Logisk set kan løsningen tegnes som nedenstående:
2.3. Notification Broker
NotificationBrokers ansvarsområder er at modtage adviseringer via det udbudte interface Notify og delegere disse videre til det rette topic på Kafka infrastrukturen.

NotificationBroker er inddelt i lag. Selve oprettelse og orkestrering af NotificationBrokers komponenter varetages af en konfigurationskomponent. Denne konfigurationskomponent er også ansvarlig for at inkludere de relevante konfigurationer fra de delte komponenter, som NotificationBroker anvender: Det drejer sig om Topic-delen af databasekomponenten samt Publisher-delen af kafkakomponenten.
På ydersiden af NotificationBroker findes Service Interface: Dette lag er ansvarlig for at udbyde Notify SOAP servicen samt at foretage mapning ned i mod den model, der anvendes i forretningslaget i NotificationBroker.
Forretningslaget indeholder forretningslogikken: Dvs tjek på, om det indkommende topic er et lovligt NAS topic og publisering til den underliggende infrastruktur.
2.3.1. User stories
I forhold til NotificationBroker er følgende user stories relevante:
...
NotificationBrokers opførsel under "Aflevering af advisering" er beskrevet i nedenstående sekvensdiagram.
2.4. PullPoint Service
PullPoint Service har som ansvarsområde at udstille et endpoint, som anvendere kan bruge til at hente adviseringer fra NAS2 for et givent pullpoint.

Som en del af dette, er det op til PullPoint Service at opretholde en status for hvert abonnement under et givent pull point, der fortæller, hvor langt anvenderen er kommet i afhentningen.
PullPoint Service er inddelt i lag. Selve oprettelse og orkestrering af PullPoint Service komponenter varetages af en konfigurationskomponent. Denne konfigurationskomponent er også ansvarlig for at inkludere de relevante konfigurationer fra de delte komponenter, som PullPoint anvender: Det drejer sig om PullPoint-delen af databasekomponenten samt Streamer-delen af kafkakomponenten.
På ydersiden af PullPoint findes Service Interface: Dette lag er ansvarlig for at udbyde GetMessages SOAP servicen samt at foretage mapning ned i mod den model, der anvendes i forretningslaget i PullPointService.
Forretningslaget indeholder forretningslogikken: PullPoint Service henter notifikationer fra Kafka via Streamer interfacet, som stilles til rådighed via det fælles Kafka modul. Til at holde styr på tilstanden for hvert abonnement anvender PullPoint Service det fælles database modul, der holder styr på tilstand (offset) hvor hvert abonnement.
2.4.1. User stories
I forhold til PullPoint Service er følgende user stories relevante:
...
2.4.2. Sekvensdiagram
Følgende diagram viser hvordan en klient henter notifikationer på et pullpoint.
Her er web service laget igen adskilt fra forretningslogikken, som det også var gjort i Notification Broker.
Efter afhentning af subscriptions, tjekkes det at klienten har adgang til de tilhørende Topics.
Databasen rammes her flere gange, da det er nødvendigt først af finde ud af hvordan beskeder filtreres og hvorfra og så skal det persisteres hvor langt klienten/pullpoint er kommet i Kafka.
Følgende diagram viser den anden user story:
2.4.3. Kald af GetMessages logik
Nedenstående er logikken for kald til GetMessages. Logikken er dokumenteret her da det er et af de steder hvor der er mest kompleksitet i løsningen.
Der er skitseret 4 forskellige scenarier for kald af GetMessages. Ved hvert scenarie er der en kort beskrivelse af hvad scenariet dækker over. Udover det anvendes der en række termer i scenarierne der er vigtige for forståelsen af logikken. Disse er beskrevet nedenunder.
- Kafka partitioner: Et Kafka topic er delt op i en række partitioner. Opdeling af et topic i flere partitioner er en måde at skalere og parallelisere adgangen til et Kafka topic. Til et givent Kafka topic er der altid minimum en partition og den vil have partition nummer 1. Det er kun muligt at tilføje partitioner til et topic. En besked i et Kafka topic er identificeret af et partitionsnummer og et offset.
- Offset: Alle beskeder i en Kafka partition er identificeret ved et offset. Et offset er et fortløbende nummer der starter ved 0.
- Nas_consumer: Database tabel der indeholder information omkring hvilke offsets en given NAS subscription er nået til i Kafka. Når der skal læses nye adviser fra Kafka læses der fra de offsets der står i denne tabel. I tabellen er offsets en kommasepareret liste af tal. Er der f.eks. 3 partitioner og sidste gang der blev hentet adviser var det til offset 10, 9 og 13 vil der stå "10,9,13" i tabellen.
Normalt kald hvor der er nye adviser
Scenarie hvor der er sendt adviser til et topic og GetMessages kaldes for at afhente adviser.
- Kald til GetMessages operationen. Body består af maksimalt antal ønskede beskeder i svar. Pull point ID, som blev returneret da pull point blev oprettet, er den sidste del af URL'en. F.eks. http://nas/pullpoint/0d7d7a08-b742-499f-b481-82b2f6d5dc83. Her er 0d7d7a08-b742-499f-b481-82b2f6d5dc83 pull point id.
- Udfør DGWS validering. Det vil sige id kort er valid, korrekt niveau af id kort osv.
- Med Pull Point ID som nøgle læses information om Pull Point alle subscriptions for det givne pull point og for hver subscription læses nyeste og næst nyeste nas_consumer. Rækkefølgen af nas_consumer bestemmes af subscription_serialnumber.
- For hver subscription der er læst fra databasen udføres nedenstående.
- Hent antal partitioner i Kafka for det Kafka topic den nuværende subscription handler om. Dette gøres via kald til partitionsFor metoden på den Kafka Consumer der anvendes. Argument til metoden er topic.
- Da antal partioner læst fra Kafka er det samme som det antal offsets der er læst fra databasen udvides listen ikke.
- For hver partition søges der frem til det offset der er angivet for den givne partition i listen med offsets.
- Kafka polles for beskeder. Det sikres at den samlede poll tid ikke overstiger den konfigurationsparameteren kafka.poll.max.time
- Filtrering udfra den evt. ID liste der er tilknyttet på hash værdi niveau. Hash værdi for ID type og ID er gemt på hvert Kafka besked samt på ID listen i databasen.
- Filtrering på ID og ID type af hensyn til mulig hash kollision.
- Indsæt nye nas_consumer rækker i databasen. Der indsættes en række pr. subscription. Det næste serialnumber i sekvensen gives til den nye nas_consumer.
- Send svar til klient.
Kald hvor subscription er kommet bagud
Scenarie hvor subscription er kommet meget bagud. Meget defineres via property kafka.poll.delta.max.
- Kald til GetMessages operationen. Body består af maksimalt antal ønskede beskeder i svar. Pull point ID, som blev returneret da pull point blev oprettet, er den sidste del af URL'en. F.eks. http://nas/pullpoint/0d7d7a08-b742-499f-b481-82b2f6d5dc83. Her er 0d7d7a08-b742-499f-b481-82b2f6d5dc83 pull point id.
- Udfør DGWS validering. Det vil sige id kort er valid, korrekt niveau af id kort osv.
- Med Pull Point ID som nøgle læses information om Pull Point alle subscriptions for det givne pull point og for hver subscription læses nyeste og næst nyeste nas_consumer. RRækkefølgen af nas_consumer bestemmes af subscription_serialnumber.
- For hver subscription der er læst fra databasen udføres nedenstående.
- Hent antal partitioner i Kafka for det Kafka topic den nuværende subscription handler om. Dette gøres via kald til partitionsFor metoden på den Kafka Consumer der anvendes. Argument til metoden er topic.
- Da antal partioner læst fra Kafka er det samme som det antal offsets der er læst fra databasen udvides listen ikke.
- For hver partition søges der frem til det offset der er angivet for den givne partition i listen med offsets.
- Kafka polles for beskeder. Det sikres at den samlede poll tid ikke overstiger den konfigurationsparameteren kafka.poll.max.time. Hvis delta mellem max. offsets på partitionerne i det topic der skal læses fra og der hvor subscription er nået til er større end kafka.poll.delta.max anvendes der kafka.poll.catchup.timeout som timeout til Kafka.poll. Dette sikrer at data hentes fra Kafka.
- Filtrering udfra den evt. ID liste der er tilknyttet på hash værdi niveau. Hash værdi for ID type og ID er gemt på hvert Kafka besked samt på ID listen i databasen.
- Filtrering på ID og ID type af hensyn til mulig hash kollision.
- Indsæt nye nas_consumer rækker i databasen. Der indsættes en række pr. subscription. Det næste serialnumber i sekvensen gives til den nye nas_consumer.
- Send svar til klient.
Kald hvor der ikke er nye adviser i Kafka
Scenarie hvor der siden sidste kald til GetMessages ikke er sendt nogle nye adviser til det topic der ønskes hentet adviser for.
- Kald til GetMessages operationen. Body består af maksimalt antal ønskede beskeder i svar. Pull point ID, som blev returneret da pull point blev oprettet, er den sidste del af URL'en. F.eks. http://nas/pullpoint/0d7d7a08-b742-499f-b481-82b2f6d5dc83. Her er 0d7d7a08-b742-499f-b481-82b2f6d5dc83 pull point id.
- Udfør DGWS validering. Det vil sige id kort er valid, korrekt niveau af id kort osv.
- Med Pull Point ID som nøgle læses information om Pull Point alle subscriptions for det givne pull point og for hver subscription læses nyeste og næst nyeste nas_consumer. Rækkefølgen af nas_consumer bestemmes af subscription_serialnumber.
- For hver subscription der er læst fra databasen udføres nedenstående.
- Hent antal partitioner i Kafka for det Kafka topic den nuværende subscription handler om. Dette gøres via kald til partitionsFor metoden på den Kafka Consumer der anvendes. Argument til metoden er topic.
- Da antal partioner læst fra Kafka er det samme som det antal offsets der er læst fra databasen udvides listen ikke.
- For hver partition søges der frem til det offset der er angivet for den givne partition i listen med offsets.
- Kafka polles for beskeder.
- Da der ikke returneres adviser fra Kafka er der heller ikke noget at foretage filtrering på.
- Indsæt nye nas_consumer rækker i databasen. Der indsættes en række pr. subscription. Det næste serialnumber i sekvensen gives til den nye nas_consumer. Selvom der ikke er returneret nye adviser fra Kafka og offsets dermed er det samme, så indsættes der stadig nye rækker. Dette gøres af hensyn til DGWS' krav om replayability samt at holde løsningen så simpel som muligt.
- Send svar til klient.
Kald hvor antallet af Kafka partioner er blevet udvidet siden sidste kald.
Scenarie hvor antallet af partitioner for det topic der hentes data fra er blevet udvidet. Det kan f.eks. være sket af hensyn til performance.
- Kald til GetMessages operationen. Body består af maksimalt antal ønskede beskeder i svar. Pull point ID, som blev returneret da pull point blev oprettet, er den sidste del af URL'en. F.eks. http://nas/pullpoint/0d7d7a08-b742-499f-b481-82b2f6d5dc83. Her er 0d7d7a08-b742-499f-b481-82b2f6d5dc83 pull point id.
- Udfør DGWS validering. Det vil sige id kort er valid, korrekt niveau af id kort osv.
- Med Pull Point ID som nøgle læses information om Pull Point alle subscriptions for det givne pull point og for hver subscription læses nyeste og næst nyeste nas_consumer. Rækkefølgen af nas_consumer bestemmes af subscription_serialnumber.
- For hver subscription der er læst fra databasen udføres nedenstående.
- Hent antal partitioner i Kafka for det Kafka topic den nuværende subscription handler om. Dette gøres via kald til partitionsFor metoden på den Kafka Consumer der anvendes. Argument til metoden er topic.
- Da antal partioner læst fra Kafka er større end det antal offsets der er angivet i nyeste nas_consumer tabellen udvides listen med offsets. Et offset er blot en numerisk værdi og en ny parition i Kafka starter altid ved 0.
- For hver partition søges der frem til det offset der er angivet for den givne partition i listen med offsets.
- Kafka polles for beskeder.
- Filtrering udfra den evt. ID liste der er tilknyttet på hash værdi niveau. Hash værdi for ID type og ID er gemt på hvert Kafka besked samt på ID listen i databasen.
- Filtrering på ID og ID type af hensyn til mulig hash kollision.
- Indsæt nye nas_consumer rækker i databasen. Der indsættes en række pr. subscription. Det næste serialnumber i sekvensen gives til den nye nas_consumer.
- Send svar til klient.
Kald hvor adviser er blevet slettet i Kafka
Nedenstående scenarie hvor beskederne i det Kafka topic der skal hentes adviser fra er blevet slettet på grund af alder. Det er en indbygget mekaniske i Kafka at beskeder slettes fra et topic efter et konfigurerbart interval.
- Kald til GetMessages operationen. Body består af maksimalt antal ønskede beskeder i svar. Pull point ID, som blev returneret da pull point blev oprettet, er den sidste del af URL'en. F.eks. http://nas/pullpoint/0d7d7a08-b742-499f-b481-82b2f6d5dc83. Her er 0d7d7a08-b742-499f-b481-82b2f6d5dc83 pull point id.
- Udfør DGWS validering. Det vil sige id kort er valid, korrekt niveau af id kort osv.
- Med Pull Point ID som nøgle læses information om Pull Point alle subscriptions for det givne pull point og for hver subscription læses nyeste og næst nyeste nas_consumer. Rækkefølgen af nas_consumer bestemmes af subscription_serialnumber.
- For hver subscription der er læst fra databasen udføres nedenstående.
- Hent antal partitioner i Kafka for det Kafka topic den nuværende subscription handler om. Dette gøres via kald til partitionsFor metoden på den Kafka Consumer der anvendes. Argument til metoden er topic.
- Da antal partioner læst fra Kafka er det samme som det antal offsets der er læst fra databasen udvides listen ikke.
- For hver partition søges der frem til det offset der er angivet for den givne partition i listen med offsets.
- Kafka polles for beskeder.
- Kafka Consumer klient kaster en OffsetOutOfRangeException. Dette betyder at det offset der forsøges polles fra ikke længere eksisterer i det angivne topic.
- Der søges frem til ældste offset i det pågældne topics og Kafka polles igen.
- Filtrering udfra den evt. ID liste der er tilknyttet på hash værdi niveau. Hash værdi for ID type og ID er gemt på hvert Kafka besked samt på ID listen i databasen.
- Filtrering på ID og ID type af hensyn til mulig hash kollision.
- Som konsekvens af at der tidligere er blevet kastet en OffsetOutOfRangeException laves der en system besked som en del af svaret. En system besked er kendetegnet ved at IsSytemNotification er true på NotifyContent.
- Indsæt nye nas_consumer rækker i databasen. Der indsættes en række pr. subscription. Det næste serialnumber i sekvensen gives til den nye nas_consumer.
- Send svar til klient.
2.5. IDList service
IDList Servicen har som ansvarsområde at udstille et endpoint, som anvendere kan bruge til at administrere ID lister.
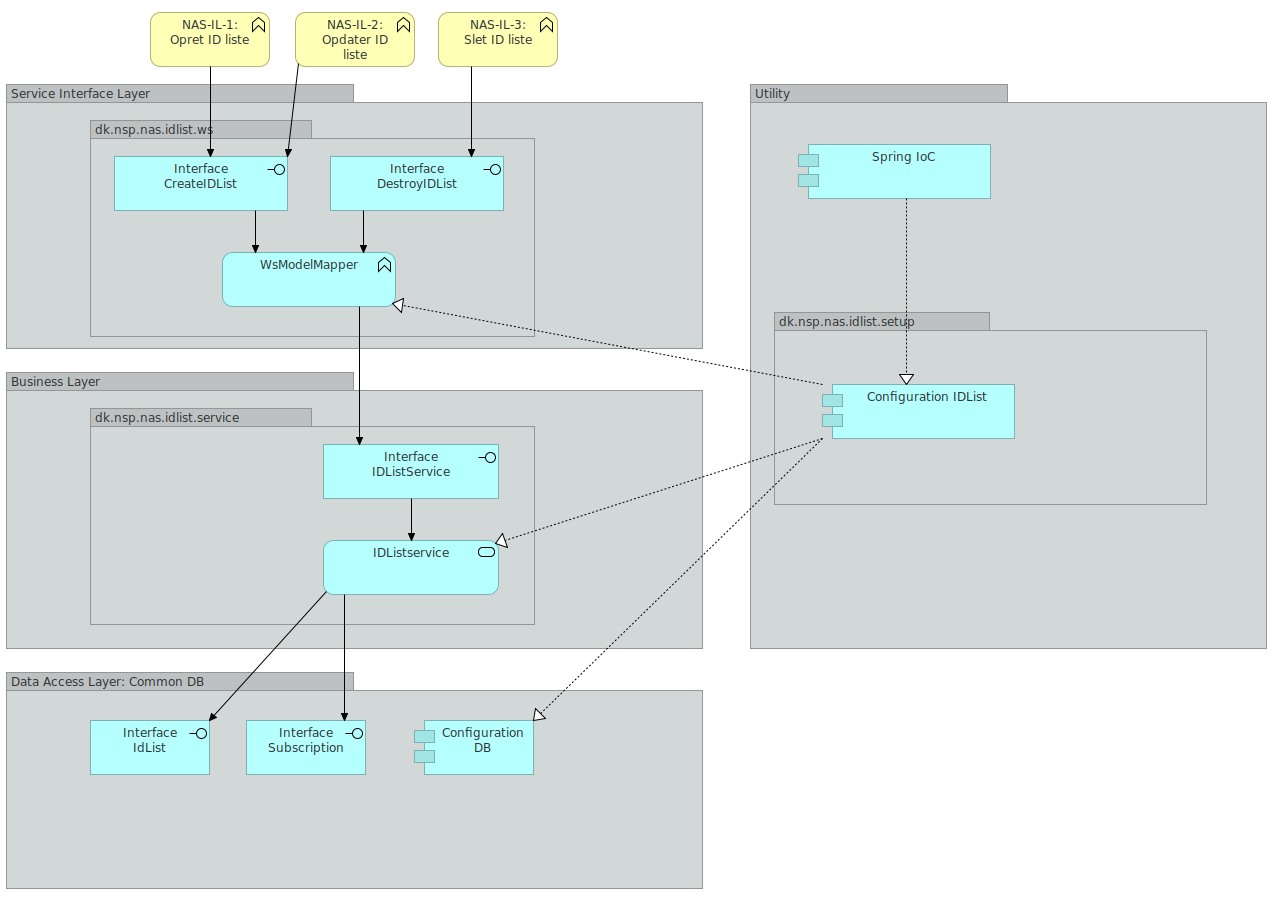
En ID liste er en liste over positive ID'er der skal hentes adviseringer for. IDList servicen udstiller to SOAP actions. En operation der hedder CreateIDList og en der hedder DestroyIDList. CreateIDList anvendes til både at oprette og opdatere en ID liste. Dette gøres ved at tjekke om en ID liste med det givne navn allerede findes.
IDList Servicen er inddelt i lag. Selve oprettelse og orkestrering af IDList Service komponenter varetages af en konfigurationskomponent. Denne konfigurationskomponent er også ansvarlig for at inkludere de relevante konfigurationer fra de delte komponenter, som IDList anvender: Det drejer sig om IDList, IDListContent og Subscription delene af databasekomponenten.
På ydersiden af IDList findes Service Interface: Dette lag er ansvarlig for at udbyde CreateIDList samt DestroyIDList SOAP servicene samt at foretage mapning ned i mod den model, der anvendes i forretningslaget i IDListService.
Forretningslaget indeholder forretningslogikken: IDList Service enten opretter, opdaterer eller nedlægger en id liste. En ID liste persisteres i databasen ved hjælp af kald til metoder i databaselaget.
2.5.1. User stories
I forhold til IDList Service er følgende user stories relevante:
...
2.5.2. Sekvensdiagram
Nedenstående 3 sekvensdiagrammer viser hvordan man henholdsvis opretter, opdaterer og sletter id lister. Hvert af de 3 sekvensdiagrammer er knyttet til en user story ved samme navn.
2.6. Subscription manager
Subscription Manager Servicen har som ansvarsområde at udstille et endpoint, som anvendere kan bruge til at oprette og nedlægge subscriptions.
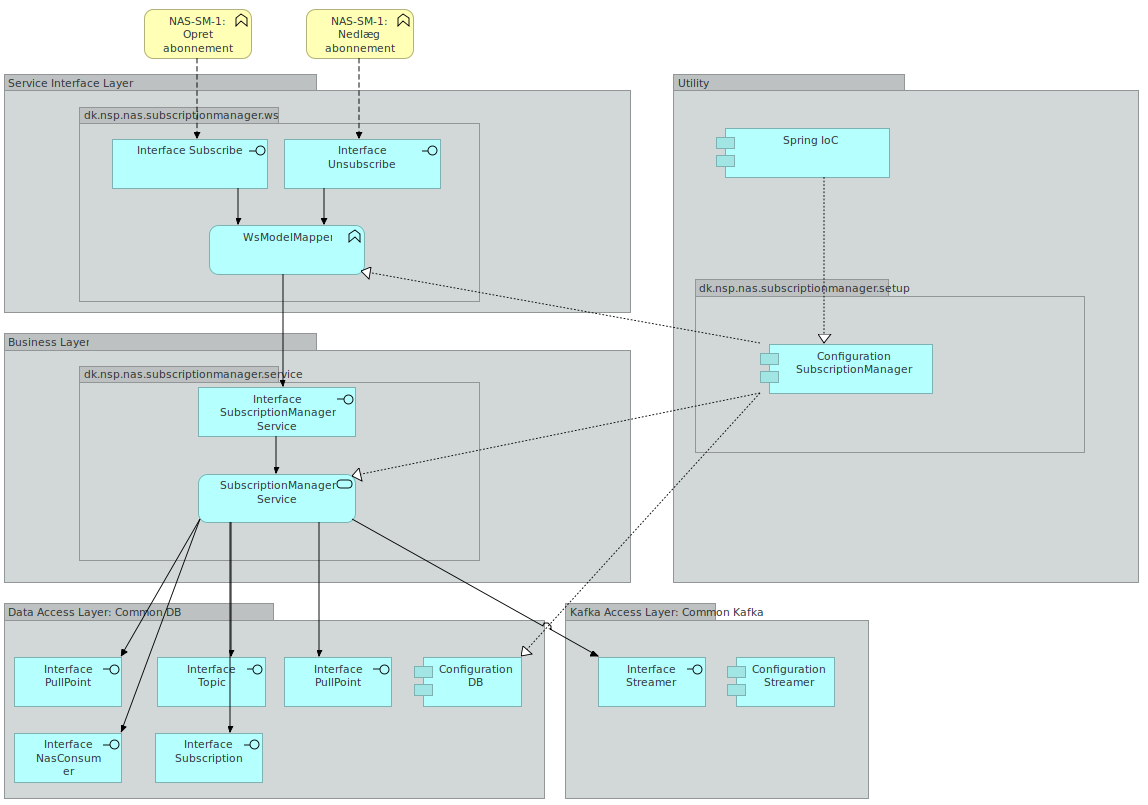
En subscription er et abbonnement på et topic hvor der kan være tilknyttet en id liste. Abonnementet er det der knytter et pull point og et topic sammen. Subscription manager servicen udstiller to SOAP actions. En operation der hedder Subscribe og en der hedder Unsubscribe. Subscribe anvendes til at oprette subscriptions. Unsubscribe anvendes til at nedlægge subscriptions.
Subscription Manager Servicen er inddelt i lag. Selve oprettelse og orkestrering af Subscription Manager Service komponenter varetages af en konfigurationskomponent. Denne konfigurationskomponent er også ansvarlig for at inkludere de relevante konfigurationer fra de delte komponenter, som Subscription Manager anvender: Det drejer sig om alle dele af database komponenten samt streamer delen af Kafka komponenten.
På ydersiden af Subscription Manager findes Service Interface: Dette lag er ansvarlig for at udbyde Subscribe samt Unsubscribe SOAP servicene samt at foretage mapning ned i mod den model, der anvendes i forretningslaget i SubscriptionManagerService.
Forretningslaget indeholder forretningslogikken: Subscription Manager Service enten opretter eller nedlægger en subscription. En subscription persisteres i databasen ved hjælp af kald til metoder i databaselaget.
2.6.1. User stories
I forhold til Subscription Manager Service er følgende user stories relevante:
...
2.6.2. Sekvensdiagram
Nedenstående 2 sekvensdiagrammer viser hvordan man henholdsvis opretter ned nedlægger subscriptions. Hvert af de 2 sekvensdiagrammer er knyttet til en user story ved samme navn.
2.7. Pullpoint Factory Service
PullPointFactory har som ansvarsområde at udstille et endpoint, som anvendere kan bruge til at oprette pullpoints.

Servicen er ligesom alle øvrige services inddelt i lag og opbygningen er identisk med PullPoint – se afsnit herom. Den eneste forskel er at PullPointFactory ikke anvender Kafka og dermed ikke har noget med Streamer interfacet at gøre.
2.7.1. User stories
I forhold til Pullpoint Factory Service er følgende user stories relevante:
...
2.7.2. Sekvensdiagram
Nedenstående sekvensdiagram viser hvordan man opretter pullpoints. Sekvensdiagrammet er knyttet til user story af samme navn.
2.8. Administration Service
Administration service har som ansvarsområde at udstille et REST endpoint til anvendelse af driften.

Dette endpoint kan anvendes til oprette topics, nedlægge topics osv. i NAS. Servicen er som de andre services i NAS2 lagdelt. Den adskiller sig dog fra de andre services ved at den ikke udstiller et SOAP WebService med DGWS. Derimod udstiller den et REST endpoint. Dette endpoint har ikke noget sikkerhedslag da det kun er udstillet til driften.
2.8.1. User stories
I forhold til Administration Service er følgende user stories relevante:
...
2.8.2. Sekvensdiagram
Nedenstående sekvensdiagram viser hvordan man opretter pullpoints. Sekvensdiagrammet er knyttet til user story af samme navn.
2.9. Cleanup Service
Cleanup Service kaldes for at starte et oprydningsjob, som sletter gamle rækker i databasen.
Følgende udføres ved cleanup:
- Gamle subscriptions slettes
- Gamle nasconsumers slettes
- De nyeste to for hver subscription beholdes, resten slettes i batches af 20.
2.10. Snitflader
NAS2 implementerer WS-Notification snitfladen. De operationer der er implementeret er beskrevet i NAS2 - Anvenderguide#Anvenderguide-Generelt dokumentet. De steder hvor der er implementeret yderlige validering eller restriktioner er disse også dokumenteret. Komplette WSDL'er vil blive tilgængelige på https://wsdl.nspop.dk/ når servicen er deployet til TEST2. I skrivende stund (2019-06-18) er det NAS1 WSDL'er og skemaer der er tilgængelige. Det skal dog nævnes at NAS1 og NAS2 implementerer samme snitflade.
2.11. Kafkamodul
* Hver kasse i ovenstående diagram har en kort forklaring, som kommer frem i et nyt browservindue, når der klikkes på kassen.
Kafkamodulet leverer en snitflad til kommunikation med Kafka. Under hjelmen anvends NSP Kafka Client library (se “Den gode brug af Kafka” (https://www.nspop.dk/display/public/web/Den+Gode+Brug+af+Kafka#DenGode-BrugafKafka-NSPKafkaClients).
Kafkamodulet er realiseret som et modul, som de konkrete NAS 2 services kan inkludere og anvende efter behov. Inkluderingen af kafkamodulet sker ved at aktivere een eller begge af kafkamodulets konfigurationskomponenter. Kafkamodulet tilbyder to konfigurationer til dens anvendere: Een til publishers og een til streamers.
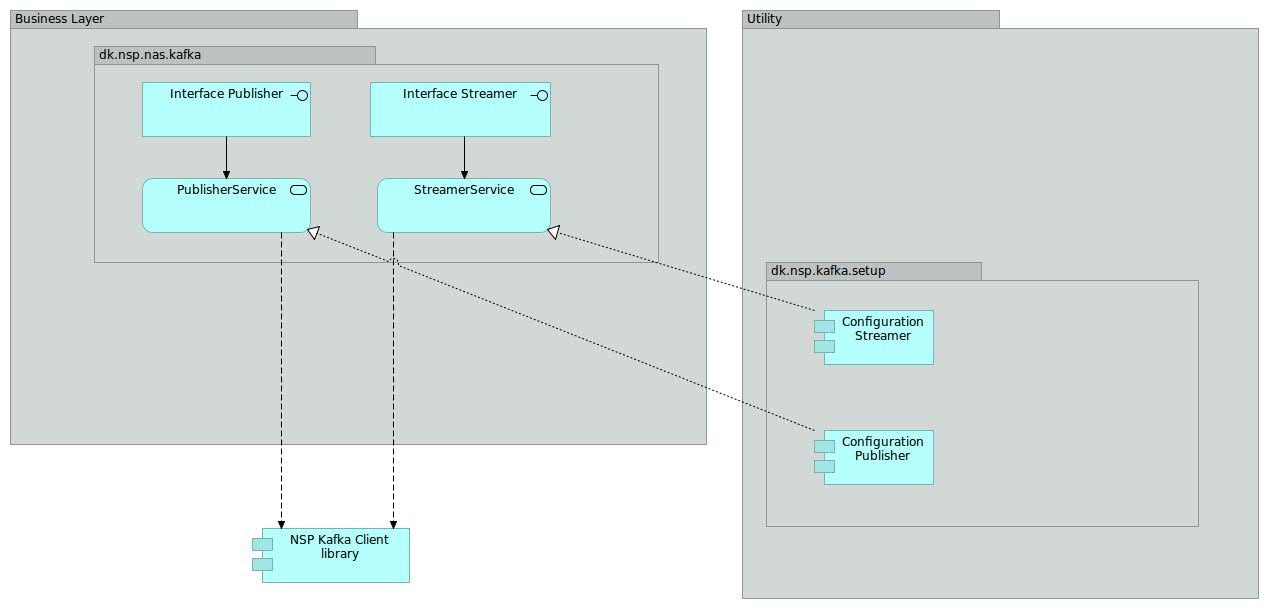
NAS 2 services tilgår kafka gennem kafkamodulets forretningslag interfaces. F.eks anvender NotificationBroker Publisher til at foretage publiseringen ned på et givent kafka topic.
2.12. Databasemodul
Alle NAS komponenter har brug for at tilgå og/eller administrere (dele af) den samlede datamodel for NAS 2. Som en del af NAS 2 komponenterne arbejdes der med et fællesmodul med services til læsning og skrivning af datamodellen.

Databasemodulet er realiseret som et modul, som de konkrete NAS 2 services kan inkludere og anvende efter behov. Inkluderingen af databasemodulet sker ved at aktivere databasemodulets konfigurationskomponent.
NAS 2 services tilgår datamodellen gennem forretningslagets interfaces. F.eks anvender NotificationBroker TopicMapping til at validere af det indkommende NAS topic og mapning ned til internt (kafka) topic. Andre services tilgår andre dele af databasemodellen via de udbudte interfaces (se blueprint ovenfor).
Det følgende diagram viser hvilke NAS2 komponenter, der tilgår hvilke services i database modulet. Det skal bemærkes at idlist dækker over både idlist og idlistcontent.
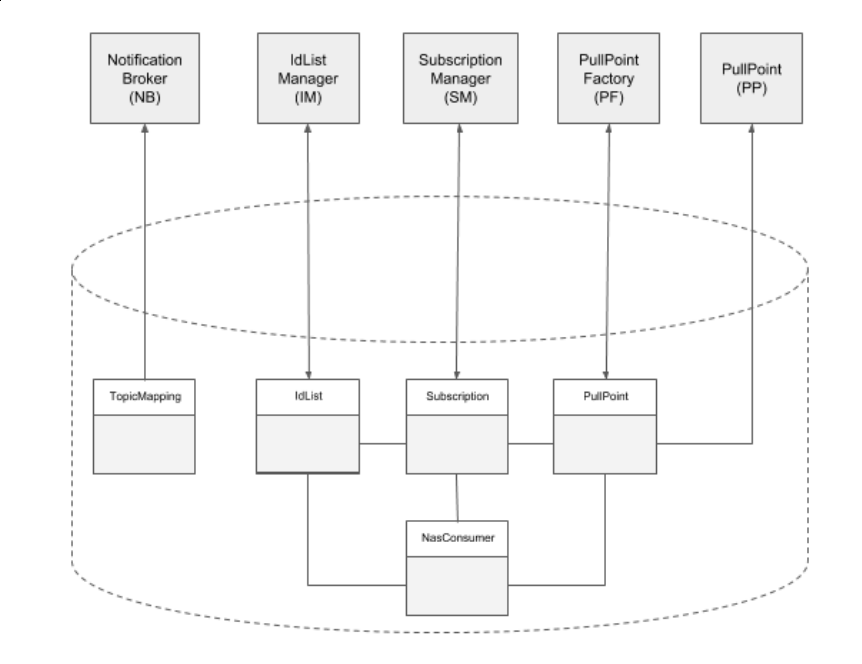
2.12.1. Database model
* Hver kasse i ovenstående diagram har en kort forklaring, som kommer frem i et nyt browservindue, når der klikkes på kassen.
Til den følgende model, er der taget udgangspunkt i databasemodellen fra NAS 1.x. Umiddelbart er der dog ingen grund til at have flere database schema, så som der tidligere har eksisteret.
2.12.2. Topic mapning
Der skal være muligt at mappe topics indeholdt i notifikationer til Kafka topics. Denne 1-til-1 mapning er givet ved følgende tabel:
Eventuelle metadata-informationer såsom f.eks. hvem der har oprettet topic kan tilføjes metadata kolonnen. Metadata kolonnen vil blive gemt som JSON og dermed kan den udvides med ekstra værdier efter behov. Disse felter vil som udgangspunkt ikke blive læse i servicen og dermed er servicen heller ikke afhængig af hvad der står i metadata kolonnen.
2.12.3. Topic Access
For at oprette et abonnement på et Topic eller hente beskeder/notifikationer for et Topic, skal klienten have adgang til det specifikke Topic. Adgangen til Topics gives i følgende tabel:
Hvordan identifier udfyldes, kan ses i driftsvejledningen.
2.12.4. Pullpoint
Et pullpoint modelleres til persistering af bla. ejerskab af et pullpoint.
2.12.5. Nas Consumer Rollback
For alle topics gemmes offsets med mellemrum. Dette gøres for at understøtte muligheden for at spole en given subscription tilbage til et givent tidspunkt. Offsets gemmes i tabellen nas_consumer_rollback.
2.12.6. Offset håndtering
Når en klient henter beskeder/notifikationer på et pullpoint, skal der fortsættes fra der hvor klienten sidst slap. Denne information gemmes i nasConsumer i offset, som allerede beskrevet. Det kræver dog en mindre forklaring. Det er nemlig ikke blot eet offset, men en samling af flere offsets, der gemmes. Dette skyldes den måde Kafka clusteret bedst muligt udnyttes på. Når en besked afleveres til Notification Broker, vil den blive givet videre til Kafka clusteret og blive gemt i en af de partitioner, der er konfigureret. Der er skal som minimum være opsat det antal partitioner for et topic, som der er noder i clusteret.
Beskeder vil blive uniform fordelt til partitioner tilhørende et topic. Når beskeder skal hentes ud igen, skal en Kafka consumer, altså Pullpoint servicen, sættes op sådan, at den henter fra samtlige partitioner for et givet topic. Der skal hentes ud fra det offset, der er gemt for den pågældende subscription og partition. Når tilstrækkelige beskeder er hentet og der skal returneres til klient, gemmes nye offsets til den efterspurgte subscription i databasen igen.
Måden offsets gemmes på er i en "liste" i offset i nasConsumer. Da dette dog kun er en streng, skal der vælges passende formattering. Dette simplificeres af at partitioner altid angives med tallene fra 0 og opefter. En komma-separeret liste vil derfor være tilstrækkelig.
2.12.7. Abonnementer
For at data kan leveres til et pull point skal der være et eller flere abonnementer (Subscription). En subscription relaterer sig til et PullPoint og en række offsets (NasConsumer) og en evt. id list (IdList). NasConsumer er en representation af hvor langt en consumer er nået samt identifikation af seneste kald. Identifikation af seneste kald er nødvendig for at overholde DGWS krav omkring at gensende seneste svar. Hvor langt en consumer er nået er blot en tekststreng og så er det op til Kafka at fortolke denne tekststreng. Dette er med til at sikre en afkopling mellem det underliggende system til at gemme beskeder og forretningslogikken. NasConsumer er modelleret så der udelukkende læses og indsættes rækker i tabellen. Når seneste offset skal hentes, så er det blot nødvendigt at læse nyeste række for den subscription, der er tale om. Der er ikke brug for at opdatere eksisterende rækker. Dette betyder også, at det løbende skal ryddes op, så gamle rækker fjernes. Dette håndeteres i Cleanup Service.
IdList og tilhørende IdListContent er en representation af det eventuelle filter der er på en subscription. Det vil sige at det er en filtrering af beskeder til en given subscription.
3. Designmålsætninger og -beslutninger
...