Page History
...
MinLog 2 service er version 2.0.45 og NSP standard performance test framework version 2.0.27.
Der er kørt 2 servere med lookup komponenten (se iøvrigt figur i performance testvejledningen afsnit 2.2.2.1).
De rå test resultater er vedhæftet denne side (minlog2-lookup_onbehalfof_test900_run1.tar.gz)
...
JMeter hoved filen beskriver overordnet testens resultat. Her kan ses, at der er kørt 5 iterationer med 7 iterationer med test, belastningen i form af tråde og nodes, deres tidsinterval , throughput, forbedring og fejlprocent for hver:
...
Af grafen fremgår det, at jo flere nodes og tråde (disse øges over tid, per iteration) jo flere kald kommer der igennem per sekund overordnet set.
Servicen kørende på Docker1Docker01, som fik problemer sidst i testen har dog ingen kald i de siste 3 iterationer.
...
Vi er inden for performance kravene i testen fulde køretid, selv i de test iterationer, hvor den ene af de testede service stoppede.
Vmstat log
Vurdering
Jstat log
Vurdering
Docker stats log
...
Denne log findes for hver applikations server (docker container). Den viser resultatet af kommandoen vmstat
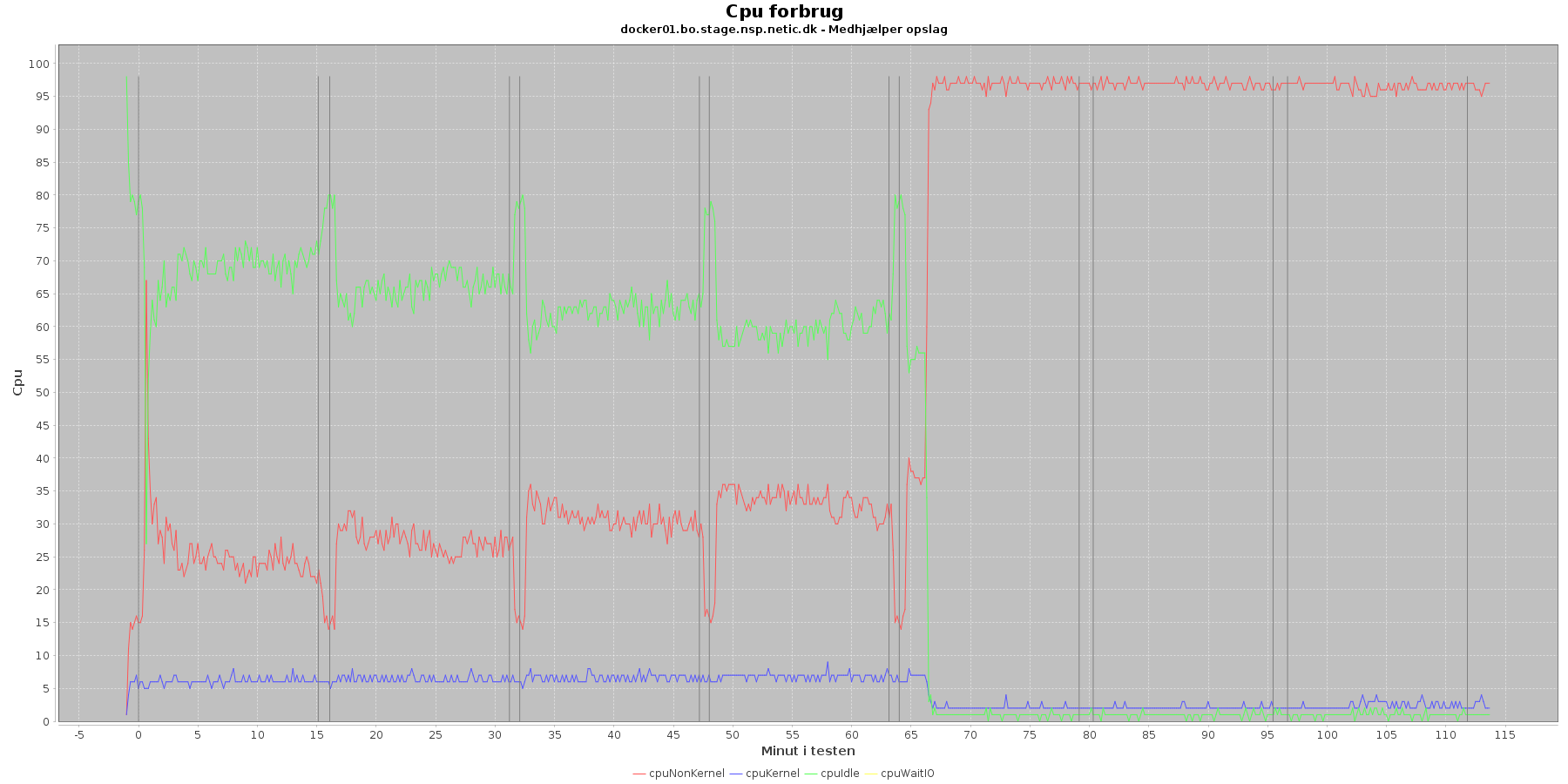
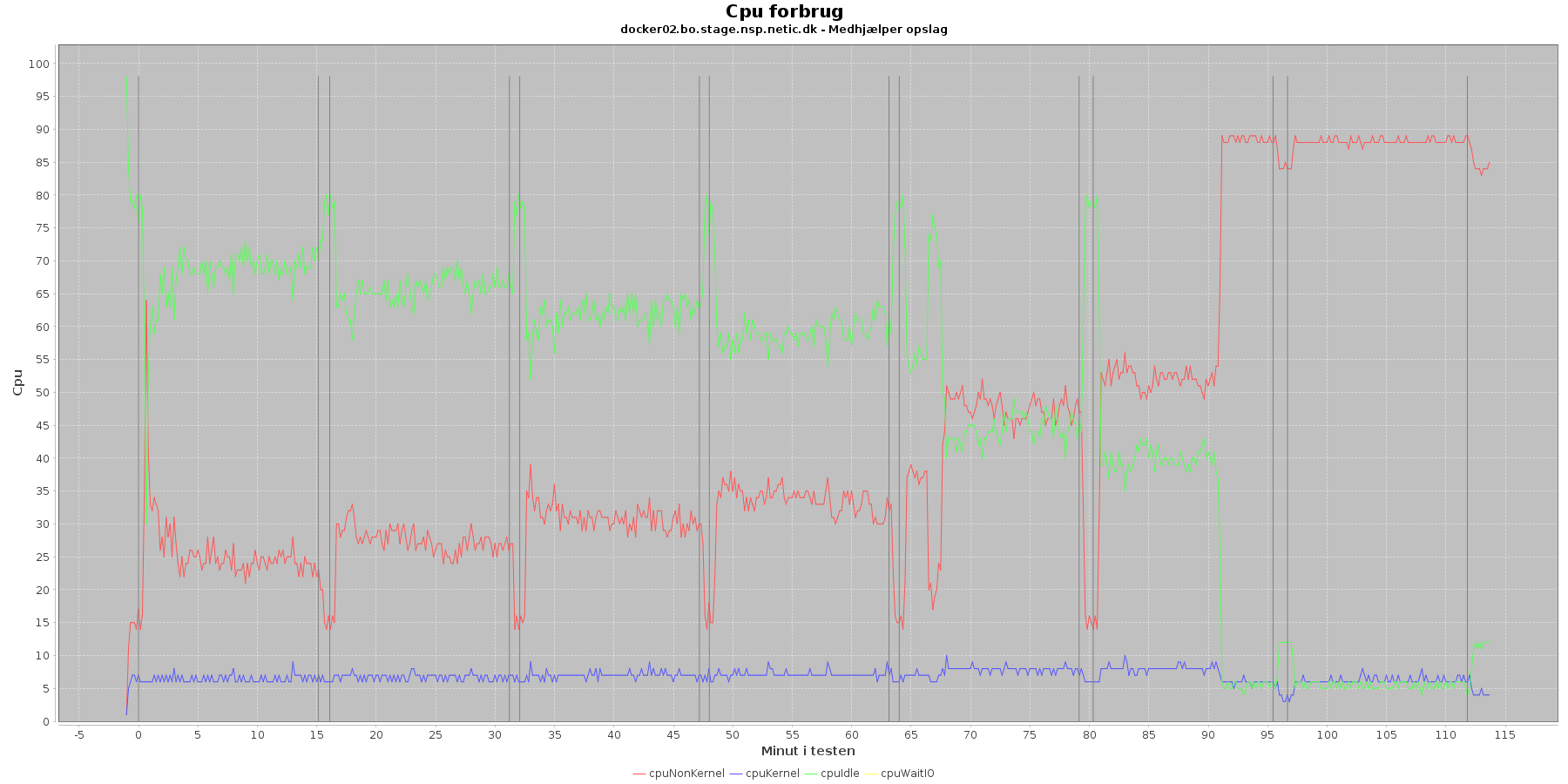
Udtræk omkring cpu fra denne log vises i de følgende grafer:
Data serier i grafen er:
- cpuNonKernel (rød): tid brugt på non-kernel opgaver
- cpuKernel (blå): tid brugt på kernel opgaver
- cpuIdle (grøn): tid brugt på ingenting
- cpuWaitIO (gul): tid brugt på at vente på i/o
- iterationerne (sort) er en cirka placering, da wmstat loggen ikke indeholder tidstempel
Man kan se at cpuIdle og cpuNonKernel påvirkes som servicen presses mere. cpuIdle ligger lavere over tid, mens cpuNonKernel grafen ligger højere over tid.
Ved testens. 5 iteration stiger cpuNonKernal fra at lægge
Hen ved testens 5. iteration sker der dog en stor ændring i dette mønster. Her stiger cpuNonKernal fra at ligge under 50 % til at komme over og til sidst ramme 90 %. For docker01 vedkommende stiger den meget brat og rammer næsten 100 %.
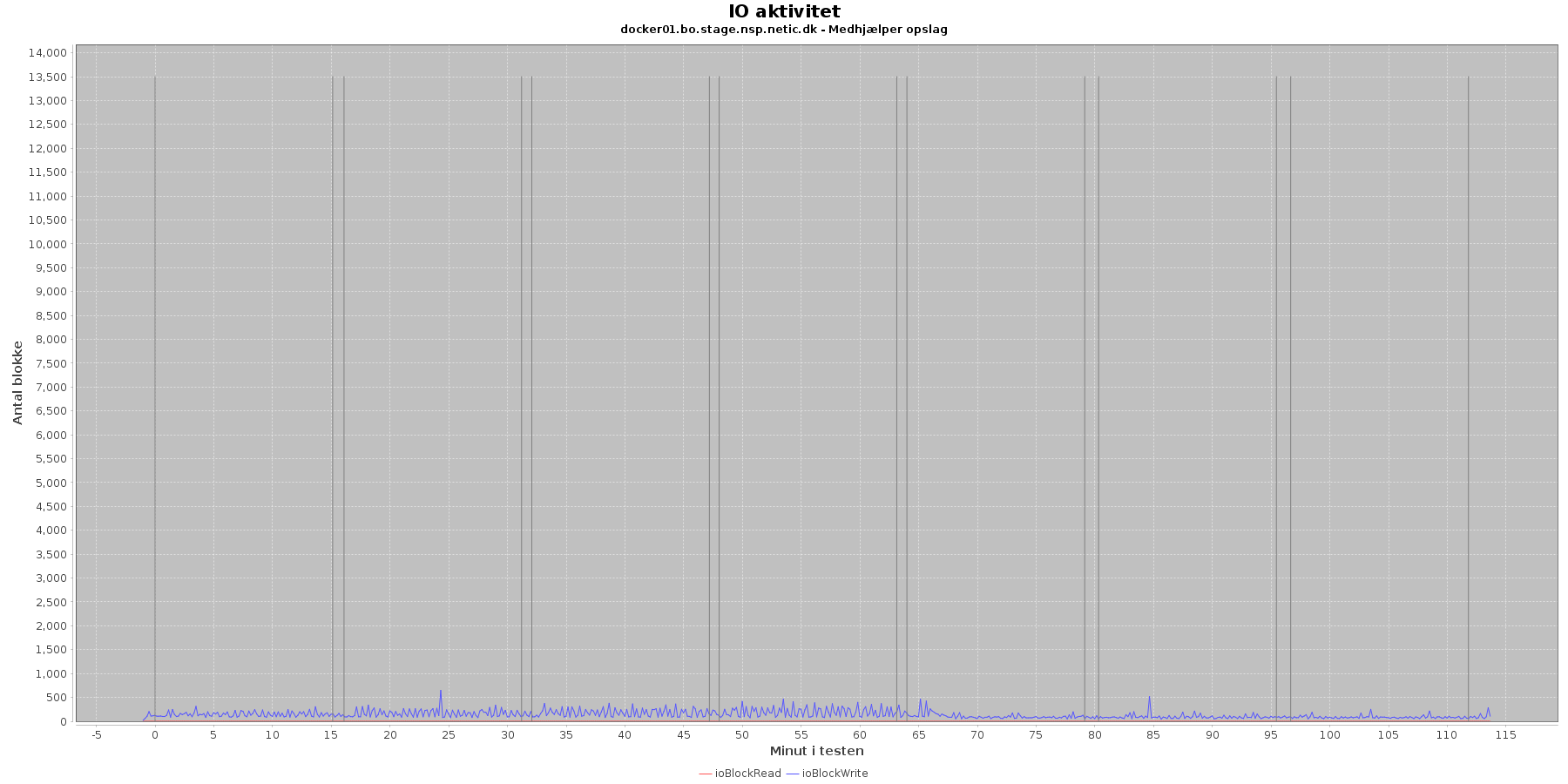
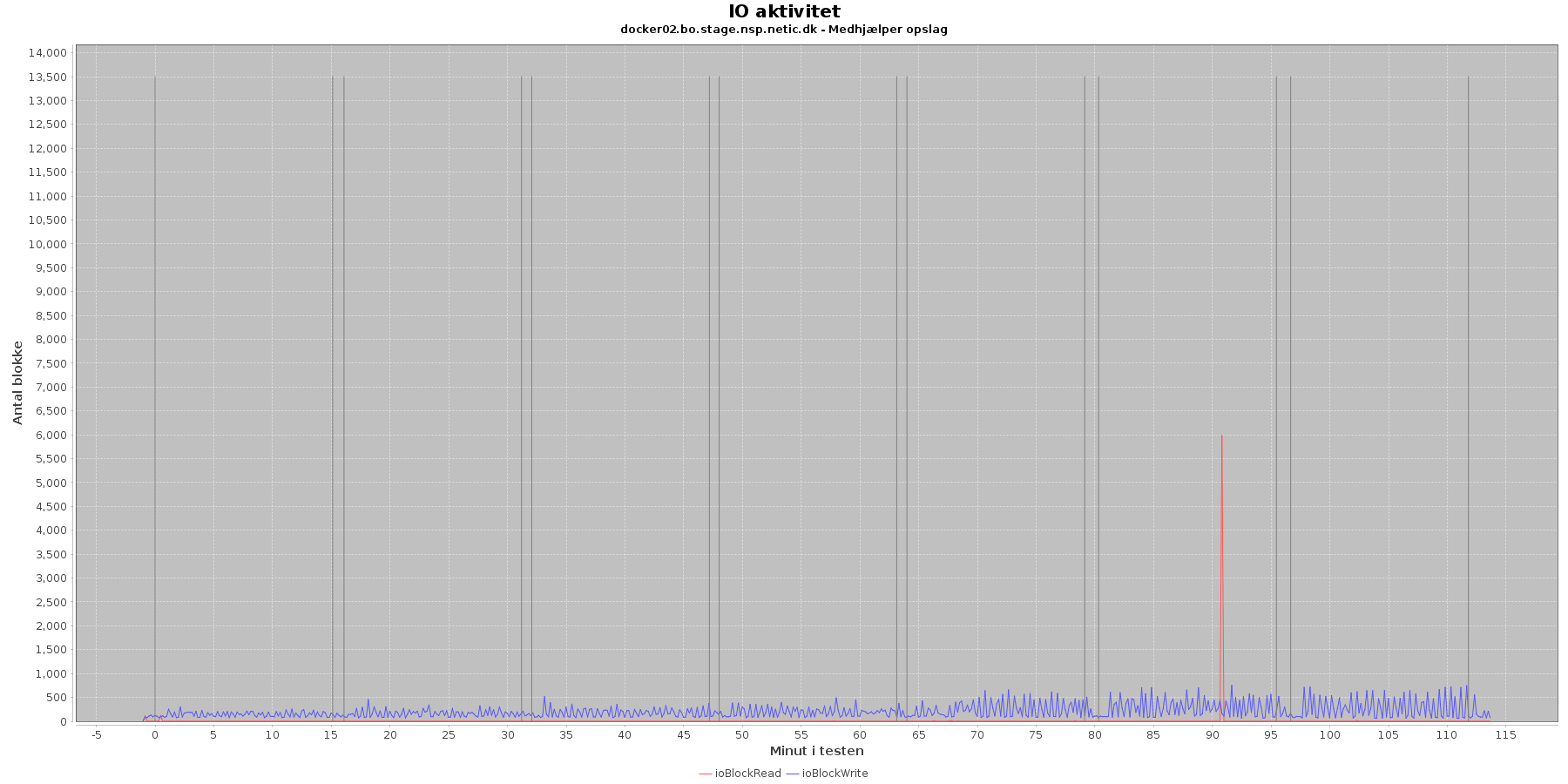
Udtræk omkring io læs og skriv fra vmstat vises i de følgende grafer:
Data serier i grafen er:
- ioBlockRead (rød): læsning på disk (blokke)
- ioBlockWrite (blå): skriving på disk (blokke)
- iterationerne (sort) er en cirka placering, da wmstat loggen ikke indeholder tidstempel
Der er løbende skriv til disken mens testen kører
Vurdering
Cpu forbruget i 5. og efterfølgende iterationer kan give grund til bekymring.
Jstat log
Denne log findes for hver applikations server (docker container). Loggen viser resultatet af kommandoen jstat. Jstat siger noget om, hvordan JVM'en har det.
Udtræk omkring hukommelse og garbage collection fra denne log vises i de følgende grafer:
Data serier i grafen er:
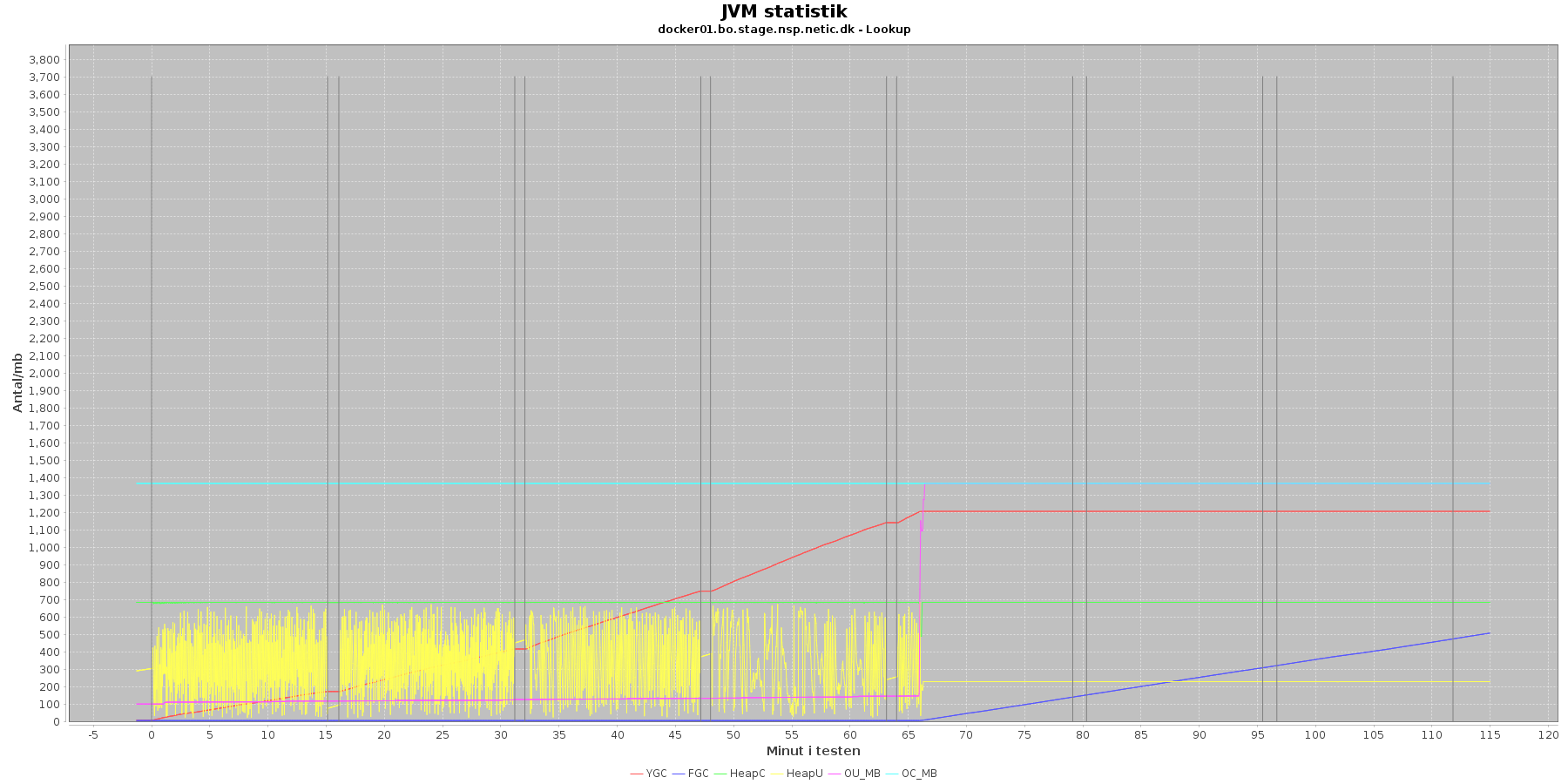
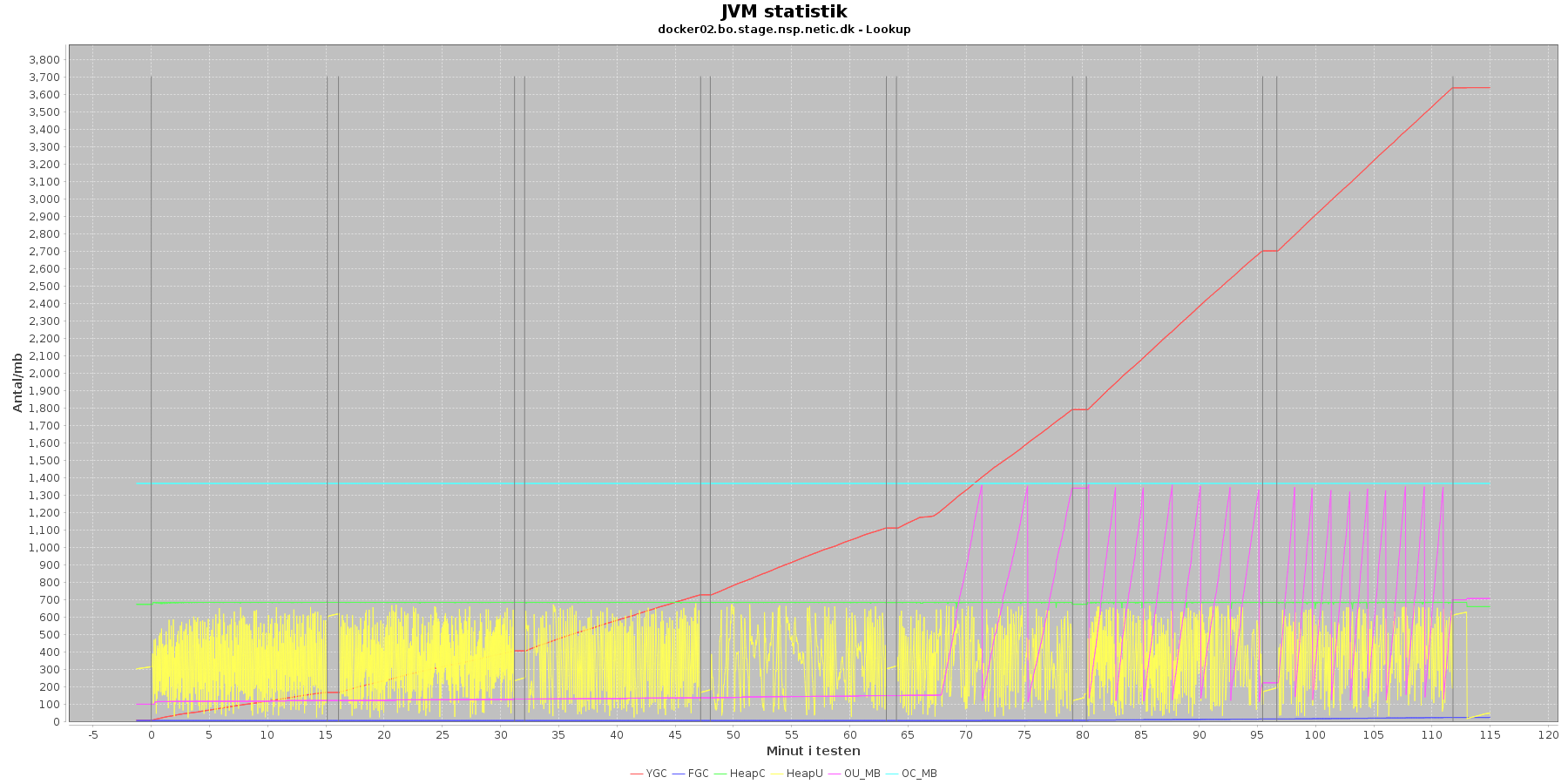
- YGC (rød): young generation garbage collection events, antal af "ung" garbage collection siden start
- FGC (blå): full garbage collection events, antal af fuldstændig garbage collection siden start
- HeapU (gul): består af S0U+S1U+EU fra jstat loggen. Young generation memory utilization. "Ung" hukommelses forbrug
- HeapC (grøn): består af S0C+S1C+EC fra jstat loggen. Young generation memory capacity. "Ung" hukommelses kapacitet
- OU_MB (pink): old space utilization. "Ældre" hukommelses forbrug
- OC_MB (tyrkis): old space capacity. "Ældre" hukommelses kapacitet er konstant på 1.398.272 KB.
- Iterationer (sort) er baseret på det tidstempel, som findes i jstatloggen
For docker02 er der kørt full garbage collection (FGC) 18 gange under testen. Docker01 kører full garbage collection 513 gange.
Der er en svag stigende tendens på den ældre hukommelse (OU_MB). Og fra iteration 5, stiger den en del, især for docker01, hvor den faktisk rammer loftet på 1.398.272 KB.
Der køres ofte garbage collection på den yngre hukommelse, hvilket holder HeapU - yngre hukommelses forbrug - nede så den kun svinger inden for et konstant interval.
Vurdering
Det giver anledning til bekymring at den ældre hukommelse rammer loftet ved øget pres og får servicen til at gå ned.
Docker stats log
Denne log findes for hver applikations server (docker container). Loggen viser resultatet af kommandoen docker stats. Docker stats siger noget om, hvordan containeren forbruger sine ressourcer.
Udtræk omkring hukommelse, cpu og netværkstrafik vises i følgende grafer.
Hukommelse:
Data serier i grafen er:
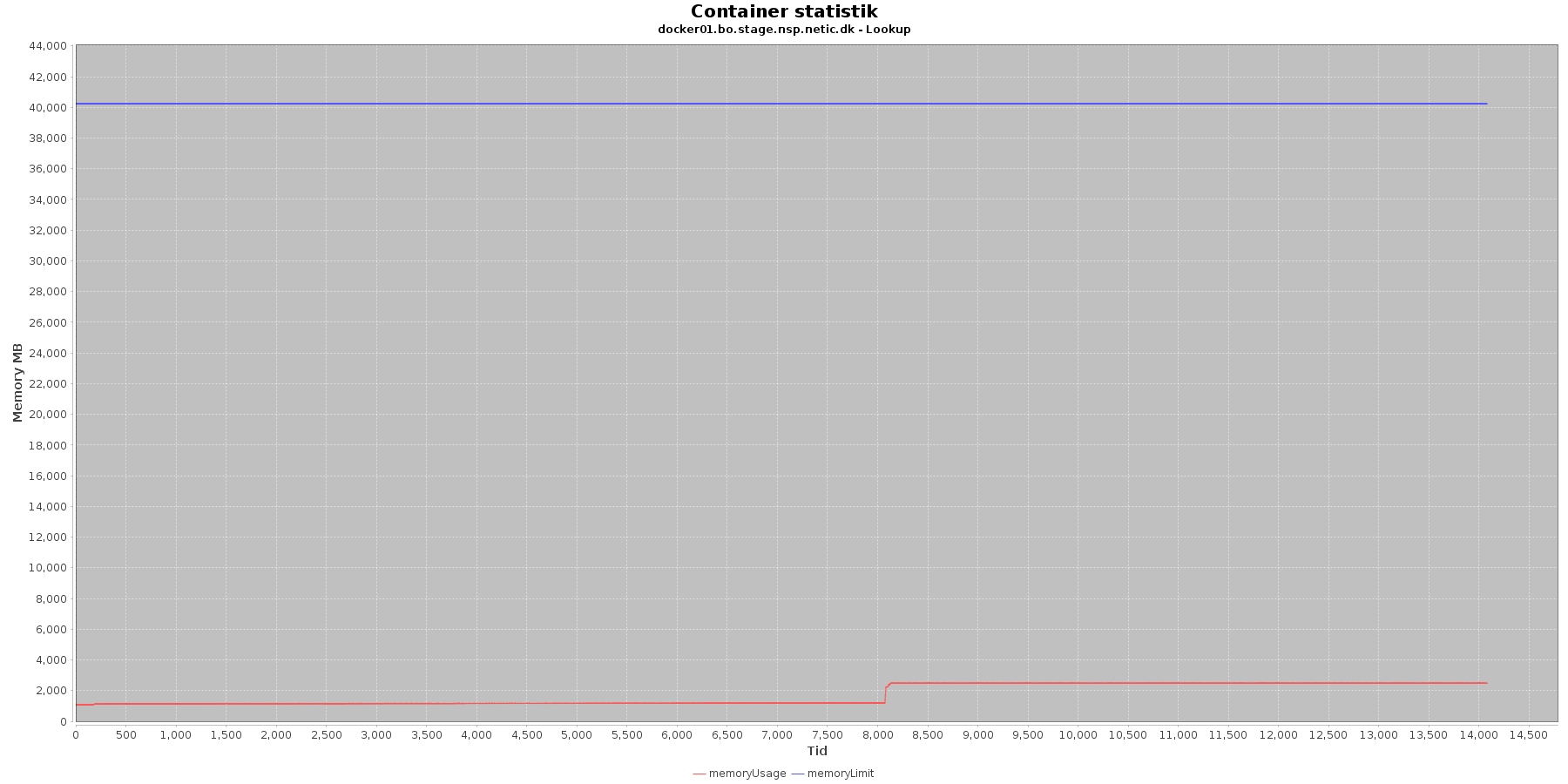
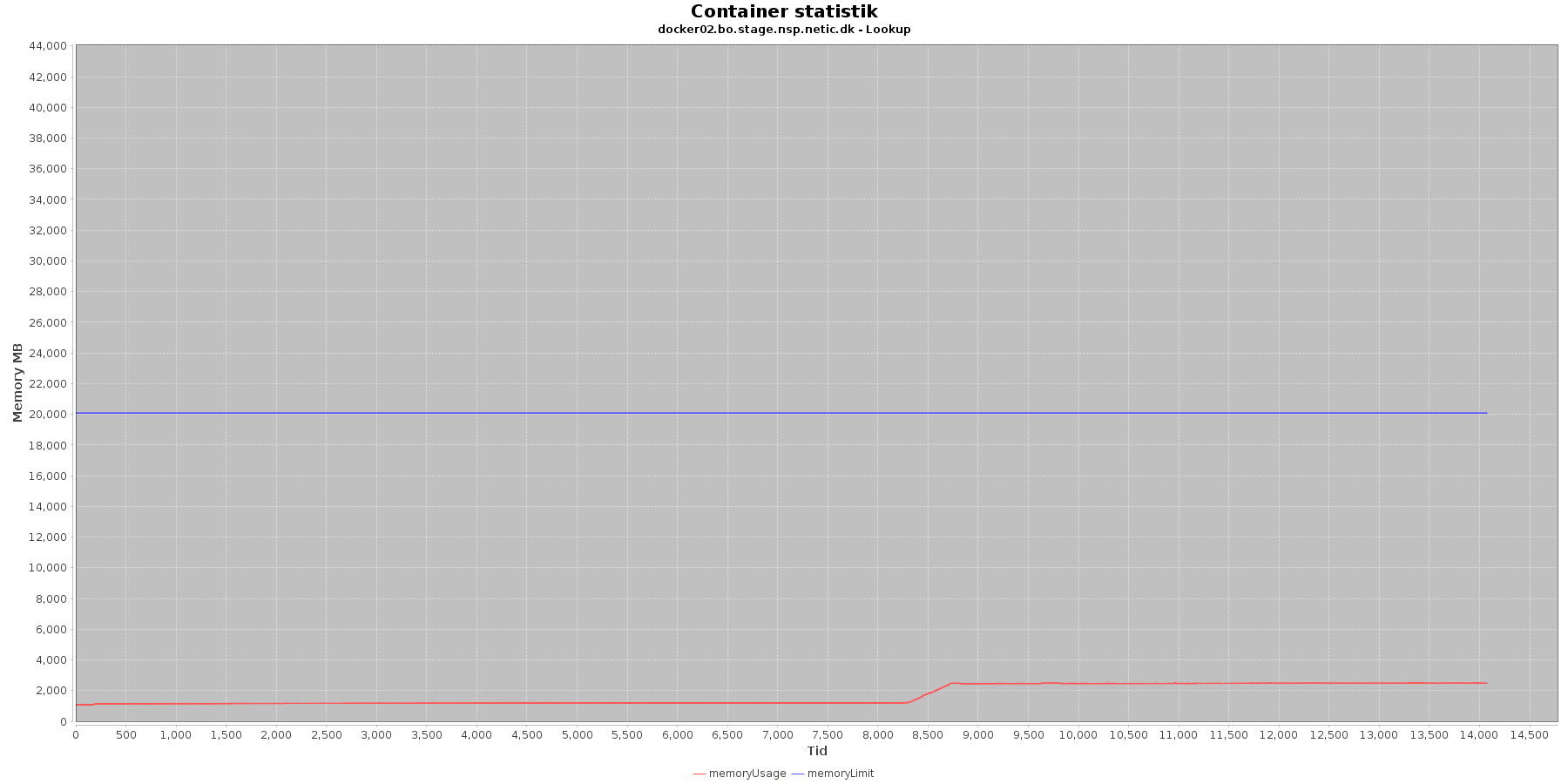
- memoryUsage (rød): den totale mængde hukommelse containeren bruger
- memoryLimit (blå): den totale mængde hukommelse contaneren kan bruge
Den forbrugte hukommelse er meget stabil indtil sidst i testen, hvor den for især docker1 stiger brat.
Den forbrugte hukommelse er meget stabil indtil iteration 5, hvor den stiger.
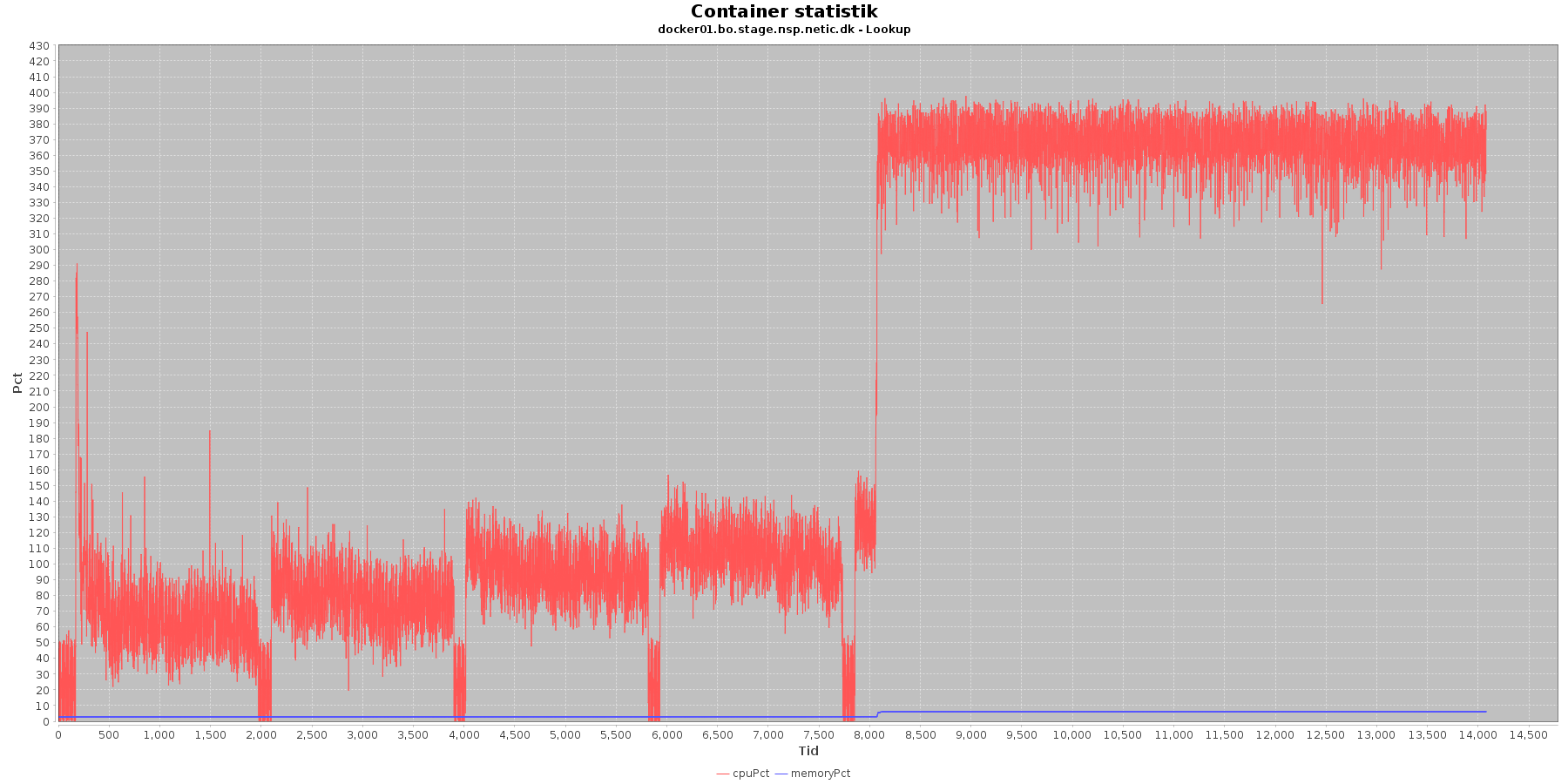
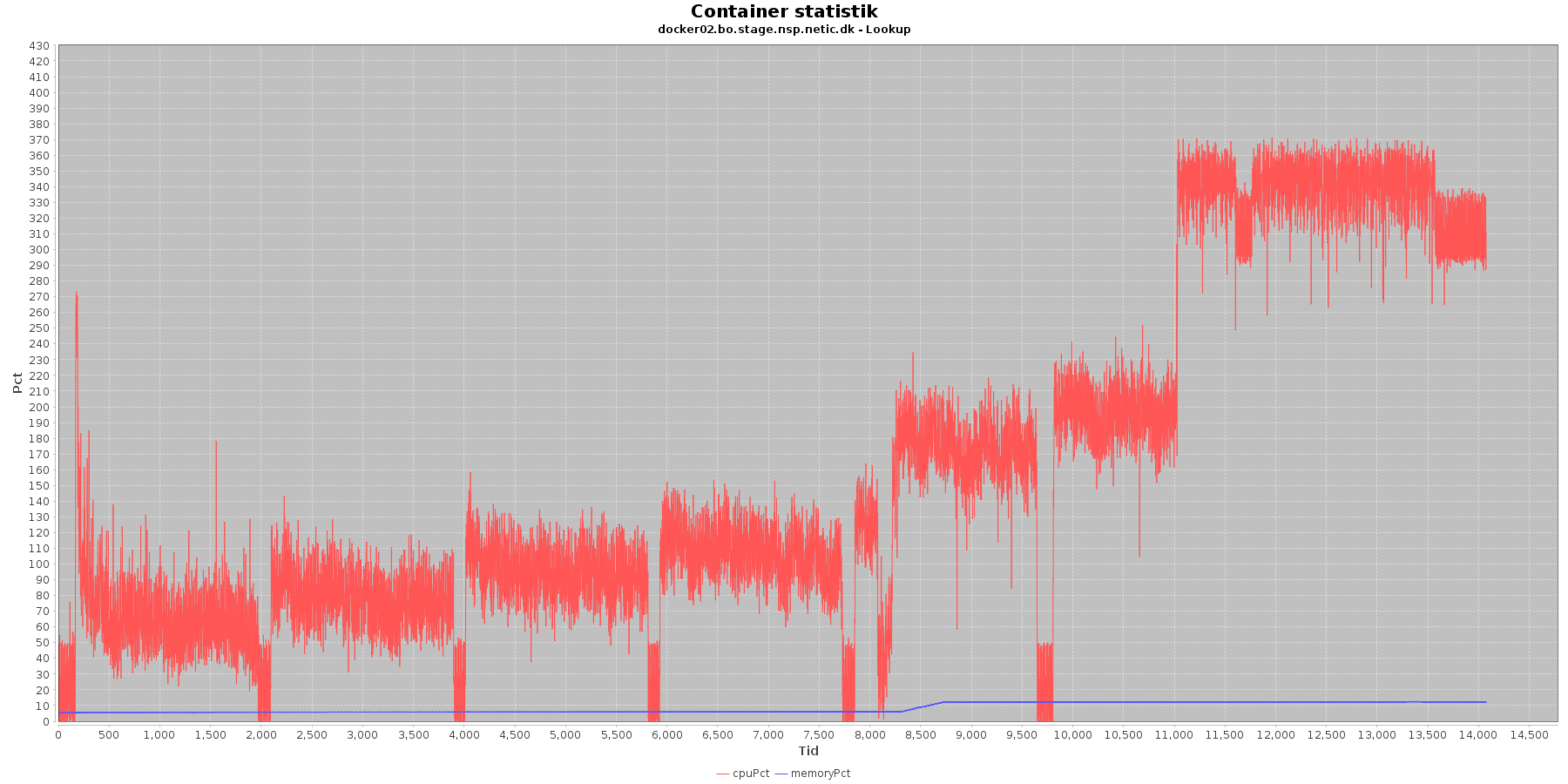
Cpu og hukommelse procent:
Data serier i grafen er:
- cpuPct (rød): hvor mange procent af hostens cpu containeren bruger
- memoryPct (blå): hvor mange procent af hostens hukommelse containeren bruger
Servicen viser et stabilt forbrug af hukommelse i starten af testen, men igen ses en stigning ved iteration 5.
Den envendte cpu er svagt stigende som servicen bliver presset. Og fra 5. iteration laver både docker01 og docker02 nogle høje spring i cpu forbruget.
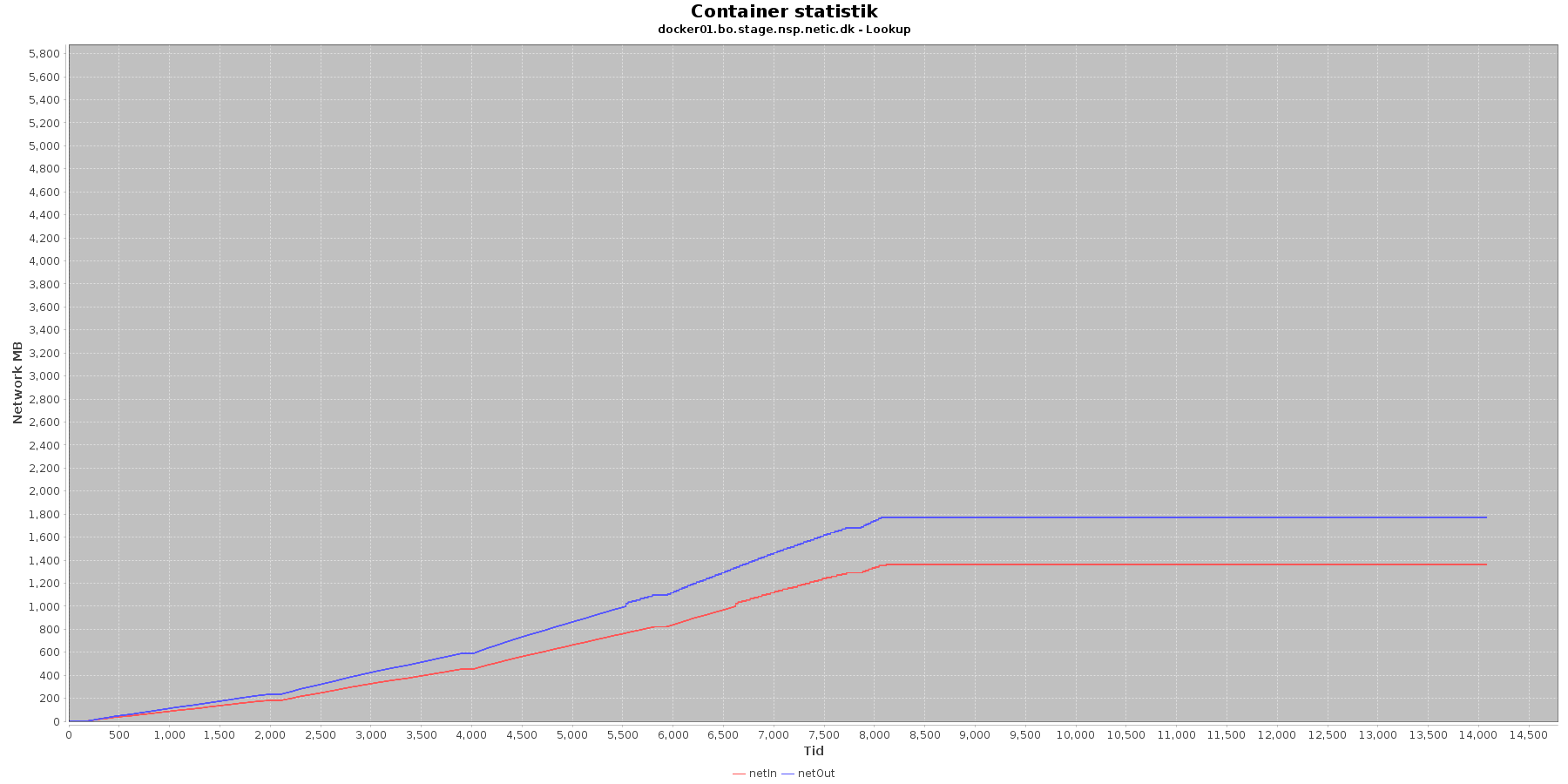
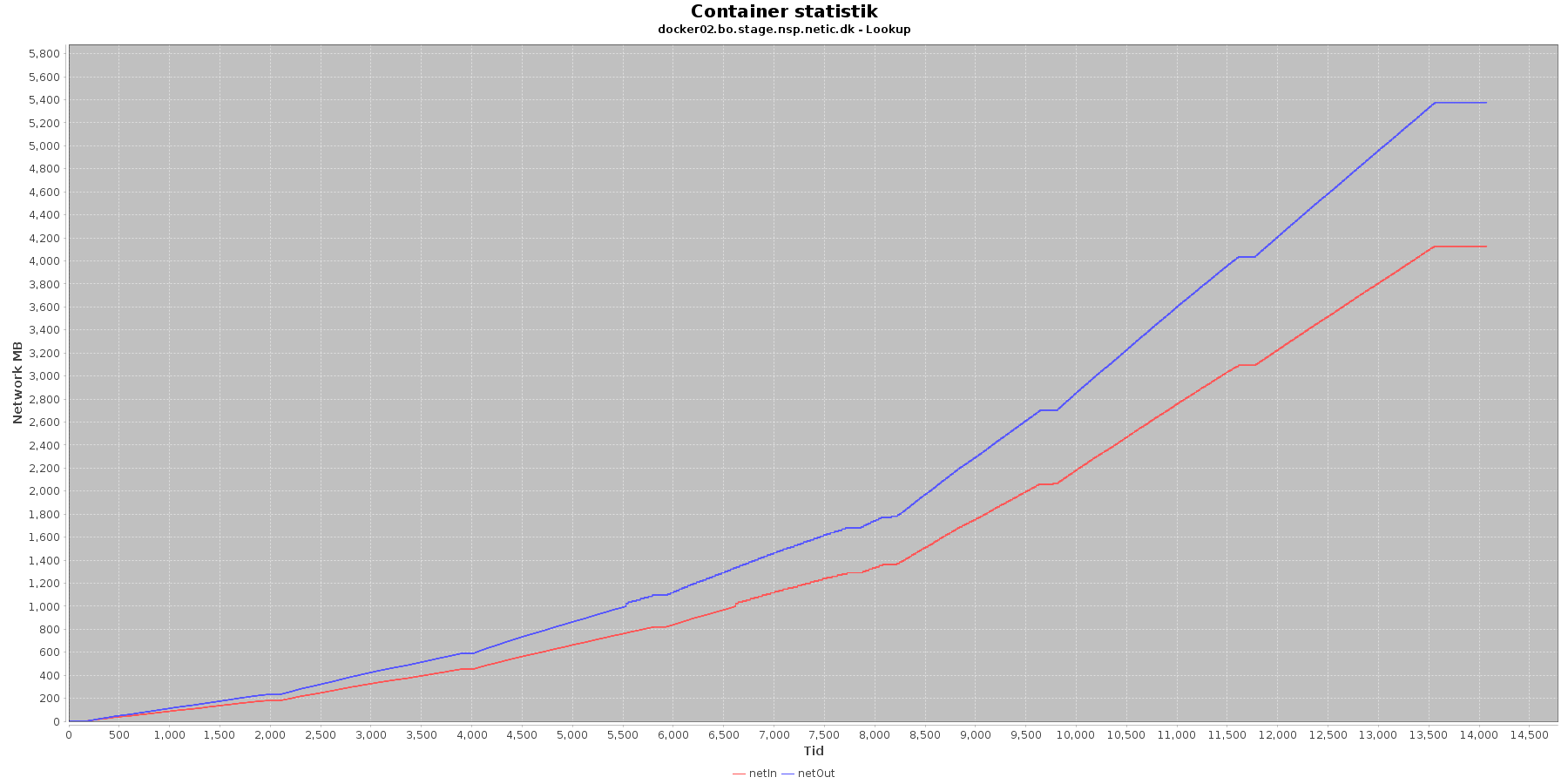
Netværk:
Data serier i grafen er:
- netIn (rød): den mængde data som er modtaget af containeren over netværket
- netOut (blå): den mængde data som er sendt ud af containeren over netværket
De 2 grafer for ind- og udsendt data følges ad, hvilket er forventeligt; indkomne kald skaber trafik til database og igen retur til kalder. netOut stiger mest. Dog flader docker02 ud i iteration 5 og har ikke mere trafik.
Vurdering
Disse log data viser igen den øgede cpu og hukommelsesforbrug fra iteration 5 i testen.
Konklusion
MinLog2 - Performancetest rapport registration
...